Exploring the Long Tail of (Malicious) Software Downloads
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
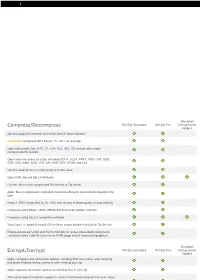
Compress/Decompress Encrypt/Decrypt
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

Building Joint Database on Curriculum, Syllabus and Reading Materials for Diplomatic Training Cooperation
BUILDING JOINT DATABASE ON CURRICULUM, SYLLABUS AND READING MATERIALS FOR DIPLOMATIC TRAINING COOPERATION DR. YAYAN GH MULYANA HEAD OF THE CENTER FOR EDUCATION & TRAINING MOFA INDONESIA HANOI, 23 OCTOBER 2019 @yayanghmulyana-oct-2019 WHY JOINT DATABASE? @yayanghmulyana-oct-2019 JOINT DATABASE – FILE SHARING FACILITATE THE PLACING, KEEPING, SHARING AS WELL AS RETRIEVING OF FILES/MATERIALS THAT RELATE TO DIPLOMATIC TRAINING IN A COLLECTIVE MANNER @yayanghmulyana-oct-2019 JOINT DATABASE – FILE SHARING A TOOL FOR INTERACTIVE AND LIVE ONLINE DISCUSSION AND EXCHANGE OF VIEWS CONCERNING FILES OR MATERIALS THAT RELATE TO DIPLOMATIC TRAINING @yayanghmulyana-oct-2019 JOINT DATABASE – FILE SHARING A RESERVOIR OF LESSONS LEARNED AND BEST PRACTICES THAT VALUE DIVERSITY AND RICHNESS IN THE EXPERIENCES OF DIPLOMATIC TRAINING @yayanghmulyana-oct-2019 ❑TECHNOLOGICAL TWO ASPECTS OF ❑CONTENTS JOINT DATABASE – FILE SHARING @yayanghmulyana-oct-2019 TYPES OF DATABASE - FILE SHARING @yayanghmulyana-oct-2019 TOP TEN FILE SHARING TOOLS JAMES A. MARTIN (COMPUTER WORLD, 17 SEPT 2019) @yayanghmulyana-oct-2019 TYPES OF DATABASE (1) AMAZON DRIVE: ❑ OFFERS ONLY BASIC FUNCTIONALITY. ❑ CAN SYNC YOUR ENTIRE DOCUMENTS FOLDER FROM YOUR COMPUTER, FOR INSTANCE, BUT YOU CAN’T CHOOSE SPECIFIC FOLDERS WITHIN THAT FOLDER TO SYNC. ❑ BEST SUITED FOR PHOTO BACKUP FOR PRIME MEMBERS, WHO GET UNLIMITED PHOTO STORAGE. ❑ 5GB FREE STORAGE FOR PRIME CUSTOMERS. @yayanghmulyana-oct-2019 TYPES OF DATABASE (2) BOX: ❑OFFERS A HEALTHY ECOSYSTEM OF INTEGRATED THIRD-PARTY APPS THAT MAKE THE SERVICES MORE ROBUST. ❑HAS ALWAYS BEEN GEARED TOWARD BUSINESSES AND ENTERPRISES, ❑10GB FREE STORAGE @yayanghmulyana-oct-2019 TYPES OF DATABASE (3) CITRIX SHAREFILE: ❑CAN SHARE FILES EASILY WITH CLIENTS, PARTNERS, CO-WORKERS AND OTHERS. -

Measurement and Analysis of Cyberlocker Services
WWW 2011 – Ph. D. Symposium March 28–April 1, 2011, Hyderabad, India Measurement and Analysis of Cyberlocker Services Aniket Mahanti University of Calgary Calgary, AB, Canada [email protected] ABSTRACT precursor to decentralized Peer-to-Peer (P2P) file sharing Cyberlocker Services (CLS) such as RapidShare and Megau- applications such as KaZaA and BitTorrent. P2P file shar- pload have recently become popular. The decline of Peer- ing was not restricted to music files, but included all sorts to-Peer (P2P) file sharing has prompted various services in- of content. The popularity of P2P file sharing surged and cluding CLS to replace it. We propose a comprehensive according to estimates was responsible for up to 60% of the multi-level characterization of the CLS ecosystem. We an- total Internet traffic in some regions during its peak [23]. swer three research questions: (a) what is a suitable mea- Recently, the popularity of Web 2.0 applications has caused surement infrastructure for gathering CLS workloads; (b) an increase in Web traffic, and P2P file sharing traffic ap- what are the characteristics of the CLS ecosystem; and (c) pears to be on the decline [12, 23, 24]. what are the implications of CLS on Web 2.0 (and the In- CLS differ from traditional P2P file sharing and other ternet). To the best of our knowledge, this work is the first new-age content sharing services. Many social media sites to characterize the CLS ecosystem. The work will highlight are restricted to sharing video files, while entertainment sites the content, usage, performance, infrastructure, quality of such as Hulu.com place geographic restrictions on its view- service, and evolution characteristics of CLS. -

Photos Copied" Box
Our photos have never been as scattered as they are now... Do you know where your photos are? Digital Photo Roundup Checklist www.theswedishorganizer.com Online Storage Edition Let's Play Digital Photo Roundup! Congrats on making the decision to start organizing your digital photos! I know the task can seem daunting, so hopefully this handy checklist will help get your moving in the right direction. LET'S ORGANIZE! To start organizing your digital photos, you must first gather them all into one place, so that you'll be able to sort and edit your collection. Use this checklist to document your family's online storage accounts (i.e. where you have photos saved online), and whether they are copied onto your Master hub (the place where you are saving EVERYTHING). It'll make the gathering process a whole lot easier if you keep a record of what you have already copied and what is still to be done. HERE'S HOW The services in this checklist are categorized, so that you only need to print out what applies to you. If you have an account with the service listed, simply check the "Have Account" box. When you have copied all the photos, check the "Photos Copied" box. Enter your login credentials under the line between the boxes for easy retrieval. If you don't see your favorite service on the list, just add it to one of the blank lines provided after each category. Once you are done, you should find yourself with all your digital images in ONE place, and when you do, check back on the blog for tools to help you with the next step in the organizing process. -

Characterizing the File Hosting Service Ecosystem
Characterizing the File Hosting Service Ecosystem Aniket Mahanti, Niklas Carlsson~, and Carey Williamson University of Calgary, Canada ~ Linköping University, Sweden ABSTRACT et al. [1] who studied traffic, usage, and performance File Hosting Services (FHS) such as Rapidshare and Mega- characteristics of a single FHS, namely Rapidshare. upload have recently become popular. The decline of P2P We propose a comprehensive characterization study file sharing has prompted various services including FHS to of FHS workloads. We study four popular FHS: Rapid- replace it. We propose a comprehensive multi-level charac- share, Megaupload, Hotfile, and Mediafire. Using a terization of the FHS ecosystem. We devise a measurement year-long dataset of HTTP transaction summaries col- framework to collect datasets from multiple vantage points. lected from a large university edge network, we charac- To the best of our knowledge, this work is the first to char- terize usage behaviour, content properties, service in- acterize the FHS ecosystem. The work will highlight the frastructure, and performance of these services. To get content, usage, performance, infrastructure, and quality of a global picture, we use a large crawl dataset and com- service characteristics of FHS. FHS can have significant im- pare and contrast the content properties of the services plications on Internet traffic, if these services were to sup- with locally observed characteristics. plant P2P as the dominant content sharing technology. A distinguishing feature of our work is the use of de- tailed Web transactions that allowed us to distinguish free and premium services based on user clickstreams. 1. INTRODUCTION We present a case study comparing FHS with P2P, and File Hosting Services (FHS) were originally designed show preliminary results highlighting content properties for file backup purposes and for uploading files that were and performance of FHS. -

Building a First Aid Kit for Data Breaches 06
Summer 2018 (vol. 12 issue 3) | www.csae.org EXCELLENCE BY ASSOCIATION BUILDING A FIRST AID KIT FOR DATA BREACHES 06 10 AI IN YOUR FUTURE Colorado 12 BACKING UP YOUR DATA Society of Association 22 SPOTLIGHT: ALEXANDRA MERRICK Executives TAKE YOUR ASSOCIATION TO NEW HEIGHTS. Book by December 31, 2018 and choose your reward. 50 - 150 Room Nights Choose One Reward 151 - 250 Room Nights Choose Two Rewards 251 - 350 Room Nights Choose Three Rewards 351 - 450 Room Nights Choose Four Rewards BOOK JUST ONE MEETING AND MAXIMIZE YOUR REWARDS BY BOOKING TWO RECEIVE GREAT REWARDS* OR MORE MEETINGS THROUGH 2025* • 3% credit to master on actualized room revenue • 5% credit to master on actualized room revenue • 5% discount on F&B • 10% discount on F&B • 1 per 45 lodging rooms comped • 1 per 35 lodging rooms comped • 25% off resort fee • 50% off resort fee • 3 Complimentary round trip airport transfers • 5 Complimentary round trip airport transfers • Complimentary WiFi in meeting space • Complimentary WiFi in meeting space • Complimentary one-night-stay gift certificate • Complimentary two-night-stay gift certificate • Complimentary catered happy hour or coffee break • Complimentary catered happy hour or coffee break • Complimentary board meeting with F&B break • Complimentary board meeting with F&B break for up to 12 people for up to 12 people • Complimentary one-hour yoga class per guest • Complimentary one-hour yoga class per guest Visit vailresortsmeetings.com/associationpromotion to learn more VAILRESORTSMEETINGS.COM | 970.496.6557 | [email protected] VAIL | BEAVER CREEK | WHISTLER | BRECKENRIDGE PARK CITY | KEYSTONE | LAKE TAHOE | JACKSON HOLE MEETINGS & EVENTS *Offer valid for bookings contracted through December 31, 2018. -

The Mystery of Blend- and Landwatermasks
The Mystery of Blend- and LandWaterMasks Introduction Blend- and LandWaterMask’s are essential for Photoreal Scenery Creation. This process is also the most time consuming and tedious part if done seriously and exactly. For this process sophisticated Painting programs are required like Adobe Photoshop, Corel Painter, Corel Photo Paint Pro, Autodesk SketchBook Pro, GNU Image Manipulation Program (GIMP), IrfanView, Paint.NET or any Photo Painting Program which supports Layers and Alpha-channels can be used, depending on the taste and requirements of the user. Searching the Internet reveals that a lot of people have problems – including the Author of this document himself – with the above mentioned subject. One important note: This is not a tutorial on how to create Blend- and LandWaterMasks because the Internet contains quiet a lot of tutorials in written form and in video form, some are good, some are bullshit. FSDeveloper.com provides an exhausting competent and comprehensive lot of information regarding this subject. The Author of this document gained a lot of this information from this source! Another requirement is a good understanding of the Photo Paint Program you are using. Also a thorough knowledge of the Flight Simulator Terrain SDK is required or is even essential for the process. You need also a basic understanding of technical terms used in the Computer Graphic Environment. Technical Background and Terms As usual, there is a bit of technical explanations and technical term's required. I will keep this very very short, because the Internet, i.e. Wikipedia provides exhausting information regarding this subjects, I will provide the relevant Hyperlinks so you can navigate to the pertinent Web-pages. -

Cloud Storage for Free
1 / 2 Cloud Storage For Free Free and cheap personal and small business cloud storage services are everywhere. But which one is best for you? Let's look at the top cloud .... Below is a list of free cloud storage you can use to store up anything you want. · #1 Dropbox · #2 Google Drive · #3 OneDrive · #4 Amazon Drive · #5 .... Also note that files and folders you haven't deleted permanently still count toward your cloud storage. Delete files permanently to free up cloud .... Oracle Cloud Free Tier. Always Free. 2 Autonomous Databases, 20 GB each; Compute VMs; 100 GB block volume; 10 GB object storage .... Included Free. Basic. Plus ... Is there a free trial for Ring Protect Plan? Yes! ... 2Your Ring videos are stored in the cloud for up to 60 days (in the USA). To keep .... The best cloud storage service: Google Drive. With its own web-based office suite and an excellent 15GB of free storage, Google Drive is the best .... Next-Generation cloud storage with Icedrive. Get started right away with a massive 10GB free space.. Backing up your work for Artists & Designers – 6 free Cloud Storage services · Dropbox · Google Drive · Onedrive · Amazon drive · Adobe Creative .... When you sign up for iCloud, you automatically get 5GB of free storage. If you need more space in iCloud, you can upgrade to a larger storage .... For free. For life. – Just plug in any hard drives to your Cubbit Cell and turn them into cloud. – For every 2GB of physical storage you ... Get powerful and secure cloud storage with Dropbox. -

Mobile Lawyering.Docx
CHAPTER THIRTEEN YOUR OFFICE - DON'T LEAVE HOME WITHOUT IT! MOBILE LAWYERING July 2012 Barron K. Henley, Esq., Partner Affinity Consulting Group 1405 Dublin Road, Suite 100 Columbus, OH 43215 Phone: (614) 340-3444 E-mail: [email protected] BARRON K. HENLEY is an attorney, a "legal technologist" since 1990, and a founding member of Affinity Consulting Group (formerly Henley March & Unger Consulting, Inc.) which handles all aspects of law practice automation including document assembly, case management, document management, legal accounting software, trial presentation/litigation support, paper reduction/scanning, hardware, networks/servers and security. Barron received his Bachelor of Science in Business Administration (majoring in marketing and economics) and J.D. from The Ohio State University and is a member of the American, Ohio and Columbus Bar Associations, and the Worthington Estate Planning Council. He is a member of the ABA Law Practice Management Section and is the former Chair of the Ohio State Bar Association Law Office Automation & Technology Committee. Barron heads Affinity’s HotDocs document assembly and software training departments; and has authored legal-specific manuals on HotDocs document assembly, Microsoft Word, Microsoft Excel and Adobe Acrobat. Barron teaches continuing legal education (CLE) classes throughout the U.S. and Canada covering practice management, document management, file management, server and personal computer issues, remote access, mobile lawyering, scanning and paper reduction strategies, electronic case filing, Word, Excel, Outlook, WordPerfect, HotDocs document assembly, Adobe Acrobat, malpractice avoidance, voice recognition, and many other topics. Copyright © 2012 Affinity Consulting Group LLC Note: WSBA does not recommend or promote any particular product or service. -

Cloud Computing in the Digital Age
Cloud Computing in the Digital Age Cloud computing is a term used to refer to a computer situation where a program runs on a remote server rather than on a local computer, tablet or smartphone. Instead of using YOUR system’s resources, it relies on the remote computer’s system resources to process the task(s). Generally speaking, “Cloud” services are ways that you can use other peoples’ computers (servers) as storage for your own personal files, programs, and other such things. You might think of the cloud as just another way of saying “Internet”. You can prefix the term “Cloud” to just about anything, and it basically means “an online/internet accessible version of” whatever you are referring to. For example: Cloud Storage = Online storage of your personal files Cloud Router = A router which can be used to share access to your computer/files from anywhere there is internet Cloud Music = Storing your music on a remote server for playback via internet anywhere in the world Why Use The Cloud? Access your files from any computer (e.g., resumes) Playing movies/music anywhere Conserving storage space on your device Origin The term “The Cloud” came from the cloud symbol that computer engineers used on network diagrams to represent the unknown segments of a network (computers accessed via the internet in a networked environment they don’t manage themselves). Cloud computing has 5 essential characteristics: On-demand self-service: A user can access and use the service as much as needed automatically without requiring human interaction with each service provider. -

Da Archive Annex of New Links, Most Needing Repair (^^) March 16Th 2017
Da Archive Annex of new links, most needing repair (^^) March 16th 2017 New links will be placed here for a while before adding them to Da Archive. PLEASE BUY A COPY OF THE BOOKS THAT YOU USE. If you can't understand why you should support your game, go work at Burger King for 2 weeks for no pay and you might get a clue. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Sorry for the incomplete links This way seems to be a good idea, what with the matrixbots and cyber crotchspiders out there. If Anon wanted to help, they could complete the links, check that they are still live, etc Special thanks to Decoderfriend, who worked hard to make it easier for everyone else. --- --- --- --- --- ---- --- --- --- --- A Hard To Find Game www anonfiles cc/file/3afdbf1484a673a0e5a0c9a2e32c0d3b Ponytales Courage is Magic Roleplaying is Magic Seaon 4 Savage world of pony 4th https://www.sendspace.com/filegroup/v2T6iRIJUfsTksuZirm36uIaun3XZlSk Over the Edge 2nd Ed rules, and the modules The Myth of Self, Unauthorized Broadcast and Welcome to Sylvan Pines http://www.mediafire.com/file/co836ku80xzt62g/Over+The+Edge.rar https://www.reddit.com/r/rpg/comments/5zj464/pdf_collection_of_grant_howitts_free_microgames/ https://mega.nz/#F!GgZGlKAY!MRRUIHUqlPNXS58UTppRIQ!38BA3RTC Orphans of the Hanged Man $$ /file/28aula http://scribd-download.com/d-amp-d-4th-edition-neverwinter-campaign- setting_58c387bddc0d60b157339029_pdf.htm l Starjammer https://drive.google.com/open?id=0B0-IxjmMq9NMME1RMElUZ1plRXM -

Osprey/Wargame Folders
Osprey/Wargame folders https://www.mediafire.com/folder/lu95l5mgg06d5/Ancient https://www.mediafire.com/folder/81ck8x600cas4/Medieval https://www.mediafire.com/folder/w6m41ma3co51e/Horse_and_Musket https://www.mediafire.com/folder/vh1uqv8gipzo1/Napoleonic https://www.mediafire.com/folder/bbpscr0dam7iy/ACW https://www.mediafire.com/folder/bvdtt01gh105d/Victorian https://www.mediafire.com/folder/b35x147vmc6sg/World_War_One https://www.mediafire.com/folder/z8a13ampzzs88/World_War_Two https://www.mediafire.com/folder/z8i8t83bysdwz/Vietnam_War https://www.mediafire.com/folder/7n3mcn9hlgl1t/Modern Flames of War scans database: http://www.mediafire.com/?8ciamhs8husms 13th Age: http://www.4shared.com/office/YuJQgsuL/13th_Age_RPG.html Torchbearer: http://www.4shared.com/office/BZoy8R_c/Torchbearer.html Conspiracy X: http://www.4shared.com/folder/SMqx1EQF/conspiracyx.html A Dirty World http://www.mediafire.com/view/5d6bret7uh2219e/A%20Dirty%20World.pdf Technoir: https://www.mediafire.com/folder/5vyh495uxvenj/Technoir Rocket Age: http://www.uploadmb.com/dw.php?id=1382562859 Night's Black Agents: http://www.mediafire.com/download/2l3z7t7u59ce6iu/%5BPELGN01D%5D+Night %27s+Black+Agents.pdf And a whooping large collection: https://www.mediafire.com/?12472575k2uel http://dwarfstar.brainiac.com/ds_index.html http://www.projectaon.org/en/Main/Books https://razir.minus.com/uploads http://thraen.minus.com/uploads#!/1.0 http://jmp.sh/b/wUp2dm1shKfadeYGDswz http://www.mediafire.com/?k34zw4sdyp7lx https://www.dropbox.com/sh/mnkrrl6q8ixonm2/Ni_z2UmcGo http://www.4shared.com/folder/s_yLbJNV/Spelljammer.html