Jon Stokes Jon
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Beyond BIOS Developing with the Unified Extensible Firmware Interface
Digital Edition Digital Editions of selected Intel Press books are in addition to and complement the printed books. Click the icon to access information on other essential books for Developers and IT Professionals Visit our website at www.intel.com/intelpress Beyond BIOS Developing with the Unified Extensible Firmware Interface Second Edition Vincent Zimmer Michael Rothman Suresh Marisetty Copyright © 2010 Intel Corporation. All rights reserved. ISBN 13 978-1-934053-29-4 This publication is designed to provide accurate and authoritative information in regard to the subject matter covered. It is sold with the understanding that the publisher is not engaged in professional services. If professional advice or other expert assistance is required, the services of a competent professional person should be sought. Intel Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights that relate to the presented subject matter. The furnishing of documents and other materials and information does not provide any license, express or implied, by estoppel or otherwise, to any such patents, trademarks, copyrights, or other intellectual property rights. Intel may make changes to specifications, product descriptions, and plans at any time, without notice. Fictitious names of companies, products, people, characters, and/or data mentioned herein are not intended to represent any real individual, company, product, or event. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel, the Intel logo, Celeron, Intel Centrino, Intel NetBurst, Intel Xeon, Itanium, Pentium, MMX, and VTune are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. -

RISC-V Vector Extension Webinar II
RISC-V Vector Extension Webinar II August 3th, 2021 Thang Tran, Ph.D. Principal Engineer Webinar II - Agenda • Andes overview • Vector technology background – SIMD/vector concept – Vector processor basic • RISC-V V extension ISA – Basic – CSR • RISC-V V extension ISA – Memory operations – Compute instructions • Sample codes – Matrix multiplication – Loads with RVV versions 0.8 and 1.0 • AndesCore™ NX27V • Summary Copyright© 2020 Andes Technology Corp. 2 Terminology • ACE: Andes Custom Extension • ISA: Instruction Set Architecture • CSR: Control and Status Register • GOPS: Giga Operations Per Second • SEW: Element Width (8-64) • GFLOPS: Giga Floating-Point OPS • ELEN: Largest Element Width (32 or 64) • XRF: Integer register file • XLEN: Scalar register length in bits (64) • FRF: Floating-point register file • FLEN: FP register length in bits (16-64) • VRF: Vector register file • VLEN: Vector register length in bits (128-512) • SIMD: Single Instruction Multiple Data • LMUL: Register grouping multiple (1/8-8) • MMX: Multi Media Extension • EMUL: Effective LMUL • SSE: Streaming SIMD Extension • VLMAX/MVL: Vector Length Max • AVX: Advanced Vector Extension • AVL/VL: Application Vector Length • Configurable: parameters are fixed at built time, i.e. cache size • Extensible: added instructions to ISA includes custom instructions to be added by customer • Standard extension: the reserved codes in the ISA for special purposes, i.e. FP, DSP, … • Programmable: parameters can be dynamically changed in the program Copyright© 2020 Andes Technology Corp. 3 RISC-V V Extension ISA Basic Copyright© 2020 Andes Technology Corp. 4 Vector Register ISA • Vector-Register ISA Definition: − All vector operations are between vector registers (except for load and store). -
Local, Compressed
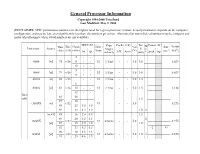
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

Optimizing Packed String Matching on AVX2 Platform
Optimizing Packed String Matching on AVX2 Platform M. Akif Aydo˘gmu¸s1,2 and M.O˘guzhan Külekci1 1 Informatics Institute, Istanbul Technical University, Istanbul, Turkey [email protected], [email protected] 2 TUBITAK UME, Gebze-Kocaeli, Turkey Abstract. Exact string matching, searching for all occurrences of given pattern P on a text T , is a fundamental issue in computer science with many applica- tions in natural language processing, speech processing, computational biology, information retrieval, intrusion detection systems, data compression, and etc. Speeding up the pattern matching operations benefiting from the SIMD par- allelism has received attention in the recent literature, where the empirical results on previous studies revealed that SIMD parallelism significantly helps, while the performance may even be expected to get automatically enhanced with the ever increasing size of the SIMD registers. In this paper, we provide variants of the previously proposed EPSM and SSEF algorithms, which are orig- inally implemented on Intel SSE4.2 (Streaming SIMD Extensions 4.2 version with 128-bit registers). We tune the new algorithms according to Intel AVX2 platform (Advanced Vector Extensions 2 with 256-bit registers) and analyze the gain in performance with respect to the increasing length of the SIMD registers. Profiling the new algorithms by using the Intel Vtune Amplifier for detecting performance bottlenecks led us to consider the cache friendliness and shared-memory access issues in the AVX2 platform. We applied cache op- timization techniques to overcome the problems particularly addressing the search algorithms based on filtering. Experimental comparison of the new solutions with the previously known-to- be-fast algorithms on small, medium, and large alphabet text files with diverse pattern lengths showed that the algorithms on AVX2 platform optimized cache obliviously outperforms the previous solutions. -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

PERL – a Register-Less Processor
PERL { A Register-Less Processor A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by P. Suresh to the Department of Computer Science & Engineering Indian Institute of Technology, Kanpur February, 2004 Certificate Certified that the work contained in the thesis entitled \PERL { A Register-Less Processor", by Mr.P. Suresh, has been carried out under my supervision and that this work has not been submitted elsewhere for a degree. (Dr. Rajat Moona) Professor, Department of Computer Science & Engineering, Indian Institute of Technology, Kanpur. February, 2004 ii Synopsis Computer architecture designs are influenced historically by three factors: market (users), software and hardware methods, and technology. Advances in fabrication technology are the most dominant factor among them. The performance of a proces- sor is defined by a judicious blend of processor architecture, efficient compiler tech- nology, and effective VLSI implementation. The choices for each of these strongly depend on the technology available for the others. Significant gains in the perfor- mance of processors are made due to the ever-improving fabrication technology that made it possible to incorporate architectural novelties such as pipelining, multiple instruction issue, on-chip caches, registers, branch prediction, etc. To supplement these architectural novelties, suitable compiler techniques extract performance by instruction scheduling, code and data placement and other optimizations. The performance of a computer system is directly related to the time it takes to execute programs, usually known as execution time. The expression for execution time (T), is expressed as a product of the number of instructions executed (N), the average number of machine cycles needed to execute one instruction (Cycles Per Instruction or CPI), and the clock cycle time (), as given in equation 1. -

Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University the Intel® 4004 Microprocessor, Introdu
Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University The 1st Microprocessor The Intel® 4004 microprocessor, introduced in November 1971 An electronics revolution that changed our world. There were no customer‐ programmable microprocessors on the market before the 4004. It propelled software into the limelight as a key player in the world of digital electronics design. 4004 Microprocessor Display at New Intel Museum A Japanese calculator maker (Busicom) asked to design: A set of 12 custom logic chips for a line of programmable calculators. Marcian E. "Ted" Hoff Recognized the integrated circuit technology (of the day) had advanced enough to build a single chip, general purpose computer. Federico Faggin to turn Hoff's vision into a silicon reality. (In less than one year, Faggin and his team delivered the 4004, which was introduced in November, 1971.) The world's first microprocessor application was this Busicom calculator. (sold about 100,000 calculators.) Measuring 1/8 inch wide by 1/6 inch long, consisting of 2,300 transistors, Intel’s 4004 microprocessor had as much computing power as the first electronic computer, ENIAC. 2 inch 4004 and 12 inch Core™2 Duo wafer ENIAC, built in 1946, filled 3000‐cubic‐ feet of space and contained 18,000 vacuum tubes. The 4004 microprocessor could execute 60,000 operations per second Running frequency: 108 KHz Founders wanted to name their new company Moore Noyce. However the name sounds very much similar to “more noise”. "Only the paranoid survive". Moore received a B.S. degree in Chemistry from the University of California, Berkeley in 1950 and a Ph.D. -

IBM Powerpc 970 (A.K.A. G5)
IBM PowerPC 970 (a.k.a. G5) Ref 1 David Benham and Yu-Chung Chen UIC – Department of Computer Science CS 466 PPC 970FX overview ● 64-bit RISC ● 58 million transistors ● 512 KB of L2 cache and 96KB of L1 cache ● 90um process with a die size of 65 sq. mm ● Native 32 bit compatibility ● Maximum clock speed of 2.7 Ghz ● SIMD instruction set (Altivec) ● 42 watts @ 1.8 Ghz (1.3 volts) ● Peak data bandwidth of 6.4 GB per second A picture is worth a 2^10 words (approx.) Ref 2 A little history ● PowerPC processor line is a product of the AIM alliance formed in 1991. (Apple, IBM, and Motorola) ● PPC 601 (G1) - 1993 ● PPC 603 (G2) - 1995 ● PPC 750 (G3) - 1997 ● PPC 7400 (G4) - 1999 ● PPC 970 (G5) - 2002 ● AIM alliance dissolved in 2005 Processor Ref 3 Ref 3 Core details ● 16(int)-25(vector) stage pipeline ● Large number of 'in flight' instructions (various stages of execution) - theoretical limit of 215 instructions ● 512 KB L2 cache ● 96 KB L1 cache – 64 KB I-Cache – 32 KB D-Cache Core details continued ● 10 execution units – 2 load/store operations – 2 fixed-point register-register operations – 2 floating-point operations – 1 branch operation – 1 condition register operation – 1 vector permute operation – 1 vector ALU operation ● 32 64 bit general purpose registers, 32 64 bit floating point registers, 32 128 vector registers Pipeline Ref 4 Benchmarks ● SPEC2000 ● BLAST – Bioinformatics ● Amber / jac - Structure biology ● CFD lab code SPEC CPU2000 ● IBM eServer BladeCenter JS20 ● PPC 970 2.2Ghz ● SPECint2000 ● Base: 986 Peak: 1040 ● SPECfp2000 ● Base: 1178 Peak: 1241 ● Dell PowerEdge 1750 Xeon 3.06Ghz ● SPECint2000 ● Base: 1031 Peak: 1067 Apple’s SPEC Results*2 ● SPECfp2000 ● Base: 1030 Peak: 1044 BLAST Ref. -

Design and VHDL Implementation of an Application-Specific Instruction Set Processor
Design and VHDL Implementation of an Application-Specific Instruction Set Processor Lauri Isola School of Electrical Engineering Thesis submitted for examination for the degree of Master of Science in Technology. Espoo 19.12.2019 Supervisor Prof. Jussi Ryynänen Advisor D.Sc. (Tech.) Marko Kosunen Copyright © 2019 Lauri Isola Aalto University, P.O. BOX 11000, 00076 AALTO www.aalto.fi Abstract of the master’s thesis Author Lauri Isola Title Design and VHDL Implementation of an Application-Specific Instruction Set Processor Degree programme Computer, Communication and Information Sciences Major Signal, Speech and Language Processing Code of major ELEC3031 Supervisor Prof. Jussi Ryynänen Advisor D.Sc. (Tech.) Marko Kosunen Date 19.12.2019 Number of pages 66+45 Language English Abstract Open source processors are becoming more popular. They are a cost-effective option in hardware designs, because using the processor does not require an expensive license. However, a limited number of open source processors are still available. This is especially true for Application-Specific Instruction Set Processors (ASIPs). In this work, an ASIP processor was designed and implemented in VHDL hardware description language. The design was based on goals that make the processor easily customizable, and to have a low resource consumption in a System- on-Chip (SoC) design. Finally, the processor was implemented on an FPGA circuit, where it was tested with a specially designed VGA graphics controller. Necessary software tools, such as an assembler were also implemented for the processor. The assembler was used to write comprehensive test programs for testing and verifying the functionality of the processor. This work also examined some future upgrades of the designed processor. -

Computer Architecture Basics
V03: Computer Architecture Basics Prof. Dr. Anton Gunzinger Supercomputing Systems AG Technoparkstrasse 1 8005 Zürich Telefon: 043 – 456 16 00 Email: [email protected] Web: www.scs.ch Supercomputing Systems AG Phone +41 43 456 16 00 Technopark 1 Fax +41 43 456 16 10 8005 Zürich www.scs.ch Computer Architecture Basic 1. Basic Computer Architecture Diagram 2. Basic Computer Architectures 3. Von Neumann versus Harvard Architecture 4. Computer Performance Measurement 5. Technology Trends 2 Zürich 20.09.2019 © by Supercomputing Systems AG CONFIDENTIAL 1.1 Basic Computer Architecture Diagram Sketch the basic computer architecture diagram Describe the functions of the building blocks 3 Zürich 20.09.2019 © by Supercomputing Systems AG CONFIDENTIAL 1.2 Basic Computer Architecture Diagram Describe the execution of a single instruction 5 Zürich 20.09.2019 © by Supercomputing Systems AG CONFIDENTIAL 2 Basic Computer Architecture 2.1 Sketch an Accumulator Machine 2.2 Sketch a Register Machine 2.3 Sketch a Stack Machine 2.4 Sketch the analysis of computing expression in a Stack Machine 2.5 Write the micro program for an Accumulator, a Register and a Stack Machine for the instruction: C:= A + B and estimate the numbers of cycles 2.6 Write the micro program for an Accumulator, a Register and a Stack Machine for the instruction: C:= (A - B)2 + C and estimate the numbers of cycles 2.7 Compare Accumulator, Register and Stack Machine 7 Zürich 20.09.2019 © by Supercomputing Systems AG CONFIDENTIAL 2.1 Accumulator Machine Draw the Accumulator Machine 8 Zürich -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

Comparative Architectures
Comparative Architectures CST Part II, 16 lectures Lent Term 2006 David Greaves [email protected] Slides Lectures 1-13 (C) 2006 IAP + DJG Course Outline 1. Comparing Implementations • Developments fabrication technology • Cost, power, performance, compatibility • Benchmarking 2. Instruction Set Architecture (ISA) • Classic CISC and RISC traits • ISA evolution 3. Microarchitecture • Pipelining • Super-scalar { static & out-of-order • Multi-threading • Effects of ISA on µarchitecture and vice versa 4. Memory System Architecture • Memory Hierarchy 5. Multi-processor systems • Cache coherent and message passing Understanding design tradeoffs 2 Reading material • OHP slides, articles • Recommended Book: John Hennessy & David Patterson, Computer Architecture: a Quantitative Approach (3rd ed.) 2002 Morgan Kaufmann • MIT Open Courseware: 6.823 Computer System Architecture, by Krste Asanovic • The Web http://bwrc.eecs.berkeley.edu/CIC/ http://www.chip-architect.com/ http://www.geek.com/procspec/procspec.htm http://www.realworldtech.com/ http://www.anandtech.com/ http://www.arstechnica.com/ http://open.specbench.org/ • comp.arch News Group 3 Further Reading and Reference • M Johnson Superscalar microprocessor design 1991 Prentice-Hall • P Markstein IA-64 and Elementary Functions 2000 Prentice-Hall • A Tannenbaum, Structured Computer Organization (2nd ed.) 1990 Prentice-Hall • A Someren & C Atack, The ARM RISC Chip, 1994 Addison-Wesley • R Sites, Alpha Architecture Reference Manual, 1992 Digital Press • G Kane & J Heinrich, MIPS RISC Architecture