A História Da Família Powerpc
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PPC400 Debugger C++ and JAVAC++ Aswell Asthe Debugging of the TPU
BDM-PPC400 Technical Information Technical PPC400 Debugger ■ Full HLL and ASM support available ■ Batch processing ■ Supports ELF/DWARF format ■ 3.3 volt support ■ Support for internal triggers ■ Break on code or data ■ Unlimited software breakpoints ■ Fast download (ETHERNET or PARALLEL) up to 600KB/sec The debugger for IBM PowerPC 400 family allows fast access to the BDM interface of the chip. Up to 450 KByte can be downloaded in 1 second. The systems supports C, C++ and JAVA as well as the debugging of the TPU. BDM-PPC400 14.06.13 TRACE32 - Technical Information 2 Features ❏ Active and Passive JTAG ❏ Variable Debug Clock Speed Debugger available ■ 10 kHz...5 MHz ■ 1/4 CPU Clock ■ 1/8 CPU Clock ❏ Software Compatible to In-Circuit ■ Variable up to 100 MHz (Pow- Emulator and Monitor erDebug only) ■ Operation System ■ PRACTICE ❏ ■ ASM Debugger Tr igger ■ HLL Debugger for C and C++ ■ Input from PODBUS ■ Peripheral Windows ■ Output to PODBUS ❏ High-Speed Download ❏ Support for EPROM/FLASH ■ Up to 450 KByte/sec Simulator ■ Breakpoints in ROM Area ■ 8, 16 and 32 Bit EPROM/ FLASH Emulation BDM-PPC400 Features TRACE32 - Technical Information 3 Connector Connector Type stanard 100 mil connector (BETRG, AMP, etc.) Connector 16 pin Signal Pin Pin Signal TDO 1 2 N/C TDI 3 4 TRST- (*) N/C 5 6 VCCS TCK 7 8 N/C TMS 9 10 N/C HALT- 11 12 N/C N/C 13 14 KEY N/C 15 16 GND BDM-PPC400 Connector TRACE32 - Technical Information 4 Operation Voltage Operation Voltage This list contains information on probes available for other voltage ranges. -

IBM Power System POWER8 Facts and Features
IBM Power Systems IBM Power System POWER8 Facts and Features April 29, 2014 IBM Power Systems™ servers and IBM BladeCenter® blade servers using IBM POWER7® and POWER7+® processors are described in a separate Facts and Features report dated July 2013 (POB03022-USEN-28). IBM Power Systems™ servers and IBM BladeCenter® blade servers using IBM POWER6® and POWER6+™ processors are described in a separate Facts and Features report dated April 2010 (POB03004-USEN-14). 1 IBM Power Systems Table of Contents IBM Power System S812L 4 IBM Power System S822 and IBM Power System S822L 5 IBM Power System S814 and IBM Power System S824 6 System Unit Details 7 Server I/O Drawers & Attachment 8 Physical Planning Characteristics 9 Warranty / Installation 10 Power Systems Software Support 11 Performance Notes & More Information 12 These notes apply to the description tables for the pages which follow: Y Standard / Supported Optional Optionally Available / Supported N/A or - Not Available / Supported or Not Applicable SOD Statement of General Direction announced SLES SUSE Linux Enterprise Server RHEL Red Hat Enterprise Linux a One x8 PCIe slots must contain a 4-port 1Gb Ethernet LAN available for client use b Use of expanded function storage backplane uses one PCIe slot Backplane provides dual high performance SAS controllers with 1.8 GB write cache expanded up to 7.2 GB with c compression plus Easy Tier function plus two SAS ports for running an EXP24S drawer d Full benchmark results are located at ibm.com/systems/power/hardware/reports/system_perf.html e Option is supported on IBM i only through VIOS. -

Power4 Focuses on Memory Bandwidth IBM Confronts IA-64, Says ISA Not Important
VOLUME 13, NUMBER 13 OCTOBER 6,1999 MICROPROCESSOR REPORT THE INSIDERS’ GUIDE TO MICROPROCESSOR HARDWARE Power4 Focuses on Memory Bandwidth IBM Confronts IA-64, Says ISA Not Important by Keith Diefendorff company has decided to make a last-gasp effort to retain control of its high-end server silicon by throwing its consid- Not content to wrap sheet metal around erable financial and technical weight behind Power4. Intel microprocessors for its future server After investing this much effort in Power4, if IBM fails business, IBM is developing a processor it to deliver a server processor with compelling advantages hopes will fend off the IA-64 juggernaut. Speaking at this over the best IA-64 processors, it will be left with little alter- week’s Microprocessor Forum, chief architect Jim Kahle de- native but to capitulate. If Power4 fails, it will also be a clear scribed IBM’s monster 170-million-transistor Power4 chip, indication to Sun, Compaq, and others that are bucking which boasts two 64-bit 1-GHz five-issue superscalar cores, a IA-64, that the days of proprietary CPUs are numbered. But triple-level cache hierarchy, a 10-GByte/s main-memory IBM intends to resist mightily, and, based on what the com- interface, and a 45-GByte/s multiprocessor interface, as pany has disclosed about Power4 so far, it may just succeed. Figure 1 shows. Kahle said that IBM will see first silicon on Power4 in 1Q00, and systems will begin shipping in 2H01. Looking for Parallelism in All the Right Places With Power4, IBM is targeting the high-reliability servers No Holds Barred that will power future e-businesses. -
Local, Compressed
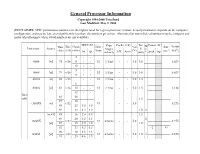
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

Chapter 2-1: Cpus
Chapter 2-1: CPUs Soo-Ik Chae © 2007 Elsevier 1 Topics CPU metrics. Categories of CPUs. CPU mechanisms. High Performance Embedded Computing © 2007 Elsevier 2 Performance as a design metric Performance = speed: Latency. Throughput. Average vs. peak performance. Worst-case and best- case performance. High Performance Embedded Computing © 2007 Elsevier 3 Other metrics Cost (area). Energy and p ower. Predictability: important for embedded systems Pipelining: branch penalty. Memory system (Cache) : cache miss penalty Security: difficult to measure because of the fact that we do not know of a successful attack. High Performance Embedded Computing © 2007 Elsevier 4 Flyyypnn’s taxonomy of processors Single-instruction single-data (SISD): RISC, etc. Single-instruction multiple-data (SIMD): all processors perform the same operations. Multiple-instruction multiple-data (MIMD): homogeneou s or heterogeneou s multiprocessor. Multiple-instruction multiple data (MISD). High Performance Embedded Computing © 2007 Elsevier 5 Other axes of comparison RISC. Emphasis on software Sing le-cyclilittile, simple instructions Register to register: LOAD" and "STORE“ are independent instructions Low cycles per second, Large code sizes Spends more transistors on memory registers CISC. Emphasis on hardware multi-cycle, complex instructions Memory-to-memory: LOAD" and "STORE“ incorporated in instructions High cycles per second Small code sizes Transistors used for storing complex instructions High Performance Embedded Computing © 2007 Elsevier 6 RISC CISC 1. 1-cycle simple instructions 1. multi-cycle complex instructions 2. only LD/ST can access memory 2. any instruction may access memory 3. designed around pipeline 3. designed around instn. set 4. instns. executed by h/w 4. instns interpreted by micro-program 5. -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

Coverstory by Robert Cravotta, Technical Editor
coverstory By Robert Cravotta, Technical Editor u WELCOME to the 31st annual EDN Microprocessor/Microcontroller Di- rectory. The number of companies and devices the directory lists continues to grow and change. The size of this year’s table of devices has grown more than NEW PROCESSOR OFFERINGS 25% from last year’s. Also, despite the fact that a number of companies have disappeared from the list, the number of companies participating in this year’s CONTINUE TO INCLUDE directory has still grown by 10%. So what? Should this growth and change in the companies and devices the directory lists mean anything to you? TARGETED, INTEGRATED One thing to note is that this year’s directory has experienced more compa- ny and product-line changes than the previous few years. One significant type PERIPHERAL SETS THAT SPAN of change is that more companies are publicly offering software-programma- ble processors. To clarify this fact, not every company that sells processor prod- ALL ARCHITECTURE SIZES. ucts decides to participate in the directory. One reason for not participating is that the companies are selling their processors only to specific customers and are not yet publicly offering those products. Some of the new companies par- ticipating in this year’s directory have recently begun making their processors available to the engineering public. Another type of change occurs when a company acquires another company or another company’s product line. Some of the acquired product lines are no longer available in their current form, such as the MediaQ processors that Nvidia acquired or the Triscend products that Arm acquired. -

Power Architecture® ISA 2.06 Stride N Prefetch Engines to Boost Application's Performance
Power Architecture® ISA 2.06 Stride N prefetch Engines to boost Application's performance History of IBM POWER architecture: POWER stands for Performance Optimization with Enhanced RISC. Power architecture is synonymous with performance. Introduced by IBM in 1991, POWER1 was a superscalar design that implemented register renaming andout-of-order execution. In Power2, additional FP unit and caches were added to boost performance. In 1996 IBM released successor of the POWER2 called P2SC (POWER2 Super chip), which is a single chip implementation of POWER2. P2SC is used to power the 30-node IBM Deep Blue supercomputer that beat world Chess Champion Garry Kasparov at chess in 1997. Power3, first 64 bit SMP, featured a data prefetch engine, non-blocking interleaved data cache, dual floating point execution units, and many other goodies. Power3 also unified the PowerPC and POWER Instruction set and was used in IBM's RS/6000 servers. The POWER3-II reimplemented POWER3 using copper interconnects, delivering double the performance at about the same price. Power4 was the first Gigahertz dual core processor launched in 2001 which was awarded the MicroProcessor Technology Award in recognition of its innovations and technology exploitation. Power5 came in with symmetric multi threading (SMT) feature to further increase application's performance. In 2004, IBM with 15 other companies founded Power.org. Power.org released the Power ISA v2.03 in September 2006, Power ISA v.2.04 in June 2007 and Power ISA v.2.05 with many advanced features such as VMX, virtualization, variable length encoding, hyper visor functionality, logical partitioning, virtual page handling, Decimal Floating point and so on which further boosted the architecture leadership in the market place and POWER5+, Cell, POWER6, PA6T, Titan are various compliant cores. -

IBM POWER8 High-Performance Computing Guide: IBM Power System S822LC (8335-GTB) Edition
Front cover IBM POWER8 High-Performance Computing Guide IBM Power System S822LC (8335-GTB) Edition Dino Quintero Joseph Apuzzo John Dunham Mauricio Faria de Oliveira Markus Hilger Desnes Augusto Nunes Rosario Wainer dos Santos Moschetta Alexander Pozdneev Redbooks International Technical Support Organization IBM POWER8 High-Performance Computing Guide: IBM Power System S822LC (8335-GTB) Edition May 2017 SG24-8371-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (May 2017) This edition applies to: IBM Platform LSF Standard 10.1.0.1 IBM XL Fortran v15.1.4 and v15.1.5 compilers IBM XLC/C++ v13.1.2 and v13.1.5 compilers IBM PE Developer Edition version 2.3 Red Hat Enterprise Linux (RHEL) 7.2 and 7.3 in little-endian mode © Copyright International Business Machines Corporation 2017. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . .x Preface . xi Authors. xi Now you can become a published author, too! . xiii Comments welcome. xiv Stay connected to IBM Redbooks . xiv Chapter 1. IBM Power System S822LC for HPC server overview . 1 1.1 IBM Power System S822LC for HPC server. 2 1.1.1 IBM POWER8 processor . 3 1.1.2 NVLink . 4 1.2 HPC system hardware components . 5 1.2.1 Login nodes . 6 1.2.2 Management nodes . 6 1.2.3 Compute nodes. 7 1.2.4 Compute racks . 7 1.2.5 High-performance interconnect. -

Technical Report
Technical Report Department of Computer Science University of Minnesota 4-192 EECS Building 200 Union Street SE Minneapolis, MN 55455-0159 USA TR 97-030 Hardware and Compiler-Directed Cache Coherence in Large-Scale Multiprocessors by: Lynn Choi and Pen-Chung Yew Hardware and Compiler-Directed Cache Coherence 1n Large-Scale Multiprocessors: Design Considerations and Performance Study1 Lynn Choi Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign 1308 West Main Street Urbana, IL 61801 Email: lchoi@csrd. uiuc. edu Pen-Chung Yew 4-192 EE/CS Building Department of Computer Science University of Minnesota 200 Union Street, SE Minneapolis, MN 55455-0159 Email: [email protected] Abstract In this paper, we study a hardware-supported, compiler-directed (HSCD) cache coherence scheme, which can be implemented on a large-scale multiprocessor using off-the-shelf micro processors, such as the Cray T3D. The scheme can be adapted to various cache organizations, including multi-word cache lines and byte-addressable architectures. Several system related issues, including critical sections, inter-thread communication, and task migration have also been addressed. The cost of the required hardware support is minimal and proportional to the cache size. The necessary compiler algorithms, including intra- and interprocedural array data flow analysis, have been implemented on the Polaris parallelizing compiler [33]. From our simulation study using the Perfect Club benchmarks [5], we found that in spite of the conservative analysis made by the compiler, the performance of the proposed HSCD scheme can be comparable to that of a full-map hardware directory scheme. Given its compa rable performance and reduced hardware cost, the proposed scheme can be a viable alternative for large-scale multiprocessors such as the Cray T3D, which rely on users to maintain data coherence. -

POWER8: the First Openpower Processor
POWER8: The first OpenPOWER processor Dr. Michael Gschwind Senior Technical Staff Member & Senior Manager IBM Power Systems #OpenPOWERSummit Join the conversation at #OpenPOWERSummit 1 OpenPOWER is about choice in large-scale data centers The choice to The choice to The choice to differentiate innovate grow . build workload • collaborative • delivered system optimized innovation in open performance solutions ecosystem • new capabilities . use best-of- • with open instead of breed interfaces technology scaling components from an open ecosystem Join the conversation at #OpenPOWERSummit Why Power and Why Now? . Power is optimized for server workloads . Power8 was optimized to simplify application porting . Power8 includes CAPI, the Coherent Accelerator Processor Interconnect • Building on a long history of IBM workload acceleration Join the conversation at #OpenPOWERSummit POWER8 Processor Cores • 12 cores (SMT8) 96 threads per chip • 2X internal data flows/queues • 64K data cache, 32K instruction cache Caches • 512 KB SRAM L2 / core • 96 MB eDRAM shared L3 • Up to 128 MB eDRAM L4 (off-chip) Accelerators • Crypto & memory expansion • Transactional Memory • VMM assist • Data Move / VM Mobility • Coherent Accelerator Processor Interface (CAPI) Join the conversation at #OpenPOWERSummit 4 POWER8 Core •Up to eight hardware threads per core (SMT8) •8 dispatch •10 issue •16 execution pipes: •2 FXU, 2 LSU, 2 LU, 4 FPU, 2 VMX, 1 Crypto, 1 DFU, 1 CR, 1 BR •Larger Issue queues (4 x 16-entry) •Larger global completion, Load/Store reorder queue •Improved branch prediction •Improved unaligned storage access •Improved data prefetch Join the conversation at #OpenPOWERSummit 5 POWER8 Architecture . High-performance LE support – Foundation for a new ecosystem . Organic application growth Power evolution – Instruction Fusion 1600 PowerPC . -

Computer Architectures an Overview
Computer Architectures An Overview PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 25 Feb 2012 22:35:32 UTC Contents Articles Microarchitecture 1 x86 7 PowerPC 23 IBM POWER 33 MIPS architecture 39 SPARC 57 ARM architecture 65 DEC Alpha 80 AlphaStation 92 AlphaServer 95 Very long instruction word 103 Instruction-level parallelism 107 Explicitly parallel instruction computing 108 References Article Sources and Contributors 111 Image Sources, Licenses and Contributors 113 Article Licenses License 114 Microarchitecture 1 Microarchitecture In computer engineering, microarchitecture (sometimes abbreviated to µarch or uarch), also called computer organization, is the way a given instruction set architecture (ISA) is implemented on a processor. A given ISA may be implemented with different microarchitectures.[1] Implementations might vary due to different goals of a given design or due to shifts in technology.[2] Computer architecture is the combination of microarchitecture and instruction set design. Relation to instruction set architecture The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the execution model, processor registers, address and data formats among other things. The Intel Core microarchitecture microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA. The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be everything from single gates and registers, to complete arithmetic logic units (ALU)s and even larger elements.