Phenomena of Social Dynamics in Online Games
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Development and Validation of the Game User Experience Satisfaction Scale (Guess)
THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) A Dissertation by Mikki Hoang Phan Master of Arts, Wichita State University, 2012 Bachelor of Arts, Wichita State University, 2008 Submitted to the Department of Psychology and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy May 2015 © Copyright 2015 by Mikki Phan All Rights Reserved THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) The following faculty members have examined the final copy of this dissertation for form and content, and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy with a major in Psychology. _____________________________________ Barbara S. Chaparro, Committee Chair _____________________________________ Joseph Keebler, Committee Member _____________________________________ Jibo He, Committee Member _____________________________________ Darwin Dorr, Committee Member _____________________________________ Jodie Hertzog, Committee Member Accepted for the College of Liberal Arts and Sciences _____________________________________ Ronald Matson, Dean Accepted for the Graduate School _____________________________________ Abu S. Masud, Interim Dean iii DEDICATION To my parents for their love and support, and all that they have sacrificed so that my siblings and I can have a better future iv Video games open worlds. — Jon-Paul Dyson v ACKNOWLEDGEMENTS Althea Gibson once said, “No matter what accomplishments you make, somebody helped you.” Thus, completing this long and winding Ph.D. journey would not have been possible without a village of support and help. While words could not adequately sum up how thankful I am, I would like to start off by thanking my dissertation chair and advisor, Dr. -

Investor Update 01/13/2015 Gamestop Overview
Investor Update 01/13/2015 GameStop Overview EUROPE 331 CANADA stores 1,321 stores UNITED STATES 4,656 stores 421 stores AUSTRALIA/NZ Italy 420 Ireland 50 France 435 Total Stores: 6,729 Germany 260 6,248 Video game stores Nordic 156 481 Technology Brand stores 2 Video Game Brands Platform Overview GameStop maintains a leadership position in the $22.4bn worldwide gaming market 30-34% next-gen console market share (U.S.) 48-52% next-gen software market share (U.S.) Leading retailer in the fast growing digital business (26%+ CAGR from 2011-2013) Unique in-store customer experience Highly successful loyalty program with 40 million global members Game Informer is the #1 digital magazine globally Established buy-sell-trade program drives differentiation from competitors and enhanced profitability 3 GameStop’s Unique Formula Informed Associates Multichannel Vendor Relationships PowerUp Rewards GameInformer Magazine Buy – Sell – Trade 4 Our Strategic Plan Maximize Brick & Mortar Stores . Capture leading market share of new console cycle . Utilize stores to grow digital sales . Apply retail expertise to Tech Brands Build on our Distinct Pre-owned Business . Expand the value assortment to increase sales and gross profit dollars . Gain market share in Value channel Own the Customer . Capitalize on our international loyalty program, now with 40 million members in 14 countries around the world Digital Growth . DLC, Kongregate, Steam wallet, PC Downloads, Console Network cards Disciplined Capital Allocation . Return 100% of our FCF to shareholders through buyback and dividend unless a better opportunity arises 5 We are delivering on our plan… . Digital & Mobile growth . $2.69B of digital receipts and $989M of mobile revenue since 2011 . -

Navigating the Videogame
From above, from below: navigating the videogame A thesis presented by Daniel Golding 228306 to The School of Culture and Communication in partial fulfilment of the requirements for the degree of Bachelor of Arts (Honours) in the field of Cultural Studies in the School of Culture and Communication The University of Melbourne Supervisor: Dr. Fran Martin October 2008 ABSTRACT The study of videogames is still evolving. While many theorists have accurately described aspects of the medium, this thesis seeks to move the study of videogames away from previously formal approaches and towards a holistic method of engagement with the experience of playing videogames. Therefore, I propose that videogames are best conceptualised as navigable, spatial texts. This approach, based on Michel de Certeau’s concept of strategies and tactics, illuminates both the textual structure of videogames and the immediate experience of playing them. I also regard videogame space as paramount. My close analysis of Portal (Valve Corporation, 2007) demonstrates that a designer can choose to communicate rules and fiction, and attempt to influence the behaviour of players through strategies of space. Therefore, I aim to plot the relationship between designer and player through the power structures of the videogame, as conceived through this new lens. ii TABLE OF CONTENTS ABSTRACT ii ACKNOWLEDGEMENTS iv CHAPTER ONE: Introduction 1 AN EVOLVING FIELD 2 LUDOLOGY AND NARRATOLOGY 3 DEFINITIONS, AND THE NAVIGABLE TEXT 6 PLAYER EXPERIENCE AND VIDEOGAME SPACE 11 MARGINS OF DISCUSSION 13 CHAPTER TWO: The videogame from above: the designer as strategist 18 PSYCHOGEOGRAPHY 18 PORTAL AND THE STRATEGIES OF DESIGN 20 STRUCTURES OF POWER 27 RAILS 29 CHAPTER THREE: The videogame from below: the player as tactician 34 THE PLAYER AS NAVIGATOR 36 THE PLAYER AS SUBJECT 38 THE PLAYER AS BRICOLEUR 40 THE PLAYER AS GUERRILLA 43 CHAPTER FOUR: Conclusion 48 BIBLIOGRAPHY 50 iii ACKNOWLEDGEMENTS I would like to thank my supervisor, Dr. -

Esports High Impact and Investable
Needham Insights: Thought Leader Series Laura A. Martin, CFA & CMT – [email protected] / (917) 373-3066 September 5, 2019 Dan Medina – [email protected] / (626) 893-2925 eSports High Impact and Investable For the past decade, eSports has been growing on the main stage in Asia and in stealth mode in the US. This report addresses questions we get most often from investors about eSports: ➢ What is eSports? Definitions differ. Our definition of eSports is “players competing at a video game in front of a live audience while being live-streamed.” By implication, viewing, attendance, and playing time are linked, and each creates revenue streams for eSports. ➢ How big is eSports? Globally, one out of every three (ie, 33%) 18-25 year olds spent more than an hour a day playing video games, 395mm people watched eSports, and 250mm people played Fortnite in 2018. eSports revenue will be $1.1B in 2019, up 26% y/y. ➢ Should investors care about eSports? We would argue “yes”, owing to: a) global scale; b) time spent playing and viewing; c) compelling demographics; d) eSports vs traditional sports trends; e) revenue growth; and, f) sports betting should supercharge US eSports. ➢ Is eSports a fad? We would argue “no”, owing to: a) many US Universities now offer Varsity eSports scholarships; b) new special purpose eSports stadiums are proliferating; c) billionaires are investing to make eSports successful; d) audience growth; and, e) Olympics potential. ➢ Why have you never heard of eSports? Because zero of the top 30 earning players in the world were from the US in 2018. -
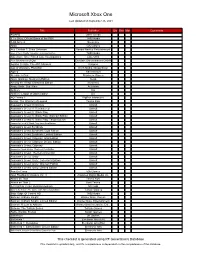
Microsoft Xbox One
Microsoft Xbox One Last Updated on September 26, 2021 Title Publisher Qty Box Man Comments #IDARB Other Ocean 8 To Glory: Official Game of the PBR THQ Nordic 8-Bit Armies Soedesco Abzû 505 Games Ace Combat 7: Skies Unknown Bandai Namco Entertainment Aces of the Luftwaffe: Squadron - Extended Edition THQ Nordic Adventure Time: Finn & Jake Investigations Little Orbit Aer: Memories of Old Daedalic Entertainment GmbH Agatha Christie: The ABC Murders Kalypso Age of Wonders: Planetfall Koch Media / Deep Silver Agony Ravenscourt Alekhine's Gun Maximum Games Alien: Isolation: Nostromo Edition Sega Among the Sleep: Enhanced Edition Soedesco Angry Birds: Star Wars Activision Anthem EA Anthem: Legion of Dawn Edition EA AO Tennis 2 BigBen Interactive Arslan: The Warriors of Legend Tecmo Koei Assassin's Creed Chronicles Ubisoft Assassin's Creed III: Remastered Ubisoft Assassin's Creed IV: Black Flag Ubisoft Assassin's Creed IV: Black Flag: Walmart Edition Ubisoft Assassin's Creed IV: Black Flag: Target Edition Ubisoft Assassin's Creed IV: Black Flag: GameStop Edition Ubisoft Assassin's Creed Syndicate Ubisoft Assassin's Creed Syndicate: Gold Edition Ubisoft Assassin's Creed Syndicate: Limited Edition Ubisoft Assassin's Creed: Odyssey: Gold Edition Ubisoft Assassin's Creed: Odyssey: Deluxe Edition Ubisoft Assassin's Creed: Odyssey Ubisoft Assassin's Creed: Origins: Steelbook Gold Edition Ubisoft Assassin's Creed: The Ezio Collection Ubisoft Assassin's Creed: Unity Ubisoft Assassin's Creed: Unity: Collector's Edition Ubisoft Assassin's Creed: Unity: Walmart Edition Ubisoft Assassin's Creed: Unity: Limited Edition Ubisoft Assetto Corsa 505 Games Atari Flashback Classics Vol. 3 AtGames Digital Media Inc. -

Florida Tech Esports Tryout Information Packet
Esports Tryouts Team Benefits ............................................................................................................................................. 3 Who can tryout? ......................................................................................................................................... 4 What to expect ............................................................................................................................................ 5 Varsity & Junior Varsity Tryout Requirements ....................................................................................... 6 League of Legends (LoL) ............................................................................................................................ 6 Rocket League (RL) .................................................................................................................................... 6 Junior Varsity Tryout Requirements ........................................................................................................ 7 Rainbow 6 Siege (R6S) ............................................................................................................................... 7 Valorant (VAL) ........................................................................................................................................... 7 Florida Tech Esports Club Titles .............................................................................................................. 8 Dear Florida Tech Students, Thank you -

Portal Prima Official Mini Eguide.Pdf 2008-05-31 12:20 3.1 MB
PRIMA OFFICIAL GAME GUIDE DAVID SJ HODGSON STEPHEN STRATTON MIGUEL LOPEZ Prima Games David SJ Hodgson A Division of Random House, Inc. Originally hailing from the United Kingdom, David left his role as a writer of numerous 3000 Lava Ridge Court, Suite 100 British video game magazines (including Mean Machines, Computer & Video Games, Roseville, CA 95661 and the Offi cial Nintendo and Sega Saturn magazines) and a bohemian lifestyle on a dry-docked German fi shing trawler to work on the infamous GameFan magazine in www.primagames.com 1996. David helped to launch the fl edgling GameFan Books and helped form Gamers’ The Prima Games logo is a registered trademark of Random House, Inc., Republic in 1998, authoring many strategy guides for Millennium Publications, registered in the United States and other countries. Primagames.com is including The Offi cial Metal Gear Solid Mission Handbook. After launching the wildly a registered trademark of Random House, Inc., registered in the United unsuccessful incite Video Gaming and Gamers.com, David found his calling, and States. began authoring guides for Prima Games. He has written over 30 Prima strategy guides, including The Godfather: The Game, Knights of the Old Republic, Perfect Dark © 2007 by Prima Games. All rights reserved. No part of this book may be Zero, Half-Life 2, and Burnout Revenge. He lives in the Pacifi c Northwest with his reproduced or transmitted in any form or by any means, electronic or mechanical, wife, Melanie, and an eight-foot statue of Great Cthulhu. including photocopying, recording, or by any information storage or retrieval system without written permission from Prima Games. -

Team Fortress 2 Mine Shaft Custom
University of Arkansas – CSCE Department Advanced Virtual Worlds – Spring 2013 CTF_Shaft: A Custom Team Fortress 2 Map Taylor Yust, Scott Benton, Luke Godfrey, Dylan Reile Note: Except where otherwise specified, text was written by Taylor Yust Abstract One of the most prominent applications of virtual worlds is in the game industry. The success of a game hinges on its ability to craft compelling environments that effectively explore the design space afforded by its mechanics. Team Fortress 2, an online multiplayer action game developed by Valve, is no exception. In an attempt to further our own experience with game development and virtual world construction, our team seeks to design and build an engaging custom map using critical game design methodology. We will tackle the “Capture the Flag” game type, which is notorious in the Team Fortress 2 community for often resulting in broken gameplay. [1] 1.0 Problem When most amateur designers approach map development, they fail to think of the design in a critical manner and instead move forward with only a vague notion of what would be “cool.” For example, rather than understanding a vertical space as providing a sort of increased “flow” in the form tactical and mechanical advantage, many designers would see it as an “awesome tower,” unable to look beyond its literal representation. This approach often leads to poorly designed maps with balancing issues. The “Capture the Flag” (CTF) maps in Team Fortress 2 are an excellent example of this. The mechanics often lead to stalemates with the dominant strategy being to “turtle” near your team’s flag. -

The Future Past: Intertextuality in Contemporary Dystopian Video Games
The Future Past: Intertextuality in Contemporary Dystopian Video Games By Matthew Warren CUNY Baccalaureate for Unique and Interdisciplinary Studies Submitted to: Timothy Portlock, Advisor Hunter College Lee Quinby, Director Macaulay Honors College Thesis Colloquium 9 May 2012 Contents I. Introduction: Designing Digital Spaces II. Theoretical Framework a. Intertextuality in the visual design of video games and other media b. Examining the established visual iconography of dystopian setting II. Textual Evidence a. Retrofuturism and the Decay of Civilization in Bioshock and Fallout b. Innocence, Iteration, and Nostalgia in Team Fortress and Limbo III. Conclusion 2 “Games help those in a polarized world take a position and play out the consequences.” The Twelve Propositions from a Critical Play Perspective Mary Flanagan, 2009 3 Designing Digital Spaces In everyday life, physical space serves a primary role in orientation — it is a “container or framework where things exist” (Mark 1991) and as a concept, it can be viewed through the lense of a multitude of disciplines that often overlap, including physics, architecture, geography, and theatre. We see the function of space in visual media — in film, where the concept of physical setting can be highly choreographed and largely an unchanging variable that comprises a final static shot, and in video games, where space can be implemented in a far more complex, less linear manner that underlines participation and system-level response. The artistry behind the fields of production design and visual design, in film and in video games respectively, are exemplified in works that engage the viewer or player in a profound or novel manner. -

ESPORTS a Guide for Public Libraries
ESPORTS A Guide for Public Libraries 1 Contents Introduction…………….….……….………….…………3 Esports 101….……….….……….………….….….…….4 What Are Esports? Why Are Esports a Good Fit for Libraries? Esports & the Public Library……….…….…….………6 Making a Library Team Other Ways Libraries Can Interact with Video Games Partnerships….……………..…….……………….….….9 Local Partners North America Scholastic Esports Federation Technical Requirements…….………..….……….……10 Creating Internet Videos….…………….……….……12 Recording Editing Uploading IP & Privacy Considerations…………….…………….15 IP Considerations for Video Sharing Privacy A Note on ESRB Ratings Glossary………….……….……….……….……………18 Acknowledgements…….……….………..……………28 Further Reading….….……….…..………….……….…29 URLs……..……….….….……….……………………….30 2 Introduction In September 2019, Pottsboro Area Library in Pottsboro, TX, began an esports program funded by a IMLS grant. With ten new gaming computers and a vastly improved internet connection, Pottsboro Library has acted as a staging location for an esports team in association with Pottsboro High School, opening new hours on Saturdays for the team to practice in private. This collaboration also includes the esports club of nearby Austin College, whose students serve as mentors for the library’s club, and the North America Scholastic Esports Federation (NASEF), which has provided information and assistance in setting up the team to play in its high school league. In addition to being used by the team, four of the gaming computers are open for public use, which has attracted younger patrons to the library and provides new options for children and young adults in an area where internet access is otherwise extremely limited. This guide is intended for public libraries that are interested in esports or video games for any reason—to increase participation of young adults in library programming, to encourage technological skills and literacy, to provide a space for young people to gather and practice teamwork, etc. -

GME - Q2 2014 Gamestop Corp Earnings Call
THOMSON REUTERS STREETEVENTS EDITED TRANSCRIPT GME - Q2 2014 GameStop Corp Earnings Call EVENT DATE/TIME: AUGUST 21, 2014 / 9:00PM GMT OVERVIEW: GME reported 2Q14 consolidated global sales of $1.73b, consolidated global net earnings of $24.6m and diluted EPS of $0.22. Expects 2014 diluted EPS to be $3.40-3.70 and 3Q14 diluted EPS to be $0.58-0.64. THOMSON REUTERS STREETEVENTS | www.streetevents.com | Contact Us ©2015 Thomson Reuters. All rights reserved. Republication or redistribution of Thomson Reuters content, including by framing or similar means, is prohibited without the prior written consent of Thomson Reuters. 'Thomson Reuters' and the Thomson Reuters logo are registered trademarks of Thomson Reuters and its affiliated companies. AUGUST 21, 2014 / 9:00PM, GME - Q2 2014 GameStop Corp Earnings Call CORPORATE PARTICIPANTS Tony Bartel GameStop Corporation - President Rob Lloyd GameStop Corporation - CFO Mike Mauler GameStop Corporation - EVP of International Mike Hogan GameStop Corporation - EVP - Strategic Business CONFERENCE CALL PARTICIPANTS Tony Wible Janney Capital Markets - Analyst David Magee SunTrust Robinson Humphrey - Analyst Curtis Nagle BofA Merrill Lynch - Analyst Brian Nagel Oppenheimer & Co. - Analyst Arvind Bhatia Sterne, Agee & Leach, Inc. - Analyst Edward Williams BMO Capital Markets - Analyst Sean McGowan Needham & Company - Analyst PRESENTATION Operator Good day, and welcome to GameStop's second-quarter 2014 earnings conference call. (Operator Instructions) I would like to remind you that this call is covered by the Safe Harbor disclosure containing GameStop's public documents, and is the property of GameStop. It is not for rebroadcast or use by any other party, without the prior written consent of GameStop. -

Design Patterns and Analysis of Player Behavior in First-Person Shooter Levels
UNIVERSITY OF CALIFORNIA SANTA CRUZ THE SCIENCE OF LEVEL DESIGN: DESIGN PATTERNS AND ANALYSIS OF PLAYER BEHAVIOR IN FIRST-PERSON SHOOTER LEVELS A dissertation submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in COMPUTER SCIENCE by Kenneth M. Hullett September 2012 The Dissertation of Kenneth M. Hullett is approved: _______________________________ Professor E. James Whitehead, Chair _______________________________ Associate Professor Travis Seymour _______________________________ Assistant Professor Arnav Jhala _____________________________ Tyrus Miller Vice Provost and Dean of Graduate Studies Copyright © by Kenneth M. Hullett 2012 TABLE OF CONTENTS Table of Contents ......................................................................................................... iii List of Figures ............................................................................................................ xiii List of Tables ............................................................................................................ xvii ABSTRACT ................................................................................................................ xx Dedication .................................................................................................................. xxi Acknowledgments..................................................................................................... xxii Chapter 1: Introduction ...............................................................................................