University of London Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Southern and Western Queensland Region
138°0'E 140°0'E 142°0'E 144°0'E 146°0'E 148°0'E 150°0'E 152°0'E 154°0'E DOO MADGE E S (! S ' ' 0 Gangalidda 0 ° QUD747/2018 ° 8 8 1 Waanyi People #2 & Garawa 1 (QC2018/004) People #2 Warrungnu [Warrungu] Girramay People Claimant application and determination boundary data compiled from NNTT based on boundaries with areas excluded or discrete boundaries of areas being claimed) as determination, a search of the Tribunal's registers and data sourced from Department of Resources (Qld) © The State of Queensland for they have been recognised by the Federal Court process. databases is required. Further information is available from the Tribunals website at GE ORG E TO W N People #2 Girramay Gkuthaarn and (! People #2 (! CARDW EL L that portion where their data has been used. Where the boundary of an application has been amended in the Federal Court, the www.nntt.gov.au or by calling 1800 640 501 Kukatj People map shows this boundary rather than the boundary as per the Register of Native Title © Commonwealth of Australia 2021 CARPENTARIA Tagalaka Southern and WesternQ UD176/2T0o2p0ographic vector data is © Commonwealth of Australia (Geoscience Australia) Claims (RNTC), if a registered application. The Registrar, the National Native Title Tribunal and its staff, members and agents Ewamian People QUD882/2015 Gurambilbarra Wulguru2k0a1b5a. Mada Claim The applications shown on the map include: and the Commonwealth (collectively the Commonwealth) accept no liability and give People #3 GULF REGION Warrgamay People (QC2020/N00o2n) freehold land tenure sourced from Department of Resources (QLD) March 2021. -

Carpentaria Gulf Region
138°0'E 139°0'E 140°0'E 141°0'E 142°0'E 143°0'E Claimant application and determination boundary data compiled from external boundaries with areas excluded or discrete boundaries of areas finalised. NNTT based on data sourced from Department of Resources (Qld) © The being claimed) as they have been recognised by the Federal Court Currency is based on the information as held by the NNTT and may not State of Queensland for that portion where their data has been used. process. reflect all decisions of the Federal Court. Where the boundary of an application has been amended in the Federal To determine whether any areas fall within the external boundary of an Topographic vector data is © Commonwealth of Australia (Geoscience Court, the map shows this boundary rather than the boundary as per the application or determination, a search of the Tribunal's registers and NORTHERN Australia) 2006. Register of Native Title Claims (RNTC), if a registered application. databases is required. Further information is avaIlable from the Tribunals NORTHERN TERRITORY Carpentaria Gulf Region The applications shown on the map include: website at www.nntt.gov.au or by calling 1800 640 501 Non freehold land tenure sourced from Department of Resources (QLD) - registered applications (i.e. those that have complied with the registration © Commonwealth of Australia 2021 March 2021. test), The Registrar, the National Native Title Tribunal and its staff, members and Native Title Claimant Applications and - new and/or amended applications where the registration test is being agents and the Commonwealth (collectively the Commonwealth) accept As part of the transitional provisions of the amended Native Title Act in applied, no liability and give no undertakings guarantees or warranties concerning Determination Areas 1998, all applications were taken to have been filed in the Federal Court. -

Computational Phylogenetic Reconstruction of Pama-Nyungan Verb Conjugation Classes
Abstract Computational Phylogenetic Reconstruction of Pama-Nyungan Verb Conjugation Classes Parker Lorber Brody 2020 The Pama-Nyungan language family comprises some 300 Indigenous languages, span- ning the majority of the Australian continent. The varied verb conjugation class systems of the modern Pama-Nyungan languages have been the object of contin- ued interest among researchers seeking to understand how these systems may have changed over time and to reconstruct the verb conjugation class system of the com- mon ancestor of Pama-Nyungan. This dissertation offers a new approach to this task, namely the application of Bayesian phylogenetic reconstruction models, which are employed in both testing existing hypotheses and proposing new trajectories for the change over time of the organization of the verbal lexicon into inflection classes. Data from 111 Pama-Nyungan languages was collected based on features of the verb conjugation class systems, including the number of distinct inflectional patterns and how conjugation class membership is determined. Results favor reconstructing a re- stricted set of conjugation classes in the prehistory of Pama-Nyungan. Moreover, I show evidence that the evolution of different parts of the conjugation class sytem are highly correlated. The dissertation concludes with an excursus into the utility of closed-class morphological data in resolving areas of uncertainty in the continuing stochastic reconstruction of the internal structure of Pama-Nyungan. Computational Phylogenetic Reconstruction of Pama-Nyungan Verb Conjugation Classes A Dissertation Presented to the Faculty of the Graduate School of Yale University in Candidacy for the Degree of Doctor of Philosophy by Parker Lorber Brody Dissertation Director: Dr. Claire Bowern December 2020 Copyright c 2020 by Parker Lorber Brody All rights reserved. -

Skin, Kin and Clan: the Dynamics of Social Categories in Indigenous
Skin, Kin and Clan THE DYNAMICS OF SOCIAL CATEGORIES IN INDIGENOUS AUSTRALIA Skin, Kin and Clan THE DYNAMICS OF SOCIAL CATEGORIES IN INDIGENOUS AUSTRALIA EDITED BY PATRICK MCCONVELL, PIERS KELLY AND SÉBASTIEN LACRAMPE Published by ANU Press The Australian National University Acton ACT 2601, Australia Email: [email protected] This title is also available online at press.anu.edu.au A catalogue record for this book is available from the National Library of Australia ISBN(s): 9781760461638 (print) 9781760461645 (eBook) This title is published under a Creative Commons Attribution-NonCommercial- NoDerivatives 4.0 International (CC BY-NC-ND 4.0). The full licence terms are available at creativecommons.org/licenses/by-nc-nd/4.0/ legalcode Cover design and layout by ANU Press. Cover image Gija Kinship by Shirley Purdie. This edition © 2018 ANU Press Contents List of Figures . vii List of Tables . xi About the Cover . xv Contributors . xvii 1 . Introduction: Revisiting Aboriginal Social Organisation . 1 Patrick McConvell 2 . Evolving Perspectives on Aboriginal Social Organisation: From Mutual Misrecognition to the Kinship Renaissance . 21 Piers Kelly and Patrick McConvell PART I People and Place 3 . Systems in Geography or Geography of Systems? Attempts to Represent Spatial Distributions of Australian Social Organisation . .43 Laurent Dousset 4 . The Sources of Confusion over Social and Territorial Organisation in Western Victoria . .. 85 Raymond Madden 5 . Disputation, Kinship and Land Tenure in Western Arnhem Land . 107 Mark Harvey PART II Social Categories and Their History 6 . Moiety Names in South-Eastern Australia: Distribution and Reconstructed History . 139 Harold Koch, Luise Hercus and Piers Kelly 7 . -

National Native Title Tribunal
NATIONAL NATIVE TITLE TRIBUNAL ANNUAL REPORT 1996/97 ANNUAL REPORT 1996/97 CONTENTS Letter to Attorney-General 1 Table of contents 3 Introduction – President’s Report 5 Tribunal values, mission, vision 9 Corporate overview – Registrar’s Report 10 Corporate goals Goal One: Increase community and stakeholder knowledge of the Tribunal and its processes. 19 Goal Two: Promote effective participation by parties involved in native title applications. 25 Goal Three: Promote practical and innovative resolution of native title applications. 30 Goal Four: Achieve recognition as an organisation that is committed to addressing the cultural and customary concerns of Aboriginal and Torres Strait Islander people. 44 Goal Five: Manage the Tribunal’s human, financial, physical and information resources efficiently and effectively. 47 Goal Six: Manage the process for authorising future acts effectively. 53 Regional Overviews 59 Appendices Appendix I: Corporate Directory 82 Appendix II: Other Relevant Legislation 84 Appendix III: Publications and Papers 85 Appendix IV: Staffing 89 Appendix V: Consultants 91 Appendix VI: Freedom of Information 92 Appendix VII: Internal and External Scrutiny, Social Justice and Equity 94 Appendix VIII: Audit Report & Notes to the Financial Statements 97 Appendix IX: Glossary 119 Appendix X: Compliance index 123 Index 124 National Native Title Tribunal 3 ANNUAL REPORT 1996/97 © Commonwealth of Australia 1997 ISSN 1324-9991 This work is copyright. It may be reproduced in whole or in part for study or training purposes if an acknowledgment of the source is included. Such use must not be for the purposes of sale or commercial exploitation. Subject to the Copyright Act, reproduction, storage in a retrieval system or transmission in any form by any means of any part of the work other than for the purposes above is not permitted without written permission. -

Salvage Studies of Western Queensland Aboriginallanguages
PACIFIC LINGUISTICS Series B-1 05 SALVAGE STUDIES OF WESTERN QUEENSLAND ABORIGINALLANGUAGES Gavan Breen Department of Linguistics Research School of Pacific Studies THE AUSTRALIAN NATIONAL UNIVERSITY Breen, G. Salvage studies of a number of extinct Aboriginal languages of Western Queensland. B-105, xii + 177 pages. Pacific Linguistics, The Australian National University, 1990. DOI:10.15144/PL-B105.cover ©1990 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. PACIFIC LINGUISTICS is issued through the Linguistic Circle of Canberra and consists of four series: SERIES A: Occasional Papers SERIES C: Books SERIES B: Monographs SERIES D: Special Publications FOUNDING EDITOR: S.A. Wurrn EDITORIAL BOARD: K.A. Adelaar, T.E. Dutton, A.K. Pawley, M.D. Ross, D.T. Tryon EDITORIAL ADVISERS: BW. Be nder K.A. McElha no n Univers ity ofHa waii Summer Institute of Linguis tics David Bra dle y H. P. McKaughan La Trobe Univers ity Unive rsityof Hawaii Mi chael G.Cl yne P. Miihlhll usler Mo nash Univers ity Bond Univers ity S.H. Elbert G.N. O' Grady Uni ve rs ity ofHa waii Univers ity of Victoria, B.C. KJ. Frank li n K. L. Pike SummerIn stitute ofLingui s tics SummerIn s titute of Linguis tics W.W. Glove r E. C. Po lo me SummerIn stit ute of Linguis tics Unive rsity ofTe xas G.W. Grace Gillian Sa nkoff University ofHa wa ii Universityof Pe nns ylvania M.A.K. Halliday W.A. L. -

Thuwathu/Bujimulla Indigenous Protected Area
Thuwathu/Bujimulla Indigenous Protected Area MANAGEMENT PLAN Prepared by the Carpentaria Land Council Aboriginal Corporation on behalf of the Traditional Owners of the Wellesley Islands LARDIL KAIADILT YANGKAAL GANGALIDDA This document was funded through the Commonwealth Government’s Indigenous Protected Area program. For further information please contact: Kelly Gardner Land & Sea Regional Coordinator Carpentaria Land Council Aboriginal Corporation Telephone: (07) 4745 5132 Email: [email protected] Thuwathu/Bujimulla Indigenous Protected Area Management Plan Prepared by Carpentaria Land Council Aboriginal Corporation on behalf of the Traditional Owners of the Wellesley Islands Acknowledgements: This document was funded through the Commonwealth Government’s Indigenous Protected Area program. The Carpentaria Land Council Aboriginal Corporation would like to acknowledge and thank the following organisations for their ongoing support for our land and sea management activities in the southern Gulf of Carpentaria: • Australian Government Department of Sustainability, Environment, Water, Population and Community (SEWPaC) • Queensland Government Department of Environment and Heritage Protection (EHP) • Northern Gulf Resource Management Group (NGRMG) • Southern Gulf Catchments (SGC) • MMG Century Environment Committee” Photo over page: Whitecliffs, Mornington Island. Photo courtesy of Kelly Gardner. WARNING: This document may contain the names and photographs of deceased Indigenous People. ii Acronyms: AFMA Australian Fisheries Management -

PAPERS in AUSTRALIAN LINGUISTICS No. 14
PACIFIC LINGUISTICS Se��e� A - No. 60 PAPERS IN AUSTRALIAN LINGUISTICS No. 14 by Bruce E. Waters Peter A. Busby Department of Linguistics Research School of Pacific Studies THE AUSTRALIAN NATIONAL UNIVERSITY Waters, B. and Busby, P. editors. Papers in Australian Linguistics No. 14. A-60, vi + 183 pages. Pacific Linguistics, The Australian National University, 1980. DOI:10.15144/PL-A60.cover ©1980 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. PACIFIC LINGUISTICS is issued through the L�ng u�¢��c C��cle 06 Canbe��a and consists of four series: SERI ES A - OCCASIONAL PAPERS SERIES B - MONOGRA PHS SERIES C - BOOKS SERIES V - SPECIAL PUB LICATIONS EDITOR: S.A. Wurm. ASSOCIATE EDITORS: D.C. Laycock, C.L. Voorhoeve, D.T. Tryon, T.E. Dutton. EDITORIAL ADVISERS: B. Bender, University of Hawaii J. Lynch, University of Papua New Guinea D. Bradley, University of Melbourne K.A. MCElhanon, University of Texas A. Capell, University of Sydney J. MCKaughan, University of Hawaii S. Elbert, University of Hawaii P. Muhlhausler, Linacre College, Oxford K. Franklin, Summer Institute of G.N. O'Grady, University of Victoria, B.C. Linguistics A.K. Pawley, University of Hawaii W.W. Glover, Summer Institute of K. Pike, University of Michigan; Summer Linguistics Institute of Linguistics G. Grace, University of Hawaii E.C. Polome, University of Texas M.A.K. Halliday, university of G. Sankoff, Universite de Montreal Sydney W.A.L. Stokhof, National Center for A. Healey, Summer Institute of Language Development, Jakarta; Linguistics University of Leiden L. -
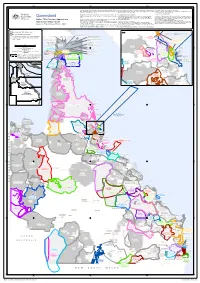
Queensland for That Map Shows This Boundary Rather Than the Boundary As Per the Register of Native Title Databases Is Required
140°0'E 145°0'E 150°0'E Claimant application and determination boundary data compiled from NNTT based on Where the boundary of an application has been amended in the Federal Court, the determination, a search of the Tribunal's registers and data sourced from Department of Resources (Qld) © The State of Queensland for that map shows this boundary rather than the boundary as per the Register of Native Title databases is required. Further information is available from the Tribunals website at portion where their data has been used. Claims (RNTC), if a registered application. www.nntt.gov.au or by calling 1800 640 501 © Commonwealth of Australia 2021 Topographic vector data is © Commonwealth of Australia (Geoscience Australia) 2006. The applications shown on the map include: Maritime boundaries data is © Commonwealth of Australia (Geoscience Australia) - registered applications (i.e. those that have complied with the registration test), The Registrar, the National Native Title Tribunal and its staff, members and agents and Queensland 2006. - new and/or amended applications where the registration test is being applied, the Commonwealth (collectively the Commonwealth) accept no liability and give no - unregistered applications (i.e. those that have not been accepted for registration), undertakings guarantees or warranties concerning the accuracy, completeness or As part of the transitional provisions of the amended Native Title Act in 1998, all - compensation applications. fitness for purpose of the information provided. Native Title Claimant Applications applications were taken to have been filed in the Federal Court. In return for you receiving this information you agree to release and Any changes to these applications and the filing of new applications happen through Determinations shown on the map include: indemnify the Commonwealth and third party data suppliers in respect of all claims, and Determination Areas the Federal Court. -

A Linguistic Bibliography of Aboriginal Australia and the Torres Strait Islands
OZBIB: a linguistic bibliography of Aboriginal Australia and the Torres Strait Islands Dedicated to speakers of the languages of Aboriginal Australia and the Torres Strait Islands and al/ who work to preserve these languages Carrington, L. and Triffitt, G. OZBIB: A linguistic bibliography of Aboriginal Australia and the Torres Strait Islands. D-92, x + 292 pages. Pacific Linguistics, The Australian National University, 1999. DOI:10.15144/PL-D92.cover ©1999 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. PACIFIC LINGUISTICS FOUNDING EDITOR: Stephen A. Wurm EDITORIAL BOARD: Malcolm D. Ross and Darrell T. Tryon (Managing Editors), John Bowden, Thomas E. Dutton, Andrew K. Pawley Pacific Linguistics is a publisher specialising in linguistic descriptions, dictionaries, atlases and other material on languages of the Pacific, the Philippines, Indonesia and Southeast Asia. The authors and editors of Pacific Linguistics publications are drawn from a wide range of institutions around the world. Pacific Linguistics is associated with the Research School of Pacific and Asian Studies at The Australian NatIonal University. Pacific Linguistics was established in 1963 through an initial grant from the Hunter Douglas Fund. It is a non-profit-making body financed largely from the sales of its books to libraries and individuals throughout the world, with some assistance from the School. The Editorial Board of Pacific Linguistics is made up of the academic staff of the School's Department of Linguistics. The Board also appoints a body of editorial advisors drawn from the international community of linguists. -

Living on Saltwater Country Saltwater on Living Background
Living on Saltwater Country Background P APER interests in northernReview Australianof literature marine about environments Aboriginal rights, use, management and Living on Saltwater Country Review of literature about Aboriginal rights, use, ∨ management and interests in northern Australian marine environments Healthy oceans: cared for, understood and used wisely for the Healthy wisely benefit of all, now and in the future. Healthy oceans: cared for, for the Healthy understood and used wisely for the benefit of all, oceans: for the National Oceans Office National Oceans Office National Oceans Office Level 1, 80 Elizabeth St, Hobart GPO Box 2139, Hobart, TAS, Australia 7001 Tel: +61 3 6221 5000 Fax: +61 3 6221 5050 www.oceans.gov.au The National Oceans Office is an Executive Agency of the Australian Government Living on Saltwater Country Aboriginal and Torres Strait Islander readers should be warned that this document may contain images of and quotes from deceased persons. Title: Living on Saltwater Country. Review of literature about Aboriginal rights, use, management and interests in northern Australian marine environments. Copyright: © National Oceans Office 2004 Disclaimers: General This paper is not intended to be used or relied upon for any purpose other than to inform the management of marine resources. The Traditional Owners and native title holders of the regions discussed in this report have not had the opportunity for comment on this document and it is not intended to have any bearing on their individual or group rights, but rather to provide an overview of the use and management of marine resources in the Northern Planning Area for the Northern regional marine planning process. -

National Indigenous Languages Survey Report 2005 National Indigenous Languages Survey Report 2005
National Indigenous Languages Survey Report 2005 National Indigenous Languages Survey Report 2005 Report submitted to the Department of Communications, Information Technology and the Arts by the Australian Institute of Aboriginal and Torres Strait Islander Studies in association with the Federation of Aboriginal and Torres Strait Islander Languages Front cover photo: Yipirinya School Choir, Northern Territory. Photo by Faith Baisden Disclaimer The Commonwealth, its employees, officers and agents are not responsible for the activities of organisations and agencies listed in this report and do not accept any liability for the results of any action taken in reliance upon, or based on or in connection with this report. To the extent legally possible, the Commonwealth, its employees, officers and agents, disclaim all liability arising by reason of any breach of any duty in tort (including negligence and negligent misstatement) or as a result of any errors and omissions contained in this document. The views expressed in this report and organisations and agencies listed do not have the endorsement of the Department of Communications, Information Technology and the Arts (DCITA). ISBN 0 642753 229 © Commonwealth of Australia 2005 This work is copyright. Apart from any use as permitted under the Copyright Act 1968, no part may be reproduced by any process without prior written permission from the Commonwealth. Requests and inquiries concerning reproduction and rights should be addressed to the: Commonwealth Copyright Administration Attorney-General’s Department Robert Garran Offices National Circuit CANBERRA ACT 2600 Or visit http://www.ag.gov.au/cca This report was commissioned by the former Broadcasting, Languages and Arts and Culture Branch of Aboriginal and Torres Strait Islander Services (ATSIS).