Development of Computational Resources for Predicting Disease Resistance Genes and Mapping Ngs- Transcripts to Secondary Metabolism in Plants
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Theoretical Study of the Tryptophan Synthase Enzyme Reaction Network
A Theoretical Study of the Tryptophan Synthase Enzyme Reaction Network Dissertation zur Erlangung des akademischen Grades doctor rerum naturalium (Dr. rer. nat.) im Fach Chemie Spezialisierung: Physikalische und theoretische Chemie Eingereicht an der Mathematisch-Naturwissenschaftlichen Fakult¨at der Humboldt-Universit¨at zu Berlin von Dimitri Loutchko Pr¨asidentin der Humboldt-Universit¨atzu Berlin Prof. Dr.-Ing. Dr. Sabine Kunst Dekan der Mathematisch-Naturwissenschaftlichen Fakult¨at Prof. Dr. Elmar Kulke 1. Gutachter: Prof. Dr. Gerhard Ertl 2. Gutachter: Prof. Dr. Klaus Rademann 3. Gutachter: Prof. Dr. Yannick de Decker Tag der m¨undlichen Pr¨ufung:09.07.2018 ii Abstract iii Abstract The channeling enzyme tryptophan synthase provides a paradigmatic example of a chemical nanomachine. It catalyzes the biosynthesis of tryptophan from serine and indole glycerol phos- phate. As a single macromolecule, it possesses two distinct catalytic subunits and implements 13 different elementary reaction steps. A complex pattern of allosteric regulation is involved in its operation. The catalytic activity in a subunit is enhanced or inhibited depending on the state of the other subunit. The gates controlling arrival and release of the ligands can become open or closed depending on the chemical states. The intermediate product indole is directly channeled within the protein from one subunit to another, so that it is never released into the solution around it. In this thesis, the first single-molecule kinetic model of the enzyme is proposed and analyzed. All its transition rate constants are extracted from available experimental data, and thus, no fitting parameters are employed. Numerical simulations reveal strong correlations in the states of the active centers and the emergent synchronization of intramolecular processes in tryptophan synthase. -

Directed Evolution of the Tryptophan Synthase Β-Subunit for Stand-Alone Function Recapitulates Allosteric Activation
Directed evolution of the tryptophan synthase β-subunit for stand-alone function recapitulates allosteric activation Andrew R. Buller1, Sabine Brinkmann-Chen1, David K. Romney, Michael Herger, Javier Murciano-Calles, and Frances H. Arnold2 Division of Chemistry and Chemical Engineering, California Institute of Technology, Pasadena, CA 91125 Edited by Alan R. Fersht, Medical Research Council Laboratory of Molecular Biology, Cambridge, United Kingdom, and approved October 16, 2015 (received for review August 17, 2015) Enzymes in heteromeric, allosterically regulated complexes cata- associated with open, partially closed, and fully closed states lyze a rich array of chemical reactions. Separating the subunits of during the catalytic cycle (2, 4, 6). such complexes, however, often severely attenuates their catalytic TrpS is a naturally promiscuous enzyme complex: the model activities, because they can no longer be activated by their protein system from S. typhimurium catalyzes its β-substitution reaction partners. We used directed evolution to explore allosteric regula- with most haloindoles, methylindoles, and aminoindoles, along tion as a source of latent catalytic potential using the β-subunit of with an assortment of nonindole nucleophiles for C–S, C–N, and – tryptophan synthase from Pyrococcus furiosus (PfTrpB). As part of C C bond formation (7). Such noncanonical amino acids (NCAAs) its native αββα complex, TrpB efficiently produces tryptophan and have diverse applications in chemical biology (8), serve as inter- tryptophan analogs; activity drops considerably when it is used as mediates in the synthesis of natural products (9, 10), and are priv- a stand-alone catalyst without the α-subunit. Kinetic, spectro- ileged scaffolds for the development of pharmaceuticals (11). -

(12) United States Patent (10) Patent No.: US 7,094,568 B2 Kozlowski Et Al
US007094568B2 (12) United States Patent (10) Patent No.: US 7,094,568 B2 Kozlowski et al. (45) Date of Patent: Aug. 22, 2006 (54) METHOD FOR PRODUCING PROTEINS WO WO O1, 57198 A3 2, 2002 TAGGED AT THE N- OR C-TERMINUS (75) Inventors: Roland Kozlowski, Babraham (GB); OTHER PUBLICATIONS Michael B. McAndrew, Babraham (GB); Jonathan Michael Blackburn, Bordini, E., and Hamdan, M., “Investigation of Some Covalent and Cambridge (GB); Michelle Anne Noncovalent Complexes by Matrix-assisted Laser Desorption/Ion Mulder, Capetown (ZA); Mitali ization Time-of-flight and Electrospray Mass Spectrometry.” Rapid Commun. Mass Spectrom. 13:1143-1151, John Wiley & Sons, Ltd. Samaddar, Hyderabad (IN) (1999). Cai, J., et al., “Functional Expression of Multidrug Resistance (73) Assignee: Sense Proteomic Ltd., (GB) Protein 1 in Pichia pastoris.” Biochemistry 40:8307-8316, Ameri can Chemical Society (Jun. 2001). (*) Notice: Subject to any disclaimer, the term of this DeRisi, J., et al., “Use of a cDNA microarray to analyse gene patent is extended or adjusted under 35 expression patterns in human cancer,” Nat. Genet. 14:457-460, U.S.C. 154(b) by 477 days. Nature Publishing Co. (1996). Doellgast, G.J., et al., “Sensitive Enzyme-Linked Immunosorbent (21) Appl. No.: 10/114,334 Assay for Detection of Clostridium botulinum Neurotoxins A, B, and E Using Signal Amplification via Enzyme-Linked Coagulation (22) Filed: Apr. 3, 2002 Assay.” J. Clin. Microbiol. 3 1:2402-2409, American Society for Microbiology (1993). (65) Prior Publication Data Giuliani, C.D., et al., “Expression of an active recombinant lysine US 2003 FOOT3811 A1 Apr. 17, 2003 49 phospholipase A myotoxin as a fusion protein in bacteria.” Toxicon 39:1595-1600, Elsevier Science Ltd. -

Structure and Conformational Dynamics of Fatty Acid Synthases
Structure and Conformational Dynamics of Fatty Acid Synthases Inauguraldissertation zur Erlangung der Würde eines Doktors der Philosophie vorgelegt der Philosophisch-Naturwissenschaftlichen Fakultät der Universität Basel von Friederike Maria Carola Benning aus Deutschland Basel, 2017 Originaldokument gespeichert auf dem Dokumentenserver der Universität Basel edoc.unibas.ch Genehmigt von der Philosophisch-Naturwissenschaftlichen Fakultät auf Antrag von Prof. Dr. Timm Maier Prof. Dr. Sebastian Hiller Basel, den 20.06.2017 Prof. Dr. Martin Spiess Dekan 2 3 4 I Abstract Multistep reactions rely on substrate channeling between active sites. Carrier protein- based enzyme systems constitute the most versatile class of shuttling systems due to their capability of linking multiple catalytic centers. In eukaryotes and some bacteria, these systems have evolved to multifunctional enzymes, which integrate all functional domains involved into one or more giant polypeptide chains. The metazoan fatty acid synthase (FAS) is a key paradigm for carrier protein-based multienzymes. It catalyzes the de novo biosynthesis of fatty acids from carbohydrate-derived precursors in more than 40 individual reactions steps. Its seven functional domains are encoded on one polypeptide chain, which assembles into an X-shaped dimer for activity. The dimer features two lateral reaction clefts, each equipped with a full set of active sites and a flexibly tethered carrier protein. Substrate loading and condensation in the condensing region are structurally and functionally separated from the b-carbon processing domains in the modifying region. At the beginning of this thesis, only a single crystal structure of an intact metazoan FAS was known. FAS, in particular its modifying region, displays extensive conformational variability, according to electron microscopy (EM) studies. -

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -

A Genomic Survey of Two Dinotoms
A GENOMIC SURVEY OF TWO DINOTOMS by Behzad Imanian MSc., The University of British Columbia, 2006 BSc., The University of British Columbia, 2002 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY in THE FACULTY OF GRADUATE STUDIES (Botany) THE UNIVERSITY OF BRITISH COLUMBIA (Vancouver) April 2013 © Behzad Imanian, 2013 Abstract Endosymbiosis has played a major role in shaping eukaryotic cells, their success and diversity. At the base of the eukaryotic tree, an α-proteobacterium endosymbiont in a protoeukaryotic cell was converted into the mitochondrion through its reductive evolution, endosymbiotic gene transfer (EGT) and the development of a protein targeting system to direct the products of the transferred genes to this organelle. Similar events mark the plastid evolution from a cyanobacterium. However, the primary endosymbiosis of plastid, unlike the mitochondrion, was followed by the secondary and tertiary movement of this organelle between eukaryotes through analogous endosymbiotic reduction, EGT and evolution of a protein targeting system and many subsequent independent losses from different eukaryotic lineages. The obligate tertiary diatom endosymbiont in a small group of dinoflagellates called ‘dinotoms’ is exceptional in that it retains most of its ancestral characters including a large nucleus, its own mitochondria, plastids and many other eukaryotic organelles and structures in a large cytoplasm all enclosed in and separated from its dinoflagellate host by a single membrane. This level of conservation of ancestral features in the endosymbiont suggests an early stage of integration. In order to investigate the impacts of endosymbiosis on the organelle genomes and to determine the extent of EGT and the contribution of the host nuclear genome to the proteomes of the organelles, I conducted mass pyrosequencing of the A+T-rich portion of the DNA extracted from two dinotoms, Durinskia baltica and Kryptoperidinium foliaceum, and the SL cDNA library constructed for D. -
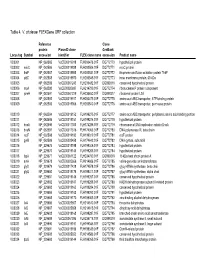
Table 4. V. Cholerae Flexgene ORF Collection
Table 4. V. cholerae FLEXGene ORF collection Reference Clone protein PlasmID clone GenBank Locus tag Symbol accession identifier FLEX clone name accession Product name VC0001 NP_062585 VcCD00019918 FLH200476.01F DQ772770 hypothetical protein VC0002 mioC NP_062586 VcCD00019938 FLH200506.01F DQ772771 mioC protein VC0003 thdF NP_062587 VcCD00019958 FLH200531.01F DQ772772 thiophene and furan oxidation protein ThdF VC0004 yidC NP_062588 VcCD00019970 FLH200545.01F DQ772773 inner membrane protein, 60 kDa VC0005 NP_062589 VcCD00061243 FLH236482.01F DQ899316 conserved hypothetical protein VC0006 rnpA NP_062590 VcCD00025697 FLH214799.01F DQ772774 ribonuclease P protein component VC0007 rpmH NP_062591 VcCD00061229 FLH236450.01F DQ899317 ribosomal protein L34 VC0008 NP_062592 VcCD00019917 FLH200475.01F DQ772775 amino acid ABC transporter, ATP-binding protein VC0009 NP_062593 VcCD00019966 FLH200540.01F DQ772776 amino acid ABC transproter, permease protein VC0010 NP_062594 VcCD00019152 FLH199275.01F DQ772777 amino acid ABC transporter, periplasmic amino acid-binding portion VC0011 NP_062595 VcCD00019151 FLH199274.01F DQ772778 hypothetical protein VC0012 dnaA NP_062596 VcCD00017363 FLH174286.01F DQ772779 chromosomal DNA replication initiator DnaA VC0013 dnaN NP_062597 VcCD00017316 FLH174063.01F DQ772780 DNA polymerase III, beta chain VC0014 recF NP_062598 VcCD00019182 FLH199319.01F DQ772781 recF protein VC0015 gyrB NP_062599 VcCD00025458 FLH174642.01F DQ772782 DNA gyrase, subunit B VC0016 NP_229675 VcCD00019198 FLH199346.01F DQ772783 hypothetical protein -

A Study of Protein Dynamics and Cofactor Interactions in Photosystem I
A STUDY OF PROTEIN DYNAMICS AND COFACTOR INTERACTIONS IN PHOTOSYSTEM I A Dissertation Presented to The Academic Faculty By Shana L. Bender In Partial Fulfillment of the Requirements for the Degree Doctorate of Philosophy in the School of Chemistry and Biochemistry Georgia Institute of Technology December 2008 A STUDY OF PROTEIN DYNAMICS AND COFACTOR INTERACTIONS IN PHOTOSYSTEM I Approved by: Dr. Bridgette Barry, Advisor Dr. Ingeborg Schmidt-Krey School of Chemistry and Biochemistry School of Biology Georgia Institute of Technology Georgia Institute of Technology Dr. Donald Doyle Dr. Nael McCarty School of Chemistry and Biochemistry Department of Pediatrics Georgia Institute of Technology Emory University Dr. Wendy Kelly School of Chemistry and Biochemistry Georgia Institute of Technology Date Approved: October 15, 2008 ACKNOWLEDGEMENTS I would like to thank my parents, who have given my strength, moral support and practical advice throughout my educational endeavors. I would also like to thank my husband who has always put my goals and education above his own ambitions. I would like to acknowledge my entire family for their constant support in my education. I would like to thank my grandparents who have kept me in their prayers, and my sister who has never doubted my career goals. I would like to acknowledge my advisor, Dr. Bridgette Barry for her valuable support throughout the years. She has been a great advisor, always challenging me to think critically. She has helped me become a better scientist. I would like to thank the past members of the Barry group: Dr. Idelisa Ayala who trained me, Dr. Colette Sacksteder who taught me to be critical of everything, and Dr. -

Genome-Scale Metabolic Network Analysis and Drug Targeting of Multi-Drug Resistant Pathogen Acinetobacter Baumannii AYE
Electronic Supplementary Material (ESI) for Molecular BioSystems. This journal is © The Royal Society of Chemistry 2017 Electronic Supplementary Information (ESI) for Molecular BioSystems Genome-scale metabolic network analysis and drug targeting of multi-drug resistant pathogen Acinetobacter baumannii AYE Hyun Uk Kim, Tae Yong Kim and Sang Yup Lee* E-mail: [email protected] Supplementary Table 1. Metabolic reactions of AbyMBEL891 with information on their genes and enzymes. Supplementary Table 2. Metabolites participating in reactions of AbyMBEL891. Supplementary Table 3. Biomass composition of Acinetobacter baumannii. Supplementary Table 4. List of 246 essential reactions predicted under minimal medium with succinate as a sole carbon source. Supplementary Table 5. List of 681 reactions considered for comparison of their essentiality in AbyMBEL891 with those from Acinetobacter baylyi ADP1. Supplementary Table 6. List of 162 essential reactions predicted under arbitrary complex medium. Supplementary Table 7. List of 211 essential metabolites predicted under arbitrary complex medium. AbyMBEL891.sbml Genome-scale metabolic model of Acinetobacter baumannii AYE, AbyMBEL891, is available as a separate file in the format of Systems Biology Markup Language (SBML) version 2. Supplementary Table 1. Metabolic reactions of AbyMBEL891 with information on their genes and enzymes. Highlighed (yellow) reactions indicate that they are not assigned with genes. No. Metabolism EC Number ORF Reaction Enzyme R001 Glycolysis/ Gluconeogenesis 5.1.3.3 ABAYE2829 -

Untersuchungen Von Amin Transaminasen Und Ihre
! " # # # $ %& ' ()(*(+), & -# ' *.(/ 0 12 ( 0 1" 34 * 0 152 3 1 0 **.(*.(6 ! "! # $% " & ' " !" # ##$ % " ! $ " !" ##$ & % ' " !" ###$ ( "! ( # )* *+ * %+ ,- . +-+- /!" #0$ " " * " )1 % * " &. & '"1' 2 3- !" 0$ . * " "!" #0$4 4 " ! $% " 3)1. +-+- / !" 0#$ * %+ ! $. +-+- /!" 0#$ ) $ ( * + , - '"1* '' '' :&!=$ :- & " !=,$ &5 & + : :+ ,6 " :.9 , * 78 * " , "", 3 2> & &3 =&8 =+ & -'/+ , ' &5 & + =<= =+ /?,, 9& " =.= =+ /?,, 6& 6& + =+ =+ 6.: 6 " 0'6 ;8 5 8 @ @ '- 5& 5 - & + " #9& #9 " <& <"& + @ 7 @ '- " .2 ./ 8== 8'/+, + ,+ /,, A %#=3)/ B 1'- '"1* )1 3 %# C * " 1' - & %, " 7"+ # - * D " 3 # *+ * = " - 6 - " =* " * ' - '"+- 9 " *+ - ) 9 " !*+"" $ & )"3 " 7"+ * D * ' B 6 " *+ ' * " ' =' %'3 % ', " * E3 ! $ " !$ " ' F % ' * - B % " !$ " ' " % .F -" = B *7 : * " ' & '" B)1! $" -3" C ' )"3 % " ! $ " -* G - % ' " ' )- ' %+ - " " # " " . B - ) " ' & '" E3 - -

An Investigation of the Molecular Determinants of Substrate Channeling and Allosteric Activation in Aldolase-Dehydrogenase Complexes
An Investigation of the Molecular Determinants of Substrate Channeling and Allosteric Activation in Aldolase-Dehydrogenase Complexes By Jason Carere A Thesis presented to The University of Guelph In partial fulfillment of requirements for the degree of Doctor of Philosophy in Molecular and Cellular Biology Guelph, Ontario, Canada © Jason Carere, April, 2013 Abstract An Investigation of the Molecular Determinants of Substrate Channeling and Allosteric Activation in Aldolase-Dehydrogenase Complexes Jason Carere Advisor: University of Guelph 2013 Stephen Seah The aldolase-dehydrogenase complex catalyzes the last two steps in the microbial meta- cleavage pathway of various aromatic compounds including polychlorinated biphenyls (bph pathway) and cholesterol (hsa pathway). The aldolase, BphI, cleaves 4-hydroxy-2-oxoacids to produce pyruvate and an aldehyde. Linear aldehydes of up to six carbons long and branched isobutyraldehyde were directly channeled to the aldehyde dehydrogenase BphJ, via a molecular tunnel, with greater than 80% efficiency. The molecular tunnel is narrow in positions lined by Gly-322 and Gly-323 in the aldolase. BphI variants G322F, G322L and G323F were found to block aldehyde channeling. The replacement of Asn-170 in BphJ with alanine and aspartate did not substantially alter aldehyde channeling efficiencies, thus disproving a previous hypothesis that hydrogen bonding between the Asn-170 and the nicotinamide cofactor induces the opening of the exit of the tunnel. The H20A and Y290F BphI variants displayed significantly reduced aldehyde channeling efficiencies indicating that these residues control the entry and exit of substrates and products from the aldolase reaction. The BphI reaction was activated by NADH binding to BphJ in the wild-type enzyme and channel blocked variants. -

Ammonia Generation by Tryptophan Synthase Drives a Key Genetic Difference Between Genital and Ocular Chlamydia Trachomatis Isolates
Ammonia generation by tryptophan synthase drives a key genetic difference between genital and ocular Chlamydia trachomatis isolates Shardulendra P. Sherchanda and Ashok Aiyara,1 aDepartment of Microbiology, Immunology, and Parasitology, Louisiana State University Health Sciences Center New Orleans, New Orleans, LA 70112 Edited by Ralph R. Isberg, Tufts University School of Medicine, Boston, MA, and approved April 19, 2019 (received for review December 19, 2018) A striking difference between genital and ocular clinical isolates of the microbiome at the site of infection produces indole, permitting Chlamydia trachomatis is that only the former express a functional chlamydial tryptophan synthase to generate tryptophan and thus tryptophan synthase and therefore can synthesize tryptophan by circumvent host-imposed tryptophan starvation (3, 4, 6, 7). The indole salvage. Ocular isolates uniformly cannot use indole due to composition of the cervicovaginal microbiome indicates the pres- inactivating mutations within tryptophan synthase, indicating a ence of indole-producing genera during dysbiotic conditions, pro- selection against maintaining this enzyme in the ocular environ- viding a strong reason for genital isolates to maintain an active ment. Here, we demonstrate that this selection occurs in two tryptophan synthase (6, 7). In contrast, factors that drive the loss of steps. First, specific indole derivatives, produced by the human gut tryptophan synthase in the majority of oculotropic strains are un- microbiome and present in serum, rapidly induce expression of C. tra- clear and the focus of this report (5). chomatis tryptophan synthase, even under conditions of tryptophan Tryptophan synthase has two α-subunits, encoded by trpA, and sufficiency. We demonstrate that these indole derivatives function by two β-subunits, encoded by trpB (11, 12).