Twitter As an Indicator of Sports Activities in the Helsinki Metropolitan Area
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Application of the Republic of Finland for the Relocation of the European Medicines Agency to Helsinki TABLE of CONTENTS
Application of the Republic of Finland for the relocation of the European Medicines Agency to Helsinki TABLE OF CONTENTS In safe hands 3 A SMOOTH TRANSITION 5 The new location of the European Medicines Agency 7 Continuity and a smooth handover 10 LIFE IN HELSINKI 13 Livable Helsinki 15 Easily accessible 17 Superb and internationally acclaimed education 21 Employment, social security and healthcare 26 A NEW CENTRE OF EXCELLENCE FOR THE PROTECTION OF HUMAN HEALTH 28 A strategic decision – EMA alongside ECHA 30 Helsinki – a hub for the life sciences 32 emahelsinki.fi 2 — Helsinki for EMA In safe hands The most crucial criterion for transferring the European Medicines Agency (EMA) to its new location is the ability to affect a smooth transition. To get the job done. Placing EMA alongside the European Chemicals Agency (ECHA) in Helsinki enhances the EU’s global regulatory competitiveness. Finland, simply stated, is known synergies to create a centre of Finland and the Helsinki region for its capacity to get the job excellence for the protection of possess top class expertise in the done. As a committed EU member human health. life sciences in terms of a high- and in our many roles on the glob- quality talent pool, world-leading al stage – from diplomatic conflict This decision is not a simple research, strong support servic- resolution initiatives to UN Peace- question of competition within es, and functioning networks of keeping missions – we are viewed the EU or among potential host collaboration among academia, as a partner to be entrusted with states. This is a global compe- industry and the public sector. -

Helsinki in Early Twentieth-Century Literature Urban Experiences in Finnish Prose Fiction 1890–1940
lieven ameel Helsinki in Early Twentieth-Century Literature Urban Experiences in Finnish Prose Fiction 1890–1940 Studia Fennica Litteraria The Finnish Literature Society (SKS) was founded in 1831 and has, from the very beginning, engaged in publishing operations. It nowadays publishes literature in the fields of ethnology and folkloristics, linguistics, literary research and cultural history. The first volume of the Studia Fennica series appeared in 1933. Since 1992, the series has been divided into three thematic subseries: Ethnologica, Folkloristica and Linguistica. Two additional subseries were formed in 2002, Historica and Litteraria. The subseries Anthropologica was formed in 2007. In addition to its publishing activities, the Finnish Literature Society maintains research activities and infrastructures, an archive containing folklore and literary collections, a research library and promotes Finnish literature abroad. Studia fennica editorial board Pasi Ihalainen, Professor, University of Jyväskylä, Finland Timo Kaartinen, Title of Docent, Lecturer, University of Helsinki, Finland Taru Nordlund, Title of Docent, Lecturer, University of Helsinki, Finland Riikka Rossi, Title of Docent, Researcher, University of Helsinki, Finland Katriina Siivonen, Substitute Professor, University of Helsinki, Finland Lotte Tarkka, Professor, University of Helsinki, Finland Tuomas M. S. Lehtonen, Secretary General, Dr. Phil., Finnish Literature Society, Finland Tero Norkola, Publishing Director, Finnish Literature Society Maija Hakala, Secretary of the Board, Finnish Literature Society, Finland Editorial Office SKS P.O. Box 259 FI-00171 Helsinki www.finlit.fi Lieven Ameel Helsinki in Early Twentieth- Century Literature Urban Experiences in Finnish Prose Fiction 1890–1940 Finnish Literature Society · SKS · Helsinki Studia Fennica Litteraria 8 The publication has undergone a peer review. The open access publication of this volume has received part funding via a Jane and Aatos Erkko Foundation grant. -

FP7-285556 Safecity Project Deliverable D2.5 Helsinki Public Safety Scenario
FP7‐285556 SafeCity Project Deliverable D2.5 Helsinki Public Safety Scenario Deliverable Type: CO Nature of the Deliverable: R Date: 30.09.2011 Distribution: WP2 Editors: VTT Contributors: VTT, ISDEFE *Deliverable Type: PU= Public, RE= Restricted to a group specified by the Consortium, PP= Restricted to other program participants (including the Commission services), CO= Confidential, only for members of the Consortium (including the Commission services) ** Nature of the Deliverable: P= Prototype, R= Report, S= Specification, T= Tool, O= Other Abstract: This document is an analysis of Helsinki’s public safety characters. It describes the critical infrastructure of Helsinki, discuss its current limitations, and give ideas for the future. D2.5 – HELSINKI PUBLIC SAFETY SCENARIO PROJECT Nº FP7‐ 285556 DISCLAIMER The work associated with this report has been carried out in accordance with the highest technical standards and SafeCity partners have endeavored to achieve the degree of accuracy and reliability appropriate to the work in question. However since the partners have no control over the use to which the information contained within the report is to be put by any other party, any other such party shall be deemed to have satisfied itself as to the suitability and reliability of the information in relation to any particular use, purpose or application. Under no circumstances will any of the partners, their servants, employees or agents accept any liability whatsoever arising out of any error or inaccuracy contained in this report (or any further consolidation, summary, publication or dissemination of the information contained within this report) and/or the connected work and disclaim all liability for any loss, damage, expenses, claims or infringement of third party rights. -
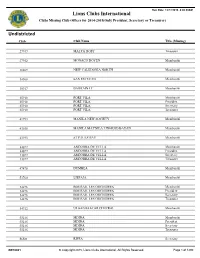
All Clubs Missing Officers 2014-15.Pdf
Run Date: 12/17/2015 8:40:39AM Lions Clubs International Clubs Missing Club Officer for 2014-2015(Only President, Secretary or Treasurer) Undistricted Club Club Name Title (Missing) 27947 MALTA HOST Treasurer 27952 MONACO DOYEN Membershi 30809 NEW CALEDONIA NORTH Membershi 34968 SAN ESTEVAN Membershi 35917 BAHRAIN LC Membershi 35918 PORT VILA Membershi 35918 PORT VILA President 35918 PORT VILA Secretary 35918 PORT VILA Treasurer 41793 MANILA NEW SOCIETY Membershi 43038 MANILA MAYNILA LINGKOD BAYAN Membershi 43193 ST PAULS BAY Membershi 44697 ANDORRA DE VELLA Membershi 44697 ANDORRA DE VELLA President 44697 ANDORRA DE VELLA Secretary 44697 ANDORRA DE VELLA Treasurer 47478 DUMBEA Membershi 53760 LIEPAJA Membershi 54276 BOURAIL LES ORCHIDEES Membershi 54276 BOURAIL LES ORCHIDEES President 54276 BOURAIL LES ORCHIDEES Secretary 54276 BOURAIL LES ORCHIDEES Treasurer 54912 ULAANBAATAR CENTRAL Membershi 55216 MDINA Membershi 55216 MDINA President 55216 MDINA Secretary 55216 MDINA Treasurer 56581 RIFFA Secretary OFF0021 © Copyright 2015, Lions Clubs International, All Rights Reserved. Page 1 of 1290 Run Date: 12/17/2015 8:40:39AM Lions Clubs International Clubs Missing Club Officer for 2014-2015(Only President, Secretary or Treasurer) Undistricted Club Club Name Title (Missing) 57293 RIGA RIGAS LIEPA Membershi 57293 RIGA RIGAS LIEPA President 57293 RIGA RIGAS LIEPA Secretary 57293 RIGA RIGAS LIEPA Treasurer 57378 MINSK CENTRAL Membershi 57378 MINSK CENTRAL President 57378 MINSK CENTRAL Secretary 57378 MINSK CENTRAL Treasurer 59850 DONETSK UNIVERSAL -

Jääpallokirja
JÄÄPALLOKIRJA Suomen Jääpalloliiton 2016 virallinen julkaisu Janne Rintala maajoukkueen keskikenttäpelaaja Sarjaohjelmat Jääpallotietoja Tilastotietoja www.finbandy.fi Pelaamaan pääsevät vain täysi-ikäiset, Veikkauksen tuotoista nauttivat kaikki Tiesithän, että rahapelien ikäraja on Jokaisella aikuisella – vanhemmalla, 18 vuotta? Ikärajalla halutaan varjella huoltajalla, valmentajalla, ohjaajalla – lapsia ja nuoria pelaamisen mahdollisilta on tärkeä rooli näyttää esimerkkiä lieveilmiöiltä, sillä heillä voi olla vääriä vastuullisesta pelaamisesta. uskomuksia pelien ominaisuuksista, voit- Vaikka pelaaminen on sallittua vain tamisen todennäköisyydestä ja omista täysi-ikäisille, Veikkauksen tuotoista taidoistaan. Tutkimusten mukaan nuore- pääsevät nauttimaan kaikki. Kaikkiaan na aloitettu rahapelaaminen kasvattaa veikkausvoittovaroja saa vuosittain noin riskiä peliongelmiin ajautumisesta. 3 000 eri tahoa liikunnassa, taiteessa, Veikkaus huolehtii omalta osaltaan, että tieteessä ja nuorisotyössä. veikkausmyyjät eivät myy pelejä ala- ikäisille ja että veikkaus.fi:hin ei pääse edes rekisteröitymään alle 18-vuotiaana. veikkaus.fi/pelaavastuullisesti Er naturliga bandyleverantör2014 - 2015 4URNAUSMATKA KAUDENPËËTTËJËISET TAKTIIKKAPALAVERI)TËMERENILOISIMMAN LAIVASTONVUOSIENKOKEMUSERILAISTENSPORTTIMATKOJENJËRJESTËMISESSËAUTTAA JOUKKUEENNEMAALIIN*ASPORTTIRYHMILLERËËTËLÚITYEDULLINENHINNASTOMME ONVOIMASSAYMPËRIVUODEN ,ISËTIEDOT(ELSINKI s4URKU www.kosa.ses4AMPERE Ordertel: 0582-152 00 Ordertel: 0582-152 00 vikingline.fi Orderfax: 0582-106 60 Årets -

Helsinki Alueittain 2015 Helsingfors Områdesvis Helsinki by District
Helsingfors stads faktacentral City of Helsinki Urban Facts HELSINKI ALUEITTAIN Helsingfors områdesvis 2015 Helsinki by District Helsingin kaupungin tietokeskus PL 5500, 00099 Helsingin kaupunki, p. 09 310 1612 Helsingfors stads faktacentral PB 5500, 00099 Helsingfors stad, tel. 09 310 1612 City of Helsinki Urban Facts P.O.Box 5500, FI-00099 City of Helsinki, tel. +358 9 310 1612 www.hel.fi/tietokeskus Tilaukset / jakelu p. 09 310 36293 Käteismyynti Tietokeskuksen kirjasto, Siltasaarenk. 18-20 A Beställningar / distribution tel. 09 310 36293 Direktförsäljning Faktacentralens bibliotek, Broholmsgatan 18-20 A Orders / distribution tel. +358 9 310 36293 Direct sales Library, Siltasaarenkatu 18-20 A S-posti / e-mail [email protected] HELSINKI ALUEITTAIN Helsingfors områdesvis 2015 Helsinki by District Helsingin kaupungin tietokeskus Helsingfors stads faktacentral Helsinki City of Helsinki Urban Facts Helsingfors 2016 Julkaisun toimitus Tea Tikkanen Redigering Editors Käännökset Magnus Gräsbeck Översättningar Translations Taitto Petri Berglund Ombrytning General layout Kansi Tarja Sundström-Alku Pärm Cover Tekninen toteutus Otto Burman Tekniskt utförande Tea Tikkanen Technical Editing Pekka Vuori Valokuvat Kansi - Pärm - Cover: Helsingin kaupungin matkailu- ja kongressitoimiston Foton materiaalipankki / Lauri Rotko, Visit Helsinki / Jussi Hellsten Photos Helsingin kaupungin tietokeskus / Raimo Riski Kartat Pohja-aineistot: Kartor © Helsingin kaupunkimittausosasto, alueen kunnat ja HSY, 2014 Maps © Liikennevirasto / Digiroad 2014 -

Lilius, J New Forms of Multi-Local Working: Identifying Multi-Locality in Planning As Well As Public and Private Organizations’ Strategies in the Helsinki Region
This is an electronic reprint of the original article. This reprint may differ from the original in pagination and typographic detail. Lapintie, Kimmo; Di Marino, Mina; Lilius, J New forms of multi-local working: identifying multi-locality in planning as well as public and private organizations’ strategies in the Helsinki region Published in: European Planning Studies DOI: 10.1080/09654313.2018.1504896 Published: 01/01/2018 Document Version Peer reviewed version Please cite the original version: Lapintie, K., Di Marino, M., & Lilius, J. (2018). New forms of multi-local working: identifying multi-locality in planning as well as public and private organizations’ strategies in the Helsinki region. European Planning Studies, 26(10), 2015-2035. https://doi.org/10.1080/09654313.2018.1504896 This material is protected by copyright and other intellectual property rights, and duplication or sale of all or part of any of the repository collections is not permitted, except that material may be duplicated by you for your research use or educational purposes in electronic or print form. You must obtain permission for any other use. Electronic or print copies may not be offered, whether for sale or otherwise to anyone who is not an authorised user. Powered by TCPDF (www.tcpdf.org) New forms of multi-local working: Identifying multi-locality in planning as well as public and private organisations’ strategies in the Helsinki region Mina Di Marino (corresponding author) Arch., Ph.D. in Urban Regional and Environmental Planning Associate Professor Department of Urban and Regional Planning Norwegian University of Life Sciences Faculty of Landscape and Society As, Norway, NO 1432 [email protected] Johanna Lilius, MSc in planning geography PhD in land use planning and Urban Studies Post-doctoral researcher Department of Architecture Aalto University School of Arts, Design and Architecture Miestentie 3, P.O. -

Kävelyllä Tapanilassa Kävelyllä Tapanilassa
Tapanilan Tuuli 46 / 2021 Kävelyllä Tapanilassa Kävelyllä Tapanilassa Tapanila on puutarhanomainen kaupunginosa pääradan varressa. Täällä ovat hienot peruskorjatut talot 1900-luvun alusta lähtien sovussa eri vuosikymmenten kerros-, rivi- ja paritalojen kanssa. On niin omistus-, osaomistus-, asumisoikeus- kuin vuokra-asuntojakin. Kylässä asuu vajaat kymmenentuhatta ihmistä. Koulut ja päiväkodit ovat lähellä. Kirjasto, Kylätila-talo ja puistot ovat kaikkien olohuoneita. Juna vie Helsingin keskustaan 15 ja lentokentälle 12 minuutissa tihein välein. Tapanila ei olisi säilynyt viihtyisänä puutarhakaupunginosana, elleivät kyläläiset olisi nousseet kapinaan kerrostalokaavaa ja leveitä tiesuunnitelmia vastaan Helsingin rakentamisen hulluina vuosina 1960- ja 1970-luvuilla. Tapanila-Seura ry julkaisee vuosittain Tapanila Tuuli -jäsenlehden, jonka teema on tänä vuonna Kävelyllä Tapanilassa. Lehdessä on esitelty 55 kävelykohdetta, joiden kirjoittamiseen on osallistunut 18 henkilöä ja useita kuvaajia. Myös koululaiset ovat olleet mukana tekemässä lehteä. Kävelyllä Tapanilassa -opas johdattaa kulkijat neliapilan lehtien tavoin neljälle eri kierrokselle, kaikkien lähtö- ja paluupisteenä on tori. Kierrosten pysähdyskohteiksi on valittu tärkeitä rakennuksia, tapahtumapaikkoja ja kiintopisteitä, joista on kerrottu faktaa, historiaa ja nykyaikaa kepeällä otteella. Pidempiä kävelyitä kaipaaville on lisäksi kolme lähialueilla sijaitsevaa, kyläläisille tärkeätä kohdetta. Nyt on eletty jo vuosi koronan aiheuttamien rajoitusten mukaan. Kylän tiet on ehkä kävelty -

Helsingin Poikittaislinjaston Kehittämissuunnitelma Luonnos 16.4.2019
Helsingin poikittaislinjaston kehittämissuunnitelma luonnos 16.4.2019 HSL Helsingin seudun liikenne HSL Helsingin seudun liikenne Opastinsilta 6 A PL 100, 00077 HSL00520 Helsinki puhelin (09) 4766 4444 www.hsl.fi Lisätietoja: Harri Vuorinen [email protected] Copyright: Kartat, graafit, ja muut kuvat Kansikuva: HSL / kuvaajan nimi Helsinki 2019 Esipuhe Työ on käynnistynyt syyskuussa 2018 ja ensimmäinen linjastosuunnitelmaluonnos on valmistunut marraskuussa 2018. Lopullisesti työ on valmistunut huhtikuussa 2019. Työtä on ohjannut ohjausryhmä, johon ovat kuuluneet: Jonne Virtanen, pj. HSL Harri Vuorinen HSL Markku Granholm Helsingin kaupunki Suunnittelutyön aikana on ollut avoinna blogi, joka on toiminut asukasvuorovaikutuksen pääkana- vana ja jossa on kerrottu suunnittelutyön etenemisestä. Blogissa asukkaat ovat voineet esittää näkemyksiään suunnittelutyöstä ja antaa palautetta linjastoluonnoksista. Työn yhteydessä on tee- tetty liikkumiskysely, jolla kartoitettiin asukkaiden ja suunnittelualueella liikkuvien liikkumistottumuk- sia ja mielipiteitä joukkoliikenteestä. Lisäksi työn aikana järjestettiin kolme asukastilaisuutta suunni- telmien esittelemiseksi ja palautteen saamiseksi. Työn tekemisestä HSL:ssä ovat vastanneet Harri Vuorinen projektipäällikkönä, Miska Peura, Riikka Sorsa ja Petteri Kantokari. Vaikutusarvioinnit on tehnyt WSP Finland Oy, jossa työstä ovat vastan- neet Samuli Kyytsönen ja Atte Supponen. Tiivistelmäsivu Julkaisija: HSL Helsingin seudun liikenne Tekijät: Harri Vuorinen, Miska Peura, Riikka Sorsa, Petteri Kantokari -

Totta Vai Tarua? Tulot Ja Tulonjako Pääkaupunkiseudulla Vuosina 2000
TASAINEN TULONJAKO – TOttA VAI TARUA? TULOT JA TULONJAKO PÄÄKAUPUNKISEUDULLA VUOSINA 2000-2012 JULKAISIJA Vantaan kaupunki, tietopalveluyksikkö TEKSTIT Harri Sinkko, tietopalveluyksikkö KANSI Sirpa Rönn, tietopalveluyksikkö KANNEN KUVA Harri Sinkko, tietopalveluyksikkö Vantaan kaupunki. Tietopalvelu C4 : 2016 ISSN-L 1799-7011, ISSN 1799-7569 (verkkojulkaisu) ISBN 978-952-443-526-0 Sisällys 1 Johdanto .......................................................................................................................................................................... 2 2 Aineistot ja menetelmät .................................................................................................................................................. 3 2.1 Asuntokuntien kulutusyksikkökohtaiset käytettävissä olevat tulot (ekvivalentit tulot) ............................................ 3 2.2 Elinvaiheittaiset tulot ................................................................................................................................................. 4 2.3 Ginikertoimet ............................................................................................................................................................. 4 2.4 Alueet ......................................................................................................................................................................... 5 2.5 Menetelmät ............................................................................................................................................................... -

Omastadi Budgeting Game an Evaluation Framework for Working Towards More Inclusive Participation Through Design Games
OmaStadi Budgeting Game An evaluation framework for working towards more inclusive participation through design games Andreas Wiberg Sode Master’s Thesis Aalto University Andreas Wiberg Sode OmaStadi Budgeting Game - An evaluation framework for working towards more inclusive participation through design games Master’s Thesis, Master of Arts Supervisor: Teemu Leinonen Advisors: Maria Jaatinen & Mikko Rask New Media Design and Production programme Department of Media School of Arts, Design and Architecture Aalto University, 2020 3 Abstract AUTHOR Andreas Wiberg Sode DEGREE PROGRAMME New Media Design TITLE OF THESIS OmaStadi Budgeting Game - An and Production evaluation framework for working towards more inclusive YEAR 2020 participation through design games NUMBER OF PAGES 102 + 22 DEPARTMENT Department of Media LANGUAGE English Today, the notion of participatory budgeting has been The impact of the game is analysed using five identified goals and implemented in more than 1500 cities worldwide. In Finland, the subsequently examined using three democratic criteria for evaluating City of Helsinki’s new participatory budgeting process, OmaStadi, participatory processes: participation (inclusion), political equality, opens up an annual budget of 4.4 million euros to implement and quality of deliberation. The evaluation results are then used to proposals suggested by citizens. For this process, the city has develop a broader evaluation framework with guidelines for how to developed a design game, the OmaStadi game, to facilitate these plan, implement, and analyse further evaluation of the OmaStadi proposals. The main goal of the game is to make participation game. in OmaStadi more inclusive. Therefore, it is designed to support qualities such as equal participation, improved discussion, creativity, The research findings indicate that the game seemingly supports citizen learning, and city perception. -

LC-Helsinki/Kontula—50 Vuotta Yhdessä Enemmän Arvoisa Lukija, Perherieha-Lehti Jaetaan Noin 15000 Joka Saa Jatkoa Myös Ensi Syksynä
Lions Club Helsinki Kontula 50v d Koko perheen PERHEd perinteinen SUNNUNTAINAd d 5.3.2017 klo 12–15 RIEHAd Keinutien ala-aste, Keinutie 13 d ARPAJAISIA MINIFUTISKENTTÄ d PONIAJELUA d OHJELMALAVALLA ILMAPALLOJA MUSIIKKIA JA d TAIKUUTTA GRILLIMAKKARAA 12.15 ALKAEN SUOSITTU LASTEN • 13.30 musisoivat Dream PEUHANURKKA On Big Band ja Pikku Pandat ONGINTAA • 13.00 ja 13.45 d Taikuri Marcus Alexander VETOKOIRA-AJELUA • 14.15 alkaen Jakomäen ja KASVOMAALAUSTA Kalliolan viihdeorkesterit HEVOSAJELUA • Kuntosalilahjakortin PUFFETTI arvonta 14.45 Marino Swing Cup Team Don Fabio racing AILU – 6 kk treenit Forever ERIKOIS- VIERAAT YLEISÖKILPAILU – 6 kk treenit Forever GSM __________ _____________________ Palkintona 6kk kunto- salitreenitNimi ______________________ ForeverOsoite Myllypurossa.Palkinto ______________ ______________________________________ ________________________________ sisältää kuntosalin lisäksi YLEryhmäliikuntapalveluttomanISÖ lipukepysäköinnin jaK tuo IaikataulunLP setalon Perheriehaan, edessä. mukaisesti, Ikäraja jossa varausoikeuden 15 arvonta vuotta. suoritetaan Ei voida jumppiin vaihtaa 5.3.2017 sekä rahaksi. veloitukset- klo 14:45.Täytä ❆2 LC-Helsinki/Kontula—50 vuotta Yhdessä Enemmän Arvoisa lukija, Perherieha-lehti jaetaan noin 15000 joka saa jatkoa myös ensi syksynä. talouteen Kontula, Kivikko, Kurkimäki ja Vesalan Lisäksi olemme valtakunnallisessa Punainen Sulka keräyksessä omalta alueelle. osaltamme. Kohde on erittäin tärkeä eli nuorten syrjäytyminen. Myös sii- Lehti on ilmestynyt jo yli 20 vuotta ja sen tarkoitus hen