Report-Indian-English
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grade -7 Activity Sheets
Azaan International School Self-Assessment – 2019 Grade: VII Subject: English Time: 20 min Marks: 10M Name of the student: _______________________________________ Date: _____________ I. Identify if these sentences are simple(S), compound (CO) or complex (C): 5M 1. A king lives in a palace. ______________________ 2. He is polite but his brother is rude. ______________________ 3. He will visit me on Sunday. ______________________ 4. He came home when it was raining. ______________________ 5. Unless you work hard, you cannot get good marks. _____________________ 6. You better walk fast or you will miss the train. ______________________ 7. Cows are grazing in the field. ______________________ 8. We met a few people who could speak English. ______________________ 9. He didn’t want to go to the dentist, yet he went anyway. _________________ 10. Harry is a baseball player who is known all over the world. ______________ II. Underline the independent clause and circle the dependent clause in the following sentences: 5M 1. Sam watched TV after he finished his homework. 2. If the dress is on sale, she will buy it. 3. We went on a hike although it was cold and windy yesterday 4. Unless you have the right size, don’t try it on. 5. After the programme ended, we went home. Azaan International School Peer - Assessment –Sep 2019 Grade: VII Subject: English Time : 20 min Marks :10 Name of the student: _____________________________ A. Match the words in both the columns to complete the oxymoron: 1. alone a. Confused 2. clearly b. Sweet 3. open c. good 4. deafening d. funny 5. -

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

2001 Presented Below Is an Alphabetical Abstract of Languages A
Hindi Version Home | Login | Tender | Sitemap | Contact Us Search this Quick ABOUT US Site Links Hindi Version Home | Login | Tender | Sitemap | Contact Us Search this Quick ABOUT US Site Links Census 2001 STATEMENT 1 ABSTRACT OF SPEAKERS' STRENGTH OF LANGUAGES AND MOTHER TONGUES - 2001 Presented below is an alphabetical abstract of languages and the mother tongues with speakers' strength of 10,000 and above at the all India level, grouped under each language. There are a total of 122 languages and 234 mother tongues. The 22 languages PART A - Languages specified in the Eighth Schedule (Scheduled Languages) Name of language and Number of persons who returned the Name of language and Number of persons who returned the mother tongue(s) language (and the mother tongues mother tongue(s) language (and the mother tongues grouped under each grouped under each) as their mother grouped under each grouped under each) as their mother language tongue language tongue 1 2 1 2 1 ASSAMESE 13,168,484 13 Dhundhari 1,871,130 1 Assamese 12,778,735 14 Garhwali 2,267,314 Others 389,749 15 Gojri 762,332 16 Harauti 2,462,867 2 BENGALI 83,369,769 17 Haryanvi 7,997,192 1 Bengali 82,462,437 18 Hindi 257,919,635 2 Chakma 176,458 19 Jaunsari 114,733 3 Haijong/Hajong 63,188 20 Kangri 1,122,843 4 Rajbangsi 82,570 21 Khairari 11,937 Others 585,116 22 Khari Boli 47,730 23 Khortha/ Khotta 4,725,927 3 BODO 1,350,478 24 Kulvi 170,770 1 Bodo/Boro 1,330,775 25 Kumauni 2,003,783 Others 19,703 26 Kurmali Thar 425,920 27 Labani 22,162 4 DOGRI 2,282,589 28 Lamani/ Lambadi 2,707,562 -

LOK SABHA ———— BILL NO. 106 of 2015 Vlk/Kkj
jftLVªh lañ Mhñ ,yñ—(,u)04@0007@2003—15 REGISTERED NO. DL—(N)04/0007/2003—15 vlk/kkj.k EXTRAORDINARY Hkkx II — [k.M 2 PART II — Section 2 izkf/kdkj ls izdkf'kr PUBLISHED BY AUTHORITY lañ 18] ubZ fnYyh] 'kqØ okj] vizSy 24] 2015@oS'kk[k 4] 1937 ¼'kd½ No. 18] NEW DELHI, FRIDAY, APRIL 24, 2015/Vaisakha 4, 1937 (SAKA) bl Hkkx esa fHkUu i`"B la[;k nh tkrh gS ftlls fd ;g vyx ladyu ds :i esa j[kk tk ldsA Separate paging is given to this Part in order that it may be filed as a separate compilation. LOK SABHA ———— The following Bills were introduced in Lok Sabha on 24th April, 2015:— BILL NO. 106 OF 2015 A Bill to provide for prevention, control and management of HIV epidemic in India; protection and promotion of human rights of persons living or affected by HIV/ AIDS; for establishment of Authorities at the National, State, Union territory and district level to promote such rights and to promote prevention, awareness, care, support, treatment programmes to control the spread of HIV/AIDS and for matters connected therewith or incidental thereto. WHEREAS the spread of HIV/AIDS is a matter of national concern; AND WHEREAS there is a need to prevent and control the spread of HIV/AIDS; AND WHEREAS there is a need to protect and promote the human rights of persons who are HIV positive or are most vulnerable to HIV/AIDS; AND WHEREAS there is a need for effective and accessible care, support and treatment for persons living with or affected by HIV/AIDS; AND WHEREAS there is a need to protect the rights of healthcare providers and other such persons providing -

India Country Name India
TOPONYMIC FACT FILE India Country name India State title in English Republic of India State title in official languages (Bhārat Gaṇarājya) (romanized in brackets) भारत गणरा煍य Name of citizen Indian Official languages Hindi, written in Devanagari script, and English1 Country name in official languages (Bhārat) (romanized in brackets) भारत Script Devanagari ISO-3166 code (alpha-2/alpha-3) IN/IND Capital New Delhi Population 1,210 million2 Introduction India occupies the greater part of South Asia. It was part of the British Empire from 1858 until 1947 when India was split along religious lines into two nations at independence: the Hindu-majority India and the Muslim-majority Pakistan. Its highly diverse population consists of thousands of ethnic groups and hundreds of languages. Northeast India comprises the states of Arunāchal Pradesh, Assam, Manipur, Meghālaya, Mizoram, Nāgāland, Sikkim and Tripura. It is connected to the rest of India through a narrow corridor of the state of West Bengal. It shares borders with the countries of Nepal, China, Bhutan, Myanmar (Burma) and Bangladesh. The mostly hilly and mountainous region is home to many hill tribes, with their own distinct languages and culture. Geographical names policy PCGN policy for India is to use the Roman-script geographical names found on official India-produced sources. Official maps are produced by the Survey of India primarily in Hindi and English (versions are also made in Odiya for Odisha state, Tamil for Tamil Nādu state and there is a Sanskrit version of the political map of the whole of India). The Survey of India is also responsible for the standardization of geographical names in India. -

Updated Proposal to Encode Tulu-Tigalari Script in Unicode
Updated proposal to encode Tulu-Tigalari script in Unicode Vaishnavi Murthy Kodipady Yerkadithaya [ [email protected] ] Vinodh Rajan [ [email protected] ] 04/03/2021 Document History & Background Documents : (This document replaces L2/17-378) L2/11-120R Preliminary proposal for encoding the Tulu script in the SMP of the UCS – Michael Everson L2/16-241 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y L2/16-342 Recommendations to UTC #149 November 2016 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Andrew Glass and Laurentiu Iancu L2/17-182 Comments on encoding the Tigalari script – Srinidhi and Sridatta L2/18-175 Replies to Script Ad Hoc Recommendations (L2/16-342) and Comments (L2/17-182) on Tigalari proposal (L2/16-241) – Vaishnavi Murthy K Y L2/17-378 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y, Vinodh Rajan L2/17-411 Letter in support of preliminary proposal to encode Tigalari – Guru Prasad (Has withdrawn support. This letter needs to be disregarded.) L2/17-422 Letter to Vaishnavi Murthy in support of Tigalari encoding proposal – A. V. Nagasampige L2/18-039 Recommendations to UTC #154 January 2018 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Lisa Moore, Liang Hai, and Richard Cook PROPOSAL TO ENCODE TIGALARI SCRIPT IN UNICODE 2 A note on recent updates : −−−Tigalari Script is renamed Tulu-Tigalari script. The reason for the same is discussed under section 1.1 (pp. 4-5) of this paper & elaborately in the supplementary paper Tulu Language and Tulu-Tigalari script (pp. 5-13). −−−This proposal attempts to harmonize the use of the Tulu-Tigalari script for Tulu, Sanskrit and Kannada languages for archival use. -
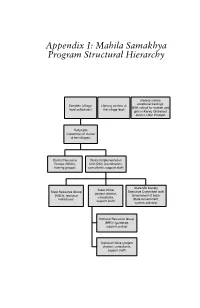
Appendix I: Mahila Samakhya Program Structural Hierarchy
Appendix I: Mahila Samakhya Program Structural Hierarchy Literacy camps, vocational trainings, Sanghas (village- Literacy centers at MSK school for women and level collectives) the village level girls in Karwi, Chitrakoot district, Uttar Pradesh Sahyogini (supervisor of cluster of ten villages) District Resource District Implementation Groups (NGOs, Unit (DIU) (coordinators, training groups) consultants, support staff) State MS Society State Office State Resource Group Executive Committee (with (project director, (NGOs, resource Government of India, consultants, institutions) State Government, support staff) women activists) National Resource Group (NRG) (guidance, support, policy) National Office (project director, consultants, support staff) Notes Introduction 1. James Ferguson, The Anti-Politics Machine: Development, Depoliticization, and Bureaucratic Power in Lesotho (Cambridge: Cambridge University Press, 1990), 17. 2. Ibid. 3. Ibid. 4. Ibid., 18. 5. Michel Foucault (1971, 1973). 6. Ferguson (1990), 18. 7. Ibid., 20. 8. Ibid., 75–89. 9. Ibid., 255–256. 10. Ibid., 275. 11. Ibid. 12. Ibid., 274. 13. Ibid., 271–273. 14. Ibid., 276. 15. Ibid. 16. Ibid., 277. 17. I am modifying Ferguson’s argument based on my experience of a govern- ment program in India. Through his experience of the Thaba Tseka govern- ment project in Lesotho, he is led to disagree with Foucault’s argument that in the conduct of “biopolitics,” the state assumes a “central, coordinating, managing” role. Instead, Ferguson argues, “growth of power does not imply any sort -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Minority Languages in India
Thomas Benedikter Minority Languages in India An appraisal of the linguistic rights of minorities in India ---------------------------- EURASIA-Net Europe-South Asia Exchange on Supranational (Regional) Policies and Instruments for the Promotion of Human Rights and the Management of Minority Issues 2 Linguistic minorities in India An appraisal of the linguistic rights of minorities in India Bozen/Bolzano, March 2013 This study was originally written for the European Academy of Bolzano/Bozen (EURAC), Institute for Minority Rights, in the frame of the project Europe-South Asia Exchange on Supranational (Regional) Policies and Instruments for the Promotion of Human Rights and the Management of Minority Issues (EURASIA-Net). The publication is based on extensive research in eight Indian States, with the support of the European Academy of Bozen/Bolzano and the Mahanirban Calcutta Research Group, Kolkata. EURASIA-Net Partners Accademia Europea Bolzano/Europäische Akademie Bozen (EURAC) – Bolzano/Bozen (Italy) Brunel University – West London (UK) Johann Wolfgang Goethe-Universität – Frankfurt am Main (Germany) Mahanirban Calcutta Research Group (India) South Asian Forum for Human Rights (Nepal) Democratic Commission of Human Development (Pakistan), and University of Dhaka (Bangladesh) Edited by © Thomas Benedikter 2013 Rights and permissions Copying and/or transmitting parts of this work without prior permission, may be a violation of applicable law. The publishers encourage dissemination of this publication and would be happy to grant permission. -

Spotlaw 2014
State of Rajasthan Vs Bhup Sing Criminal Appeal No. 377 of 1996 (Dr. A. S. Anand, K. T. Thomas JJ) 13.01.1997 JUDGMENT THOMAS, J. – 1. The respondent's wife (Mst. Chawli) was shot dead on 20-7-1985 while she was sleeping in her house. Respondent Bhup Singh was alleged to be the killer. The police, after investigation, upheld the allegation and challaned him. Though the Sessions Court convicted him of murder, the High Court of Rajasthan acquitted him. This appeal has been filed by special leave by the State of Rajasthan in challenge of the aforesaid acquittal. 2. The prosecution case is a very short story : Chawli was first married to the respondent's brother who died after a brief marital life. Thereafter, Chawli was given in marriage to the respondent, but the new alliance was marred by frequent skirmishes and bickerings between the spouses. Chawli was residing in the house of her parents. The estrangement between the couple reached a point of no return and the respondent wished to get rid of her. So he went to her house on the night of the occurrence and shot her with a pistol. When he tried to use the firearm again, Chawli's father who had heard the sound of the first shot rushed towards him and caught him but the killer escaped with the pistol. 3. Chawli told everybody present in the house that she was shot at by her husband Bhup Singh. She was taken to the hospital and the doctor who attended on her thought it necessary to inform a Judicial Magistrate that her dying declaration should be recorded. -

Mapping India's Language and Mother Tongue Diversity and Its
Mapping India’s Language and Mother Tongue Diversity and its Exclusion in the Indian Census Dr. Shivakumar Jolad1 and Aayush Agarwal2 1FLAME University, Lavale, Pune, India 2Centre for Social and Behavioural Change, Ashoka University, New Delhi, India Abstract In this article, we critique the process of linguistic data enumeration and classification by the Census of India. We map out inclusion and exclusion under Scheduled and non-Scheduled languages and their mother tongues and their representation in state bureaucracies, the judiciary, and education. We highlight that Census classification leads to delegitimization of ‘mother tongues’ that deserve the status of language and official recognition by the state. We argue that the blanket exclusion of languages and mother tongues based on numerical thresholds disregards the languages of about 18.7 million speakers in India. We compute and map the Linguistic Diversity Index of India at the national and state levels and show that the exclusion of mother tongues undermines the linguistic diversity of states. We show that the Hindi belt shows the maximum divergence in Language and Mother Tongue Diversity. We stress the need for India to officially acknowledge the linguistic diversity of states and make the Census classification and enumeration to reflect the true Linguistic diversity. Introduction India and the Indian subcontinent have long been known for their rich diversity in languages and cultures which had baffled travelers, invaders, and colonizers. Amir Khusru, Sufi poet and scholar of the 13th century, wrote about the diversity of languages in Northern India from Sindhi, Punjabi, and Gujarati to Telugu and Bengali (Grierson, 1903-27, vol. -

Ambiguity in Chhattisgarhi Language – Introduction and Prevention
© 2021 JETIR July 2021, Volume 8, Issue 7 www.jetir.org (ISSN-2349-5162) Ambiguity in Chhattisgarhi language – Introduction and Prevention 1Pragya Bhagat, 2Dr.Chandrakant S. Ragit 1Department of information and language Engineering, Mahatma Gandhi Antarrashtriya Hindi Vishwavidyalaya, Wardha , Maharashtra, India 2 Pro-vice Chancellor and Director, Department of information and language Engineering, Mahatma Gandhi Antarrashtriya Hindi Vishwavidyalaya, Wardha , Maharashtra, India Abstract: We use sentences to express our sentiments. Sentences need to be grammatical in order to communicate. These grammatical sentences address the language. The use of words present in sentences to represent different situations is called ambiguity of the word. This research paper highlights the ambiguity and redressal of the words of natural language (Chhattisgarhi). In this research paper, we have compiled and analyzed data from various fields of Chhattisgarh language to understand the ambiguity present in Chhattisgarhi language and then highlighted their redressal. The main objective of this paper is to make aware of the ambiguity present in the Chhattisgarhi language and the rule based method used for its solution. This system is effective only for the prevention of word level ambiguity. Index Terms – ambiguity, Chhattisgarhi language, contextual rules, knowledge base I. INTRODUCTION All organisms express their dialogue through language. But the language used in dialog observation itself reveals many features. One of the different characteristics of the language is ambiguity. It is because of this characteristic of language that sometimes dialogue is also responsible for wrong transmission due to the multi meaning of the word present in the language. This feature of language is found in every natural language.