Emerging Roles of Protein Disulfide Isomerase in Cancer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Primate Specific Retrotransposons, Svas, in the Evolution of Networks That Alter Brain Function
Title: Primate specific retrotransposons, SVAs, in the evolution of networks that alter brain function. Olga Vasieva1*, Sultan Cetiner1, Abigail Savage2, Gerald G. Schumann3, Vivien J Bubb2, John P Quinn2*, 1 Institute of Integrative Biology, University of Liverpool, Liverpool, L69 7ZB, U.K 2 Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK 3 Division of Medical Biotechnology, Paul-Ehrlich-Institut, Langen, D-63225 Germany *. Corresponding author Olga Vasieva: Institute of Integrative Biology, Department of Comparative genomics, University of Liverpool, Liverpool, L69 7ZB, [email protected] ; Tel: (+44) 151 795 4456; FAX:(+44) 151 795 4406 John Quinn: Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK, [email protected]; Tel: (+44) 151 794 5498. Key words: SVA, trans-mobilisation, behaviour, brain, evolution, psychiatric disorders 1 Abstract The hominid-specific non-LTR retrotransposon termed SINE–VNTR–Alu (SVA) is the youngest of the transposable elements in the human genome. The propagation of the most ancient SVA type A took place about 13.5 Myrs ago, and the youngest SVA types appeared in the human genome after the chimpanzee divergence. Functional enrichment analysis of genes associated with SVA insertions demonstrated their strong link to multiple ontological categories attributed to brain function and the disorders. SVA types that expanded their presence in the human genome at different stages of hominoid life history were also associated with progressively evolving behavioural features that indicated a potential impact of SVA propagation on a cognitive ability of a modern human. -

Anti-Inflammatory Role of Curcumin in LPS Treated A549 Cells at Global Proteome Level and on Mycobacterial Infection
Anti-inflammatory Role of Curcumin in LPS Treated A549 cells at Global Proteome level and on Mycobacterial infection. Suchita Singh1,+, Rakesh Arya2,3,+, Rhishikesh R Bargaje1, Mrinal Kumar Das2,4, Subia Akram2, Hossain Md. Faruquee2,5, Rajendra Kumar Behera3, Ranjan Kumar Nanda2,*, Anurag Agrawal1 1Center of Excellence for Translational Research in Asthma and Lung Disease, CSIR- Institute of Genomics and Integrative Biology, New Delhi, 110025, India. 2Translational Health Group, International Centre for Genetic Engineering and Biotechnology, New Delhi, 110067, India. 3School of Life Sciences, Sambalpur University, Jyoti Vihar, Sambalpur, Orissa, 768019, India. 4Department of Respiratory Sciences, #211, Maurice Shock Building, University of Leicester, LE1 9HN 5Department of Biotechnology and Genetic Engineering, Islamic University, Kushtia- 7003, Bangladesh. +Contributed equally for this work. S-1 70 G1 S 60 G2/M 50 40 30 % of cells 20 10 0 CURI LPSI LPSCUR Figure S1: Effect of curcumin and/or LPS treatment on A549 cell viability A549 cells were treated with curcumin (10 µM) and/or LPS or 1 µg/ml for the indicated times and after fixation were stained with propidium iodide and Annexin V-FITC. The DNA contents were determined by flow cytometry to calculate percentage of cells present in each phase of the cell cycle (G1, S and G2/M) using Flowing analysis software. S-2 Figure S2: Total proteins identified in all the three experiments and their distribution betwee curcumin and/or LPS treated conditions. The proteins showing differential expressions (log2 fold change≥2) in these experiments were presented in the venn diagram and certain number of proteins are common in all three experiments. -

WO 2019/079361 Al 25 April 2019 (25.04.2019) W 1P O PCT
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2019/079361 Al 25 April 2019 (25.04.2019) W 1P O PCT (51) International Patent Classification: CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, C12Q 1/68 (2018.01) A61P 31/18 (2006.01) DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, C12Q 1/70 (2006.01) HR, HU, ID, IL, IN, IR, IS, JO, JP, KE, KG, KH, KN, KP, KR, KW, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, (21) International Application Number: MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, PCT/US2018/056167 OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, (22) International Filing Date: SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, 16 October 2018 (16. 10.2018) TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (25) Filing Language: English (84) Designated States (unless otherwise indicated, for every kind of regional protection available): ARIPO (BW, GH, (26) Publication Language: English GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, ST, SZ, TZ, (30) Priority Data: UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, 62/573,025 16 October 2017 (16. 10.2017) US TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, DK, EE, ES, FI, FR, GB, GR, HR, HU, ΓΕ , IS, IT, LT, LU, LV, (71) Applicant: MASSACHUSETTS INSTITUTE OF MC, MK, MT, NL, NO, PL, PT, RO, RS, SE, SI, SK, SM, TECHNOLOGY [US/US]; 77 Massachusetts Avenue, TR), OAPI (BF, BJ, CF, CG, CI, CM, GA, GN, GQ, GW, Cambridge, Massachusetts 02139 (US). -
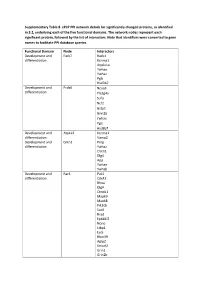
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

Analysis of the Dystrophin Interactome
Analysis of the dystrophin interactome Dissertation In fulfillment of the requirements for the degree “Doctor rerum naturalium (Dr. rer. nat.)” integrated in the International Graduate School for Myology MyoGrad in the Department for Biology, Chemistry and Pharmacy at the Freie Universität Berlin in Cotutelle Agreement with the Ecole Doctorale 515 “Complexité du Vivant” at the Université Pierre et Marie Curie Paris Submitted by Matthew Thorley born in Scunthorpe, United Kingdom Berlin, 2016 Supervisor: Simone Spuler Second examiner: Sigmar Stricker Date of defense: 7th December 2016 Dedicated to My mother, Joy Thorley My father, David Thorley My sister, Alexandra Thorley My fiancée, Vera Sakhno-Cortesi Acknowledgements First and foremost, I would like to thank my supervisors William Duddy and Stephanie Duguez who gave me this research opportunity. Through their combined knowledge of computational and practical expertise within the field and constant availability for any and all assistance I required, have made the research possible. Their overarching support, approachability and upbeat nature throughout, while granting me freedom have made this year project very enjoyable. The additional guidance and supported offered by Matthias Selbach and his team whenever required along with a constant welcoming invitation within their lab has been greatly appreciated. I thank MyoGrad for the collaboration established between UPMC and Freie University, creating the collaboration within this research project possible, and offering research experience in both the Institute of Myology in Paris and the Max Delbruck Centre in Berlin. Vital to this process have been Gisele Bonne, Heike Pascal, Lidia Dolle and Susanne Wissler who have aided in the often complex processes that I am still not sure I fully understand. -

Associated Gene Expression Profiles in Multiple Sclerosis Jeroen Melief1, Marie Orre2, Koen Bossers3, Corbert G
Melief et al. Acta Neuropathologica Communications (2019) 7:60 https://doi.org/10.1186/s40478-019-0705-7 RESEARCH Open Access Transcriptome analysis of normal-appearing white matter reveals cortisol- and disease- associated gene expression profiles in multiple sclerosis Jeroen Melief1, Marie Orre2, Koen Bossers3, Corbert G. van Eden1, Karianne G. Schuurman1, Matthew R. J. Mason1,3, Joost Verhaagen3, Jörg Hamann1,4 and Inge Huitinga1* Abstract Inter-individual differences in cortisol production by the hypothalamus–pituitary–adrenal (HPA) axis are thought to contribute to clinical and pathological heterogeneity of multiple sclerosis (MS). At the same time, accumulating evidence indicates that MS pathogenesis may originate in the normal-appearing white matter (NAWM). Therefore, we performed a genome-wide transcriptional analysis, by Agilent microarray, of post-mortem NAWM of 9 control subjects and 18 MS patients to investigate to what extent gene expression reflects disease heterogeneity and HPA- axis activity. Activity of the HPA axis was determined by cortisol levels in cerebrospinal fluid and by numbers of corticotropin-releasing neurons in the hypothalamus, while duration of MS and time to EDSS6 served as indicator of disease severity. Applying weighted gene co-expression network analysis led to the identification of a range of gene modules with highly similar co-expression patterns that strongly correlated with various indicators of HPA-axis activity and/or severity of MS. Interestingly, molecular profiles associated with relatively -

Ncomms14357.Pdf
ARTICLE Received 10 Aug 2016 | Accepted 16 Dec 2016 | Published 27 Feb 2017 DOI: 10.1038/ncomms14357 OPEN Connecting genetic risk to disease end points through the human blood plasma proteome Karsten Suhre1**, Matthias Arnold2,*, Aditya Mukund Bhagwat3,*, Richard J. Cotton3,*, Rudolf Engelke3,*, Johannes Raffler2,*, Hina Sarwath3,*, Gaurav Thareja1,*, Annika Wahl4,5,*, Robert Kirk DeLisle6, Larry Gold6, Marija Pezer7, Gordan Lauc7, Mohammed A. El-Din Selim8, Dennis O. Mook-Kanamori9, Eman K. Al-Dous10, Yasmin A. Mohamoud10, Joel Malek10, Konstantin Strauch11,12, Harald Grallert4,5,13, Annette Peters5,13,14, Gabi Kastenmu¨ller2,13, Christian Gieger4,5,13,** & Johannes Graumann3,**,w Genome-wide association studies (GWAS) with intermediate phenotypes, like changes in metabolite and protein levels, provide functional evidence to map disease associations and translate them into clinical applications. However, although hundreds of genetic variants have been associated with complex disorders, the underlying molecular pathways often remain elusive. Associations with intermediate traits are key in establishing functional links between GWAS-identified risk-variants and disease end points. Here we describe a GWAS using a highly multiplexed aptamer-based affinity proteomics platform. We quantify 539 associa- tions between protein levels and gene variants (pQTLs) in a German cohort and replicate over half of them in an Arab and Asian cohort. Fifty-five of the replicated pQTLs are located in trans. Our associations overlap with 57 genetic risk loci for 42 unique disease end points. We integrate this information into a genome-proteome network and provide an interactive web-tool for interrogations. Our results provide a basis for novel approaches to pharma- ceutical and diagnostic applications. -

Protein Disulfide Isomerases Are Promising Targets for Predicting the Survival and Tumor Progression in Glioma Patients
www.aging-us.com AGING 2020, Vol. 12, No. 3 Research Paper Protein disulfide isomerases are promising targets for predicting the survival and tumor progression in glioma patients Zhigang Peng1,*, Yu Chen2,*, Hui Cao3, Hecun Zou4, Xin Wan1, Wenjing Zeng4, Yanling Liu4, Jiaqing Hu5, Nan Zhang6, Zhiwei Xia7, Zhixiong Liu1, Quan Cheng1,4,8 1Department of Neurosurgery, Xiangya Hospital, Central South University, Changsha 410008, Hunan, P. R. China 2Department of Neurosurgery, The First Affiliated Hospital of Zhengzhou University, Zhengzhou 450001, Henan, P. R. China 3Department of Psychiatry, The Second People's Hospital of Hunan Province, The Affiliated Hospital of Hunan University of Chinese Medicine, Changsha 410007, Hunan, P. R. China 4Department of Clinical Pharmacology, Xiangya Hospital, Central South University, Changsha 410008, Hunan, P. R. China 5Department of Emergency, The Second People’s Hospital of Hunan Province, The Affiliated Hospital of Hunan University of Chinese Medicine, Changsha 410007, Hunan, P. R. China 6School of Bioinformatics Science and Technology, Harbin Medical University, Harbin 150081, Heilongjiang, P. R. China 7Department of Neurology, Xiangya Hospital, Central South University, Changsha 410008, Hunan, P. R. China 8Institute of Clinical Pharmacology, Central South University; Hunan Key Laboratory of Pharmacogenetics, Changsha 410078, Hunan, P. R. China *Equal contribution Correspondence to: Quan Cheng, Zhixiong Liu; email: [email protected], [email protected] Keywords: PDI family, PDI, GBM, glioma, prognosis Received: September 13, 2019 Accepted: January 7, 2020 Published: February 5, 2020 Copyright: Peng et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY 3.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. -

Predict AID Targeting in Non-Ig Genes Multiple Transcription Factor
Downloaded from http://www.jimmunol.org/ by guest on September 26, 2021 is online at: average * The Journal of Immunology published online 20 March 2013 from submission to initial decision 4 weeks from acceptance to publication Multiple Transcription Factor Binding Sites Predict AID Targeting in Non-Ig Genes Jamie L. Duke, Man Liu, Gur Yaari, Ashraf M. Khalil, Mary M. Tomayko, Mark J. Shlomchik, David G. Schatz and Steven H. Kleinstein J Immunol http://www.jimmunol.org/content/early/2013/03/20/jimmun ol.1202547 Submit online. Every submission reviewed by practicing scientists ? is published twice each month by http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://www.jimmunol.org/content/suppl/2013/03/20/jimmunol.120254 7.DC1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 26, 2021. Published March 20, 2013, doi:10.4049/jimmunol.1202547 The Journal of Immunology Multiple Transcription Factor Binding Sites Predict AID Targeting in Non-Ig Genes Jamie L. Duke,* Man Liu,†,1 Gur Yaari,‡ Ashraf M. Khalil,x Mary M. Tomayko,{ Mark J. Shlomchik,†,x David G. -

Glucagon-Like Peptide-1 Receptor Agonists Increase Pancreatic Mass by Induction of Protein Synthesis
Page 1 of 73 Diabetes Glucagon-like peptide-1 receptor agonists increase pancreatic mass by induction of protein synthesis Jacqueline A. Koehler1, Laurie L. Baggio1, Xiemin Cao1, Tahmid Abdulla1, Jonathan E. Campbell, Thomas Secher2, Jacob Jelsing2, Brett Larsen1, Daniel J. Drucker1 From the1 Department of Medicine, Tanenbaum-Lunenfeld Research Institute, Mt. Sinai Hospital and 2Gubra, Hørsholm, Denmark Running title: GLP-1 increases pancreatic protein synthesis Key Words: glucagon-like peptide 1, glucagon-like peptide-1 receptor, incretin, exocrine pancreas Word Count 4,000 Figures 4 Tables 1 Address correspondence to: Daniel J. Drucker M.D. Lunenfeld-Tanenbaum Research Institute Mt. Sinai Hospital 600 University Ave TCP5-1004 Toronto Ontario Canada M5G 1X5 416-361-2661 V 416-361-2669 F [email protected] 1 Diabetes Publish Ahead of Print, published online October 2, 2014 Diabetes Page 2 of 73 Abstract Glucagon-like peptide-1 (GLP-1) controls glucose homeostasis by regulating secretion of insulin and glucagon through a single GLP-1 receptor (GLP-1R). GLP-1R agonists also increase pancreatic weight in some preclinical studies through poorly understood mechanisms. Here we demonstrate that the increase in pancreatic weight following activation of GLP-1R signaling in mice reflects an increase in acinar cell mass, without changes in ductal compartments or β-cell mass. GLP-1R agonists did not increase pancreatic DNA content or the number of Ki67+ cells in the exocrine compartment, however pancreatic protein content was increased in mice treated with exendin-4 or liraglutide. The increased pancreatic mass and protein content was independent of cholecystokinin receptors, associated with a rapid increase in S6 kinase phosphorylation, and mediated through the GLP-1 receptor. -

Hormone and Inhibitor Treatment T47DM Cells Were Used for All Experiments Unless Otherwise Stated
Extended Data Extended Materials Methods Cell culture; hormone and inhibitor treatment T47DM cells were used for all experiments unless otherwise stated. For hormone induction experiments, cells were grown in RPMI medium without Phenol Red, supplemented with 10% dextran-coated charcoal-treated FBS (DCC/FBS) after 24 h in serum-free conditions; cells were incubated with R5020 (10 nM) or vehicle (ethanol) as described (Vicent et al. 2011). For hormone induction experiments in MCF7 cells a similar procedure was performed; cells were grown in DMEM medium without Phenol Red, supplemented with 10% dextran-coated charcoal-treated FBS (DCC/FBS) after 24 h in serum-free conditions; cells were incubated with Estradiol (10 nM) or vehicle (ethanol). PARG and PARP inhibition were carried out via incubating cells with 5uM TA (tannic acid) or 10uM 3AB (3-amino-benzamide) respectively 1 hour prior to hormone treatment. All transfections were performed using Lipofectamine2000 (Invitrogen) according to manufacturers instructions. PAR-capture ELISA Hormone and or inhibitor treatments were carried out as described, and sample preparation was carried out as follows: At the required time point, cells were washed twice with ice-cold PBS and scraped in lysis buffer (0.4 M NaCl, 1% Triton X-100) plus protease inhibitors. Cell suspensions were then incubated for 30 min on ice with periodic vortexing. The disrupted cell suspension was centrifuged at 10,000g for 10 min at 4°C, and the supernatant was recovered, snap-frozen, and stored at 80°C until required. Ninety-six-well black-walled plates were incubated with 2 ng/mL anti-PAR monoclonal antibody (Trevigen) in 50 mM sodium carbonate (pH 7.6) overnight at 4°C.