Parametric Versus Semi and Nonparametric Regression Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Instrumental Regression in Partially Linear Models
10-167 Research Group: Econometrics and Statistics September, 2009 Instrumental Regression in Partially Linear Models JEAN-PIERRE FLORENS, JAN JOHANNES AND SEBASTIEN VAN BELLEGEM INSTRUMENTAL REGRESSION IN PARTIALLY LINEAR MODELS∗ Jean-Pierre Florens1 Jan Johannes2 Sebastien´ Van Bellegem3 First version: January 24, 2008. This version: September 10, 2009 Abstract We consider the semiparametric regression Xtβ+φ(Z) where β and φ( ) are unknown · slope coefficient vector and function, and where the variables (X,Z) are endogeneous. We propose necessary and sufficient conditions for the identification of the parameters in the presence of instrumental variables. We also focus on the estimation of β. An incorrect parameterization of φ may generally lead to an inconsistent estimator of β, whereas even consistent nonparametric estimators for φ imply a slow rate of convergence of the estimator of β. An additional complication is that the solution of the equation necessitates the inversion of a compact operator that has to be estimated nonparametri- cally. In general this inversion is not stable, thus the estimation of β is ill-posed. In this paper, a √n-consistent estimator for β is derived under mild assumptions. One of these assumptions is given by the so-called source condition that is explicitly interprated in the paper. Finally we show that the estimator achieves the semiparametric efficiency bound, even if the model is heteroscedastic. Monte Carlo simulations demonstrate the reasonable performance of the estimation procedure on finite samples. Keywords: Partially linear model, semiparametric regression, instrumental variables, endo- geneity, ill-posed inverse problem, Tikhonov regularization, root-N consistent estimation, semiparametric efficiency bound JEL classifications: Primary C14; secondary C30 ∗We are grateful to R. -

Parametric Models
An Introduction to Event History Analysis Oxford Spring School June 18-20, 2007 Day Two: Regression Models for Survival Data Parametric Models We’ll spend the morning introducing regression-like models for survival data, starting with fully parametric (distribution-based) models. These tend to be very widely used in social sciences, although they receive almost no use outside of that (e.g., in biostatistics). A General Framework (That Is, Some Math) Parametric models are continuous-time models, in that they assume a continuous parametric distribution for the probability of failure over time. A general parametric duration model takes as its starting point the hazard: f(t) h(t) = (1) S(t) As we discussed yesterday, the density is the probability of the event (at T ) occurring within some differentiable time-span: Pr(t ≤ T < t + ∆t) f(t) = lim . (2) ∆t→0 ∆t The survival function is equal to one minus the CDF of the density: S(t) = Pr(T ≥ t) Z t = 1 − f(t) dt 0 = 1 − F (t). (3) This means that another way of thinking of the hazard in continuous time is as a conditional limit: Pr(t ≤ T < t + ∆t|T ≥ t) h(t) = lim (4) ∆t→0 ∆t i.e., the conditional probability of the event as ∆t gets arbitrarily small. 1 A General Parametric Likelihood For a set of observations indexed by i, we can distinguish between those which are censored and those which aren’t... • Uncensored observations (Ci = 1) tell us both about the hazard of the event, and the survival of individuals prior to that event. -
![Arxiv:1609.06421V4 [Math.ST] 26 Sep 2019 Semiparametric Identification and Fisher Information∗](https://docslib.b-cdn.net/cover/9452/arxiv-1609-06421v4-math-st-26-sep-2019-semiparametric-identification-and-fisher-information-339452.webp)
Arxiv:1609.06421V4 [Math.ST] 26 Sep 2019 Semiparametric Identification and Fisher Information∗
Semiparametric Identification and Fisher Information∗ Juan Carlos Escanciano† Universidad Carlos III de Madrid September 25th, 2019 Abstract This paper provides a systematic approach to semiparametric identification that is based on statistical information as a measure of its “quality”. Identification can be regular or irregular, depending on whether the Fisher information for the parameter is positive or zero, respectively. I first characterize these cases in models with densities linear in a nonparametric parameter. I then introduce a novel “generalized Fisher information”. If positive, it implies (possibly irregular) identification when other conditions hold. If zero, it implies impossibility results on rates of estimation. Three examples illustrate the applicability of the general results. First, I find necessary conditions for semiparametric regular identification in a structural model for unemployment duration with two spells and nonparametric heterogeneity. Second, I show irregular identification of the median willingness to pay in contingent valuation studies. Finally, I study identification of the discount factor and average measures of risk aversion in a nonparametric Euler Equation with nonparametric measurement error in consumption. Keywords: Identification; Semiparametric Models; Fisher Information. arXiv:1609.06421v4 [math.ST] 26 Sep 2019 JEL classification: C14; C31; C33; C35 ∗First version: September 20th, 2016. †Department of Economics, Universidad Carlos III de Madrid, email: [email protected]. Research funded by the Spanish Programa de Generaci´on de Conocimiento, reference number PGC2018-096732-B-I00. I thank Michael Jansson, Ulrich M¨uller, Whitney Newey, Jack Porter, Pedro Sant’Anna, Ruli Xiao, and seminar par- ticipants at BC, Indiana, MIT, Texas A&M, UBC, Vanderbilt and participants of the 2018 Conference on Identification in Econometrics for useful comments. -

Semiparametric Efficiency
Faculteit Wetenschappen Vakgroep Toegepaste Wiskunde en Informatica Semiparametric Efficiency Karel Vermeulen Prof. Dr. S. Vansteelandt Proefschrift ingediend tot het behalen van de graad van Master in de Wiskunde, afstudeerrichting Toegepaste Wiskunde Academiejaar 2010-2011 To my parents, my brother Lukas To my best friend Sara A mathematical theory is not to be considered complete until you have made it so clear that you can explain it to the first man whom you meet on the street::: David Hilbert Preface My interest in semiparametric theory awoke several years ago, two and a half to be precise. That time, I was in my third year of mathematics. I had to choose a subject for my Bachelor thesis. My decision was: A geometrical approach to the asymptotic efficiency of estimators, based on the monograph by Anastasios Tsiatis, [35], under the supervision of Prof. Dr. Stijn Vansteelandt. In this manner, I entered the world of semiparametric efficiency. However, at that point I did not know it was just the beginning. Shortly after I wrote this Bachelor thesis, Prof. Dr. Stijn Vansteelandt asked me to be involved in research on semiparametric inference for so called probabilistic index models, in the context of a one month student job. Under his guidance, I applied semiparametric estimation theory to this setting and obtained the semiparametric efficiency bound to which efficiency of estimators in this model can be measured. Some results of this research are contained within this thesis. While short, this experience really convinced me I wanted to write a thesis in semiparametric efficiency. That feeling was only more encouraged after following the course Causality and Missing Data, taught by Prof. -

Nonparametric Regression 1 Introduction
Nonparametric Regression 10/36-702 Larry Wasserman 1 Introduction Now we focus on the following problem: Given a sample (X1;Y1);:::,(Xn;Yn), where d Xi 2 R and Yi 2 R, estimate the regression function m(x) = E(Y jX = x) (1) without making parametric assumptions (such as linearity) about the regression function m(x). Estimating m is called nonparametric regression or smoothing. We can write Y = m(X) + where E() = 0. This follows since, = Y − m(X) and E() = E(E(jX)) = E(m(X) − m(X)) = 0 A related problem is nonparametric prediction. Given a pair (X; Y ), we want to predict Y from X. The optimal predictor (under squared error loss) is the regression function m(X). Hence, estimating m is of interest for its own sake and for the purposes of prediction. Example 1 Figure 1 shows data on bone mineral density. The plots show the relative change in bone density over two consecutive visits, for men and women. The smooth estimates of the regression functions suggest that a growth spurt occurs two years earlier for females. In this example, Y is change in bone mineral density and X is age. Example 2 Figure 2 shows an analysis of some diabetes data from Efron, Hastie, Johnstone and Tibshirani (2004). The outcome Y is a measure of disease progression after one year. We consider four covariates (ignoring for now, six other variables): age, bmi (body mass index), and two variables representing blood serum measurements. A nonparametric regression model in this case takes the form Y = m(x1; x2; x3; x4) + . -

Nonparametric Regression with Complex Survey Data
CHAPTER 11 NONPARAMETRIC REGRESSION WITH COMPLEX SURVEY DATA R. L. Chambers Department of Social Statistics University of Southampton A.H. Dorfman Office of Survey Methods Research Bureau of Labor Statistics M.Yu. Sverchkov Department of Statistics Hebrew University of Jerusalem June 2002 11.1 Introduction The problem considered here is one familiar to analysts carrying out exploratory data analysis (EDA) of data obtained via a complex sample survey design. How does one adjust for the effects, if any, induced by the method of sampling used in the survey when applying EDA methods to these data? In particular, are adjustments to standard EDA methods necessary when the analyst's objective is identification of "interesting" population (rather than sample) structures? A variety of methods for adjusting for complex sample design when carrying out parametric inference have been suggested. See, for example, SHS, Pfeffermann (1993) and Breckling et al (1994). However, comparatively little work has been done to date on extending these ideas to EDA, where a parametric formulation of the problem is typically inappropriate. We focus on a popular EDA technique, nonparametric regression or scatterplot smoothing. The literature contains a limited number of applications of this type of analysis to survey data, usually based on some form of sample weighting. The design-based theory set out in chapter 10, with associated references, provides an introduction to this work. See also Chesher (1997). The approach taken here is somewhat different. In particular, it is model-based, building on the sample distribution concept discussed in section 2.3. Here we develop this idea further, using it to motivate a number of methods for adjusting for the effect of a complex sample design when estimating a population regression function. -

Nonparametric Bayesian Inference
Nonparametric Bayesian Methods 1 What is Nonparametric Bayes? In parametric Bayesian inference we have a model M = ff(yjθ): θ 2 Θg and data Y1;:::;Yn ∼ f(yjθ). We put a prior distribution π(θ) on the parameter θ and compute the posterior distribution using Bayes' rule: L (θ)π(θ) π(θjY ) = n (1) m(Y ) Q where Y = (Y1;:::;Yn), Ln(θ) = i f(Yijθ) is the likelihood function and n Z Z Y m(y) = m(y1; : : : ; yn) = f(y1; : : : ; ynjθ)π(θ)dθ = f(yijθ)π(θ)dθ i=1 is the marginal distribution for the data induced by the prior and the model. We call m the induced marginal. The model may be summarized as: θ ∼ π Y1;:::;Ynjθ ∼ f(yjθ): We use the posterior to compute a point estimator such as the posterior mean of θ. We can also summarize the posterior by drawing a large sample θ1; : : : ; θN from the posterior π(θjY ) and the plotting the samples. In nonparametric Bayesian inference, we replace the finite dimensional model ff(yjθ): θ 2 Θg with an infinite dimensional model such as Z F = f : (f 00(y))2dy < 1 (2) Typically, neither the prior nor the posterior have a density function with respect to a dominating measure. But the posterior is still well defined. On the other hand, if there is a dominating measure for a set of densities F then the posterior can be found by Bayes theorem: R A Ln(f)dπ(f) πn(A) ≡ P(f 2 AjY ) = R (3) F Ln(f)dπ(f) Q where A ⊂ F, Ln(f) = i f(Yi) is the likelihood function and π is a prior on F. -
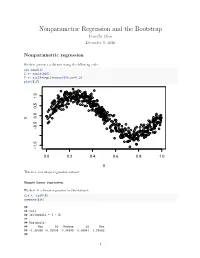
Nonparametric Regression and the Bootstrap Yen-Chi Chen December 5, 2016
Nonparametric Regression and the Bootstrap Yen-Chi Chen December 5, 2016 Nonparametric regression We first generate a dataset using the following code: set.seed(1) X <- runif(500) Y <- sin(X*2*pi)+rnorm(500,sd=0.2) plot(X,Y) 1.0 0.5 0.0 Y −0.5 −1.5 0.0 0.2 0.4 0.6 0.8 1.0 X This is a sine shape regression dataset. Simple linear regression We first fit a linear regression to this dataset: fit <- lm(Y~X) summary(fit) ## ## Call: ## lm(formula = Y ~ X) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.38395 -0.35908 0.04589 0.38541 1.05982 ## 1 ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 1.03681 0.04306 24.08 <2e-16 *** ## X -1.98962 0.07545 -26.37 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 '' 1 ## ## Residual standard error: 0.4775 on 498 degrees of freedom ## Multiple R-squared: 0.5827, Adjusted R-squared: 0.5819 ## F-statistic: 695.4 on 1 and 498 DF, p-value: < 2.2e-16 We observe a negative slope and here is the scatter plot with the regression line: plot(X,Y, pch=20, cex=0.7, col="black") abline(fit, lwd=3, col="red") 1.0 0.5 0.0 Y −0.5 −1.5 0.0 0.2 0.4 0.6 0.8 1.0 X After fitted a regression, we need to examine the residual plot to see if there is any patetrn left in the fit: plot(X, fit$residuals) 2 1.0 0.5 0.0 fit$residuals −0.5 −1.0 0.0 0.2 0.4 0.6 0.8 1.0 X We see a clear pattern in the residual plot–this suggests that there is a nonlinear relationship between X and Y. -

Nonparametric Regression
Nonparametric Regression Statistical Machine Learning, Spring 2015 Ryan Tibshirani (with Larry Wasserman) 1 Introduction, and k-nearest-neighbors 1.1 Basic setup, random inputs Given a random pair (X; Y ) Rd R, recall that the function • 2 × f0(x) = E(Y X = x) j is called the regression function (of Y on X). The basic goal in nonparametric regression is ^ d to construct an estimate f of f0, from i.i.d. samples (x1; y1);::: (xn; yn) R R that have the same joint distribution as (X; Y ). We often call X the input, predictor,2 feature,× etc., and Y the output, outcome, response, etc. Importantly, in nonparametric regression we do not assume a certain parametric form for f0 Note for i.i.d. samples (x ; y );::: (x ; y ), we can always write • 1 1 n n yi = f0(xi) + i; i = 1; : : : n; where 1; : : : n are i.i.d. random errors, with mean zero. Therefore we can think about the sampling distribution as follows: (x1; 1);::: (xn; n) are i.i.d. draws from some common joint distribution, where E(i) = 0, and then y1; : : : yn are generated from the above model In addition, we will assume that each i is independent of xi. As discussed before, this is • actually quite a strong assumption, and you should think about it skeptically. We make this assumption for the sake of simplicity, and it should be noted that a good portion of theory that we cover (or at least, similar theory) also holds without the assumption of independence between the errors and the inputs 1.2 Basic setup, fixed inputs Another common setup in nonparametric regression is to directly assume a model • yi = f0(xi) + i; i = 1; : : : n; where now x1; : : : xn are fixed inputs, and 1; : : : are still i.i.d. -

Robust Estimation on a Parametric Model Via Testing 3 Estimators
Bernoulli 22(3), 2016, 1617–1670 DOI: 10.3150/15-BEJ706 Robust estimation on a parametric model via testing MATHIEU SART 1Universit´ede Lyon, Universit´eJean Monnet, CNRS UMR 5208 and Institut Camille Jordan, Maison de l’Universit´e, 10 rue Tr´efilerie, CS 82301, 42023 Saint-Etienne Cedex 2, France. E-mail: [email protected] We are interested in the problem of robust parametric estimation of a density from n i.i.d. observations. By using a practice-oriented procedure based on robust tests, we build an estimator for which we establish non-asymptotic risk bounds with respect to the Hellinger distance under mild assumptions on the parametric model. We show that the estimator is robust even for models for which the maximum likelihood method is bound to fail. A numerical simulation illustrates its robustness properties. When the model is true and regular enough, we prove that the estimator is very close to the maximum likelihood one, at least when the number of observations n is large. In particular, it inherits its efficiency. Simulations show that these two estimators are almost equal with large probability, even for small values of n when the model is regular enough and contains the true density. Keywords: parametric estimation; robust estimation; robust tests; T-estimator 1. Introduction We consider n independent and identically distributed random variables X1,...,Xn de- fined on an abstract probability space (Ω, , P) with values in the measure space (X, ,µ). E F We suppose that the distribution of Xi admits a density s with respect to µ and aim at estimating s by using a parametric approach. -

Testing for No Effect in Nonparametric Regression Via Spline Smoothing Techniques
Ann. Inst. Statist. Math. Vol. 46, No. 2, 251-265 (1994) TESTING FOR NO EFFECT IN NONPARAMETRIC REGRESSION VIA SPLINE SMOOTHING TECHNIQUES JUEI-CHAO CHEN Graduate Institute of Statistics and Actuarial Science, Feng Chic University, Taiehung ~072~, Taiwan, ROC (Received June 8, 1992; revised August 2, 1993) Abstract. We propose three statistics for testing that a predictor variable has no effect on the response variable in regression analysis. The test statistics are integrals of squared derivatives of various orders of a periodic smoothing spline fit to the data. The large sample properties of the test statistics are investigated under the null hypothesis and sequences of local alternatives and a Monte Carlo study is conducted to assess finite sample power properties. Key words and phrases: Asymptotic distribution, local alternatives, nonpara- metric regression, Monte Carlo. 1. Introduction Regression analysis is used to study relationships between the response vari- able and a predictor variable; therefore, all of the inference is based on the as- sumption that the response variable actually depends on the predictor variable. Testing for no effect is the same as checking this assumption. In this paper, we propose three statistics for testing that a predictor variable has no effect on the response variable and derive their asymptotic distributions. Suppose we have an experiment which yields observations (tin,y1),..., (tn~, Yn), where yj represents the value of a response variable y at equally spaced values tjn = (j - 1)/n, j = 1,...,n, of the predictor variable t. The regression model is (1.1) yj = #(tin) + ey, j --- 1,...,n, where the ej are iid random errors with E[el] = 0, Var[r ~2 and 0 K E[e 41 K oe. -

A PARTIALLY PARAMETRIC MODEL 1. Introduction a Notable
A PARTIALLY PARAMETRIC MODEL DANIEL J. HENDERSON AND CHRISTOPHER F. PARMETER Abstract. In this paper we propose a model which includes both a known (potentially) nonlinear parametric component and an unknown nonparametric component. This approach is feasible given that we estimate the finite sample parameter vector and the bandwidths simultaneously. We show that our objective function is asymptotically equivalent to the individual objective criteria for the parametric parameter vector and the nonparametric function. In the special case where the parametric component is linear in parameters, our single-step method is asymptotically equivalent to the two-step partially linear model esti- mator in Robinson (1988). Monte Carlo simulations support the asymptotic developments and show impressive finite sample performance. We apply our method to the case of a partially constant elasticity of substitution production function for an unbalanced sample of 134 countries from 1955-2011 and find that the parametric parameters are relatively stable for different nonparametric control variables in the full sample. However, we find substan- tial parameter heterogeneity between developed and developing countries which results in important differences when estimating the elasticity of substitution. 1. Introduction A notable development in applied economic research over the last twenty years is the use of the partially linear regression model (Robinson 1988) to study a variety of phenomena. The enthusiasm for the partially linear model (PLM) is not confined to