ECE 4750 Computer Architecture Topic 1: Microcoding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Instruction Set Architecture
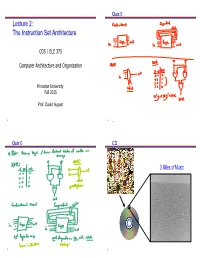
Quiz 0 Lecture 2: The Instruction Set Architecture COS / ELE 375 Computer Architecture and Organization Princeton University Fall 2015 Prof. David August 1 2 Quiz 0 CD 3 Miles of Music 3 4 Pits and Lands Interpretation 0 1 1 1 0 1 0 1 As Music: 011101012 = 117/256 position of speaker As Number: Transition represents a bit state (1/on/red/female/heads) 01110101 = 1 + 4 + 16 + 32 + 64 = 117 = 75 No change represents other state (0/off/white/male/tails) 2 10 16 (Get comfortable with base 2, 8, 10, and 16.) As Text: th 011101012 = 117 character in the ASCII codes = “u” 5 6 Interpretation – ASCII Princeton Computer Science Building West Wall 7 8 Interpretation Binary Code and Data (Hello World!) • Programs consist of Code and Data • Code and Data are Encoded in Bits IA-64 Binary (objdump) As Music: 011101012 = 117/256 position of speaker As Number: 011101012 = 1 + 4 + 16 + 32 + 64 = 11710 = 7516 As Text: th 011101012 = 117 character in the ASCII codes = “u” CAN ALSO BE INTERPRETED AS MACHINE INSTRUCTION! 9 Interfaces in Computer Systems Instructions Sequential Circuit!! Software: Produce Bits Instructing Machine to Manipulate State or Produce I/O Computers process information State Applications • Input/Output (I/O) Operating System • State (memory) • Computation (processor) Compiler Firmware Instruction Set Architecture Input Output Instruction Set Processor I/O System Datapath & Control Computation Digital Design Circuit Design • Instructions instruct processor to manipulate state Layout • Instructions instruct processor to produce I/O in the same way Hardware: Read and Obey Instruction Bits 12 State State – Main Memory Typical modern machine has this architectural state: Main Memory (AKA: RAM – Random Access Memory) 1. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Simple Computer Example Register Structure
Simple Computer Example Register Structure Read pp. 27-85 Simple Computer • To illustrate how a computer operates, let us look at the design of a very simple computer • Specifications 1. Memory words are 16 bits in length 2. 2 12 = 4 K words of memory 3. Memory can be accessed in one clock cycle 4. Single Accumulator for ALU (AC) 5. Registers are fully connected Simple Computer Continued 4K x 16 Memory MAR 12 MDR 16 X PC 12 ALU IR 16 AC Simple Computer Specifications (continued) 6. Control signals • INCPC – causes PC to increment on clock edge - [PC] +1 PC •ACin - causes output of ALU to be stored in AC • GMDR2X – get memory data register to X - [MDR] X • Read (Write) – Read (Write) contents of memory location whose address is in MAR To implement instructions, control unit must break down the instruction into a series of register transfers (just like a complier must break down C program into a series of machine level instructions) Simple Computer (continued) • Typical microinstruction for reading memory State Register Transfer Control Line(s) Next State 1 [[MAR]] MDR Read 2 • Timing State 1 State 2 During State 1, Read set by control unit CLK - Data is read from memory - MDR changes at the Read beginning of State 2 - Read is completed in one clock cycle MDR Simple Computer (continued) • Study: how to write the microinstructions to implement 3 instructions • ADD address • ADD (address) • JMP address ADD address: add using direct addressing 0000 address [AC] + [address] AC ADD (address): add using indirect addressing 0001 address [AC] + [[address]] AC JMP address 0010 address address PC Instruction Format for Simple Computer IR OP 4 AD 12 AD = address - Two phases to implement instructions: 1. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Operating Guide
Operating Guide EPIA-P830 Mainboard EPIA-P830 Operating Guide Table of Contents Table of Contents .......................................................................................................................................................................................... i VIA EPIA-P830 overview.............................................................................................................................................................................1 VIA EPIA-P830 layout ..................................................................................................................................................................................2 VIA EPIA-P830 specifications ...................................................................................................................................................................3 VIA EPIA-P830 processor SKUs ...............................................................................................................................................................4 VIA VX900 chipset overview.....................................................................................................................................................................5 VIA EPIA-P830 and P830-A board dimensions.................................................................................................................................6 VIA P830-B board dimensions.................................................................................................................................................................7 -

PIC Family Microcontroller Lesson 02
Chapter 13 PIC Family Microcontroller Lesson 02 Architecture of PIC 16F877 Internal hardware for the operations in a PIC family MCU direct Internal ID, control, sequencing and reset circuits address 7 14-bit Instruction register 8 MUX program File bus Select 8 Register 14 8 8 W Register (Accumulator) ADDR Status Register MUX Flash Z, C and DC 9 Memory Data Internal EEPROM RAM 13 Peripherals 256 Byte Program Registers counter Ports data 368 Byte 13 bus 2011 Microcontrollers-... 2nd Ed. Raj KamalA to E 3 8-level stack (13-bit) Pearson Education 8 ALU Features • Supports 8-bit operations • Internal data bus is of 8-bits 2011 Microcontrollers-... 2nd Ed. Raj Kamal 4 Pearson Education ALU Features • ALU operations between the Working (W) register (accumulator) and register (or internal RAM) from a register-file • ALU operations can also be between the W and 8-bits operand from instruction register (IR) • The operations also use three flags Z, C and DC/borrow. [Zero flag, Carry flag and digit (nibble) carry flag] 2011 Microcontrollers-... 2nd Ed. Raj Kamal 5 Pearson Education ALU features • The destination of result from ALU operations can be either W or register (f) in file • The flags save at status register (STATUS) • PIC CPU is a one-address machine (one operand specified in the instruction for ALU) 2011 Microcontrollers-... 2nd Ed. Raj Kamal 6 Pearson Education ALU features • Two operands are used in an arithmetic or logic operations • One is source operand from one a register file/RAM (or operand from instruction) and another is W-register • Advantage—ALU directly operates on a register or memory similar to 8086 CPU 2011 Microcontrollers-.. -

A Simple Processor
CS 240251 SpringFall 2019 2020 FoundationsPrinciples of Programming of Computer Languages Systems λ Ben Wood A Simple Processor 1. A simple Instruction Set Architecture 2. A simple microarchitecture (implementation): Data Path and Control Logic https://cs.wellesley.edu/~cs240/s20/ A Simple Processor 1 Program, Application Programming Language Compiler/Interpreter Software Operating System Instruction Set Architecture Microarchitecture Digital Logic Devices (transistors, etc.) Hardware Solid-State Physics A Simple Processor 2 Instruction Set Architecture (HW/SW Interface) processor memory Instructions • Names, Encodings Instruction Encoded • Effects Logic Instructions • Arguments, Results Registers Data Local storage • Names, Size • How many Large storage • Addresses, Locations Computer A Simple Processor 3 Computer Microarchitecture (Implementation of ISA) Instruction Fetch and Registers ALU Memory Decode A Simple Processor 4 (HW = Hardware or Hogwarts?) HW ISA An example made-up instruction set architecture Word size = 16 bits • Register size = 16 bits. • ALU computes on 16-bit values. Memory is byte-addressable, accesses full words (byte pairs). 16 registers: R0 - R15 • R0 always holds hardcoded 0 Address Contents • R1 always holds hardcoded 1 0 First instruction, low-order byte • R2 – R15: general purpose 1 First instruction, Instructions are 1 word in size. high-order byte 2 Second instruction, Separate instruction memory. low-order byte Program Counter (PC) register ... ... • holds address of next instruction to execute. A Simple Processor 5 R: Register File M: Data Memory Reg Contents Reg Contents Address Contents R0 0x0000 R8 0x0 – 0x1 R1 0x0001 R9 0x2 – 0x3 R2 R10 0x4 – 0x5 R3 R11 0x6 – 0x7 R4 R12 0x8 – 0x9 R5 R13 0xA – 0xB R6 R14 0xC – 0xD R7 R15 … Program Counter IM: Instruction Memory PC Address Contents 0x0 – 0x1 ß Processor 1. -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -

Apparecchiature Medicali: Il Ruolo Delle Nanotecnologie
EO Medical APPAreCCHIAture MeDICALI: IL ruoLo DeLLe NANoteCNoLoGIe IN queSto NuMero III Mercati/Attualità VIII Stanford, in fase di sviluppo una ‘pelle elettronica’ X Dialisi direttamente a casa XII Affrontare richieste ad alte prestazioni per la visualizzazione di immagini mediche XIV Criteri di scelta per alimentatori conformi a Iec60601-1 3a edizione XVII News Foto: Future Electronics Murata MEMS Solutions for Medical and Healthcare Enabling MEMS Sensing Improved Care Elements (Dies) SCG12S and SCG14S In medical and healthcare applications Vertical Accelerometer Elements (Dies) Murata’s medical MEMS sensors enable • Size 3mm x 2.12mm x 1.95 or 1.25mm • Various measuring ranges possible (1 - 12g) improved care and a better quality of life • Proven capacitive 3D-MEMS Technology for patients and elderly people. Medical sensors increase the intelligence of life supporting SCG10X and SCG10Z Horizontal Accelerometer Elements (Dies) transplants, and they can be used in new types of patient • Size SCG10X: 2.55mm x 2.95mm x 1.91mm monitoring applications that allow patients to lead more • Size SCG10Z: 1.50mm x 1.70mm x 1.83mm independent lives. Detecting signals triggered by symptoms • Various measuring ranges possible (1 - 12g) • Proven capacitive 3D-MEMS Technology helps optimize medication and prevent serious attacks of illness. Murata’s unique MEMS design, which combines single SCB10H crystal silicon and glass, ensures exceptional reliability, Pressure Sensor Elements (Dies) unprecedented accuracy and excellent stability over time. The • Size 1.4mm x 1.4mm x 0.85mm • High pressure shock survival (> 200 bar) power requirements of these medical sensors are extremely • Various pressure ranges possible (1.2 - 25 bar) low, which gives them a significant advantage in small • Proven capacitive 3D-MEMS technology battery-operated devices. -

PERL – a Register-Less Processor
PERL { A Register-Less Processor A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by P. Suresh to the Department of Computer Science & Engineering Indian Institute of Technology, Kanpur February, 2004 Certificate Certified that the work contained in the thesis entitled \PERL { A Register-Less Processor", by Mr.P. Suresh, has been carried out under my supervision and that this work has not been submitted elsewhere for a degree. (Dr. Rajat Moona) Professor, Department of Computer Science & Engineering, Indian Institute of Technology, Kanpur. February, 2004 ii Synopsis Computer architecture designs are influenced historically by three factors: market (users), software and hardware methods, and technology. Advances in fabrication technology are the most dominant factor among them. The performance of a proces- sor is defined by a judicious blend of processor architecture, efficient compiler tech- nology, and effective VLSI implementation. The choices for each of these strongly depend on the technology available for the others. Significant gains in the perfor- mance of processors are made due to the ever-improving fabrication technology that made it possible to incorporate architectural novelties such as pipelining, multiple instruction issue, on-chip caches, registers, branch prediction, etc. To supplement these architectural novelties, suitable compiler techniques extract performance by instruction scheduling, code and data placement and other optimizations. The performance of a computer system is directly related to the time it takes to execute programs, usually known as execution time. The expression for execution time (T), is expressed as a product of the number of instructions executed (N), the average number of machine cycles needed to execute one instruction (Cycles Per Instruction or CPI), and the clock cycle time (), as given in equation 1. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data