An Averaging Estimator for Two Step M Estimation in Semiparametric Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Instrumental Regression in Partially Linear Models
10-167 Research Group: Econometrics and Statistics September, 2009 Instrumental Regression in Partially Linear Models JEAN-PIERRE FLORENS, JAN JOHANNES AND SEBASTIEN VAN BELLEGEM INSTRUMENTAL REGRESSION IN PARTIALLY LINEAR MODELS∗ Jean-Pierre Florens1 Jan Johannes2 Sebastien´ Van Bellegem3 First version: January 24, 2008. This version: September 10, 2009 Abstract We consider the semiparametric regression Xtβ+φ(Z) where β and φ( ) are unknown · slope coefficient vector and function, and where the variables (X,Z) are endogeneous. We propose necessary and sufficient conditions for the identification of the parameters in the presence of instrumental variables. We also focus on the estimation of β. An incorrect parameterization of φ may generally lead to an inconsistent estimator of β, whereas even consistent nonparametric estimators for φ imply a slow rate of convergence of the estimator of β. An additional complication is that the solution of the equation necessitates the inversion of a compact operator that has to be estimated nonparametri- cally. In general this inversion is not stable, thus the estimation of β is ill-posed. In this paper, a √n-consistent estimator for β is derived under mild assumptions. One of these assumptions is given by the so-called source condition that is explicitly interprated in the paper. Finally we show that the estimator achieves the semiparametric efficiency bound, even if the model is heteroscedastic. Monte Carlo simulations demonstrate the reasonable performance of the estimation procedure on finite samples. Keywords: Partially linear model, semiparametric regression, instrumental variables, endo- geneity, ill-posed inverse problem, Tikhonov regularization, root-N consistent estimation, semiparametric efficiency bound JEL classifications: Primary C14; secondary C30 ∗We are grateful to R. -

Nonparametric Statistics for Social and Behavioral Sciences
Statistics Incorporating a hands-on approach, Nonparametric Statistics for Social SOCIAL AND BEHAVIORAL SCIENCES and Behavioral Sciences presents the concepts, principles, and methods NONPARAMETRIC STATISTICS FOR used in performing many nonparametric procedures. It also demonstrates practical applications of the most common nonparametric procedures using IBM’s SPSS software. Emphasizing sound research designs, appropriate statistical analyses, and NONPARAMETRIC accurate interpretations of results, the text: • Explains a conceptual framework for each statistical procedure STATISTICS FOR • Presents examples of relevant research problems, associated research questions, and hypotheses that precede each procedure • Details SPSS paths for conducting various analyses SOCIAL AND • Discusses the interpretations of statistical results and conclusions of the research BEHAVIORAL With minimal coverage of formulas, the book takes a nonmathematical ap- proach to nonparametric data analysis procedures and shows you how they are used in research contexts. Each chapter includes examples, exercises, SCIENCES and SPSS screen shots illustrating steps of the statistical procedures and re- sulting output. About the Author Dr. M. Kraska-Miller is a Mildred Cheshire Fraley Distinguished Professor of Research and Statistics in the Department of Educational Foundations, Leadership, and Technology at Auburn University, where she is also the Interim Director of Research for the Center for Disability Research and Service. Dr. Kraska-Miller is the author of four books on teaching and communications. She has published numerous articles in national and international refereed journals. Her research interests include statistical modeling and applications KRASKA-MILLER of statistics to theoretical concepts, such as motivation; satisfaction in jobs, services, income, and other areas; and needs assessments particularly applicable to special populations. -
![Arxiv:1609.06421V4 [Math.ST] 26 Sep 2019 Semiparametric Identification and Fisher Information∗](https://docslib.b-cdn.net/cover/9452/arxiv-1609-06421v4-math-st-26-sep-2019-semiparametric-identification-and-fisher-information-339452.webp)
Arxiv:1609.06421V4 [Math.ST] 26 Sep 2019 Semiparametric Identification and Fisher Information∗
Semiparametric Identification and Fisher Information∗ Juan Carlos Escanciano† Universidad Carlos III de Madrid September 25th, 2019 Abstract This paper provides a systematic approach to semiparametric identification that is based on statistical information as a measure of its “quality”. Identification can be regular or irregular, depending on whether the Fisher information for the parameter is positive or zero, respectively. I first characterize these cases in models with densities linear in a nonparametric parameter. I then introduce a novel “generalized Fisher information”. If positive, it implies (possibly irregular) identification when other conditions hold. If zero, it implies impossibility results on rates of estimation. Three examples illustrate the applicability of the general results. First, I find necessary conditions for semiparametric regular identification in a structural model for unemployment duration with two spells and nonparametric heterogeneity. Second, I show irregular identification of the median willingness to pay in contingent valuation studies. Finally, I study identification of the discount factor and average measures of risk aversion in a nonparametric Euler Equation with nonparametric measurement error in consumption. Keywords: Identification; Semiparametric Models; Fisher Information. arXiv:1609.06421v4 [math.ST] 26 Sep 2019 JEL classification: C14; C31; C33; C35 ∗First version: September 20th, 2016. †Department of Economics, Universidad Carlos III de Madrid, email: [email protected]. Research funded by the Spanish Programa de Generaci´on de Conocimiento, reference number PGC2018-096732-B-I00. I thank Michael Jansson, Ulrich M¨uller, Whitney Newey, Jack Porter, Pedro Sant’Anna, Ruli Xiao, and seminar par- ticipants at BC, Indiana, MIT, Texas A&M, UBC, Vanderbilt and participants of the 2018 Conference on Identification in Econometrics for useful comments. -

Semiparametric Efficiency
Faculteit Wetenschappen Vakgroep Toegepaste Wiskunde en Informatica Semiparametric Efficiency Karel Vermeulen Prof. Dr. S. Vansteelandt Proefschrift ingediend tot het behalen van de graad van Master in de Wiskunde, afstudeerrichting Toegepaste Wiskunde Academiejaar 2010-2011 To my parents, my brother Lukas To my best friend Sara A mathematical theory is not to be considered complete until you have made it so clear that you can explain it to the first man whom you meet on the street::: David Hilbert Preface My interest in semiparametric theory awoke several years ago, two and a half to be precise. That time, I was in my third year of mathematics. I had to choose a subject for my Bachelor thesis. My decision was: A geometrical approach to the asymptotic efficiency of estimators, based on the monograph by Anastasios Tsiatis, [35], under the supervision of Prof. Dr. Stijn Vansteelandt. In this manner, I entered the world of semiparametric efficiency. However, at that point I did not know it was just the beginning. Shortly after I wrote this Bachelor thesis, Prof. Dr. Stijn Vansteelandt asked me to be involved in research on semiparametric inference for so called probabilistic index models, in the context of a one month student job. Under his guidance, I applied semiparametric estimation theory to this setting and obtained the semiparametric efficiency bound to which efficiency of estimators in this model can be measured. Some results of this research are contained within this thesis. While short, this experience really convinced me I wanted to write a thesis in semiparametric efficiency. That feeling was only more encouraged after following the course Causality and Missing Data, taught by Prof. -

Nonparametric Estimation by Convex Programming
The Annals of Statistics 2009, Vol. 37, No. 5A, 2278–2300 DOI: 10.1214/08-AOS654 c Institute of Mathematical Statistics, 2009 NONPARAMETRIC ESTIMATION BY CONVEX PROGRAMMING By Anatoli B. Juditsky and Arkadi S. Nemirovski1 Universit´eGrenoble I and Georgia Institute of Technology The problem we concentrate on is as follows: given (1) a convex compact set X in Rn, an affine mapping x 7→ A(x), a parametric family {pµ(·)} of probability densities and (2) N i.i.d. observations of the random variable ω, distributed with the density pA(x)(·) for some (unknown) x ∈ X, estimate the value gT x of a given linear form at x. For several families {pµ(·)} with no additional assumptions on X and A, we develop computationally efficient estimation routines which are minimax optimal, within an absolute constant factor. We then apply these routines to recovering x itself in the Euclidean norm. 1. Introduction. The problem we are interested in is essentially as fol- lows: suppose that we are given a convex compact set X in Rn, an affine mapping x A(x) and a parametric family pµ( ) of probability densities. Suppose that7→N i.i.d. observations of the random{ variable· } ω, distributed with the density p ( ) for some (unknown) x X, are available. Our objective A(x) · ∈ is to estimate the value gT x of a given linear form at x. In nonparametric statistics, there exists an immense literature on various versions of this problem (see, e.g., [10, 11, 12, 13, 15, 17, 18, 21, 22, 23, 24, 25, 26, 27, 28] and the references therein). -

Repeated-Measures ANOVA & Friedman Test Using STATCAL
Repeated-Measures ANOVA & Friedman Test Using STATCAL (R) & SPSS Prana Ugiana Gio Download STATCAL in www.statcal.com i CONTENT 1.1 Example of Case 1.2 Explanation of Some Book About Repeated-Measures ANOVA 1.3 Repeated-Measures ANOVA & Friedman Test 1.4 Normality Assumption and Assumption of Equality of Variances (Sphericity) 1.5 Descriptive Statistics Based On SPSS dan STATCAL (R) 1.6 Normality Assumption Test Using Kolmogorov-Smirnov Test Based on SPSS & STATCAL (R) 1.7 Assumption Test of Equality of Variances Using Mauchly Test Based on SPSS & STATCAL (R) 1.8 Repeated-Measures ANOVA Based on SPSS & STATCAL (R) 1.9 Multiple Comparison Test Using Boferroni Test Based on SPSS & STATCAL (R) 1.10 Friedman Test Based on SPSS & STATCAL (R) 1.11 Multiple Comparison Test Using Wilcoxon Test Based on SPSS & STATCAL (R) ii 1.1 Example of Case For example given data of weight of 11 persons before and after consuming medicine of diet for one week, two weeks, three weeks and four week (Table 1.1.1). Tabel 1.1.1 Data of Weight of 11 Persons Weight Name Before One Week Two Weeks Three Weeks Four Weeks A 89.43 85.54 80.45 78.65 75.45 B 85.33 82.34 79.43 76.55 71.35 C 90.86 87.54 85.45 80.54 76.53 D 91.53 87.43 83.43 80.44 77.64 E 90.43 84.45 81.34 78.64 75.43 F 90.52 86.54 85.47 81.44 78.64 G 87.44 83.34 80.54 78.43 77.43 H 89.53 86.45 84.54 81.35 78.43 I 91.34 88.78 85.47 82.43 78.76 J 88.64 84.36 80.66 78.65 77.43 K 89.51 85.68 82.68 79.71 76.5 Average 89.51 85.68 82.68 79.71 76.69 Based on Table 1.1.1: The person whose name is A has initial weight 89,43, after consuming medicine of diet for one week 85,54, two weeks 80,45, three weeks 78,65 and four weeks 75,45. -

Efficient Estimation in Single Index Models Through Smoothing Splines
arXiv: 1612.00068 Efficient Estimation in Single Index Models through Smoothing splines Arun K. Kuchibhotla and Rohit K. Patra University of Pennsylvania and University of Florida e-mail: [email protected]; [email protected] Abstract: We consider estimation and inference in a single index regression model with an unknown but smooth link function. In contrast to the standard approach of using kernels or regression splines, we use smoothing splines to estimate the smooth link function. We develop a method to compute the penalized least squares estimators (PLSEs) of the para- metric and the nonparametric components given independent and identically distributed (i.i.d.) data. We prove the consistency and find the rates of convergence of the estimators. We establish asymptotic normality under under mild assumption and prove asymptotic effi- ciency of the parametric component under homoscedastic errors. A finite sample simulation corroborates our asymptotic theory. We also analyze a car mileage data set and a Ozone concentration data set. The identifiability and existence of the PLSEs are also investigated. Keywords and phrases: least favorable submodel, penalized least squares, semiparamet- ric model. 1. Introduction Consider a regression model where one observes i.i.d. copies of the predictor X ∈ Rd and the response Y ∈ R and is interested in estimating the regression function E(Y |X = ·). In nonpara- metric regression E(Y |X = ·) is generally assumed to satisfy some smoothness assumptions (e.g., twice continuously differentiable), but no assumptions are made on the form of dependence on X. While nonparametric models offer flexibility in modeling, the price for this flexibility can be high for two main reasons: the estimation precision decreases rapidly as d increases (“curse of dimensionality”) and the estimator can be hard to interpret when d > 1. -
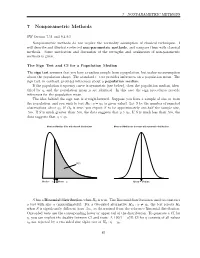
7 Nonparametric Methods
7 NONPARAMETRIC METHODS 7 Nonparametric Methods SW Section 7.11 and 9.4-9.5 Nonparametric methods do not require the normality assumption of classical techniques. I will describe and illustrate selected non-parametric methods, and compare them with classical methods. Some motivation and discussion of the strengths and weaknesses of non-parametric methods is given. The Sign Test and CI for a Population Median The sign test assumes that you have a random sample from a population, but makes no assumption about the population shape. The standard t−test provides inferences on a population mean. The sign test, in contrast, provides inferences about a population median. If the population frequency curve is symmetric (see below), then the population median, iden- tified by η, and the population mean µ are identical. In this case the sign procedures provide inferences for the population mean. The idea behind the sign test is straightforward. Suppose you have a sample of size m from the population, and you wish to test H0 : η = η0 (a given value). Let S be the number of sampled observations above η0. If H0 is true, you expect S to be approximately one-half the sample size, .5m. If S is much greater than .5m, the data suggests that η > η0. If S is much less than .5m, the data suggests that η < η0. Mean and Median differ with skewed distributions Mean and Median are the same with symmetric distributions 50% Median = η Mean = µ Mean = Median S has a Binomial distribution when H0 is true. The Binomial distribution is used to construct a test with size α (approximately). -

9 Blocked Designs
9 Blocked Designs 9.1 Friedman's Test 9.1.1 Application 1: Randomized Complete Block Designs • Assume there are k treatments of interest in an experiment. In Section 8, we considered the k-sample Extension of the Median Test and the Kruskal-Wallis Test to test for any differences in the k treatment medians. • Suppose the experimenter is still concerned with studying the effects of a single factor on a response of interest, but variability from another factor that is not of interest is expected. { Suppose a researcher wants to study the effect of 4 fertilizers on the yield of cotton. The researcher also knows that the soil conditions at the 8 areas for performing an experiment are highly variable. Thus, the researcher wants to design an experiment to detect any differences among the 4 fertilizers on the cotton yield in the presence a \nuisance variable" not of interest (the 8 areas). • Because experimental units can vary greatly with respect to physical characteristics that can also influence the response, the responses from experimental units that receive the same treatment can also vary greatly. • If it is not controlled or accounted for in the data analysis, it can can greatly inflate the experimental variability making it difficult to detect real differences among the k treatments of interest (large Type II error). • If this source of variability can be separated from the treatment effects and the random experimental error, then the sensitivity of the experiment to detect real differences between treatments in increased (i.e., lower the Type II error). • Therefore, the goal is to choose an experimental design in which it is possible to control the effects of a variable not of interest by bringing experimental units that are similar into a group called a \block". -

Introduction to Empirical Processes and Semiparametric Inference1
This is page i Printer: Opaque this Introduction to Empirical Processes and Semiparametric Inference1 Michael R. Kosorok August 2006 1c 2006 SPRINGER SCIENCE+BUSINESS MEDIA, INC. All rights re- served. Permission is granted to print a copy of this preliminary version for non- commercial purposes but not to distribute it in printed or electronic form. The author would appreciate notification of typos and other suggestions for improve- ment. ii This is page iii Printer: Opaque this Preface The goal of this book is to introduce statisticians, and other researchers with a background in mathematical statistics, to empirical processes and semiparametric inference. These powerful research techniques are surpris- ingly useful for studying large sample properties of statistical estimates from realistically complex models as well as for developing new and im- proved approaches to statistical inference. This book is more a textbook than a research monograph, although some new results are presented in later chapters. The level of the book is more introductory than the seminal work of van der Vaart and Wellner (1996). In fact, another purpose of this work is to help readers prepare for the mathematically advanced van der Vaart and Wellner text, as well as for the semiparametric inference work of Bickel, Klaassen, Ritov and Wellner (1997). These two books, along with Pollard (1990) and chapters 19 and 25 of van der Vaart (1998), formulate a very complete and successful elucida- tion of modern empirical process methods. The present book owes much by the way of inspiration, concept, and notation to these previous works. What is perhaps new is the introductory, gradual and unified way this book introduces the reader to the field. -

Variable Selection in Semiparametric Regression Modeling
The Annals of Statistics 2008, Vol. 36, No. 1, 261–286 DOI: 10.1214/009053607000000604 c Institute of Mathematical Statistics, 2008 VARIABLE SELECTION IN SEMIPARAMETRIC REGRESSION MODELING By Runze Li1 and Hua Liang2 Pennsylvania State University and University of Rochester In this paper, we are concerned with how to select significant vari- ables in semiparametric modeling. Variable selection for semipara- metric regression models consists of two components: model selection for nonparametric components and selection of significant variables for the parametric portion. Thus, semiparametric variable selection is much more challenging than parametric variable selection (e.g., linear and generalized linear models) because traditional variable selection procedures including stepwise regression and the best subset selection now require separate model selection for the nonparametric compo- nents for each submodel. This leads to a very heavy computational burden. In this paper, we propose a class of variable selection proce- dures for semiparametric regression models using nonconcave penal- ized likelihood. We establish the rate of convergence of the resulting estimate. With proper choices of penalty functions and regulariza- tion parameters, we show the asymptotic normality of the resulting estimate and further demonstrate that the proposed procedures per- form as well as an oracle procedure. A semiparametric generalized likelihood ratio test is proposed to select significant variables in the nonparametric component. We investigate the asymptotic behavior of the proposed test and demonstrate that its limiting null distri- bution follows a chi-square distribution which is independent of the nuisance parameters. Extensive Monte Carlo simulation studies are conducted to examine the finite sample performance of the proposed variable selection procedures. -

1 Exercise 8: an Introduction to Descriptive and Nonparametric
1 Exercise 8: An Introduction to Descriptive and Nonparametric Statistics Elizabeth M. Jakob and Marta J. Hersek Goals of this lab 1. To understand why statistics are used 2. To become familiar with descriptive statistics 1. To become familiar with nonparametric statistical tests, how to conduct them, and how to choose among them 2. To apply this knowledge to sample research questions Background If we are very fortunate, our experiments yield perfect data: all the animals in one treatment group behave one way, and all the animals in another treatment group behave another way. Usually our results are not so clear. In addition, even if we do get results that seem definitive, there is always a possibility that they are a result of chance. Statistics enable us to objectively evaluate our results. Descriptive statistics are useful for exploring, summarizing, and presenting data. Inferential statistics are used for interpreting data and drawing conclusions about our hypotheses. Descriptive statistics include the mean (average of all of the observations; see Table 8.1), mode (most frequent data class), and median (middle value in an ordered set of data). The variance, standard deviation, and standard error are measures of deviation from the mean (see Table 8.1). These statistics can be used to explore your data before going on to inferential statistics, when appropriate. In hypothesis testing, a variety of statistical tests can be used to determine if the data best fit our null hypothesis (a statement of no difference) or an alternative hypothesis. More specifically, we attempt to reject one of these hypotheses.