Ncomms14357.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Complement Factor H Deficiency and Endocapillary Glomerulonephritis Due to Paternal Isodisomy and a Novel Factor H Mutation
Genes and Immunity (2011) 12, 90–99 & 2011 Macmillan Publishers Limited All rights reserved 1466-4879/11 www.nature.com/gene ORIGINAL ARTICLE Complement factor H deficiency and endocapillary glomerulonephritis due to paternal isodisomy and a novel factor H mutation L Schejbel1, IM Schmidt2, M Kirchhoff3, CB Andersen4, HV Marquart1, P Zipfel5 and P Garred1 1Department of Clinical Immunology, Laboratory of Molecular Medicine, Rigshospitalet, Copenhagen, Denmark; 2Department of Pediatrics, Rigshospitalet, Copenhagen, Denmark; 3Department of Clinical Genetics, Rigshospitalet, Copenhagen, Denmark; 4Department of Pathology, Rigshospitalet, Copenhagen, Denmark and 5Department of Infection Biology, Leibniz Institute for Natural Product Research and Infection Biology, Jena, Germany Complement factor H (CFH) is a regulator of the alternative complement activation pathway. Mutations in the CFH gene are associated with atypical hemolytic uremic syndrome, membranoproliferative glomerulonephritis type II and C3 glomerulonephritis. Here, we report a 6-month-old CFH-deficient child presenting with endocapillary glomerulonephritis rather than membranoproliferative glomerulonephritis (MPGN) or C3 glomerulonephritis. Sequence analyses showed homozygosity for a novel CFH missense mutation (Pro139Ser) associated with severely decreased CFH plasma concentration (o6%) but normal mRNA splicing and expression. The father was heterozygous carrier of the mutation, but the mother was a non-carrier. Thus, a large deletion in the maternal CFH locus or uniparental isodisomy was suspected. Polymorphic markers across chromosome 1 showed homozygosity for the paternal allele in all markers and a lack of the maternal allele in six informative markers. This combined with a comparative genomic hybridization assay demonstrated paternal isodisomy. Uniparental isodisomy increases the risk of homozygous variations in other genes on the affected chromosome. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Primate Specific Retrotransposons, Svas, in the Evolution of Networks That Alter Brain Function
Title: Primate specific retrotransposons, SVAs, in the evolution of networks that alter brain function. Olga Vasieva1*, Sultan Cetiner1, Abigail Savage2, Gerald G. Schumann3, Vivien J Bubb2, John P Quinn2*, 1 Institute of Integrative Biology, University of Liverpool, Liverpool, L69 7ZB, U.K 2 Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK 3 Division of Medical Biotechnology, Paul-Ehrlich-Institut, Langen, D-63225 Germany *. Corresponding author Olga Vasieva: Institute of Integrative Biology, Department of Comparative genomics, University of Liverpool, Liverpool, L69 7ZB, [email protected] ; Tel: (+44) 151 795 4456; FAX:(+44) 151 795 4406 John Quinn: Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK, [email protected]; Tel: (+44) 151 794 5498. Key words: SVA, trans-mobilisation, behaviour, brain, evolution, psychiatric disorders 1 Abstract The hominid-specific non-LTR retrotransposon termed SINE–VNTR–Alu (SVA) is the youngest of the transposable elements in the human genome. The propagation of the most ancient SVA type A took place about 13.5 Myrs ago, and the youngest SVA types appeared in the human genome after the chimpanzee divergence. Functional enrichment analysis of genes associated with SVA insertions demonstrated their strong link to multiple ontological categories attributed to brain function and the disorders. SVA types that expanded their presence in the human genome at different stages of hominoid life history were also associated with progressively evolving behavioural features that indicated a potential impact of SVA propagation on a cognitive ability of a modern human. -

Anti-Inflammatory Role of Curcumin in LPS Treated A549 Cells at Global Proteome Level and on Mycobacterial Infection
Anti-inflammatory Role of Curcumin in LPS Treated A549 cells at Global Proteome level and on Mycobacterial infection. Suchita Singh1,+, Rakesh Arya2,3,+, Rhishikesh R Bargaje1, Mrinal Kumar Das2,4, Subia Akram2, Hossain Md. Faruquee2,5, Rajendra Kumar Behera3, Ranjan Kumar Nanda2,*, Anurag Agrawal1 1Center of Excellence for Translational Research in Asthma and Lung Disease, CSIR- Institute of Genomics and Integrative Biology, New Delhi, 110025, India. 2Translational Health Group, International Centre for Genetic Engineering and Biotechnology, New Delhi, 110067, India. 3School of Life Sciences, Sambalpur University, Jyoti Vihar, Sambalpur, Orissa, 768019, India. 4Department of Respiratory Sciences, #211, Maurice Shock Building, University of Leicester, LE1 9HN 5Department of Biotechnology and Genetic Engineering, Islamic University, Kushtia- 7003, Bangladesh. +Contributed equally for this work. S-1 70 G1 S 60 G2/M 50 40 30 % of cells 20 10 0 CURI LPSI LPSCUR Figure S1: Effect of curcumin and/or LPS treatment on A549 cell viability A549 cells were treated with curcumin (10 µM) and/or LPS or 1 µg/ml for the indicated times and after fixation were stained with propidium iodide and Annexin V-FITC. The DNA contents were determined by flow cytometry to calculate percentage of cells present in each phase of the cell cycle (G1, S and G2/M) using Flowing analysis software. S-2 Figure S2: Total proteins identified in all the three experiments and their distribution betwee curcumin and/or LPS treated conditions. The proteins showing differential expressions (log2 fold change≥2) in these experiments were presented in the venn diagram and certain number of proteins are common in all three experiments. -

WO 2019/079361 Al 25 April 2019 (25.04.2019) W 1P O PCT
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2019/079361 Al 25 April 2019 (25.04.2019) W 1P O PCT (51) International Patent Classification: CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, C12Q 1/68 (2018.01) A61P 31/18 (2006.01) DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, C12Q 1/70 (2006.01) HR, HU, ID, IL, IN, IR, IS, JO, JP, KE, KG, KH, KN, KP, KR, KW, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, (21) International Application Number: MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, PCT/US2018/056167 OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, (22) International Filing Date: SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, 16 October 2018 (16. 10.2018) TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (25) Filing Language: English (84) Designated States (unless otherwise indicated, for every kind of regional protection available): ARIPO (BW, GH, (26) Publication Language: English GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, ST, SZ, TZ, (30) Priority Data: UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, 62/573,025 16 October 2017 (16. 10.2017) US TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, DK, EE, ES, FI, FR, GB, GR, HR, HU, ΓΕ , IS, IT, LT, LU, LV, (71) Applicant: MASSACHUSETTS INSTITUTE OF MC, MK, MT, NL, NO, PL, PT, RO, RS, SE, SI, SK, SM, TECHNOLOGY [US/US]; 77 Massachusetts Avenue, TR), OAPI (BF, BJ, CF, CG, CI, CM, GA, GN, GQ, GW, Cambridge, Massachusetts 02139 (US). -

Complement Factor H Related Proteins (Cfhrs)
G Model MIMM-4208; No. of Pages 11 ARTICLE IN PRESS Molecular Immunology xxx (2013) xxx–xxx Contents lists available at SciVerse ScienceDirect Molecular Immunology jo urnal homepage: www.elsevier.com/locate/molimm Review Complement factor H related proteins (CFHRs) a,∗ a b,c b,d,e Christine Skerka , Qian Chen , Veronique Fremeaux-Bacchi , Lubka T. Roumenina a Department of Infection Biology, Leibniz Institute for Natural Product Research and Infection Biology, Jena, Germany b Centre de Recherche des Cordeliers, INSERM UMRS 872, Paris, France c Service d’Immunologie Biologique, Hôpital Européen Georges Pompidou, Paris, France d Université Paris Descartes Sorbonne Paris-Cité, Paris, France e Université Pierre et Marie Curie (UPMC-Paris-6), Paris, France a b s t r a c t a r t i c l e i n f o Factor H related proteins comprise a group of five plasma proteins: CFHR1, CFHR2, CFHR3, CFHR4 and Article history: CFHR5, and each member of this group binds to the central complement component C3b. Mutations, Received 1 May 2013 genetic deletions, duplications or rearrangements in the individual CFHR genes are associated with a Accepted 8 May 2013 Available online xxx number of diseases including atypical hemolytic uremic syndrome (aHUS), C3 glomerulopathies (C3 glomerulonephritis (C3GN), dense deposit disease (DDD) and CFHR5 nephropathy), IgA nephropathy, age related macular degeneration (AMD) and systemic lupus erythematosus (SLE). Although complement regulatory functions were attributed to most of the members of the CFHR protein family, the precise role of each CFHR protein in complement activation and the exact contribution to disease pathology is still unclear. -

Molecular and Epigenetic Features of Melanomas and Tumor Immune
Seremet et al. J Transl Med (2016) 14:232 DOI 10.1186/s12967-016-0990-x Journal of Translational Medicine RESEARCH Open Access Molecular and epigenetic features of melanomas and tumor immune microenvironment linked to durable remission to ipilimumab‑based immunotherapy in metastatic patients Teofila Seremet1,3*† , Alexander Koch2†, Yanina Jansen1, Max Schreuer1, Sofie Wilgenhof1, Véronique Del Marmol3, Danielle Liènard3, Kris Thielemans4, Kelly Schats5, Mark Kockx5, Wim Van Criekinge2, Pierre G. Coulie6, Tim De Meyer2, Nicolas van Baren6,7 and Bart Neyns1 Abstract Background: Ipilimumab (Ipi) improves the survival of advanced melanoma patients with an incremental long-term benefit in 10–15 % of patients. A tumor signature that correlates with this survival benefit could help optimizing indi- vidualized treatment strategies. Methods: Freshly frozen melanoma metastases were collected from patients treated with either Ipi alone (n: 7) or Ipi combined with a dendritic cell vaccine (TriMixDC-MEL) (n: 11). Samples were profiled by immunohistochemistry (IHC), whole transcriptome (RNA-seq) and methyl-DNA sequencing (MBD-seq). Results: Patients were divided in two groups according to clinical evolution: durable benefit (DB; 5 patients) and no clinical benefit (NB; 13 patients). 20 metastases were profiled by IHC and 12 were profiled by RNA- and MBD-seq. 325 genes were identified as differentially expressed between DB and NB. Many of these genes reflected a humoral and cellular immune response. MBD-seq revealed differences between DB and NB patients in the methylation of genes linked to nervous system development and neuron differentiation. DB tumors were more infiltrated by CD8+ and PD-L1+ cells than NB tumors. -
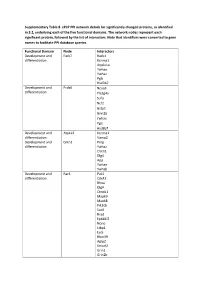
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

A Genome-Wide Association Study Identifies Key Modulators of Complement Factor H Binding to Malondialdehyde-Epitopes
A genome-wide association study identifies key modulators of complement factor H binding to malondialdehyde-epitopes Lejla Alica,b,c,1, Nikolina Papac-Milicevica,b,1,2, Darina Czamarad, Ramona B. Rudnicke, Maria Ozsvar-Kozmaa,b, Andrea Hartmanne, Michael Gurbisza, Gregor Hoermanna,f, Stefanie Haslinger-Huttera, Peter F. Zipfele,g, Christine Skerkae, Elisabeth B. Binderd, and Christoph J. Bindera,b,2 aDepartment of Laboratory Medicine, Medical University of Vienna, 1090 Vienna, Austria; bResearch Center for Molecular Medicine of the Austrian Academy of Sciences, 1090 Vienna, Austria; cDepartment of Medical Biochemistry, Faculty of Medicine, University of Sarajevo, 71000 Sarajevo, Bosnia and Herzegovina; dDepartment of Translational Research in Psychiatry, Max Planck Institute of Psychiatry, 80804 Munich, Germany; eDepartment of Infection Biology, Leibniz Institute for Natural Product Research and Infection Biology, 07745 Jena, Germany; fCentral Institute for Medical and Chemical Laboratory Diagnosis, University Hospital Innsbruck, 6020 Innsbruck, Austria; and gInstitute for Microbiology, Friedrich Schiller University, 07743 Jena, Germany Edited by Thaddeus Dryja, Harvard Medical School, Boston, MA, and approved March 17, 2020 (received for review August 12, 2019) Genetic variants within complement factor H (CFH), a major head-to-tail fashion. Moreover, its splice variant factor H-like alternative complement pathway regulator, are associated with protein 1 (FHL-1), consisting of the first seven SCRs of CFH, the development of age-related -

Analysis of the Dystrophin Interactome
Analysis of the dystrophin interactome Dissertation In fulfillment of the requirements for the degree “Doctor rerum naturalium (Dr. rer. nat.)” integrated in the International Graduate School for Myology MyoGrad in the Department for Biology, Chemistry and Pharmacy at the Freie Universität Berlin in Cotutelle Agreement with the Ecole Doctorale 515 “Complexité du Vivant” at the Université Pierre et Marie Curie Paris Submitted by Matthew Thorley born in Scunthorpe, United Kingdom Berlin, 2016 Supervisor: Simone Spuler Second examiner: Sigmar Stricker Date of defense: 7th December 2016 Dedicated to My mother, Joy Thorley My father, David Thorley My sister, Alexandra Thorley My fiancée, Vera Sakhno-Cortesi Acknowledgements First and foremost, I would like to thank my supervisors William Duddy and Stephanie Duguez who gave me this research opportunity. Through their combined knowledge of computational and practical expertise within the field and constant availability for any and all assistance I required, have made the research possible. Their overarching support, approachability and upbeat nature throughout, while granting me freedom have made this year project very enjoyable. The additional guidance and supported offered by Matthias Selbach and his team whenever required along with a constant welcoming invitation within their lab has been greatly appreciated. I thank MyoGrad for the collaboration established between UPMC and Freie University, creating the collaboration within this research project possible, and offering research experience in both the Institute of Myology in Paris and the Max Delbruck Centre in Berlin. Vital to this process have been Gisele Bonne, Heike Pascal, Lidia Dolle and Susanne Wissler who have aided in the often complex processes that I am still not sure I fully understand. -

Emerging Roles of Protein Disulfide Isomerase in Cancer
BMB Rep. 2017; 50(8): 401-410 BMB www.bmbreports.org Reports Invited Mini Review Emerging roles of protein disulfide isomerase in cancer Eunyoug Lee & Do Hee Lee* Department of Bio and Environmental Technology, Seoul Women’s University, Seoul 01797, Korea The protein disulfide isomerase (PDI) family is a group of secretory and membrane proteins (4). The PDI family is a multifunctional endoplasmic reticulum (ER) enzymes that group of ER enzymes responsible for the formation, breakage, mediate the formation of disulfide bonds, catalyze the and rearrangement of protein disulfide bond. PDI, the first ER cysteine-based redox reactions and assist the quality control of protein discovered as a folding catalyst, is a highly abundant client proteins. Recent structural and functional studies have ER protein constituting approximately 0.8% of a total protein demonstrated that PDI members not only play an essential role (5). Inside cells, S-S bond is formed by thiol-disulfide exchange in the proteostasis in the ER but also exert diverse effects in reactions in which electrons are initially transferred from the numerous human disorders including cancer and neurodege- reduced substrates to oxidized PDI. Reduced PDI is then nerative diseases. Increasing evidence suggests that PDI is regenerated (oxidized) by the FAD-linked sulfhydryl oxidase actively involved in the proliferation, survival, and metastasis Ero1, which generates H2O2 by transferring electrons directly of several types of cancer cells. Although the molecular onto oxygen (4, 6). The chemical aspects of thiol-disulfide mechanism by which PDI contributes to tumorigenesis and exchange reactions and the enzymatic properties of PDI and metastasis remains to be understood, PDI is now emerging as a its partners in oxidative protein folding are well-explained in new therapeutic target for cancer treatment. -

Associated Gene Expression Profiles in Multiple Sclerosis Jeroen Melief1, Marie Orre2, Koen Bossers3, Corbert G
Melief et al. Acta Neuropathologica Communications (2019) 7:60 https://doi.org/10.1186/s40478-019-0705-7 RESEARCH Open Access Transcriptome analysis of normal-appearing white matter reveals cortisol- and disease- associated gene expression profiles in multiple sclerosis Jeroen Melief1, Marie Orre2, Koen Bossers3, Corbert G. van Eden1, Karianne G. Schuurman1, Matthew R. J. Mason1,3, Joost Verhaagen3, Jörg Hamann1,4 and Inge Huitinga1* Abstract Inter-individual differences in cortisol production by the hypothalamus–pituitary–adrenal (HPA) axis are thought to contribute to clinical and pathological heterogeneity of multiple sclerosis (MS). At the same time, accumulating evidence indicates that MS pathogenesis may originate in the normal-appearing white matter (NAWM). Therefore, we performed a genome-wide transcriptional analysis, by Agilent microarray, of post-mortem NAWM of 9 control subjects and 18 MS patients to investigate to what extent gene expression reflects disease heterogeneity and HPA- axis activity. Activity of the HPA axis was determined by cortisol levels in cerebrospinal fluid and by numbers of corticotropin-releasing neurons in the hypothalamus, while duration of MS and time to EDSS6 served as indicator of disease severity. Applying weighted gene co-expression network analysis led to the identification of a range of gene modules with highly similar co-expression patterns that strongly correlated with various indicators of HPA-axis activity and/or severity of MS. Interestingly, molecular profiles associated with relatively