Miscellaneous Mathematical Symbols-A Range: 27C0–27EF
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tt-Satisfiable
CMPSCI 601: Recall From Last Time Lecture 6 Boolean Syntax: ¡ ¢¤£¦¥¨§¨£ © §¨£ § Boolean variables: A boolean variable represents an atomic statement that may be either true or false. There may be infinitely many of these available. Boolean expressions: £ atomic: , (“top”), (“bottom”) § ! " # $ , , , , , for Boolean expressions Note that any particular expression is a finite string, and thus may use only finitely many variables. £ £ A literal is an atomic expression or its negation: , , , . As you may know, the choice of operators is somewhat arbitary as long as we have a complete set, one that suf- fices to simulate all boolean functions. On HW#1 we ¢ § § ! argued that is already a complete set. 1 CMPSCI 601: Boolean Logic: Semantics Lecture 6 A boolean expression has a meaning, a truth value of true or false, once we know the truth values of all the individual variables. ¢ £ # ¡ A truth assignment is a function ¢ true § false , where is the set of all variables. An as- signment is appropriate to an expression ¤ if it assigns a value to all variables used in ¤ . ¡ The double-turnstile symbol ¥ (read as “models”) de- notes the relationship between a truth assignment and an ¡ ¥ ¤ expression. The statement “ ” (read as “ models ¤ ¤ ”) simply says “ is true under ”. 2 ¡ ¤ ¥ ¤ If is appropriate to , we define when is true by induction on the structure of ¤ : is true and is false for any , £ A variable is true iff says that it is, ¡ ¡ ¡ ¡ " ! ¥ ¤ ¥ ¥ If ¤ , iff both and , ¡ ¡ ¡ ¡ " ¥ ¤ ¥ ¥ If ¤ , iff either or or both, ¡ ¡ ¡ ¡ " # ¥ ¤ ¥ ¥ If ¤ , unless and , ¡ ¡ ¡ ¡ $ ¥ ¤ ¥ ¥ If ¤ , iff and are both true or both false. 3 Definition 6.1 A boolean expression ¤ is satisfiable iff ¡ ¥ ¤ there exists . -

Transport and Map Symbols Range: 1F680–1F6FF
Transport and Map Symbols Range: 1F680–1F6FF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -
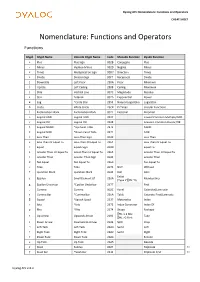
Dyalog APL Binding Strengths
Dyalog APL Nomenclature: Functions and Operators CHEAT SHEET Nomenclature: Functions and Operators Functions Glyph Glyph Name Unicode Glyph Name Code Monadic Function Dyadic Function + Plus Plus Sign 002B Conjugate Plus - Minus Hyphen-Minus 002D Negate Minus × Times Multiplication Sign 00D7 Direction Times ÷ Divide Division Sign 00F7 Reciprocal Divide ⌊ Downstile Left Floor 230A Floor Minimum ⌈ Upstile Left Ceiling 2308 Ceiling Maximum | Stile Vertical Line 007C Magnitude Residue * Star Asterisk 002A Exponential Power ⍟ Log *Circle Star 235F Natural Logarithm Logarithm ○ Circle White Circle 25CB Pi Times Circular Functions ! Exclamation Mark Exclamation Mark 0021 Factorial Binomial ∧ Logical AND Logical AND 2227 Lowest Common Multiple/AND ∨ Logical OR Logical OR 2228 Greatest Common Divisor/OR ⍲ Logical NAND *Up Caret Tilde 2372 NAND ⍱ Logical NOR *Down Caret Tilde 2371 NOR < Less Than Less-Than Sign 003C Less Than ≤ Less Than Or Equal To Less-Than Or Equal To 2264 Less Than Or Equal To = Equal Equals Sign 003D Equal To ≥ Greater Than Or Equal To Great-Than Or Equal To 2265 Greater Than Or Equal To > Greater Than Greater-Than Sign 003E Greater Than ≠ Not Equal Not Equal To 2260 Not Equal To ~ Tilde Tilde 007E NOT Without ? Question Mark Question Mark 003F Roll Deal Enlist ∊ Epsilon Small Element Of 220A Membership (Type if ⎕ML=0) ⍷ Epsilon Underbar *Epsilon Underbar 2377 Find , Comma Comma 002C Ravel Catenate/Laminate ⍪ Comma Bar *Comma Bar 236A Table Catenate First/Laminate ⌷ Squad *Squish Quad 2337 Materialise Index ⍳ Iota *Iota 2373 -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Chapter 9: Initial Theorems About Axiom System
Initial Theorems about Axiom 9 System AS1 1. Theorems in Axiom Systems versus Theorems about Axiom Systems ..................................2 2. Proofs about Axiom Systems ................................................................................................3 3. Initial Examples of Proofs in the Metalanguage about AS1 ..................................................4 4. The Deduction Theorem.......................................................................................................7 5. Using Mathematical Induction to do Proofs about Derivations .............................................8 6. Setting up the Proof of the Deduction Theorem.....................................................................9 7. Informal Proof of the Deduction Theorem..........................................................................10 8. The Lemmas Supporting the Deduction Theorem................................................................11 9. Rules R1 and R2 are Required for any DT-MP-Logic........................................................12 10. The Converse of the Deduction Theorem and Modus Ponens .............................................14 11. Some General Theorems About ......................................................................................15 12. Further Theorems About AS1.............................................................................................16 13. Appendix: Summary of Theorems about AS1.....................................................................18 2 Hardegree, -

The Unicode Standard 5.2 Code Charts
Miscellaneous Technical Range: 2300–23FF The Unicode Standard, Version 5.2 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 5.2. Characters in this chart that are new for The Unicode Standard, Version 5.2 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-5.2/ for charts showing only the characters added in Unicode 5.2. See http://www.unicode.org/Public/5.2.0/charts/ for a complete archived file of character code charts for Unicode 5.2. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 5.2 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 5.2, online at http://www.unicode.org/versions/Unicode5.2.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -

Inference Versus Consequence* Göran Sundholm Leyden University
To appear in LOGICA Yearbook, 1998, Czech Acad. Sc., Prague. Inference versus Consequence* Göran Sundholm Leyden University The following passage, hereinafter "the passage", could have been taken from a modern textbook.1 It is prototypical of current logical orthodoxy: The inference (*) A1, …, Ak. Therefore: C is valid if and only if whenever all the premises A1, …, Ak are true, the conclusion C is true also. When (*) is valid, we also say that C is a logical consequence of A1, …, Ak. We write A1, …, Ak |= C. It is my contention that the passage does not properly capture the nature of inference, since it does not distinguish between valid inference and logical consequence. The view that the validity of inference is reducible to logical consequence has been made famous in our century by Tarski, and also by Wittgenstein in the Tractatus and by Quine, who both reduced valid inference to the logical truth of a suitable implication.2 All three were anticipated by Bolzano.3 Bolzano considered Urteile (judgements) of the form A is true where A is a Satz an sich (proposition in the modern sense).4 Such a judgement is correct (richtig) when the proposition A, that serves as the judgemental content, really is true.5 A correct judgement is an Erkenntnis, that is, a piece of knowledge.6 Similarly, for Bolzano, the general form I of inference * I am indebted to my colleague Dr. E. P. Bos who read an early version of the manuscript and offered valuable comments. 1 Could have been so taken and almost was; cf. -

ISO/IEC JTC1/SC2/WG2 N 2005 Date: 1999-05-29
ISO INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION --------------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 Universal Multiple-Octet Coded Character Set (UCS) -------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 N 2005 Date: 1999-05-29 TITLE: ISO/IEC 10646-1 Second Edition text, Draft 2 SOURCE: Bruce Paterson, project editor STATUS: Working paper of JTC1/SC2/WG2 ACTION: For review and comment by WG2 DISTRIBUTION: Members of JTC1/SC2/WG2 1. Scope This paper provides a second draft of the text sections of the Second Edition of ISO/IEC 10646-1. It replaces the previous paper WG2 N 1796 (1998-06-01). This draft text includes: - Clauses 1 to 27 (replacing the previous clauses 1 to 26), - Annexes A to R (replacing the previous Annexes A to T), and is attached here as “Draft 2 for ISO/IEC 10646-1 : 1999” (pages ii & 1 to 77). Published and Draft Amendments up to Amd.31 (Tibetan extended), Technical Corrigenda nos. 1, 2, and 3, and editorial corrigenda approved by WG2 up to 1999-03-15, have been applied to the text. The draft does not include: - character glyph tables and name tables (these will be provided in a separate WG2 document from AFII), - the alphabetically sorted list of character names in Annex E (now Annex G), - markings to show the differences from the previous draft. A separate WG2 paper will give the editorial corrigenda applied to this text since N 1796. The editorial corrigenda are as agreed at WG2 meetings #34 to #36. Editorial corrigenda applicable to the character glyph tables and name tables, as listed in N1796 pages 2 to 5, have already been applied to the draft character tables prepared by AFII. -

ISO/IEC International Standard 10646-1
ISO/IEC 10646:2003/Amd.6:2009(E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 6: Bamum, Javanese, Lisu, Meetei Mayek, Samaritan, and other characters Page 2, Clause 3, Normative references Click on this highlighted text to access the reference file. Update the reference to the Unicode Bidirectional Algo- NOTE 5 – The content is also available as a separate view- rithm and the Unicode Normalization Forms as follows: able file in the same file directory as this document. The file is named: “CJKU_SR.txt”. Unicode Standard Annex, UAX#9, The Unicode Bidi- rectional Algorithm: Page 25, Clause 29, Named UCS Sequence http://www.unicode.org/reports/tr9/tr9-21.html. Identifiers Unicode Standard Annex, UAX#15, Unicode Normali- Insert the additional 290 sequence identifiers zation Forms: http://www.unicode.org/reports/tr15/tr15-31.html. <0B95, 0BCD> TAMIL CONSONANT K <0B99, 0BCD> TAMIL CONSONANT NG Page 14, Sub-clause 20.3, Format characters <0B9A, 0BCD> TAMIL CONSONANT C <0B9E, 0BCD> TAMIL CONSONANT NY Insert the following entry in the list of formats charac- <0B9F, 0BCD> TAMIL CONSONANT TT ters: <0BA3, 0BCD> TAMIL CONSONANT NN <0BA4, 0BCD> TAMIL CONSONANT T 110BD KAITHI NUMBER SIGN <0BA8, 0BCD> TAMIL CONSONANT N <0BAA, 0BCD> TAMIL CONSONANT P Page 20, Sub-clause 26.1, Hangul syllable <0BAE, 0BCD> TAMIL CONSONANT M composition method <0BAF, 0BCD> TAMIL CONSONANT Y <0BB0, 0BCD> TAMIL CONSONANT R <0BB2, 0BCD> TAMIL CONSONANT L Insert the following note after Note 2. <0BB5, 0BCD> TAMIL CONSONANT V NOTE 3 – Hangul text can be represented in several differ- <0BB4, 0BCD> TAMIL CONSONANT LLL ent ways in this standard. -

Logic and Proof Release 3.18.4
Logic and Proof Release 3.18.4 Jeremy Avigad, Robert Y. Lewis, and Floris van Doorn Sep 10, 2021 CONTENTS 1 Introduction 1 1.1 Mathematical Proof ............................................ 1 1.2 Symbolic Logic .............................................. 2 1.3 Interactive Theorem Proving ....................................... 4 1.4 The Semantic Point of View ....................................... 5 1.5 Goals Summarized ............................................ 6 1.6 About this Textbook ........................................... 6 2 Propositional Logic 7 2.1 A Puzzle ................................................. 7 2.2 A Solution ................................................ 7 2.3 Rules of Inference ............................................ 8 2.4 The Language of Propositional Logic ................................... 15 2.5 Exercises ................................................. 16 3 Natural Deduction for Propositional Logic 17 3.1 Derivations in Natural Deduction ..................................... 17 3.2 Examples ................................................. 19 3.3 Forward and Backward Reasoning .................................... 20 3.4 Reasoning by Cases ............................................ 22 3.5 Some Logical Identities .......................................... 23 3.6 Exercises ................................................. 24 4 Propositional Logic in Lean 25 4.1 Expressions for Propositions and Proofs ................................. 25 4.2 More commands ............................................ -

Iso/Iec Jtc 1/Sc 2 N 3769/Wg2 N2866 Date: 2004-11-12
ISO/IEC JTC 1/SC 2 N 3769/WG2 N2866 DATE: 2004-11-12 ISO/IEC JTC 1/SC 2 Coded Character Sets Secretariat: Japan (JISC) DOC. TYPE Summary of Voting/Table of Replies Summary of Voting on ISO/IEC JTC 1/SC 2 N 3758 : ISO/IEC 14651/FPDAM 2, Information technology -- International string ordering TITLE and comparison -- Method for comparing character strings and description of the common template tailorable ordering -- AMENDMENT 2 SOURCE SC 2 Secretariat PROJECT JTC1.02.14651.00.02 This document is forwarded to Project Editor for resolution of comments. STATUS The Project Editor is requested to prepare a draft disposition of comments report, revised text and a recommendation for further processing. ACTION ID FYI DUE DATE P, O and L Members of ISO/IEC JTC 1/SC 2 ; ISO/IEC JTC 1 Secretariat; DISTRIBUTION ISO/IEC ITTF ACCESS LEVEL Def ISSUE NO. 202 NAME 02n3769.pdf SIZE FILE (KB) 24 PAGES Secretariat ISO/IEC JTC 1/SC 2 - IPSJ/ITSCJ *(Information Processing Society of Japan/Information Technology Standards Commission of Japan) Room 308-3, Kikai-Shinko-Kaikan Bldg., 3-5-8, Shiba-Koen, Minato-ku, Tokyo 105- 0011 Japan *Standard Organization Accredited by JISC Telephone: +81-3-3431-2808; Facsimile: +81-3-3431-6493; E-mail: [email protected] Summary of Voting on ISO/IEC JTC 1/SC 2 N 3758 : ISO/IEC 14651/FPDAM 2, Information technology -- International string ordering and comparison -- Method for comparing character strings and description of the common template tailorable ordering AMENDMENT 2 Q1 : FPDAM Consideration Q1 Not yet Comments Approve