Nonparametric Statistics for Social and Behavioral Sciences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nonparametric Estimation by Convex Programming
The Annals of Statistics 2009, Vol. 37, No. 5A, 2278–2300 DOI: 10.1214/08-AOS654 c Institute of Mathematical Statistics, 2009 NONPARAMETRIC ESTIMATION BY CONVEX PROGRAMMING By Anatoli B. Juditsky and Arkadi S. Nemirovski1 Universit´eGrenoble I and Georgia Institute of Technology The problem we concentrate on is as follows: given (1) a convex compact set X in Rn, an affine mapping x 7→ A(x), a parametric family {pµ(·)} of probability densities and (2) N i.i.d. observations of the random variable ω, distributed with the density pA(x)(·) for some (unknown) x ∈ X, estimate the value gT x of a given linear form at x. For several families {pµ(·)} with no additional assumptions on X and A, we develop computationally efficient estimation routines which are minimax optimal, within an absolute constant factor. We then apply these routines to recovering x itself in the Euclidean norm. 1. Introduction. The problem we are interested in is essentially as fol- lows: suppose that we are given a convex compact set X in Rn, an affine mapping x A(x) and a parametric family pµ( ) of probability densities. Suppose that7→N i.i.d. observations of the random{ variable· } ω, distributed with the density p ( ) for some (unknown) x X, are available. Our objective A(x) · ∈ is to estimate the value gT x of a given linear form at x. In nonparametric statistics, there exists an immense literature on various versions of this problem (see, e.g., [10, 11, 12, 13, 15, 17, 18, 21, 22, 23, 24, 25, 26, 27, 28] and the references therein). -

Repeated-Measures ANOVA & Friedman Test Using STATCAL
Repeated-Measures ANOVA & Friedman Test Using STATCAL (R) & SPSS Prana Ugiana Gio Download STATCAL in www.statcal.com i CONTENT 1.1 Example of Case 1.2 Explanation of Some Book About Repeated-Measures ANOVA 1.3 Repeated-Measures ANOVA & Friedman Test 1.4 Normality Assumption and Assumption of Equality of Variances (Sphericity) 1.5 Descriptive Statistics Based On SPSS dan STATCAL (R) 1.6 Normality Assumption Test Using Kolmogorov-Smirnov Test Based on SPSS & STATCAL (R) 1.7 Assumption Test of Equality of Variances Using Mauchly Test Based on SPSS & STATCAL (R) 1.8 Repeated-Measures ANOVA Based on SPSS & STATCAL (R) 1.9 Multiple Comparison Test Using Boferroni Test Based on SPSS & STATCAL (R) 1.10 Friedman Test Based on SPSS & STATCAL (R) 1.11 Multiple Comparison Test Using Wilcoxon Test Based on SPSS & STATCAL (R) ii 1.1 Example of Case For example given data of weight of 11 persons before and after consuming medicine of diet for one week, two weeks, three weeks and four week (Table 1.1.1). Tabel 1.1.1 Data of Weight of 11 Persons Weight Name Before One Week Two Weeks Three Weeks Four Weeks A 89.43 85.54 80.45 78.65 75.45 B 85.33 82.34 79.43 76.55 71.35 C 90.86 87.54 85.45 80.54 76.53 D 91.53 87.43 83.43 80.44 77.64 E 90.43 84.45 81.34 78.64 75.43 F 90.52 86.54 85.47 81.44 78.64 G 87.44 83.34 80.54 78.43 77.43 H 89.53 86.45 84.54 81.35 78.43 I 91.34 88.78 85.47 82.43 78.76 J 88.64 84.36 80.66 78.65 77.43 K 89.51 85.68 82.68 79.71 76.5 Average 89.51 85.68 82.68 79.71 76.69 Based on Table 1.1.1: The person whose name is A has initial weight 89,43, after consuming medicine of diet for one week 85,54, two weeks 80,45, three weeks 78,65 and four weeks 75,45. -
7 Nonparametric Methods
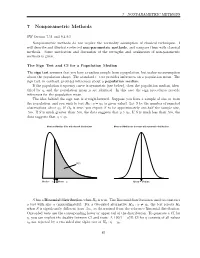
7 NONPARAMETRIC METHODS 7 Nonparametric Methods SW Section 7.11 and 9.4-9.5 Nonparametric methods do not require the normality assumption of classical techniques. I will describe and illustrate selected non-parametric methods, and compare them with classical methods. Some motivation and discussion of the strengths and weaknesses of non-parametric methods is given. The Sign Test and CI for a Population Median The sign test assumes that you have a random sample from a population, but makes no assumption about the population shape. The standard t−test provides inferences on a population mean. The sign test, in contrast, provides inferences about a population median. If the population frequency curve is symmetric (see below), then the population median, iden- tified by η, and the population mean µ are identical. In this case the sign procedures provide inferences for the population mean. The idea behind the sign test is straightforward. Suppose you have a sample of size m from the population, and you wish to test H0 : η = η0 (a given value). Let S be the number of sampled observations above η0. If H0 is true, you expect S to be approximately one-half the sample size, .5m. If S is much greater than .5m, the data suggests that η > η0. If S is much less than .5m, the data suggests that η < η0. Mean and Median differ with skewed distributions Mean and Median are the same with symmetric distributions 50% Median = η Mean = µ Mean = Median S has a Binomial distribution when H0 is true. The Binomial distribution is used to construct a test with size α (approximately). -

9 Blocked Designs
9 Blocked Designs 9.1 Friedman's Test 9.1.1 Application 1: Randomized Complete Block Designs • Assume there are k treatments of interest in an experiment. In Section 8, we considered the k-sample Extension of the Median Test and the Kruskal-Wallis Test to test for any differences in the k treatment medians. • Suppose the experimenter is still concerned with studying the effects of a single factor on a response of interest, but variability from another factor that is not of interest is expected. { Suppose a researcher wants to study the effect of 4 fertilizers on the yield of cotton. The researcher also knows that the soil conditions at the 8 areas for performing an experiment are highly variable. Thus, the researcher wants to design an experiment to detect any differences among the 4 fertilizers on the cotton yield in the presence a \nuisance variable" not of interest (the 8 areas). • Because experimental units can vary greatly with respect to physical characteristics that can also influence the response, the responses from experimental units that receive the same treatment can also vary greatly. • If it is not controlled or accounted for in the data analysis, it can can greatly inflate the experimental variability making it difficult to detect real differences among the k treatments of interest (large Type II error). • If this source of variability can be separated from the treatment effects and the random experimental error, then the sensitivity of the experiment to detect real differences between treatments in increased (i.e., lower the Type II error). • Therefore, the goal is to choose an experimental design in which it is possible to control the effects of a variable not of interest by bringing experimental units that are similar into a group called a \block". -

1 Exercise 8: an Introduction to Descriptive and Nonparametric
1 Exercise 8: An Introduction to Descriptive and Nonparametric Statistics Elizabeth M. Jakob and Marta J. Hersek Goals of this lab 1. To understand why statistics are used 2. To become familiar with descriptive statistics 1. To become familiar with nonparametric statistical tests, how to conduct them, and how to choose among them 2. To apply this knowledge to sample research questions Background If we are very fortunate, our experiments yield perfect data: all the animals in one treatment group behave one way, and all the animals in another treatment group behave another way. Usually our results are not so clear. In addition, even if we do get results that seem definitive, there is always a possibility that they are a result of chance. Statistics enable us to objectively evaluate our results. Descriptive statistics are useful for exploring, summarizing, and presenting data. Inferential statistics are used for interpreting data and drawing conclusions about our hypotheses. Descriptive statistics include the mean (average of all of the observations; see Table 8.1), mode (most frequent data class), and median (middle value in an ordered set of data). The variance, standard deviation, and standard error are measures of deviation from the mean (see Table 8.1). These statistics can be used to explore your data before going on to inferential statistics, when appropriate. In hypothesis testing, a variety of statistical tests can be used to determine if the data best fit our null hypothesis (a statement of no difference) or an alternative hypothesis. More specifically, we attempt to reject one of these hypotheses. -

Nonparametric Analogues of Analysis of Variance
*\ NONPARAMETRIC ANALOGUES OF ANALYSIS OF VARIANCE by °\\4 RONALD K. LOHRDING B. A., Southwestern College, 1963 A MASTER'S REPORT submitted in partial fulfillment of the requirements for the degree MASTER OF SCIENCE Department of Statistics and Statistical Laboratory KANSAS STATE UNIVERSITY Manhattan, Kansas 1966 Approved by: ' UKC )x 0-i Major PrProfessor L IVoJL CONTENTS 1. INTRODUCTION 1 2. COMPLETELY RANDOMIZED DESIGN 4 2. 1. The Kruskal-Wallis One-way Analysis of Variance by Ranks 4 2. 2. Mosteller's k-Sample Slippage Test 7 2.3. Conover's k-Sample Slippage Test 8 2.4. A k-Sample Kolmogorov-Smirnov Test 11 2 2. 5. The Contingency x Test 13 3. RANDOMIZED COMPLETE BLOCK 14 3. 1. Cochran Q Test 15 3.2. Friedman's Two-way Analysis of Variance by Ranks . 16 4. PROCEDURES WHICH GENERALIZE TO SEVERAL DESIGNS . 17 4.1. Mood's Median Test 18 4.2. Wilson's Median Test 21 4.3. The Randomized Rank-Sum Test 27 4.4. Rank Test for Paired-Comparison Experiments ... 30 5. BALANCED INCOMPLETE BLOCK 33 5. 1. Bradley's Rank Analysis of Incomplete Block Designs 33 5.2. Durbin's Rank Analysis of Incomplete Block Designs 40 6. A 2x2 FACTORIAL EXPERIMENT 44 7. PARTIALLY BALANCED INCOMPLETE BLOCK 47 OTHER RELATED TESTS 50 ACKNOWLEDGEMENTS 53 REFERENCES 54 NONPARAMETRIC ANALOGUES OF ANALYSIS OF VARIANCE 1. Introduction J. V. Bradley (I960) proposes that the history of statistics can be divided into four major stages. The first or one parameter stage was when statistics were merely thought of as averages or in some instances ratios. -

An Averaging Estimator for Two Step M Estimation in Semiparametric Models
An Averaging Estimator for Two Step M Estimation in Semiparametric Models Ruoyao Shi∗ February, 2021 Abstract In a two step extremum estimation (M estimation) framework with a finite dimen- sional parameter of interest and a potentially infinite dimensional first step nuisance parameter, I propose an averaging estimator that combines a semiparametric esti- mator based on nonparametric first step and a parametric estimator which imposes parametric restrictions on the first step. The averaging weight is the sample analog of an infeasible optimal weight that minimizes the asymptotic quadratic risk. I show that under mild conditions, the asymptotic lower bound of the truncated quadratic risk dif- ference between the averaging estimator and the semiparametric estimator is strictly less than zero for a class of data generating processes (DGPs) that includes both cor- rect specification and varied degrees of misspecification of the parametric restrictions, and the asymptotic upper bound is weakly less than zero. Keywords: two step M estimation, semiparametric model, averaging estimator, uniform dominance, asymptotic quadratic risk JEL Codes: C13, C14, C51, C52 ∗Department of Economics, University of California Riverside, [email protected]. The author thanks Colin Cameron, Xu Cheng, Denis Chetverikov, Yanqin Fan, Jinyong Hahn, Bo Honoré, Toru Kitagawa, Zhipeng Liao, Hyungsik Roger Moon, Whitney Newey, Geert Ridder, Aman Ullah, Haiqing Xu and the participants at various seminars and conferences for helpful comments. This project is generously supported by UC Riverside Regents’ Faculty Fellowship 2019-2020. Zhuozhen Zhao provides great research assistance. All remaining errors are the author’s. 1 1 Introduction Semiparametric models, consisting of a parametric component and a nonparametric com- ponent, have gained popularity in economics. -

Stat 425 Introduction to Nonparametric Statistics Rank Tests For
Stat 425 Introduction to Nonparametric Statistics Rank Tests for Comparing Two Treatments Fritz Scholz Spring Quarter 2009∗ ∗May 16, 2009 Textbooks Erich L. Lehmann, Nonparametrics, Statistical Methods Based on Ranks, Springer Verlag 2008 (required) W. John Braun and Duncan J. Murdoch, A First Course in STATISTICAL PROGRAMMING WITH R, Cambridge University Press 2007 (optional). For other introductory material on R see the class web page. http://www.stat.washington.edu/fritz/Stat425 2009.html 1 Comparing Two Treatments Often it is desired to understand whether an innovation constitutes an improvement over current methods/treatments. Application Areas: New medical drug treatment, surgical procedures, industrial process change, teaching method, ::: ! ¥ Example 1 New Drug: A mental hospital wants to investigate the (beneficial?) effect of some new drug on a particular type of mental or emotional disorder. We discuss this in the context of five patients (suffering from the disorder to roughly the same degree) to simplify the logistics of getting the basic ideas out in the open. Three patients are randomly assigned the new treatment while the other two get a placebo pill (also called the “control treatment”). 2 Precautions: Triple Blind! The assignments of new drug and placebo should be blind to the patient to avoid “placebo effects”. It should be blind to the staff of the mental hospital to avoid conscious or subconscious staff treatment alignment with either one of these treatments. It should also be blind to the physician who evaluates the patients after a few weeks on this treatment. A placebo effect occurs when a patient thinks he/she is on the beneficial drug, shows some beneficial effect, but in reality is on a placebo pill. -

Nonparametric Statistics
NONPARAMETRIC STATISTICS SECOND EDITION NONPARAMETRIC STATISTICS A Step-by-Step Approach GREGORY W. CORDER DALE I. FOREMAN Copyright © 2014 by John Wiley & Sons, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4470, or on the web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http://www.wiley.com/go/ permissions. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and speciically disclaim any implied warranties of merchantability or itness for a particular purpose. No warranty may be created or extended by sales representatives or written sales materials. The advice and strategies contained herein may not be suitable for your situation. You should consult with a professional where appropriate. Neither the publisher nor author shall be liable for any loss of proit or any other commercial damages, including but not limited to special, incidental, consequential, or other damages. -

Nonparametric Statistics
14 Nonparametric Statistics • These methods required that the data be normally CONTENTS distributed or that the sampling distributions of the 14.1 Introduction: Distribution-Free Tests relevant statistics be normally distributed. 14.2 Single-Population Inferences Where We're Going 14.3 Comparing Two Populations: • Develop the need for inferential techniques that Independent Samples require fewer or less stringent assumptions than the 14.4 Comparing Two Populations: Paired methods of Chapters 7 – 10 and 11 (14.1) Difference Experiment • Introduce nonparametric tests that are based on ranks 14.5 Comparing Three or More Populations: (i.e., on an ordering of the sample measurements Completely Randomized Design according to their relative magnitudes) (14.2–14.7) • Present a nonparametric test about the central 14.6 Comparing Three or More Populations: tendency of a single population (14.2) Randomized Block Design • Present a nonparametric test for comparing two 14.7 Rank Correlation populations with independent samples (14.3) • Present a nonparametric test for comparing two Where We've Been populations with paired samples (14.4) • Presented methods for making inferences about • Present a nonparametric test for comparing three or means ( Chapters 7 – 10 ) and for making inferences more populations using a designed experiment about the correlation between two quantitative (14.5–14.6) variables ( Chapter 11 ) • Present a nonparametric test for rank correlation (14.7) 14-1 Copyright (c) 2013 Pearson Education, Inc M14_MCCL6947_12_AIE_C14.indd 14-1 10/1/11 9:59 AM Statistics IN Action How Vulnerable Are New Hampshire Wells to Groundwater Contamination? Methyl tert- butyl ether (commonly known as MTBE) is a the measuring device, the MTBE val- volatile, flammable, colorless liquid manufactured by the chemi- ues for these wells are recorded as .2 cal reaction of methanol and isobutylene. -

Robust Regression Estimators When There Are Tied Values
ROBUST REGRESSION ESTIMATORS WHEN THERE ARE TIED VALUES Rand R. Wilcox Dept of Psychology University of Southern California Florence Clark Division of Occupational Science & Occupational Therapy University of Southern California June 13, 2013 1 ABSTRACT There is a vast literature on robust regression estimators, the bulk of which assumes that the dependent (outcome) variable is continuous. Evidently, there are no published results on the impact of tied values in terms of the Type I error probability. A minor goal in this paper to comment generally on problems created by tied values when testing the hypothesis of a zero slope. Simulations indicate that when tied values are common, there are practical problems with Yohai's MM-estimator, the Coakley{Hettmansperger M-estimator, the least trimmed squares estimator, the Koenker{Bassett quantile regression estimator, Jaeckel's rank-based estimator as well as the Theil{Sen estimator. The main goal is to suggest a modification of the Theil{Sen estimator that avoids the problems associated with the estimators just listed. Results on the small-sample efficiency of the modified Theil-Sen estimator are reported as well. Data from the Well Elderly 2 Study are used to illustrate that the modified Theil-Sen estimator can make a practical difference. Keywords: tied values, Harrell{Davis estimator, MM-estimator, Coakley{Hettmansperger estimator, rank-based regression, Theil{Sen estimator, Well Elderly 2 Study, perceived con- trol 1 Introduction It is well known that the ordinary least squares (OLS) regression estimator is not robust (e.g., Hampel et al., 1987; Huber & Ronchetti, 2009; Maronna et al. 2006; Staudte & Sheather, 1990; Wilcox, 2012a, b). -

Nonparametric Statistics*
, I ' NONPARAMETRIC STATISTICS* I. Richard Savage Special Report No. 7 University of Minnesota Minneapolis, Minnesota * A condensed version of this manuscript is to appear in the second edition of the International Encyclopedia of The Soci~l Sciences. ' NONPARAMETRIC STATISTICS I. Richard Savage O. Introduction. Nonparametric techniques are characterized by their applicability to data not assumed to have specialized distributional properties, e.g., normality. These techniques have been devised for problems in descriptive statistics, testing of hypotheses, point estimation, interval estimation, tolerance intervals, and to a lesser extent, decision theory and sequential analysis. There is a substantial body of knowledge for making inferences nonparametrically about the location parameter of a single population and the difference between the location parameters of two populations. At the present time, research is directed towards developing aids to ease the application of nonparametric techniques, extending the range of knowledge of the operating characteristics of nonparametric techniques and providing additional techniques for more involved experimental situations and deeper analysis. Historically many of the first statistical techniques were applied to massive quantities of data. The statistics arising in these techniques had effectively known probability distributions since the techniques were usually based on sample moments, which have approximate normal distributions. These techniques were nonparametric in that they did not require special assumptions about the data. As the applications of statistics increased, important situations arose where a statistical analysis was called for, but the data available was severely limited. Then, under the leadership of "Student" (W. S. Gossett) and R. A. Fisher, the exact distributions of many statistics were derived when the underlying distributions were assumed to have a particular form, usually normal.