High Bandwidth Memory for Graphics Applications Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
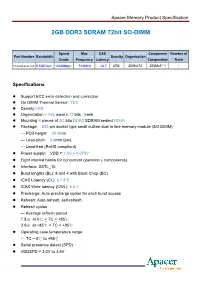
2GB DDR3 SDRAM 72Bit SO-DIMM
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Reviving the Development of Openchrome
Reviving the Development of OpenChrome Kevin Brace OpenChrome Project Maintainer / Developer XDC2017 September 21st, 2017 Outline ● About Me ● My Personal Story Behind OpenChrome ● Background on VIA Chrome Hardware ● The History of OpenChrome Project ● Past Releases ● Observations about Standby Resume ● Developmental Philosophy ● Developmental Challenges ● Strategies for Further Development ● Future Plans 09/21/2017 XDC2017 2 About Me ● EE (Electrical Engineering) background (B.S.E.E.) who specialized in digital design / computer architecture in college (pretty much the only undergraduate student “still” doing this stuff where I attended college) ● Graduated recently ● First time conference presenter ● Very experienced with Xilinx FPGA (Spartan-II through 7 Series FPGA) ● Fluent in Verilog / VHDL design and verification ● Interest / design experience with external communication interfaces (PCI / PCIe) and external memory interfaces (SDRAM / DDR3 SDRAM) ● Developed a simple DMA engine for PCI I/F validation w/Windows WDM (Windows Driver Model) kernel device driver ● Almost all the knowledge I have is self taught (university engineering classes were not very useful) 09/21/2017 XDC2017 3 Motivations Behind My Work ● General difficulty in obtaining meaningful employment in the digital hardware design field (too many students in the field, difficulty obtaining internship, etc.) ● Collects and repairs abandoned computer hardware (It’s like rescuing puppies!) ● Owns 100+ desktop computers and 20+ laptop computers (mostly abandoned old stuff I -

Performance Impact of Memory Channels on Sparse and Irregular Algorithms
Performance Impact of Memory Channels on Sparse and Irregular Algorithms Oded Green1,2, James Fox2, Jeffrey Young2, Jun Shirako2, and David Bader3 1NVIDIA Corporation — 2Georgia Institute of Technology — 3New Jersey Institute of Technology Abstract— Graph processing is typically considered to be a Graph algorithms are typically latency-bound if there is memory-bound rather than compute-bound problem. One com- not enough parallelism to saturate the memory subsystem. mon line of thought is that more available memory bandwidth However, the growth in parallelism for shared-memory corresponds to better graph processing performance. However, in this work we demonstrate that the key factor in the utilization systems brings into question whether graph algorithms are of the memory system for graph algorithms is not necessarily still primarily latency-bound. Getting peak or near-peak the raw bandwidth or even the latency of memory requests. bandwidth of current memory subsystems requires highly Instead, we show that performance is proportional to the parallel applications as well as good spatial and temporal number of memory channels available to handle small data memory reuse. The lack of spatial locality in sparse and transfers with limited spatial locality. Using several widely used graph frameworks, including irregular algorithms means that prefetched cache lines have Gunrock (on the GPU) and GAPBS & Ligra (for CPUs), poor data reuse and that the effective bandwidth is fairly low. we evaluate key graph analytics kernels using two unique The introduction of high-bandwidth memories like HBM and memory hierarchies, DDR-based and HBM/MCDRAM. Our HMC have not yet closed this inefficiency gap for latency- results show that the differences in the peak bandwidths sensitive accesses [19]. -

Amd Filed: February 24, 2009 (Period: December 27, 2008)
FORM 10-K ADVANCED MICRO DEVICES INC - amd Filed: February 24, 2009 (period: December 27, 2008) Annual report which provides a comprehensive overview of the company for the past year Table of Contents 10-K - FORM 10-K PART I ITEM 1. 1 PART I ITEM 1. BUSINESS ITEM 1A. RISK FACTORS ITEM 1B. UNRESOLVED STAFF COMMENTS ITEM 2. PROPERTIES ITEM 3. LEGAL PROCEEDINGS ITEM 4. SUBMISSION OF MATTERS TO A VOTE OF SECURITY HOLDERS PART II ITEM 5. MARKET FOR REGISTRANT S COMMON EQUITY, RELATED STOCKHOLDER MATTERS AND ISSUER PURCHASES OF EQUITY SECURITIES ITEM 6. SELECTED FINANCIAL DATA ITEM 7. MANAGEMENT S DISCUSSION AND ANALYSIS OF FINANCIAL CONDITION AND RESULTS OF OPERATIONS ITEM 7A. QUANTITATIVE AND QUALITATIVE DISCLOSURE ABOUT MARKET RISK ITEM 8. FINANCIAL STATEMENTS AND SUPPLEMENTARY DATA ITEM 9. CHANGES IN AND DISAGREEMENTS WITH ACCOUNTANTS ON ACCOUNTING AND FINANCIAL DISCLOSURE ITEM 9A. CONTROLS AND PROCEDURES ITEM 9B. OTHER INFORMATION PART III ITEM 10. DIRECTORS, EXECUTIVE OFFICERS AND CORPORATE GOVERNANCE ITEM 11. EXECUTIVE COMPENSATION ITEM 12. SECURITY OWNERSHIP OF CERTAIN BENEFICIAL OWNERS AND MANAGEMENT AND RELATED STOCKHOLDER MATTERS ITEM 13. CERTAIN RELATIONSHIPS AND RELATED TRANSACTIONS AND DIRECTOR INDEPENDENCE ITEM 14. PRINCIPAL ACCOUNTANT FEES AND SERVICES PART IV ITEM 15. EXHIBITS, FINANCIAL STATEMENT SCHEDULES SIGNATURES EX-10.5(A) (OUTSIDE DIRECTOR EQUITY COMPENSATION POLICY) EX-10.19 (SEPARATION AGREEMENT AND GENERAL RELEASE) EX-21 (LIST OF AMD SUBSIDIARIES) EX-23.A (CONSENT OF ERNST YOUNG LLP - ADVANCED MICRO DEVICES) EX-23.B -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -

RADEON 7000 MAC EDITION User's Guide
RADEON™ 7000 MAC® EDITION User’s Guide P/N: 137-40298-20 Copyright © 2002, ATI Technologies Inc. All rights reserved. ATI and all ATI product and product feature names are trademarks and/or registered trademarks of ATI Technologies Inc. All other company and/or product names are trademarks and/or registered trademarks of their respective owners. Features, performance and specifications are subject to change without notice. Product may not be exactly as shown in the diagrams. Reproduction of this manual, or parts thereof, in any form, without the express written permission of ATI Technologies Inc. is strictly prohibited. Disclaimer While every precaution has been taken in the preparation of this document, ATI Technologies Inc. assumes no liability with respect to the operation or use of ATI hardware, software or other products and documentation described herein, for any act or omission of ATI concerning such products or this documentation, for any interruption of service, loss or interruption of business, loss of anticipatory profits, or for punitive, incidental or consequential damages in connection with the furnishing, performance, or use of the ATI hardware, software, or other products and documentation provided herein. ATI Technologies Inc. reserves the right to make changes without further notice to a product or system described herein to improve reliability, function or design. With respect to ATI products which this document relates, ATI disclaims all express or implied warranties regarding such products, including but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. Page ii 1 Introduction The RADEON 7000 MAC EDITION represents the next generation in 3D and video acceleration for your Power Macintosh computer. -

Case Study on Integrated Architecture for In-Memory and In-Storage Computing
electronics Article Case Study on Integrated Architecture for In-Memory and In-Storage Computing Manho Kim 1, Sung-Ho Kim 1, Hyuk-Jae Lee 1 and Chae-Eun Rhee 2,* 1 Department of Electrical Engineering, Seoul National University, Seoul 08826, Korea; [email protected] (M.K.); [email protected] (S.-H.K.); [email protected] (H.-J.L.) 2 Department of Information and Communication Engineering, Inha University, Incheon 22212, Korea * Correspondence: [email protected]; Tel.: +82-32-860-7429 Abstract: Since the advent of computers, computing performance has been steadily increasing. Moreover, recent technologies are mostly based on massive data, and the development of artificial intelligence is accelerating it. Accordingly, various studies are being conducted to increase the performance and computing and data access, together reducing energy consumption. In-memory computing (IMC) and in-storage computing (ISC) are currently the most actively studied architectures to deal with the challenges of recent technologies. Since IMC performs operations in memory, there is a chance to overcome the memory bandwidth limit. ISC can reduce energy by using a low power processor inside storage without an expensive IO interface. To integrate the host CPU, IMC and ISC harmoniously, appropriate workload allocation that reflects the characteristics of the target application is required. In this paper, the energy and processing speed are evaluated according to the workload allocation and system conditions. The proof-of-concept prototyping system is implemented for the integrated architecture. The simulation results show that IMC improves the performance by 4.4 times and reduces total energy by 4.6 times over the baseline host CPU. -

Innovative AMD Handheld Technology – the Ultimate Visual Experience™ Anywhere –
MEDIA BACKGROUNDER Innovative AMD Handheld Technology – The Ultimate Visual Experience™ Anywhere – AMD Vision AMD has a vision of a new era of mobile entertainment, bringing all the capabilities of a camera, camcorder, music player and 3D gaming console to mobile phones, smart phones and tomorrow’s converged portable devices. This vision is quickly becoming reality. Mass adoption of image and video sharing sites like YouTube, as well as the growing popularity of camera phones and personalized media services, are several trends that demonstrate ever-increasing consumer demand for “always connected” multimedia. And consumers have demonstrated a willingness to pay for sophisticated devices and services that deliver immersive, media-rich experiences. This increasing appetite for mobile multimedia makes it more important than ever for device manufacturers to quickly deliver the latest multimedia features – without significantly increasing design and manufacturing costs. AMD in Mobile Multimedia With the acquisition of ATI Technologies in 2006, AMD expanded beyond its traditional realm of PC computing to become a powerhouse in multimedia processing technologies. Building on more than 20 years of graphics and multimedia expertise, AMD is a leading supplier of media processors to the handheld market with nearly 250 million AMD Imageon™ media processors shipped to date. Furthermore, AMD is a significant source of mobile intellectual property (IP), licensing graphics technology to semiconductor suppliers. AMD provides customers with a top-to-bottom family of cutting-edge audio, video, imaging, graphics and mobile TV products. The scalable AMD technology platforms are based on open industry standards, and are designed for maximum performance with low power consumption. -

Lewis University Dr. James Girard Summer Undergraduate Research Program 2021 Faculty Mentor - Project Application
Lewis University Dr. James Girard Summer Undergraduate Research Program 2021 Faculty Mentor - Project Application Exploring the Use of High-level Parallel Abstractions and Parallel Computing for Functional and Gate-Level Simulation Acceleration Dr. Lucien Ngalamou Department of Engineering, Computing and Mathematical Sciences Abstract System-on-Chip (SoC) complexity growth has multiplied non-stop, and time-to- market pressure has driven demand for innovation in simulation performance. Logic simulation is the primary method to verify the correctness of such systems. Logic simulation is used heavily to verify the functional correctness of a design for a broad range of abstraction levels. In mainstream industry verification methodologies, typical setups coordinate the validation e↵ort of a complex digital system by distributing logic simulation tasks among vast server farms for months at a time. Yet, the performance of logic simulation is not sufficient to satisfy the demand, leading to incomplete validation processes, escaped functional bugs, and continuous pressure on the EDA1 industry to develop faster simulation solutions. In this research, we will explore a solution that uses high-level parallel abstractions and parallel computing to boost the performance of logic simulation. 1Electronic Design Automation 1 1 Project Description 1.1 Introduction and Background SoC complexity is increasing rapidly, driven by demands in the mobile market, and in- creasingly by the fast-growth of assisted- and autonomous-driving applications. SoC teams utilize many verification technologies to address their complexity and time-to-market chal- lenges; however, logic simulation continues to be the foundation for all verification flows, and continues to account for more than 90% [10] of all verification workloads. -

AN 436: Using DDR3 SDRAM in Stratix III and Stratix IV Devices.Pdf
AN 436: Using DDR3 SDRAM in Stratix III and Stratix IV Devices © November 2008 AN-436-4.0 Introduction DDR3 SDRAM is the latest generation of DDR SDRAM technology, with improvements that include lower power consumption, higher data bandwidth, enhanced signal quality with multiple on-die termination (ODT) selection and output driver impedance control. DDR3 SDRAM brings higher memory performance to a broad range of applications, such as PCs, embedded processor systems, image processing, storage, communications, and networking. Although DDR2 SDRAM is currently the more popular SDRAM, to save system power and increase system performance you should consider using DDR3 SDRAM. DDR3 SDRAM offers lower power by using 1.5 V for the supply and I/O voltage compared to the 1.8-V supply and I/O voltage used by DDR2 SDRAM. DDR3 SDRAM also has better maximum throughput compared to DDR2 SDRAM by increasing the data rate per pin and the number of banks (8 banks are standard). 1 The Altera® ALTMEMPHY megafunction and DDR3 SDRAM high-performance controller only support local interfaces running at half the rate of the memory interface. Altera Stratix® III and Stratix IV devices support DDR3 SDRAM interfaces with dedicated DQS, write-, and read-leveling circuitry. Table 1 displays the maximum clock frequency for DDR3 SDRAM in Stratix III devices. Table 1. DDR3 SDRAM Maximum Clock Frequency Supported in Stratix III Devices (Note 1), (2) Speed Grade fMAX (MHz) –2 533 (3) –3 and I3 400 –4, 4L, and I4L at 1.1 V 333 (4), (5) –4, 4L, and I4L at 0.9 V Not supported Notes to Table 1: (1) Numbers are preliminary until characterization is final. -

ECE 571 – Advanced Microprocessor-Based Design Lecture 17
ECE 571 { Advanced Microprocessor-Based Design Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver [email protected] 3 April 2018 Announcements • HW8 is readings 1 More DRAM 2 ECC Memory • There's debate about how many errors can happen, anywhere from 10−10 error/bit*h (roughly one bit error per hour per gigabyte of memory) to 10−17 error/bit*h (roughly one bit error per millennium per gigabyte of memory • Google did a study and they found more toward the high end • Would you notice if you had a bit flipped? • Scrubbing { only notice a flip once you read out a value 3 Registered Memory • Registered vs Unregistered • Registered has a buffer on board. More expensive but can have more DIMMs on a channel • Registered may be slower (if it buffers for a cycle) • RDIMM/UDIMM 4 Bandwidth/Latency Issues • Truly random access? No, burst speed fast, random speed not. • Is that a problem? Mostly filling cache lines? 5 Memory Controller • Can we have full random access to memory? Why not just pass on CPU mem requests unchanged? • What might have higher priority? • Why might re-ordering the accesses help performance (back and forth between two pages) 6 Reducing Refresh • DRAM Refresh Mechanisms, Penalties, and Trade-Offs by Bhati et al. • Refresh hurts performance: ◦ Memory controller stalls access to memory being refreshed ◦ Refresh takes energy (read/write) On 32Gb device, up to 20% of energy consumption and 30% of performance 7 Async vs Sync Refresh • Traditional refresh rates ◦ Async Standard (15.6us) ◦ Async Extended (125us) ◦ SDRAM -