Xcell Journal Issue 42, Spring 2002
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures
18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 1/28/2015 Agenda for Today & Next Few Lectures n Single-cycle Microarchitectures n Multi-cycle and Microprogrammed Microarchitectures n Pipelining n Issues in Pipelining: Control & Data Dependence Handling, State Maintenance and Recovery, … n Out-of-Order Execution n Issues in OoO Execution: Load-Store Handling, … 2 Reminder on Assignments n Lab 2 due next Friday (Feb 6) q Start early! n HW 1 due today n HW 2 out n Remember that all is for your benefit q Homeworks, especially so q All assignments can take time, but the goal is for you to learn very well 3 Lab 1 Grades 25 20 15 10 5 Number of Students 0 30 40 50 60 70 80 90 100 n Mean: 88.0 n Median: 96.0 n Standard Deviation: 16.9 4 Extra Credit for Lab Assignment 2 n Complete your normal (single-cycle) implementation first, and get it checked off in lab. n Then, implement the MIPS core using a microcoded approach similar to what we will discuss in class. n We are not specifying any particular details of the microcode format or the microarchitecture; you can be creative. n For the extra credit, the microcoded implementation should execute the same programs that your ordinary implementation does, and you should demo it by the normal lab deadline. n You will get maximum 4% of course grade n Document what you have done and demonstrate well 5 Readings for Today n P&P, Revised Appendix C q Microarchitecture of the LC-3b q Appendix A (LC-3b ISA) will be useful in following this n P&H, Appendix D q Mapping Control to Hardware n Optional q Maurice Wilkes, “The Best Way to Design an Automatic Calculating Machine,” Manchester Univ. -

System Design for a Computational-RAM Logic-In-Memory Parailel-Processing Machine
System Design for a Computational-RAM Logic-In-Memory ParaIlel-Processing Machine Peter M. Nyasulu, B .Sc., M.Eng. A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy Ottaw a-Carleton Ins titute for Eleceical and Computer Engineering, Department of Electronics, Faculty of Engineering, Carleton University, Ottawa, Ontario, Canada May, 1999 O Peter M. Nyasulu, 1999 National Library Biôiiothkque nationale du Canada Acquisitions and Acquisitions et Bibliographie Services services bibliographiques 39S Weiiington Street 395. nie WeUingtm OnawaON KlAW Ottawa ON K1A ON4 Canada Canada The author has granted a non- L'auteur a accordé une licence non exclusive licence allowing the exclusive permettant à la National Library of Canada to Bibliothèque nationale du Canada de reproduce, ban, distribute or seU reproduire, prêter, distribuer ou copies of this thesis in microform, vendre des copies de cette thèse sous paper or electronic formats. la forme de microficbe/nlm, de reproduction sur papier ou sur format électronique. The author retains ownership of the L'auteur conserve la propriété du copyright in this thesis. Neither the droit d'auteur qui protège cette thèse. thesis nor substantial extracts fkom it Ni la thèse ni des extraits substantiels may be printed or otherwise de celle-ci ne doivent être imprimés reproduced without the author's ou autrement reproduits sans son permission. autorisation. Abstract Integrating several 1-bit processing elements at the sense amplifiers of a standard RAM improves the performance of massively-paralle1 applications because of the inherent parallelism and high data bandwidth inside the memory chip. -
Local, Compressed
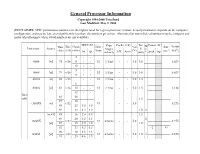
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

Micro-Circuits for High Energy Physics*
MICRO-CIRCUITS FOR HIGH ENERGY PHYSICS* Paul F. Kunz Stanford Linear Accelerator Center Stanford University, Stanford, California, U.S.A. ABSTRACT Microprogramming is an inherently elegant method for implementing many digital systems. It is a mixture of hardware and software techniques with the logic subsystems controlled by "instructions" stored Figure 1: Basic TTL Gate in a memory. In the past, designing microprogrammed systems was difficult, tedious, and expensive because the available components were capable of only limited number of functions. Today, however, large blocks of microprogrammed systems have been incorporated into a A input B input C output single I.e., thus microprogramming has become a simple, practical method. false false true false true true true false true true true false 1. INTRODUCTION 1.1 BRIEF HISTORY OF MICROCIRCUITS Figure 2: Truth Table for NAND Gate. The first question which arises when one talks about microcircuits is: What is a microcircuit? The answer is simple: a complete circuit within a single integrated-circuit (I.e.) package or chip. The next question one might ask is: What circuits are available? The answer to this question is also simple: it depends. It depends on the economics of the circuit for the semiconductor manufacturer, which depends on the technology he uses, which in turn changes as a function of time. Thus to understand Figure 3: Logical NOT Circuit. what microcircuits are available today and what makes them different from those of yesterday it is interesting to look into the economics of producing microcircuits. The basic element in a logic circuit is a gate, which is a circuit with a number of inputs and one output and it performs a basic logical function such as AND, OR, or NOT. -

P4080 Development System User's Guide
Freescale Semiconductor Document Number: P4080DSUG User Guide Rev. 0, 07/2010 P4080 Development System User’s Guide by Networking and Multimedia Group Freescale Semiconductor, Inc. Austin, TX Contents 1Overview 1. Overview . 1 2. Features Summary . 2 The P4080 development system (DS) is a high-performance 3. Block Diagram and Placement . 4 computing, evaluation, and development platform 4. Evaluation Support . 6 supporting the P4080 Power Architecture® processor. The 5. Architecture . 8 P4080 development system’s official designation is 6. Configuration . 40 7. Programming Model . 45 P4080DS, and may be ordered using this part number. 8. Revision History . 58 The P4080DS is designed to the ATX form-factor standard, A. References . 58 allowing it to be used in 2U rack-mount chassis, as well as in a standard ATX chassis. The system is lead-free and RoHS-compliant. © 2011 Freescale Semiconductor, Inc. All rights reserved. Features Summary 2 Features Summary The features of the P4080DS development board are as follows: • Support for the P4080 processor — Core processors – Eight e500mc cores – 45 nm SOI process technology — High-speed serial port (SerDes) – Eighteen lanes, dividable into many combinations – Five controllers support five add-in card slots. – Supports PCI Express, SGMII, Nexus/Aurora debug, XAUI, and Serial RapidIO®. — Dual DDR memory controllers – Designed for DDR3 support – One-per-channel 240-pin sockets that support standard JEDEC DIMMs — Triple-speed Ethernet/ USB controller – One 10/100/1G port uses on-board VSC8244 PHY -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

Micro-Sequencer Based Control Unit Design for a Central Processing Unit
MICRO-SEQUENCER BASED CONTROL UNIT DESIGN FOR A CENTRAL PROCESSING UNIT TAN CHANG HAI A project report submitted in partial fulfillment of the requirement for the award of the degree of Master of Engineering (Computer & Microelectronic Systems) Faculty of Electrical Engineering Universiti Teknologi Malaysia APRIL 2007 iii DEDICATION To my beloved wife, parents and family members iv ACKNOLEDGEMENT In preparing this thesis, I was in contact with many people, researchers and academicians. They have contributed towards my understanding and thoughts. In particular, I wish to express my sincere appreciation to my thesis supervisor, Professor Dr. Mohamed Khalil Hani, for encouragement, guidance and friendships. I am also very thankful to my friends and family members for their great support, advices and motivation. Without their continued support and interest, this thesis would not have been as presented here. v ABSTRACT Central Processing Unit (CPU) is a processing unit that controls the computer operations. The current in house CPU design was not complete therefore the purpose of this research was to enhance the current CPU design in such a way that it can handle hardware interrupt operation, stack operations and subroutine call. Register transfer logic (RTL) level design methodology namely top level RTL architecture, RTL control algorithm, data path unit design, RTL control sequence table, micro- sequencer control unit design, integration of control unit and data path unit, and the functional simulation for the design verification are included in this research. vi ABSTRAK Unit pusat pemprosesan (CPU) merupakan sebuah mesin yang berfungsi untuk menjana fungsi komputer. Buat masa kini, rekaan CPU masih belum sempurna. -
EEL 4914 Senior Design Gator Μprocessor Spring 2007 Submitted By
EEL 4914 Senior Design Gator µProcessor Spring 2007 Submitted by: Kevin Phillipson Project Abstract The Gator microprocessor or GµP is a central processing unit to be used for education and research at the University of Florida. This processor will be realized on a development board that will be constructed in the course of this project. The board will contain a programmable gate array, in this case a FPGA. Using this FPGA we can dynamically build and test the CPU by describing and synthesizing it using a hardware description language. The processor will be instruction set & machine code compatible with the Motorola/Freescale 68xx microprocessors. This will allow us to use the extensive library of compliers, assemblers and other tools already available. Introduction The ultimate goal is to create a tool which could be used to bridge between Microprocessor Applications (EEL4744C) and Digital Design (EEL4712C) while enhancing both classes. Currently, the courses implement two separate boards. EEL4744C uses a board based on the Freescale 68HC12 micro-controller (Figure 1). It is supported by an EEPROM containing a monitor program, a 4MHz crystal oscillator, a serial port connection, an Altera CPLD, bus drivers and various supporting resistors and capacitors. Most devices are through-hole mounted. EEL4712C uses the BT-U board produced by Binary Technologies which is based on an Altera Cyclone FPGA (Figure 2). The board also features VGA & PS2 interfaces, switch banks and LED displays. The board comes pre-assembled. Figure 1: Current 4744 board Figure 2: Current 4712 board The GµP would be a bridge between these two designs, implementing a 68xx compatible CPU core in an Altera Cyclone II FPGA. -

Technical Report
Technical Report Department of Computer Science University of Minnesota 4-192 EECS Building 200 Union Street SE Minneapolis, MN 55455-0159 USA TR 97-030 Hardware and Compiler-Directed Cache Coherence in Large-Scale Multiprocessors by: Lynn Choi and Pen-Chung Yew Hardware and Compiler-Directed Cache Coherence 1n Large-Scale Multiprocessors: Design Considerations and Performance Study1 Lynn Choi Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign 1308 West Main Street Urbana, IL 61801 Email: lchoi@csrd. uiuc. edu Pen-Chung Yew 4-192 EE/CS Building Department of Computer Science University of Minnesota 200 Union Street, SE Minneapolis, MN 55455-0159 Email: [email protected] Abstract In this paper, we study a hardware-supported, compiler-directed (HSCD) cache coherence scheme, which can be implemented on a large-scale multiprocessor using off-the-shelf micro processors, such as the Cray T3D. The scheme can be adapted to various cache organizations, including multi-word cache lines and byte-addressable architectures. Several system related issues, including critical sections, inter-thread communication, and task migration have also been addressed. The cost of the required hardware support is minimal and proportional to the cache size. The necessary compiler algorithms, including intra- and interprocedural array data flow analysis, have been implemented on the Polaris parallelizing compiler [33]. From our simulation study using the Perfect Club benchmarks [5], we found that in spite of the conservative analysis made by the compiler, the performance of the proposed HSCD scheme can be comparable to that of a full-map hardware directory scheme. Given its compa rable performance and reduced hardware cost, the proposed scheme can be a viable alternative for large-scale multiprocessors such as the Cray T3D, which rely on users to maintain data coherence. -

Traditional Cisc Design
Supplement to Logic and Computer Design Fundamentals 4th Edition1 TRADITIONAL CISC DESIGN elected topics not covered in the fourth edition of Logic and Computer Design Fundamentals are provided here for optional coverage and for self-study. This S material fits well with the desired coverage in some programs but not may not fit within others due to time constraints or local preferences. This supplement consists of the CISC processor material from Chapter 10 of the 2nd edition of Logic and Computer Design Fundamentals. The use of this material is not recommended except as an example of microprogramming applied to a non-pipelined system. Note that the processor described is incomplete, has some architectural inconsistencies, and does not represent current processor microarchitectures. Instruction Set Architecture Figure 1 shows the CISC register set accessible to the programmer. All registers have 16 bits. The register file has eight registers, R0 through R7. R0 is a special reg- ister that always supplies the value zero when it is used as a source and discards the result when it is used as a destination. In addition to the register file, there is a program counter PC and stack pointer SP. The presence of a stack pointer indicates that a memory stack is a part of the architecture. The final register is the processor status register PSR, which contains information only in its rightmost five bits; the remainder of the register is assumed to contain zero. The PSR contains the four stored status bit values Z, N, C, and V in positions 3 through 0, respectively. -

Quesenberry JD T 2011.Pdf (1.137Mb)
Communication Synthesis for MIMO Decoder Algorithms Joshua D. Quesenberry Thesis submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science in Computer Engineering Cameron D. Patterson, Chair Michael S. Hsiao Thomas L. Martin August 9, 2011 Bradley Department of Electrical and Computer Engineering Blacksburg, Virginia Keywords: FPGA, Xilinx, Communication Synthesis, MIMO Copyright 2011, Joshua D. Quesenberry Communication Synthesis for MIMO Decoder Algorithms Joshua D. Quesenberry (ABSTRACT) The design in this work provides an easy and cost-efficient way of performing an FPGA implementation of a specific algorithm through use of a custom hardware design language and communication synthesis. The framework is designed to optimize performance with matrix-type mathematical operations. The largest matrices used in this process are 4 4 × matrices. The primary example modeled in this work is MIMO decoding. Making this possible are 16 functional unit containers within the framework, with generalized interfaces, which can hold custom user hardware and IP cores. This framework, which is controlled by a microsequencer, is centered on a matrix-based memory structure comprised of 64 individual dual-ported memory blocks. The microse- quencer uses an instruction word that can control every element of the architecture during a single clock cycle. Routing to and from the memory structure uses an optimized form of a crossbar switch with predefined routing paths supporting any combination of input/output pairs needed by the algorithm. A goal at the start of the design was to achieve a clock speed of over 100 MHz; a clock speed of 183 MHz has been achieved. -

SMBIOS Specification
1 2 Document Identifier: DSP0134 3 Date: 2019-10-31 4 Version: 3.4.0a 5 System Management BIOS (SMBIOS) Reference 6 Specification Information for Work-in-Progress version: IMPORTANT: This document is not a standard. It does not necessarily reflect the views of the DMTF or its members. Because this document is a Work in Progress, this document may still change, perhaps profoundly and without notice. This document is available for public review and comment until superseded. Provide any comments through the DMTF Feedback Portal: http://www.dmtf.org/standards/feedback 7 Supersedes: 3.3.0 8 Document Class: Normative 9 Document Status: Work in Progress 10 Document Language: en-US 11 System Management BIOS (SMBIOS) Reference Specification DSP0134 12 Copyright Notice 13 Copyright © 2000, 2002, 2004–2019 DMTF. All rights reserved. 14 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 15 management and interoperability. Members and non-members may reproduce DMTF specifications and 16 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 17 time, the particular version and release date should always be noted. 18 Implementation of certain elements of this standard or proposed standard may be subject to third party 19 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 20 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 21 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 22 inaccurate identification or disclosure of such rights, owners or claimants.