Early Life Determinants of Metabolic and Reproductive Health
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
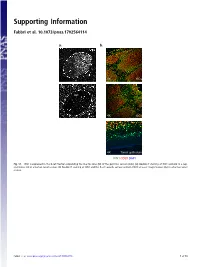
Supporting Information
Supporting Information Fabbri et al. 10.1073/pnas.1702564114 a. b. GC 4X GCs 20x GC 4X GCs 4X Tonsil epithelium ICN1 CD20 DAPI Fig. S1. ICN1 is expressed in the B-cell fraction populating the mantle zone (M) of the germinal centers (GCs). (A) Double IF staining of ICN1 and AID in a rep- resentative GC in a human tonsil section. (B) Double IF staining of ICN1 and the B-cell–specific surface antigen CD20 at lower magnification (4×) in a human tonsil section. Fabbri et al. www.pnas.org/cgi/content/short/1702564114 1of10 Fig. S2. ICN1 expression analysis in a panel of primary CLL cases and PBMC. (A) IB analysis of ICN1 and control β-actin in a panel of 124 CLL PB primary CLL cases, (B) in primary NOTCH1–wild-type CLL cells treated with the γ-secretase inhibitor Compound E (CpE, 500 nM, 8 h) or control DMSO, and (C) in PBMC protein extracts and representative primary CLL cases expressing ICN1. Samples are color-coded based on the NOTCH1 mutational status [red, clonal NOTCH1 PEST-truncating events; orange, subclonal NOTCH1 PEST-truncating events; blue, RAG-mediated NOTCH1 translocation (83); and black, NOTCH1–wild-type]. Samples in gray were excluded from the analysis because of low quality of the protein lysate, low viability, or low leukemic representation. Color-coded arrows indicate cases subjected to RNA-Seq analysis: dark red denotes NOTCH1-mutated cases expressing ICN1; blue, NOTCH1–wild-type cases expressing ICN1; and green, ICN1− NOTCH1–wild-type cases. Abbreviations: MO+DL1, MO1043 cells cocultured on OP9-DL1 cells (54); s.e., short exposure; l.e., long exposure. -

Chromosome Abnormalities in Neonates with Congenital Heart Defects
CHROMOSOME ABNORMALITIES IN NEONATES WITH CONGENITAL HEART DEFECTS by Kristine Kay Bachman B.A. Biology and Spanish, Bucknell University, 2010 Submitted to the Graduate Faculty of Human Genetics, Genetic Counseling Graduate School of Public Health in partial fulfillment of the requirements for the degree of Master of Science University of Pittsburgh 2012 UNIVERSITY OF PITTSBURGH Graduate School of Public Health This thesis was presented by Kristine Kay Bachman It was defended on April 11, 2012 and approved by Thesis Advisor: Suneeta Madan-Khetarpal, MD Associate Professor of Pediatrics Division of Medical Genetics School of Medicine University of Pittsburgh Committee Member: Robin Grubs, MS, PhD, CGC Assistant Professor of Human Genetics Co-Director, Genetic Counseling Program Department of Human Genetics Graduate School of Public Health University of Pittsburgh Committee Member: Susanne Gollin, PhD Professor of Human Genetics Department of Human Genetics Graduate School of Public Health University of Pittsburgh Committee Member: Stephanie DeWard, MS, CGC Division of Medical Genetics School of Medicine University of Pittsburgh ii Kristine Kay Bachman 2012 iii Thesis Advisor: Suneeta Madan-Khetarpal, MD CHROMOSOME ABNORMALITIES IN NEONATES WITH CONGENITAL HEART DEFECTS Kristine Kay Bachman, M.S. University of Pittsburgh, 2012 Congenital heart disease (CHD) contributes to the rate of birth defects in the population with an incidence of nearly 1% of all live births (1). CHD has significant Public Health importance due to its high incidence, clinical severity, and complexity of medical management. In some cases, efficiently diagnosing the underlying cause of CHD is essential to providing optimal clinical care. The etiology of CHD is hypothesized to be largely multifactorial in nature, but chromosome abnormalities account for 8-13% of all CHD (2, 3). -

WO 2018/067991 Al 12 April 2018 (12.04.2018) W !P O PCT
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2018/067991 Al 12 April 2018 (12.04.2018) W !P O PCT (51) International Patent Classification: achusetts 021 15 (US). THE BROAD INSTITUTE, A61K 51/10 (2006.01) G01N 33/574 (2006.01) INC. [US/US]; 415 Main Street, Cambridge, Massachu C07K 14/705 (2006.01) A61K 47/68 (2017.01) setts 02142 (US). MASSACHUSETTS INSTITUTE OF G01N 33/53 (2006.01) TECHNOLOGY [US/US]; 77 Massachusetts Avenue, Cambridge, Massachusetts 02139 (US). (21) International Application Number: PCT/US2017/055625 (72) Inventors; and (71) Applicants: KUCHROO, Vijay K. [IN/US]; 30 Fairhaven (22) International Filing Date: Road, Newton, Massachusetts 02149 (US). ANDERSON, 06 October 2017 (06.10.2017) Ana Carrizosa [US/US]; 110 Cypress Street, Brookline, (25) Filing Language: English Massachusetts 02445 (US). MADI, Asaf [US/US]; c/o The Brigham and Women's Hospital, Inc., 75 Francis (26) Publication Language: English Street, Boston, Massachusetts 021 15 (US). CHIHARA, (30) Priority Data: Norio [US/US]; c/o The Brigham and Women's Hospital, 62/405,835 07 October 2016 (07.10.2016) US Inc., 75 Francis Street, Boston, Massachusetts 021 15 (US). REGEV, Aviv [US/US]; 15a Ellsworth Ave, Cambridge, (71) Applicants: THE BRIGHAM AND WOMEN'S HOSPI¬ Massachusetts 02139 (US). SINGER, Meromit [US/US]; TAL, INC. [US/US]; 75 Francis Street, Boston, Mass c/o The Broad Institute, Inc., 415 Main Street, Cambridge, (54) Title: MODULATION OF NOVEL IMMUNE CHECKPOINT TARGETS CD4 FIG. -

IBRAHIM ALDEAILEJ Phd.2013.Pdf
Bangor University DOCTOR OF PHILOSOPHY Identification and functional characterisation of germ line genes in human cancer cells Aldeailej, Ibrahim Award date: 2013 Awarding institution: Bangor University Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal ? Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. Download date: 09. Oct. 2021 Bangor University School of Biological Sciences Identification and functional characterisation of germ line genes in human cancer cells Ph.D. Thesis 2013 IBRAHIM ALDEAILEJ Declaration and Consent Details of the Work I hereby agree to deposit the following item in the digital repository maintained by Bangor University and/or in any other repository authorized for use by Bangor University. Author Name: IBRAHIM MOHAMMED ALDEAILEJ Title: Identification and functional characterisation of germ line genes in human cancer cells Supervisor/Department: Dr. Ramsay James McFarlane/ School of Biological Sciences Funding body (if any): kingdom of Saudi Arabia Government Qualification/Degree obtained: Ph.D. -

Overexpression of the Proneural Transcription Factor ASCL1 In
Malli et al. Molecular Cytogenetics (2018) 11:3 DOI 10.1186/s13039-018-0355-7 CASE REPORT Open Access Overexpression of the proneural transcription factor ASCL1 in chronic lymphocytic leukemia with a t(12;14)(q23.2;q32.3) Theodora Malli1, Melanie Rammer1, Sabrina Haslinger1, Jonathan Burghofer1, Sonja Burgstaller2, Hans-Christian Boesmueller3,4, Renate Marschon1, Wolfgang Kranewitter1, Martin Erdel1, Sabine Deutschbauer1 and Gerald Webersinke1* Abstract Background: Translocations of the IGH locus on 14q32.3 are present in about 8% of patients with chronic lymphocytic leukemia (CLL) and contribute to leukemogenesis by deregulating the expression of the IGH-partner genes. Identification of these genes and investigation of the downstream effects of their deregulation can reveal disease-causing mechanisms. Case presentation: We report on the molecular characterization of a novel t(12;14)(q23.2;q32.3) in CLL. As a consequence of the rearrangement ASCL1 was brought into proximity of the IGHJ-Cμ enhancer and was highly overexpressed in the aberrant B-cells of the patient, as shown by qPCR and immunohistochemistry. ASCL1 encodes for a transcription factor acting as a master regulator of neurogenesis, is overexpressed in neuroendocrine tumors and a promising therapeutic target in small cell lung cancer (SCLC). Its overexpression has also been recently reported in acute adult T-cell leukemia/lymphoma. To examine possible downstream effects of the ASCL1 upregulation in CLL, we compared the gene expression of sorted CD5+ cells of the translocation patient to that of CD19+ B-cells from seven healthy donors and detected 176 significantly deregulated genes (Fold Change ≥2, FDR p ≤ 0.01). -

The DNA Sequence and Comparative Analysis of Human Chromosome 20
articles The DNA sequence and comparative analysis of human chromosome 20 P. Deloukas, L. H. Matthews, J. Ashurst, J. Burton, J. G. R. Gilbert, M. Jones, G. Stavrides, J. P. Almeida, A. K. Babbage, C. L. Bagguley, J. Bailey, K. F. Barlow, K. N. Bates, L. M. Beard, D. M. Beare, O. P. Beasley, C. P. Bird, S. E. Blakey, A. M. Bridgeman, A. J. Brown, D. Buck, W. Burrill, A. P. Butler, C. Carder, N. P. Carter, J. C. Chapman, M. Clamp, G. Clark, L. N. Clark, S. Y. Clark, C. M. Clee, S. Clegg, V. E. Cobley, R. E. Collier, R. Connor, N. R. Corby, A. Coulson, G. J. Coville, R. Deadman, P. Dhami, M. Dunn, A. G. Ellington, J. A. Frankland, A. Fraser, L. French, P. Garner, D. V. Grafham, C. Grif®ths, M. N. D. Grif®ths, R. Gwilliam, R. E. Hall, S. Hammond, J. L. Harley, P. D. Heath, S. Ho, J. L. Holden, P. J. Howden, E. Huckle, A. R. Hunt, S. E. Hunt, K. Jekosch, C. M. Johnson, D. Johnson, M. P. Kay, A. M. Kimberley, A. King, A. Knights, G. K. Laird, S. Lawlor, M. H. Lehvaslaiho, M. Leversha, C. Lloyd, D. M. Lloyd, J. D. Lovell, V. L. Marsh, S. L. Martin, L. J. McConnachie, K. McLay, A. A. McMurray, S. Milne, D. Mistry, M. J. F. Moore, J. C. Mullikin, T. Nickerson, K. Oliver, A. Parker, R. Patel, T. A. V. Pearce, A. I. Peck, B. J. C. T. Phillimore, S. R. Prathalingam, R. W. Plumb, H. Ramsay, C. M. -

The Effect of Prpsc Accumulation on Inflammatory Gene
Edinburgh Research Explorer The effect of PrP(Sc) accumulation on inflammatory gene expression within sheep peripheral lymphoid tissue Citation for published version: Gossner, AG & Hopkins, J 2015, 'The effect of PrP(Sc) accumulation on inflammatory gene expression within sheep peripheral lymphoid tissue', Veterinary Microbiology, vol. 181, no. 3-4, pp. 204-211. https://doi.org/10.1016/j.vetmic.2015.10.013 Digital Object Identifier (DOI): 10.1016/j.vetmic.2015.10.013 Link: Link to publication record in Edinburgh Research Explorer Document Version: Publisher's PDF, also known as Version of record Published In: Veterinary Microbiology General rights Copyright for the publications made accessible via the Edinburgh Research Explorer is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy The University of Edinburgh has made every reasonable effort to ensure that Edinburgh Research Explorer content complies with UK legislation. If you believe that the public display of this file breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 29. Sep. 2021 G Model VETMIC 7118 No. of Pages 8 Veterinary Microbiology xxx (2015) xxx–xxx Contents lists available at ScienceDirect Veterinary Microbiology journal homepage: www.elsevier.com/locate/vetmic Sc The effect of PrP accumulation on inflammatory gene expression within sheep peripheral lymphoid tissue Anton G. Gossner, John Hopkins* The Roslin Institute & R(D)SVS, University of Edinburgh, Easter Bush, Midlothian EH25 9RG, UK A R T I C L E I N F O A B S T R A C T Sc Article history: Accumulation of the misfolded prion protein, PrP in the central nervous system (CNS) is strongly linked Received 27 April 2015 to progressive neurodegenerative disease. -

Ep 2885427 B1
(19) TZZ _T (11) EP 2 885 427 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12Q 1/68 (2018.01) 10.01.2018 Bulletin 2018/02 (86) International application number: (21) Application number: 13759978.3 PCT/EP2013/002462 (22) Date of filing: 14.08.2013 (87) International publication number: WO 2014/026768 (20.02.2014 Gazette 2014/08) (54) COLORECTAL CANCER METHYLATION MARKER KOLOREKTALKREBSMETHYLIERUNGSMARKER MARQUEUR DE METHYLATION POUR LE CANCER COLORECTAL (84) Designated Contracting States: • RAFAEL A IRIZARRY ET AL: "The human colon AL AT BE BG CH CY CZ DE DK EE ES FI FR GB cancer methylome shows similar hypo- and GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO hypermethylation at conserved tissue-specific PL PT RO RS SE SI SK SM TR CpG island shores", NATURE GENETICS, vol. 41, no. 2, 1 February 2009 (2009-02-01), pages (30) Priority: 14.08.2012 EP 12180459 178-186, XP055029485, ISSN: 1061-4036, DOI: 10.1038/ng.298 (43) Date of publication of application: • M. D. ROBINSON ET AL: "Evaluation of 24.06.2015 Bulletin 2015/26 affinity-based genome-wide DNA methylation data: Effects of CpG density, amplification bias, (73) Proprietor: Max-Planck-Gesellschaft zur and copy number variation", GENOME Förderung RESEARCH, vol. 20, no. 12, 1 December 2010 der Wissenschaften (2010-12-01), pages 1719-1729, XP055041625, 80539 Munich (DE) ISSN: 1088-9051, DOI: 10.1101/gr.110601.110 • E. A. HOUSEMAN ET AL: "Copy number variation (72) Inventors: has little impact on bead-array-based measures • SCHWEIGER, Michal-Ruth of DNA methylation", BIOINFORMATICS, vol. -

Translational Profiling Reveals the Transcriptome of Leptin Receptor Neurons and Its Regulation by Leptin
TRANSLATIONAL PROFILING REVEALS THE TRANSCRIPTOME OF LEPTIN RECEPTOR NEURONS AND ITS REGULATION BY LEPTIN by Margaret B. Allison A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Molecular and Integrative Physiology) In the University of Michigan 2015 Doctoral Committee: Professor Martin G. Myers Jr., Chair Associate Professor Carol F. Elias Professor Malcolm J. Low Professor Suzanne Moenter Professor Audrey Seasholtz Before you leave these portals To meet less fortunate mortals There's just one final message I would give to you: You all have learned reliance On the sacred teachings of science So I hope, through life, you never will decline In spite of philistine defiance To do what all good scientists do: Experiment! -- Cole Porter There is no cure for curiosity. -- unknown © Margaret Brewster Allison 2015 ACKNOWLEDGEMENTS If it takes a village to raise a child, it takes a research university to raise a graduate student. There are many people who have supported me over the past six years at Michigan, and it is hard to imagine pursuing my PhD without them. First and foremost among all the people I need to thank is my mentor, Martin. Nothing I might say here would ever suffice to cover the depth and breadth of my gratitude to him. Without his patience, his insight, and his at times insufferably positive outlook, I don’t know where I would be today. Martin supported my intellectual curiosity, honed my scientific inquiry, and allowed me to do some really fun research in his lab. It was a privilege and a pleasure to work for him and with him. -

Snps in Genes Coding for ROS Metabolism and Signalling in Association with Docetaxel Clearance
The Pharmacogenomics Journal (2010) 10, 513–523 & 2010 Macmillan Publishers Limited. All rights reserved 1470-269X/10 www.nature.com/tpj ORIGINAL ARTICLE SNPs in genes coding for ROS metabolism and signalling in association with docetaxel clearance H Edvardsen1,2, PF Brunsvig3, The dose of docetaxel is currently calculated based on body surface area 1,4 5 and does not reflect the pharmacokinetic, metabolic potential or genetic H Solvang , A Tsalenko , background of the patients. The influence of genetic variation on the 6 7 A Andersen , A-C Syvanen , clearance of docetaxel was analysed in a two-stage analysis. In step one, 583 Z Yakhini5, A-L Børresen-Dale1,2, single-nucleotide polymorphisms (SNPs) in 203 genes were genotyped on H Olsen6, S Aamdal3 and samples from 24 patients with locally advanced non-small cell lung cancer. 1,2 We found that many of the genes harbour several SNPs associated with VN Kristensen clearance of docetaxel. Most notably these were four SNPs in EGF, three SNPs 1Department of Genetics, Institute of Cancer in PRDX4 and XPC, and two SNPs in GSTA4, TGFBR2, TNFAIP2, BCL2, DPYD Research, Oslo University Hospital Radiumhospitalet, and EGFR. The multiple SNPs per gene suggested the existence of common Oslo, Norway; 2Institute of Clinical Medicine, haplotypes associated with clearance. These were confirmed with detailed 3 University of Oslo, Oslo, Norway; Cancer Clinic, haplotype analysis. On the basis of analysis of variance (ANOVA), quantitative Oslo University Hospital Radiumhospitalet, Oslo, Norway; 4Institute of -

Chromatin Conformation Links Distal Target Genes to CKD Loci
BASIC RESEARCH www.jasn.org Chromatin Conformation Links Distal Target Genes to CKD Loci Maarten M. Brandt,1 Claartje A. Meddens,2,3 Laura Louzao-Martinez,4 Noortje A.M. van den Dungen,5,6 Nico R. Lansu,2,3,6 Edward E.S. Nieuwenhuis,2 Dirk J. Duncker,1 Marianne C. Verhaar,4 Jaap A. Joles,4 Michal Mokry,2,3,6 and Caroline Cheng1,4 1Experimental Cardiology, Department of Cardiology, Thoraxcenter Erasmus University Medical Center, Rotterdam, The Netherlands; and 2Department of Pediatrics, Wilhelmina Children’s Hospital, 3Regenerative Medicine Center Utrecht, Department of Pediatrics, 4Department of Nephrology and Hypertension, Division of Internal Medicine and Dermatology, 5Department of Cardiology, Division Heart and Lungs, and 6Epigenomics Facility, Department of Cardiology, University Medical Center Utrecht, Utrecht, The Netherlands ABSTRACT Genome-wide association studies (GWASs) have identified many genetic risk factors for CKD. However, linking common variants to genes that are causal for CKD etiology remains challenging. By adapting self-transcribing active regulatory region sequencing, we evaluated the effect of genetic variation on DNA regulatory elements (DREs). Variants in linkage with the CKD-associated single-nucleotide polymorphism rs11959928 were shown to affect DRE function, illustrating that genes regulated by DREs colocalizing with CKD-associated variation can be dysregulated and therefore, considered as CKD candidate genes. To identify target genes of these DREs, we used circular chro- mosome conformation capture (4C) sequencing on glomerular endothelial cells and renal tubular epithelial cells. Our 4C analyses revealed interactions of CKD-associated susceptibility regions with the transcriptional start sites of 304 target genes. Overlap with multiple databases confirmed that many of these target genes are involved in kidney homeostasis. -

The Convergent Roles of the Nuclear Factor I Transcription Factors in Development and Cancer
The convergent roles of the nuclear factor I transcription factors in development and cancer Kok-Siong Chen1, Jonathan W.C. Lim1, Linda J. Richards1,2*, Jens Bunt1* 1 Queensland Brain Institute, The University of Queensland, Brisbane, Australia 4072 2 The School of Biomedical Sciences, The University of Queensland, Brisbane, Australia 4072 * Corresponding authors: Jens Bunt: [email protected] and Linda J Richards: [email protected] 1 Highlights • NFI transcription factors play important roles in normal development and are associated with cancer in multiple organ systems. • NFI transcription factors are implicated in tumours that arise from cells that normally express the concordant transcription factor during development. • The role of NFI transcription factors in regulating the balance between cell proliferation and differentiation during development may be disrupted in cancer. • NFI transcription factors are context-dependent in various cancer types and can play either oncogenic or tumour-suppressive roles. 2 Abstract The nuclear factor I (NFI) transcription factors play important roles during normal development and have been associated with developmental abnormalities in humans. All four family members, NFIA, NFIB, NFIC and NFIX, have a homologous DNA binding domain and function by regulating cell proliferation and differentiation via the transcriptional control of their target genes. More recently, NFI genes have also been implicated in cancer based on genomic analyses and studies of animal models in a variety of tumours across multiple organ systems. However, the association between their functions in development and in cancer is not well described. In this review, we summarise the evidence suggesting a converging role for the NFI genes in development and cancer.