Finding Song Melody Similarities Using a Dna String Matching Algorithm
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Songs by Artist
Reil Entertainment Songs by Artist Karaoke by Artist Title Title &, Caitlin Will 12 Gauge Address In The Stars Dunkie Butt 10 Cc 12 Stones Donna We Are One Dreadlock Holiday 19 Somethin' Im Mandy Fly Me Mark Wills I'm Not In Love 1910 Fruitgum Co Rubber Bullets 1, 2, 3 Redlight Things We Do For Love Simon Says Wall Street Shuffle 1910 Fruitgum Co. 10 Years 1,2,3 Redlight Through The Iris Simon Says Wasteland 1975 10, 000 Maniacs Chocolate These Are The Days City 10,000 Maniacs Love Me Because Of The Night Sex... Because The Night Sex.... More Than This Sound These Are The Days The Sound Trouble Me UGH! 10,000 Maniacs Wvocal 1975, The Because The Night Chocolate 100 Proof Aged In Soul Sex Somebody's Been Sleeping The City 10Cc 1Barenaked Ladies Dreadlock Holiday Be My Yoko Ono I'm Not In Love Brian Wilson (2000 Version) We Do For Love Call And Answer 11) Enid OS Get In Line (Duet Version) 112 Get In Line (Solo Version) Come See Me It's All Been Done Cupid Jane Dance With Me Never Is Enough It's Over Now Old Apartment, The Only You One Week Peaches & Cream Shoe Box Peaches And Cream Straw Hat U Already Know What A Good Boy Song List Generator® Printed 11/21/2017 Page 1 of 486 Licensed to Greg Reil Reil Entertainment Songs by Artist Karaoke by Artist Title Title 1Barenaked Ladies 20 Fingers When I Fall Short Dick Man 1Beatles, The 2AM Club Come Together Not Your Boyfriend Day Tripper 2Pac Good Day Sunshine California Love (Original Version) Help! 3 Degrees I Saw Her Standing There When Will I See You Again Love Me Do Woman In Love Nowhere Man 3 Dog Night P.S. -

Read Book Runaway Horses Pdf Free Download
RUNAWAY HORSES PDF, EPUB, EBOOK Yukio Mishima | 432 pages | 11 Mar 1999 | Vintage Publishing | 9780099282891 | English | London, United Kingdom Solve the Problem of a Runaway Horse - Horse&Rider Retrieved August 2, Archived from the original on October 12, Retrieved November 23, Chart Position". Retrieved Music Canada. Solo Exitos — Ano A Ano. IFPI Sweden. IFPI Switzerland. Hung Medien. British Phonographic Industry. Select albums in the Format field. Select Platinum in the Certification field. Recording Industry Association of America. Retrieved September 8, Book Commons. Namespaces Article Talk. Views Read Edit View history. Help Learn to edit Community portal Recent changes Upload file. Download as PDF Printable version. AOR , pop rock , adult contemporary. Heaven on Earth Runaway Horses Live Your Life Be Free Seidman Vidal. Kelly Sky Steinberg. Munday Stewart. Caffey Carlisle. Austrian Albums Chart [5]. Canadian Album Chart [6]. Dutch Albums Chart [5]. German Albums Chart [7]. In the decadent West people often get together and have all kinds of pointless, speculative conversations. The current political climate being what it is, one subject that frequently comes up, at least amongst my friends, is whether you would be prepared to die for a cause, or an ideal. During these debates my position is unequivocal; my answer is a firm no. Not under any circumstances. My vehemence can, in part, be explained by my cowardice. I am, I freely admit, a rum coward. Yet I do also have philosophical objections. Someone who dies for an ideal is, to me, just a dead idiot, because their ideal, which is necessarily subjective in character, dies with them. -

Lecture 7 Script
1 Lecture 7 Script Stability of Graph Filters to Relative Perturbations Foreword 1. In this lecture, we study the stability of graph filters to relative perturbations. This is work by Alejandro Ribeiro and Fernando Gama. 2. We consider relative perturbations of shift operators such that the difference between the shift operator S and its shifted version S hat is a symmetric additive term of the form E times S plus S times E. 3. The norm of the error matrix in (1) is a measure of how close, S hat and S are. We have seen that graphs that are permutations of each other are equivalent from the perspective of running graph filters. Thus, a more convenient perturbation model is to consider a relationship in which we multiply the left hand side by a permutation matrix P sub zero. 4. We measure the size of the perturbation with the norm of this other error matrix E. We can write a relationship of the form in (2) for any permutation matrix P_0. 5. Naturally, we want to consider the permutation for which the norm of the error is minimized. The bounds we will derive here apply to any pair of shift operators that are related as per (2). They will be tightest however, for the permutation matrix P sub zero for which the nom of the error E is the smallest. Properties of the Perturbation 1. Let's study some properties of the perturbation. 2. There are two aspects of the perturbation matrix E in (2) that are important in seizing its effect on a graph filter. -

Love Ain't Got No Color?
Sayaka Osanami Törngren LOVE AIN'T GOT NO COLOR? – Attitude toward interracial marriage in Sweden Föreliggande doktorsavhandling har producerats inom ramen för forskning och forskarutbildning vid REMESO, Institutionen för Samhälls- och Välfärdsstudier, Linköpings universitet. Samtidigt är den en produkt av forskningen vid IMER/MIM, Malmö högskola och det nära samarbetet mellan REMESO och IMER/MIM. Den publiceras i Linköping Studies in Arts and Science. Vid filosofiska fakulteten vid Linköpings universitet bedrivs forskning och ges forskarutbildning med utgångspunkt från breda problemområden. Forskningen är organiserad i mångvetenskapliga forskningsmiljöer och forskarutbildningen huvudsakligen i forskarskolor. Denna doktorsavhand- ling kommer från REMESO vid Institutionen för Samhälls- och Välfärdsstudier, Linköping Studies in Arts and Science No. 533, 2011. Vid IMER, Internationell Migration och Etniska Relationer, vid Malmö högskola bedrivs flervetenskaplig forskning utifrån ett antal breda huvudtema inom äm- nesområdet. IMER ger tillsammans med MIM, Malmö Institute for Studies of Migration, Diversity and Welfare, ut avhandlingsserien Malmö Studies in International Migration and Ethnic Relations. Denna avhandling är No 10 i avhandlingsserien. Distribueras av: REMESO, Institutionen för Samhälls- och Välfärsstudier, ISV Linköpings universitet, Norrköping SE-60174 Norrköping Sweden Internationell Migration och Etniska Relationer, IMER och Malmö Studies of Migration, Diversity and Welfare, MIM Malmö Högskola SE-205 06 Malmö, Sweden ISSN -

My Bloody Valentine's Loveless David R
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2006 My Bloody Valentine's Loveless David R. Fisher Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF MUSIC MY BLOODY VALENTINE’S LOVELESS By David R. Fisher A thesis submitted to the College of Music In partial fulfillment of the requirements for the degree of Master of Music Degree Awarded: Spring Semester, 2006 The members of the Committee approve the thesis of David Fisher on March 29, 2006. ______________________________ Charles E. Brewer Professor Directing Thesis ______________________________ Frank Gunderson Committee Member ______________________________ Evan Jones Outside Committee M ember The Office of Graduate Studies has verified and approved the above named committee members. ii TABLE OF CONTENTS List of Tables......................................................................................................................iv Abstract................................................................................................................................v 1. THE ORIGINS OF THE SHOEGAZER.........................................................................1 2. A BIOGRAPHICAL ACCOUNT OF MY BLOODY VALENTINE.………..………17 3. AN ANALYSIS OF MY BLOODY VALENTINE’S LOVELESS...............................28 4. LOVELESS AND ITS LEGACY...................................................................................50 BIBLIOGRAPHY..............................................................................................................63 -

Answers to the Top 50 Questions About Genesis, Creation, and Noah's Flood
ANSWERS TO THE TOP 50 QUESTIONS ABOUT GENESIS, CREATION, AND NOAH’S FLOOD Daniel A. Biddle, Ph.D. Copyright © 2018 by Genesis Apologetics, Inc. E-mail: [email protected] www.genesisapologetics.com A 501(c)(3) ministry equipping youth pastors, parents, and students with Biblical answers for evolutionary teaching in public schools. The entire contents of this book (including videos) are available online: www.genesisapologetics.com/faqs Answers to the Top 50 Questions about Genesis, Creation, and Noah’s Flood by Daniel A. Biddle, Ph.D. Printed in the United States of America ISBN-13: 978-1727870305 ISBN-10: 1727870301 All rights reserved solely by the author. The author guarantees all contents are original and do not infringe upon the legal rights of any other person or work. No part of this book may be reproduced in any form without the permission of the author. The views expressed in this book are not necessarily those of the publisher. Scripture taken from the New King James Version®. Copyright © 1982 by Thomas Nelson. Used by permission. All rights reserved. Print Version November 2019 Dedication To my wife, Jenny, who supports me in this work. To my children Makaela, Alyssa, Matthew, and Amanda, and to your children and your children’s children for a hundred generations—this book is for all of you. We would like to acknowledge Answers in Genesis (www.answersingenesis.org), the Institute for Creation Research (www.icr.org), and Creation Ministries International (www.creation.com). Much of the content herein has been drawn from (and is meant to be in alignment with) these Biblical Creation ministries. -

Biography Mark Ronson Is an Internationally Renowned DJ and Five-Time-Grammy-Award-Winning and Golden Globe-Winning Artist and P
Biography Mark Ronson is an internationally renowned DJ and five-time-Grammy-Award-winning and Golden Globe-winning artist and producer. Ronson spent the first eight years of his life growing up in London, England. Having played guitar and drums from an early age, it wasn't until moving to New York City following his parents’ divorce, that he discovered DJ culture. At age 16, and already a fan of artists like A Tribe Called Quest, Run DMC and the Beastie Boys, Ronson began listening to mixtapes released by various hip hop DJs. Inspired, Ronson confiscated his step-father's vinyl collection and tried his hand at mixing. It was the first step in a career highlighted by work on a multi Grammy-winning album by Amy Winehouse, as well as his own Grammy-winning, global smash hit with Bruno Mars, "Uptown Funk." In the late 1990s into the early 2000s, the New York club scene was percolating with booming hip-hop and glitzy R&B. Ronson quickly earned himself a reputation through stints on the decks in downtown clubs before becoming the DJ of choice for many noteworthy parties. Hip-hop mogul Sean "P. Diddy" Combs hired Ronson to DJ his fabled 29th birthday bash. These and other high-profile gigs boosted Ronson's profile and connected him with other artists, many of whom were interested in collaborating. His first production gig came from British soul singer Nikka Costa and he found that his experience of working a club crowd informed his production skills. Fusing his eclectic turntable skills with his knowledge of musical instruments and songwriting, Ronson soon embarked on his first solo record. -

Analýza Nejposlouchanějších Skladeb Na Serveru Youtube.Com
Masarykova univerzita Pedagogická fakulta ANALÝZA NEJPOSLOUCHANĚJŠÍCH SKLADEB NA SERVERU YOUTUBE.COM Bakalářská práce Brno 2017 Autor: Vedoucí bakalářské práce: Jakub Šindelka doc. PhDr. Marek Sedláček, Ph.D. Anotace Název práce: Analýza nejposlouchanějších skladeb na serveru YouTube.com Title: The analysis of the most listened compositions on YouTube.com Tato práce se zabývá analýzou devatenácti nejposlouchanějších hudebních skladeb na serveru YouTube.com, které byly uploadovány v roce 2014 a později. Seznam je aktuální k datu 1. 7. 2016, práce se tedy zabývá skladbami, které byly nejpopulárnější na serveru YouTube od začátku roku 2014 do poloviny roku 2016. U skladeb je zkoumán jejich žánr, délka, tempo, harmonie, struktura a další charakteristiky, práce se zabývá rovněž interprety těchto skladeb a jejich životem, tvorbou a uměleckou kariérou. Závěrečná část práce je věnována vyhodnocení toho, jaké znaky jsou u skladeb nejčastější a nejtypičtější. Okrajově se práce zabývá rovněž historií a principem fungování serveru YouTube. This thesis is focused on the analysis of the nineteen most listened music compositions on YouTube.com, which were uploaded in 2014 or later. The list is relevant to 1. 7. 2016, therefore the point of interest of the thesis are composions, which were the most popular in the period since the beginning of 2014 to the half of 2016. The aspects of compositions which are analyzed are their genre, lenght, tempo, harmony, structure and other characteristics, thesis also tries to comprehend the life, artworks and carrier of interprets of the compositions. The goal of the final part of this thesis is to evaluate which characteristics of the compositions are the most frequent and the most typical ones. -

Beets Documentation Release 1.5.1
beets Documentation Release 1.5.1 Adrian Sampson Oct 01, 2021 Contents 1 Contents 3 1.1 Guides..................................................3 1.2 Reference................................................. 14 1.3 Plugins.................................................. 44 1.4 FAQ.................................................... 120 1.5 Contributing............................................... 125 1.6 For Developers.............................................. 130 1.7 Changelog................................................ 145 Index 213 i ii beets Documentation, Release 1.5.1 Welcome to the documentation for beets, the media library management system for obsessive music geeks. If you’re new to beets, begin with the Getting Started guide. That guide walks you through installing beets, setting it up how you like it, and starting to build your music library. Then you can get a more detailed look at beets’ features in the Command-Line Interface and Configuration references. You might also be interested in exploring the plugins. If you still need help, your can drop by the #beets IRC channel on Libera.Chat, drop by the discussion board, send email to the mailing list, or file a bug in the issue tracker. Please let us know where you think this documentation can be improved. Contents 1 beets Documentation, Release 1.5.1 2 Contents CHAPTER 1 Contents 1.1 Guides This section contains a couple of walkthroughs that will help you get familiar with beets. If you’re new to beets, you’ll want to begin with the Getting Started guide. 1.1.1 Getting Started Welcome to beets! This guide will help you begin using it to make your music collection better. Installing You will need Python. Beets works on Python 3.6 or later. • macOS 11 (Big Sur) includes Python 3.8 out of the box. -
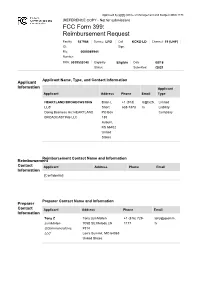
TV Broadcaster Relocation Fund Reimbursement Application
Approved by OMB (Office of Management and Budget) 3060-1178 (REFERENCE COPY - Not for submission) FCC Form 399: Reimbursement Request Facility 187964 Service: LPD Call KCKS-LD Channel: 19 (UHF) ID: Sign: File 0000089941 Number: FRN: 0019530740 Eligibility Eligible Date 08/18 Status: Submitted: /2021 Applicant Name, Type, and Contact Information Applicant Information Applicant Applicant Address Phone Email Type HEARTLAND BROADCASTING Brian L +1 (913) b@tv25. Limited LLC Short 638-7373 tv Liability Doing Business As: HEARTLAND PO Box Company BROADCASTING LLC 130 Auburn, KS 66402 United States Reimbursement Contact Name and Information Reimbursement Contact Applicant Address Phone Email Information [Confidential] Preparer Contact Name and Information Preparer Contact Applicant Address Phone Email Information Tony Z Tony zumMallen +1 (816) 729- tony@qcomm. zumMallen 705B SE Melody LN 1177 tv QCommunications, #314 LLC Lee's Summit, MO 64063 United States Broadcaster Question Response Information Will the station be sharing equipment with No and another broadcast television station or Transition Plan stations (e.g., a shared antenna, co-location on a tower, use of the same transmitter room, multiple transmitters feeding a combiner, etc.)? If yes, enter the facility ID's of the other stations and click 'prefill' to download those stations' licensing information. Briefly describe transition plan Replace the transmitter, line and antenna per the channel reassignment with reasonable and customary engineering and business practices. Transmitters -

Exclusive Behind the Scenes Video of Martin Cohen’S 76Th
Exclusive Behind The Scenes Video Of Martin Cohen’s 76th Birthday Party 2015 Definitely one of the best parties anywhere, every year, I’m always honored to attend and sometimes perform with the band. Here’s some exclusive video. Sadly, I had to leave early, to perform with The Mambo Legends Orch and Tito Nieves at West Gate, which is fortunate for me. Check out the videos as I give a little tour and talk to some special people in attendance including the birthday boy. By Pete Nater Harvey Averne, Producer, Musician and Living Legend Harvey Averne is an American record producer, and the founder of CoCo Records, as well as its many subsidiaries. Established in 1972, CoCo was a label specializing in Afro-Cuban and Latin American Popular music, with special emphasis on the “New York Sound”, commonly referred to as “Salsa”. Averne’s gift for identifying and bringing together new and established musical talent, along with the careful management of his artists’ public image, initially made CoCo Records a major label nationally, and subsequently an international success. Over the next decade, he signed internationally known artists and was instrumental in bringing Latin American music into the American cultural mainstream. Averne personally ran the label from 1972 until 1979. His only rival was Fania Records, the leading Latin music label at the time and for whom Averne had previously been employed. He incorporated his new company (in partnership with Sam Goff, previously of Scepter/Wand Records) and quickly became one of the leading record producers in the Latin music field. -

Manga Vision: Cultural and Communicative Perspectives / Editors: Sarah Pasfield-Neofitou, Cathy Sell; Queenie Chan, Manga Artist
VISION CULTURAL AND COMMUNICATIVE PERSPECTIVES WITH MANGA ARTIST QUEENIE CHAN EDITED BY SARAH PASFIELD-NEOFITOU AND CATHY SELL MANGA VISION MANGA VISION Cultural and Communicative Perspectives EDITED BY SARAH PASFIELD-NEOFITOU AND CATHY SELL WITH MANGA ARTIST QUEENIE CHAN © Copyright 2016 Copyright of this collection in its entirety is held by Sarah Pasfield-Neofitou and Cathy Sell. Copyright of manga artwork is held by Queenie Chan, unless another artist is explicitly stated as its creator in which case it is held by that artist. Copyright of the individual chapters is held by the respective author(s). All rights reserved. Apart from any uses permitted by Australia’s Copyright Act 1968, no part of this book may be reproduced by any process without prior written permission from the copyright owners. Inquiries should be directed to the publisher. Monash University Publishing Matheson Library and Information Services Building 40 Exhibition Walk Monash University Clayton, Victoria 3800, Australia www.publishing.monash.edu Monash University Publishing brings to the world publications which advance the best traditions of humane and enlightened thought. Monash University Publishing titles pass through a rigorous process of independent peer review. www.publishing.monash.edu/books/mv-9781925377064.html Series: Cultural Studies Design: Les Thomas Cover image: Queenie Chan National Library of Australia Cataloguing-in-Publication entry: Title: Manga vision: cultural and communicative perspectives / editors: Sarah Pasfield-Neofitou, Cathy Sell; Queenie Chan, manga artist. ISBN: 9781925377064 (paperback) 9781925377071 (epdf) 9781925377361 (epub) Subjects: Comic books, strips, etc.--Social aspects--Japan. Comic books, strips, etc.--Social aspects. Comic books, strips, etc., in art. Comic books, strips, etc., in education.