Spatial Variation in House Prices and the Opening of Chicago's Orange
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Green Line Trains Ashland and Clinton: Pink Line
T Free connections between trains Chicago Transit Authority Monday thru Friday Green Line Trains Ashland and Clinton: Pink Line. Clark/Lake: Blue, Brown, Orange, Pink, To Harlem To Ashland/63rd – Cottage Grove Purple lines. Leave Leave Arrive Leave Arrive Arrive Adams/Wabash: Brown, Orange, Pink, Ashland/ Cottage 35th- Adams/ Harlem/ Harlem/ Clark/ 35th- Ashland/ Cottage Purple lines. 63rd Grove Garfi eld Bronzeville Wabash Pulaski Lake Lake Pulaski Lake Bronzeville Garfi eld 63rd Grove Roosevelt: Orange, Red lines. Green Line 3:50 am ----- 4:00 am 4:08 am 4:17 am 4:36 am 4:47 am 4:00 am 4:12 am 4:25 am 4:39 am 4:49 am ----- 4:55 am State/Lake: Red Line (with Farecard only). ----- 4:09 am 4:15 4:23 4:32 4:51 5:02 4:12 4:24 4:37 4:51 5:01 5:10 am ----- 4:20 ----- 4:30 4:38 4:47 5:06 5:17 4:24 4:36 4:49 5:03 5:13 ----- 5:19 ----- 4:39 4:45 4:53 5:02 5:21 5:32 4:36 4:48 5:01 5:15 5:25 5:34 ----- Bikes on Trains 4:50 ----- 5:00 5:08 5:17 5:36 5:47 4:48 5:00 5:13 5:27 5:37 ----- 5:43 Trains ----- 5:09 5:15 5:23 5:32 5:51 6:02 5:00 5:12 5:25 5:39 5:49 5:58 ----- Bicycles are permitted on trains every weekday 5:20 ----- 5:30 5:38 5:47 6:06 6:17 5:10 5:22 5:35 5:50 6:00 ----- 6:06 Effective November 8, 2020 ----- 5:39 5:45 5:53 6:02 6:21 6:32 5:20 5:32 5:45 6:00 6:10 6:19 ----- except from 7:00 a.m. -

Metrarail.Com Transitchicago.Com Route Weekdays Saturday Sunday/Holidays Ticket Information CTA FARES and TICKETS King Drive* Save Over 30%
80708_Millennium 3/7/18 11:27 AM Page 1 CTa First Bus/Last Bus Times: This chart shows approximate first and last bus times between the Metra stations and downtown in the direction Metra riders are most likely to travel. Routes marked with an * extend beyond this area. Buses run every 10 to 20 minutes. All CTA buses are accessible. T metrarail.com transitchicago.com ROUTe WeekDayS SaTURDay SUnDay/HOLIDayS TICkeT InFORMaTIOn CTA FARES AND TICKETS king Drive* Save over 30%. Good for unlimited travel BASE/REGULAR FARES FULL REDUCED STUDENT Michigan/Randolph to Michigan/Chicago 5:20a.m.–12:00a.m. 5:15a.m.–11:55p.m. 6:50a.m.–11:50p.m. Monthly Pass: (deducted from Transit Value in a 3 Michigan/Superior to Michigan/Randolph 5:45a.m.–12:30a.m. 5:35a.m.–12:20a.m. 7:10a.m.–12:10a.m. between the fare zones indicated on the ticket during a calendar Ventra Transit Account) month. The Monthly Pass is valid until noon on the first business 'L' train fare $2.50* $1.25 75¢ day of the following month. The pass is for the exclusive use of Harrison* Bus fare $2.25 $1.10 75¢ Michigan/Van Buren to Harrison/Racine 5:55a.m.–9:55p.m. No Service No Service the purchaser and is not transferable. Refunds are subject to a 7 Harrison/Racine to Michigan/Van Buren 5:45a.m.–9:30p.m. $5 handling fee. Transfer 25¢ 15¢ 15¢ Up to 2 additional rides within 2 hours United Center express* For Bulls and Blackhawks games and concerts, every 15 to 20 minutes, 10-Ride Ticket: 5% savings. -

Brown Line Trains Belmont and Fullerton: Red, Purple Lines
T Free connections between trains Chicago Transit Authority Monday thru Friday Brown Line Trains Belmont and Fullerton: Red, Purple lines. Merchandise Mart: Purple Line To Loop To Kimball Washington/Wells: Orange, Pink, Purple lines. Arrive Leave Harold Washington Library: Orange, Pink, Purple Leave Merchandise Adams/ Adams/ Merchandise Arrive lines. Also, Red, Blue lines (with Farecard only). Kimball Irving Park Belmont Fullerton Mart Wabash Wabash Mart Fullerton Belmont Irving Park Kimball Adams/Wabash: Green, Orange, Pink, Purple lines. Brown Line 4:00 am 4:09 am 4:15 am 4:19 am 4:31 am 4:37 am 4:37 am 4:42 am 4:54 am 4:59 am 5:05 am 5:15 am State/Lake: Red Line (with Farecard only). 4:15 4:24 4:30 4:34 4:46 4:52 4:52 4:57 5:09 5:14 5:20 5:30 4:30 4:39 4:45 4:49 5:01 5:07 5:07 5:12 5:24 5:29 5:35 5:45 Clark/Lake: Blue, Green, Orange, Pink, Purple 4:45 4:54 5:00 5:04 5:16 5:22 5:22 5:27 5:39 5:44 5:50 6:00 lines. Trains 4:58 5:07 5:13 5:17 5:29 5:35 5:35 5:40 5:52 5:57 6:03 6:13 5:10 5:19 5:25 5:29 5:41 5:47 5:47 5:52 6:04 6:09 6:15 6:25 Effective April 25, 2021 then every 10 minutes until 5:57 6:02 6:14 6:19 6:25 6:35 Bikes On Trains 6:07 6:12 6:24 6:29 6:35 6:45 6:20 6:29 6:35 6:39 6:51 6:57 6:12 K 6:17 6:30 6:35 6:41 6:50 6:29 6:38 6:44 6:48 7:01 7:07 6:17 6:22 6:34 6:39 6:45 6:55 Bicycles are permitted on trains every weekday 6:35 6:44 6:50 6:54 7:07 7:13 6:22 K 6:27 6:40 6:45 6:51 7:00 except from 7:00 a.m. -

Chicago Transit Authority (CTA)
06JN023apr 2006.qxp 6/21/2006 12:37 PM Page 1 All Aboard! Detailed Fare Information First Bus / Last Bus Times All CTA and Pace buses are accessible X to people with disabilities. This map gives detailed information about Chicago Transit # ROUTE & TERMINALS WEEKDAYS SATURDAY SUNDAY/HOL. # ROUTE & TERMINALS WEEKDAYS SATURDAY SUNDAY/HOL. # ROUTE & TERMINALS WEEKDAYS SATURDAY SUNDAY/HOL. Authority bus and elevated/subway train service, and shows Type of Fare* Full Reduced Reduced fares are for: You can use this chart to determine days, hours and frequency of service, and Fare Payment Farareboebox Topop where each route begins and ends. BROADWAY DIVISION ILLINOIS CENTER/NORTH WESTERN EXPRESS Pace suburban bus and Metra commuter train routes in the 36 70 Division/Austin east to Division/Clark 4:50a-12:40a 5:05a-12:40a 5:05a-12:40a 122 CASH FARE Accepted on buses only. $2 $1 Devon/Clark south to Polk/Clark 4:00a-12:10a 4:20a-12:00m 4:20a-12:15a Canal/Washington east to Wacker/Columbus 6:40a-9:15a & CTA service area. It is updated twice a year, and available at CTA Children 7 through 11 BUSES: CarCardsds It shows the first and last buses in each direction on each route, traveling Polk/Clark north to Devon/Clark 4:55a-1:20a 4:55a-1:05a 4:50a-1:15a Division/Clark west to Division/Austin 5:30a-1:20a 5:40a-1:20a 5:45a-1:20a 3:40p-6:10p Exact fare (both coins and bills accepted). No cash transfers available. years old. -

Inner Circumferential Commuter Rail Feasibility Study
INNER CIRCUMFERENTIAL COMMUTER RAIL FEASIBILITY STUDY FINAL REPORT and STV Inc. April 1999 Inner Circumferential Commuter Rail Feasibility Study TABLE OF CONTENTS PAGE FOREWORD ............................................................. iii EXECUTIVE SUMMARY ................................................ ES-1 1.0 INTRODUCTION .................................................. 1 2.0 EXISTING CONDITIONS ......................................... 5 2.1 Alignment Options .................................................. 5 2.2 Description of Alignments ............................................ 8 2.3 Land Use and Zoning ................................................ 12 2.4 Potential Station Locations ............................................ 12 2.5 Environmental Issues ................................................ 19 3.0 FUTURE PLANS .................................................. 24 3.1 Demographic and Socioeconomic Characteristics .......................... 24 3.2 Municipal Development Plans. ........................................ 27 3.3 Railroads and Other Agencies .......................................... 34 4.0 POTENTIAL OPERATIONS ...................................... 39 4.1 Option 1: IHB-BRC ................................................. 40 4.2 Option 2 :MDW-BRC. .............................................. 41 4.3 Option 3: WCL-CSX-BRC ........................................... 42 4.4 Option 4: IHB-CCP-BRC ............................................ 43 5.0 CAPITAL IMPROVEMENTS .................................... -

Directions to the Holiday Inn Chicago Mart Plaza
Chicago Transit Authority (CTA) Directions to The Holiday Inn Chicago Mart Plaza From O’Hare International Airport: Take the train Blue Line train from O’Hare International Airport to the Clark/Lake subway station downtown. Blue Line Stops The Clark/Lake station is below ground level, so passengers will need to use stairs, escalator or elevator to ascend to street level. From here, it is approximately a 6-10 minute walk or very short taxi ride to the property: Walking from Clark / Lake CTA stop to Hotel Alternatively, travelers electing not to walk or taxi from the CTA Clark / Lake Blue line station may then board the take the Brown Line CTA train from this station. The Brown Line station at the Clark / Lake stop is elevated, so passengers will need to make their way from the underground subway station to the Brown Line elevated platform toward (Northbound toward Kimball). From here it is only one additional stop to the station servicing the hotel. Passengers should disembark from the Brown Line train at the Merchandise Mart stop. This stop is connected to the Merchandise Mart building. The train platform leads directly into The Merchandise Mart building on its 2nd Floor. The Merchandise Mart’s 2nd Floor connects over Orleans Street via a skybridge into the 2nd Floor of the hotel building. Follow the 2nd Floor , and when you arrive past the skybridge, elevator banks will be straight ahead. Take these elevators up to the 15th Floor, main lobby of the Holiday Inn Chicago Mart Plaza. From Midway International Airport: Take the CTA Orange Line train to the Loop. -
CTA Crime Clusters by ALEX BORDENS | Tribune Graphics Since 2009, More Than 18,000 Crimes Were Reported on the CTA
CTA crime clusters BY ALEX BORDENS | Tribune Graphics Since 2009, more than 18,000 crimes were reported on the CTA. Reports of crime were highest on the rail system, where 38.6 percent of all crimes were reported at rail platforms, though nearly 40 percent of those crimes were riders jumping turnstyles. On the bus system, violent crimes, such as robbery and battery, were clustered on the South and West sides, while thefts were more broadly distributed. Crimes at CTA rail stations From Jan. 1, 2009 to June 13 of this year, 3,943 crimes occurred at CTA stations, of which 38 percent were robberies or thefts. Red, Blue and Green Line stations had the largest number of overall crimes while riders boarding at Brown Line stations west of Southport experienced the least amount of crime. KEY: NUMBER OF CRIMES NOTE: Crimes outside the city boundary not included Jan. 1, 2009 - June 13, 2012 200 100 O’Hare 50 International Blue Line 25 Airport 94 90 Line Red 10 Brown Line KIMBALL LOOP IRVING PARK Stations counted as one: Red Line: State/Lake, Methodology Monroe, Jackson, BELMONT Harrison To conduct this geographic analysis, data from the city of Chicago’s data 90 Blue Line: Clark/Lake, Washington, Monroe, portal was filtered for the location FULLERTON 94 description “CTA Platform.” Data Jackson, LaSalle/Van were further filtered to exclude CICERO Buren, LaSalle deceptive practice incidents, or NORTH Green Line: cases where a rider jumped the Adams/Wabash, turnstyle, then plotted on a map CHICAGO 6 Madison/Wabash, using geographic coordinates Randolph/Wabash, Green Line State/Lake, Clark/Lake included with each record. -

N:\JOE\RTCP\Interim Progress Report\Links\Report Cover.Tif
Final Report Submitted to Regional Transportation Authority REGIONAL TRANSIT COORDINATION PLAN: LOCATION STUDY prepared by BOOZ·ALLEN & HAMILTON INC. in association with WELSH PLANNING July 2001 This report is confidential and intended solely for the use and information of the company to whom it is addressed Table of Contents Disclaimer Page.........................................................................................................................1 Section 1 – Project Summary...................................................................................................2 Section 2 – Study Purpose .......................................................................................................5 Section 3 – Background............................................................................................................7 3.1 Introduction .............................................................................................................7 3.2 Assessment of Transit Coordination ...................................................................8 3.2.1 Physical Coordination.............................................................................9 3.2.2 Service Coordination .............................................................................10 3.2.3 Fare Coordination ..................................................................................10 3.2.4 Information Coordination.....................................................................11 3.2.5 Other Themes and Issues......................................................................13 -

Downtown Transit Account on a Ventra Card Or Attraction Take Bus Or Train: North Michigan Avenue, and a Few Places Beyond
All Aboard! Buses Trains Fares* Quick Ride Guide Chicago Transit Authority This guide will show you how to use Chicago Transit Riding CTA Buses Riding CTA Trains Base/Regular Fares From the Loop 151511 SHERIDIDANAN Deducted from Transit Value in a Ventra Authority (CTA) buses and trains to see Downtown Chicago, CTA buses stop at bus shelters or signs Each rail line has a color name. All trains operate Downtown Transit Account on a Ventra Card or Attraction Take Bus or Train: North Michigan Avenue, and a few places beyond. that look like this. Signs list the service TOTO DEEVO VO NN daily until at least midnight, except the Purple Line Express (see contactless bankcard Full Reduced** Art Institute, Chicago Cultural Ctr. Short walk from most buses and all rail lines days/general hours, route number, name map for hours). Trains run every 7 to 10 minutes during the day ♦ The CTA runs buses and elevated/subway trains (the ‘L’) and destinations, and the direction of travel. and early evening, and every 10 to 15 minutes in later evening. ‘L’ train fare $2.25 $1.10 FirstMerit Bank Pavilion at 146 south on State or 130 (Memorial Day Northerly Island Park weekend thru Labor Day) east on Jackson that serve Chicago and 35 nearby suburbs. From Here’s a quick guide to boarding in the Downtown area: Bus fare† $2 $1 When a bus approaches, look at the sign Chinatown Red Line train (toward 95th/Dan Ryan) Downtown, travel to most attractions on one bus or train. 22 Clark above the windshield. -

Chicago Maps & Transit
CHICAGO MAPS & TRANSIT Airports | Taxis | Bus/Van Charter | Traveling By Car |Easy Public Transportation to and from Chicago http://visitchicagonorthshore.com/visitors_maps.cfm#public Exploring Chicago's North Shore is a breeze! This map was in your post-registration packet Chicago's North Shore is only 30 minutes from O'Hare International Airport and easily accessible from downtown Chicago, Midway Airport, Palwaukee Airport as well as by Amtrak, and the many rail and bus service providers in the Chicago Metropolitan area. Maps on this page allow you to view estimated travel times in the region, an overview of area with major highway routes and maps of the individual communities on the North Shore. Once here, there are numerous ways to explore the North Shore's magnificent surroundings. If you enjoy driving on your own, several local car rental companies service the North Shore as well as a fleet of clean, safe taxicabs and numerous limousine companies with friendly, knowledgeable chauffeurs on staff. And, if public transportation is more your speed, you're sure to find the North Shore's affordable bus and train services easy to navigate and the finest in the country! Whether you're coming or going, quality transportation is one of the North Shore's most valued assets. Airports O'Hare International Airport 773.686.2200 O'Hare International Airport handles more passengers than any other airport in the world. For visitors needing information or directions, airport information booths are located on the lower levels of the domestic terminals and on the upper and lower levels of the International Terminal. -
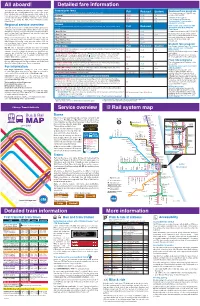
First Bus All Aboard! Rail System Map Detailed Fare in for Ma Tion Service
All aboard! Detailed fare in for ma tion First bus / last bus times This map gives detailed information about Chica go Transit Base/regular fares All CTA and Pace buses are accessible to people with disabilities. # ROUTE & TERMINALS WEEKDAYS SATURDAY SUN./HOL. # ROUTE & TERMINALS WEEKDAYS SATURDAY SUN./HOL. # ROUTE & TERMINALS WEEKDAYS SATURDAY SUN./HOL. Authority bus and el e vat ed/sub way train ser vice, and shows Full Reduced Student Reduced fare program X Pay-per-ride fares, as deducted from value in a Ventra Transit Account Use this chart to determine days, hours of service, where each Pace subur ban bus and Metra commut er train routes in the The following groups are eligible to pay a reduced fare on CTA: CTA ser vice area. It is up dat ed regularly, and avail able at ‘L’ train fare $2.50* $1.25 75¢ route begins and ends, and first and last buses in each direction Wallace/Racine West Lawrence Inner Drive/Michigan Express 44 Racine/87th north to Halsted (Orange) 4:30a-9:40p 8:00a-6:00p 9:00a-6:00p 81W Cumberland (Blue) east to Jeff Park (Blue) 5:25a-10:25p 5:20a-10:20p 8:45a-10:15p 14 6 Berwyn (Red) south to Museum Campus 5:55a-10:40p 6:00a-10:40p 6:00a-10:40p † on each route. X X X CTA rail stations, Metra down town terminals, visitor cen ters, Bus fare $2.25 $1.10 75¢ Children 7 through 11 Halsted (Orange) south to Racine/87th 5:15a-10:25p 8:50a-6:45p 9:45a-6:45p Museum Campus north to Berwyn (Red) 7:00a-11:35p 6:50a-11:40p 6:50a-11:35p X Jeff Park X (Blue) west to Cumberland X (Blue) 4:55a-9:55p 4:50a-9:50p 8:20a-9:50p air ports, or by calling the RTA. -

Chicago Downtown Chicago Connections
Stone Scott Regional Transportation 1 2 3 4 5Sheridan 6 7 8 9 10 11 12 13 14 Dr 270 ter ss C en 619 421 Edens Plaza 213 Division Division ne 272 Lake Authority i ood s 422 Sk 422 u D 423 LaSalle B w 423 Clark/Division e Forest y okie Rd Central 151 a WILMETTE ville s amie 422 The Regional Transportation Authority r P GLENVIEW 800W 600W 200W nonstop between Michigan/Delaware 620 421 0 E/W eehan Preserve Wilmette C Union Pacific/North Line 3rd 143 l Forest Baha’i Temple F e La Elm ollw Green Bay a D vice 4th v Green Glenview Glenview to Waukegan, Kenosha and Stockton/Arlington (2500N) T i lo 210 626 Evanston Elm n (RTA) provides financial oversight, Preserve bard Linden nonstop between Michigan/Delaware e Dewes b 421 146 s Wilmette 221 Dear Milw Foster and Lake Shore/Belmont (3200N) funding, and regional transit planning R Glenview Rd 94 Hi 422 221 i i-State 270 Cedar nonstop between Delaware/Michigan Rand v r Emerson Chicago Downtown Central auk T 70 e Oakton National- Ryan Field & Welsh-Ryan Arena Map Legend Hill 147 r Cook Co 213 and Marine/Foster (5200N) for the three public transit operations Comm ee Louis Univ okie Central Courts k Central 213 93 Maple College 201 Sheridan nonstop between Delaware/Michigan Holy 422 S 148 Old Orchard Gross 206 C Northwestern Univ Hobbie and Marine/Irving Park (4000N) Dee Family yman 270 Point Central St/ CTA Trains Hooker Wendell 22 70 36 Bellevue L in Northeastern Illinois: The Chicago olf Cr Chicago A Harrison 54A 201 Evanston 206 A 8 A W Sheridan Medical 272 egan osby Maple th Central Ser 423 201 k Illinois Center 412 GOLF Westfield Noyes Blue Line Haines Transit Authority (CTA), Metra and Antioch Golf Glen Holocaust 37 208 au 234 D Golf Old Orchard Benson Between O’Hare Airport, Downtown Newberry Oak W Museum Nor to Golf Golf Golf Simpson EVANSTON Oak Research Sherman & Forest Park Oak Pace Suburban bus.