Gravitational Octree Code Performance Evaluation on Volta GPU
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Units and Magnitudes (Lecture Notes)
physics 8.701 topic 2 Frank Wilczek Units and Magnitudes (lecture notes) This lecture has two parts. The first part is mainly a practical guide to the measurement units that dominate the particle physics literature, and culture. The second part is a quasi-philosophical discussion of deep issues around unit systems, including a comparison of atomic, particle ("strong") and Planck units. For a more extended, profound treatment of the second part issues, see arxiv.org/pdf/0708.4361v1.pdf . Because special relativity and quantum mechanics permeate modern particle physics, it is useful to employ units so that c = ħ = 1. In other words, we report velocities as multiples the speed of light c, and actions (or equivalently angular momenta) as multiples of the rationalized Planck's constant ħ, which is the original Planck constant h divided by 2π. 27 August 2013 physics 8.701 topic 2 Frank Wilczek In classical physics one usually keeps separate units for mass, length and time. I invite you to think about why! (I'll give you my take on it later.) To bring out the "dimensional" features of particle physics units without excess baggage, it is helpful to keep track of powers of mass M, length L, and time T without regard to magnitudes, in the form When these are both set equal to 1, the M, L, T system collapses to just one independent dimension. So we can - and usually do - consider everything as having the units of some power of mass. Thus for energy we have while for momentum 27 August 2013 physics 8.701 topic 2 Frank Wilczek and for length so that energy and momentum have the units of mass, while length has the units of inverse mass. -

Guide for the Use of the International System of Units (SI)
Guide for the Use of the International System of Units (SI) m kg s cd SI mol K A NIST Special Publication 811 2008 Edition Ambler Thompson and Barry N. Taylor NIST Special Publication 811 2008 Edition Guide for the Use of the International System of Units (SI) Ambler Thompson Technology Services and Barry N. Taylor Physics Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899 (Supersedes NIST Special Publication 811, 1995 Edition, April 1995) March 2008 U.S. Department of Commerce Carlos M. Gutierrez, Secretary National Institute of Standards and Technology James M. Turner, Acting Director National Institute of Standards and Technology Special Publication 811, 2008 Edition (Supersedes NIST Special Publication 811, April 1995 Edition) Natl. Inst. Stand. Technol. Spec. Publ. 811, 2008 Ed., 85 pages (March 2008; 2nd printing November 2008) CODEN: NSPUE3 Note on 2nd printing: This 2nd printing dated November 2008 of NIST SP811 corrects a number of minor typographical errors present in the 1st printing dated March 2008. Guide for the Use of the International System of Units (SI) Preface The International System of Units, universally abbreviated SI (from the French Le Système International d’Unités), is the modern metric system of measurement. Long the dominant measurement system used in science, the SI is becoming the dominant measurement system used in international commerce. The Omnibus Trade and Competitiveness Act of August 1988 [Public Law (PL) 100-418] changed the name of the National Bureau of Standards (NBS) to the National Institute of Standards and Technology (NIST) and gave to NIST the added task of helping U.S. -
![Arxiv:1303.1588V2 [Physics.Hist-Ph] 8 Jun 2015 4.4 Errors in the Article](https://docslib.b-cdn.net/cover/6367/arxiv-1303-1588v2-physics-hist-ph-8-jun-2015-4-4-errors-in-the-article-1106367.webp)
Arxiv:1303.1588V2 [Physics.Hist-Ph] 8 Jun 2015 4.4 Errors in the Article
Translation of an article by Paul Drude in 1904 Translation by A. J. Sederberg1;∗ (pp. 512{519, 560{561), J. Burkhart2;y (pp. 519{527), and F. Apfelbeck3;z (pp. 528{560) Discussion by B. H. McGuyer1;x 1Department of Physics, Princeton University, Princeton, New Jersey 08544, USA 2Department of Physics, Columbia University, 538 West 120th Street, New York, NY 10027-5255, USA June 9, 2015 Abstract English translation of P. Drude, Annalen der Physik 13, 512 (1904), an article by Paul Drude about Tesla transformers and wireless telegraphy. Includes a discussion of the derivation of an equivalent circuit and the prediction of nonreciprocal mutual inductance for Tesla transformers in the article, which is supplementary material for B. McGuyer, PLoS ONE 9, e115397 (2014). Contents 1 Introduction 2 2 Bibliographic information 2 3 Translation 3 I. Definition and Integration of the Differential Equations . .3 Figure 1 . .5 II. The Magnetic Coupling is Very Small . .9 III. Measurement of the Period and the Damping . 12 IV. The Magnetic Coupling is Not Very Small . 19 VII. Application to Wireless Telegraphy . 31 Figure 2 . 32 Figure 3 . 33 Summary of Main Results . 39 4 Discussion 41 4.1 Technical glossary . 41 4.2 Hopkinson's law . 41 4.3 Equivalent circuit parameters from the article . 42 arXiv:1303.1588v2 [physics.hist-ph] 8 Jun 2015 4.4 Errors in the article . 42 4.5 Modifications to match Ls with previous work . 42 ∗Present address: Division of Biological Sciences, University of Chicago, 5812 South Ellis Avenue, Chicago, IL 60637, USA. yPresent address: Department of Microsystems and Informatics, Hochschule Kaiserslautern, Amerikastrasse 1, D-66482 Zweibr¨ucken, Germany. -

From Cell to Battery System in Bevs: Analysis of System Packing Efficiency and Cell Types
Article From Cell to Battery System in BEVs: Analysis of System Packing Efficiency and Cell Types Hendrik Löbberding 1,* , Saskia Wessel 2, Christian Offermanns 1 , Mario Kehrer 1 , Johannes Rother 3, Heiner Heimes 1 and Achim Kampker 1 1 Chair for Production Engineering of E-Mobility Components, RWTH Aachen University, 52064 Aachen, Germany; c.off[email protected] (C.O.); [email protected] (M.K.); [email protected] (H.H.); [email protected] (A.K.) 2 Fraunhofer IPT, 48149 Münster, Germany; [email protected] 3 Faculty of Mechanical Engineering, RWTH Aachen University, 52072 Aachen, Germany; [email protected] * Correspondence: [email protected] Received: 7 November 2020; Accepted: 4 December 2020; Published: 10 December 2020 Abstract: The motivation of this paper is to identify possible directions for future developments in the battery system structure for BEVs to help choosing the right cell for a system. A standard battery system that powers electrified vehicles is composed of many individual battery cells, modules and forms a system. Each of these levels have a natural tendency to have a decreased energy density and specific energy compared to their predecessor. This however, is an important factor for the size of the battery system and ultimately, cost and range of the electric vehicle. This study investigated the trends of 25 commercially available BEVs of the years 2010 to 2019 regarding their change in energy density and specific energy of from cell to module to system. Systems are improving. However, specific energy is improving more than energy density. -

AP Physics 2: Algebra Based
AP® PHYSICS 2 TABLE OF INFORMATION CONSTANTS AND CONVERSION FACTORS -27 -19 Proton mass, mp =1.67 ¥ 10 kg Electron charge magnitude, e =1.60 ¥ 10 C -27 -19 Neutron mass, mn =1.67 ¥ 10 kg 1 electron volt, 1 eV= 1.60 ¥ 10 J -31 8 Electron mass, me =9.11 ¥ 10 kg Speed of light, c =3.00 ¥ 10 m s Universal gravitational Avogadro’s number, N 6.02 1023 mol- 1 -11 3 2 0 = ¥ constant, G =6.67 ¥ 10 m kg s Acceleration due to gravity 2 Universal gas constant, R = 8.31 J (mol K) at Earth’s surface, g = 9.8 m s -23 Boltzmann’s constant, kB =1.38 ¥ 10 J K 1 unified atomic mass unit, 1 u=¥= 1.66 10-27 kg 931 MeV c2 -34 -15 Planck’s constant, h =¥=¥6.63 10 J s 4.14 10 eV s -25 3 hc =¥=¥1.99 10 J m 1.24 10 eV nm -12 2 2 Vacuum permittivity, e0 =8.85 ¥ 10 C N m 9 22 Coulomb’s law constant, k =1 4pe0 = 9.0 ¥ 10 N m C -7 Vacuum permeability, mp0 =4 ¥ 10 (T m) A -7 Magnetic constant, k¢ =mp0 4 = 1 ¥ 10 (T m) A 1 atmosphere pressure, 1 atm=¥= 1.0 1052 N m 1.0¥ 105 Pa meter, m mole, mol watt, W farad, F kilogram, kg hertz, Hz coulomb, C tesla, T UNIT second, s newton, N volt, V degree Celsius, ∞C SYMBOLS ampere, A pascal, Pa ohm, W electron volt, eV kelvin, K joule, J henry, H PREFIXES VALUES OF TRIGONOMETRIC FUNCTIONS FOR COMMON ANGLES Factor Prefix Symbol q 0 30 37 45 53 60 90 12 tera T 10 sinq 0 12 35 22 45 32 1 109 giga G cosq 1 32 45 22 35 12 0 106 mega M 103 kilo k tanq 0 33 34 1 43 3 • 10-2 centi c 10-3 milli m The following conventions are used in this exam. -

Modern GPU Architecture
Modern GPU Architecture Msc Software Engineering student of Tartu University Ismayil Tahmazov [email protected] Agenda • What is a GPU? • GPU evolution!! • GPU costs • GPU pipeline • Fermi architecture • Kepler architecture • Pascal architecture • Turing architecture • AMD Radeon R9 • AMD vs Nvidia What is it a GPU? A graphics processing unit is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device. photo reference Wikipedia What is it a GPU? GPU Evolution image:reference Evolution of Nvidia GeForce 1999 - 2018 Modern GPU First GPU Nvidia GeForce 256 GeForce GTX 1050 CUDA CUDA is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs. text source photo reference Graphics Processing image:refence source Nvidia GeForce 8880 GPU pipeline Why GPUs so fast ? Why GPUs so fast ? simplified Nvidia GPU architecture MP = Multi Processor SM = Shared Memory SFU = Special Functions Unit IU = Instruction Unit SP = Streaming processor reference Nvidia Fermi GPU Architecture Nvidia Fermi GPU Architecture photo Nvidia Kepler GPU Architecture reference Specifications reference for table Pascal architecture reference GP100 (Tesla P100) image Pascal Streaming Multiprocessor Compute Capabilities: GK110 vs GM200 vs GP100 Cross-section Illustrating GP100 adjacent HBM2 stacks Cross-section Photomicrograph of a P100 HBM2 stack and GP100 GPU image reference image refence Nvidia Turing GPU Architecture reference Nvidia Turing TU102 GPU reference NVIDIA Pascal GP102 vs Turing TU102 reference Turing Streaming Multiprocessor (SM) reference New shared memory architecture reference Turing Shading Performance reference Costs !!! Really? image image Conclusion We have several GPU architectures from different companies. -
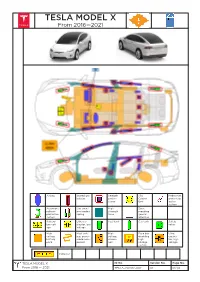
TESLA MODEL X from 2016—2021
TESLA MODEL X From 2016—2021 Airbag Stored gas Seatbelt SRS Pedestrian inflator preten- Control protection sioner Unit active system Automatic Gas strut/ High Zone rollover pre-loaded strength requiring protection spring zone special system attention Battery Ultra ca- Fuel tank Gas tank Safety low volt- pacitor, low valve age voltage High High volt- High Fuse box Ultra voltage age power voltage disabling capaci- battery cable/com- discon- high tor, high pack ponent nect voltage voltage system Cable cut TESLA MODEL X ID No. Version No. Page No. From 2016 — 2021 TESLA–202012–002 01 01/04 1. Identification / recognition WARNING LACK OF ENGINE NOISE DOES NOT MEAN VEHICLE IS OFF. SILENT MOVEMENT OR INSTANT RESTART CAPABILITY EXISTS UNTIL VEHICLE IS FULLY SHUT DOWN. WEAR APPROPRIATE PERSONAL PROTECTIVE EQUIPMENT (PPE). NOTE: The Tesla emblem indicates a fully electric vehicle. NOTE: The model name is located on the rear of the vehicle. 2. Immobilization / stabilization / lifting IMMOBILIZATION STABILIZATION/ LIFTING POINTS 1. CHOCK WHEELS 2. PUT VEHICLE INTO PARK POSITION Appropriate lift areas PUSH 1x Safe stabilization points for Model X resting on its side High Voltage (HV) Battery 3. Disable direct hazards / safety regulations ACCESS MAIN DISABLE METHOD 1. Open the hood (see chapter 4). 1. Double cut the first responder loop. 2. Remove the access panel by pulling it upward 2. Disable the 12V battery. to release the clips that hold it in place. WARNING Not every high voltage component is labeled. Always wear appropriate PPE. Always double cut the first responder loop. Do not attempt to open the High Voltage (HV) battery. -

Nikola Tesla and the Planetary Radio Signals
Adapted from the 5th International Tesla Conference: "Tesla. III Millennium", October 15-19,1996, Belgrade, Yugoslavia. NIKOLA TESLA AND THE PLANETARY RADIO SIGNALS By Kenneth L. Corum* and James F. Corum, Ph.D. © 2003 by K.L. Corum and J.F. Corum "My ear barely caught signals coming in regular succession which could not have been produced on earth . ." Nikola Tesla, 1919 * This brief paper is condensed from the 1996 technical report Nikola Tesla And The Electrical Signals Of Planetary Origin, by K.L. Corum and J.F. Corum (81 pages). That document is available through PV Scientific, (http://www.arcsandsparks.com) TESLA SPEAKS . "We are getting messages from the clouds one hundred miles away, possibly many times that distance. Do not leak it to the reporters."1 Nikola Tesla, 1899 "My measurements and calculations have shown that it is perfectly practicable to produce on our globe, by the use of these principles, an electrical movement of such magnitude that, without the slightest doubt, its effect will be perceptible on some of our nearer planets, as Venus and Mars. Thus, from mere possibility, interplanetary communication has entered the stage of probability."2 Nikola Tesla, 1900 "Movements on instrument repeated many times. Concludes it to be a message from another planet."3 Newspaper Interview, 1901 "I did not state that I had obtained a message from Mars, I only expressed my conviction that the disturbances that I obtained were of planetary origin."4 Nikola Tesla, 1901 "The feeling is constantly growing on me that I had been the first to hear the greetings of one planet to another."5 Nikola Tesla, 1901 "I refer to the strange electrical disturbances, the discovery which I announced six years ago. -

The International System of Units (SI) - Conversion Factors For
NIST Special Publication 1038 The International System of Units (SI) – Conversion Factors for General Use Kenneth Butcher Linda Crown Elizabeth J. Gentry Weights and Measures Division Technology Services NIST Special Publication 1038 The International System of Units (SI) - Conversion Factors for General Use Editors: Kenneth S. Butcher Linda D. Crown Elizabeth J. Gentry Weights and Measures Division Carol Hockert, Chief Weights and Measures Division Technology Services National Institute of Standards and Technology May 2006 U.S. Department of Commerce Carlo M. Gutierrez, Secretary Technology Administration Robert Cresanti, Under Secretary of Commerce for Technology National Institute of Standards and Technology William Jeffrey, Director Certain commercial entities, equipment, or materials may be identified in this document in order to describe an experimental procedure or concept adequately. Such identification is not intended to imply recommendation or endorsement by the National Institute of Standards and Technology, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose. National Institute of Standards and Technology Special Publications 1038 Natl. Inst. Stand. Technol. Spec. Pub. 1038, 24 pages (May 2006) Available through NIST Weights and Measures Division STOP 2600 Gaithersburg, MD 20899-2600 Phone: (301) 975-4004 — Fax: (301) 926-0647 Internet: www.nist.gov/owm or www.nist.gov/metric TABLE OF CONTENTS FOREWORD.................................................................................................................................................................v -

Drag Coefficient
086 . comparo D RAG QUEENS FIVE SLIPPERY CARS ENTER A WIND TUNNEL; ONE SLINKS OUT A WINNER. by DON SHERMAN photography by MARK BRAMLEY 087 LIKE A THIEF IN THE NIGHT, WIND RESISTANCE IS A STEALTHY INTRUDER THAT SAPS YOUR SPEED AND MURDERS YOUR MILEAGE WITHOUT LEAVING FINGERPRINTS. THE GENTLE MURMUR OF AIR STREAMING OVER, UNDER, AND THROUGH YOUR CAR BELIES THE WIND’S HEINOUS WAYS. Even if there’s no alternative to driving through Earth’s atmosphere, we can at least fight wind resistance with science. Aerodynamics—the study of air in motion—can lift our top speeds, curb our fuel consumption, and, if we’re smart about it, keep our tires stuck to the pavement. Long before automotive engineers fretted over aerodynamics, D RAG QUEENS aviation pioneers defined the basic principles of drag and lift. Inspired by birds and airships, early speed demons also toyed with streamlined shapes. The first car to crack 60 mph (in 1899) was an electrically pro- pelled torpedo on wheels called, hilariously, “La Jamais Contente” (“The Never Satisfied”). Grand Prix racers took up the cause in the early 1920s; the following decade, Auto Union and Mercedes-Benz raced toward 300 mph with streamliners developed in German wind tunnels. Half a century after Chuck Yeager broke the sound barrier in flight, Andy Green drove his ThrustSSC a satisfying 763 mph across Nevada’s Black Rock desert. Now it’s our turn. Car and Driver gathered five slippery cars to study their drag and lift properties at a wind tunnel whose name and location we swore not to reveal. -

Nvidia's GPU Microarchitectures
NVidia’s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture - Kepler Architecture - Ma xwe ll Archite cture - Future Advances CPU vs GPU Architectures ● Few Cores ● Hundreds of Cores ● Lots of Cache ● Thousands of Threads ● Handful of Threads ● Single Proce ss Exe cution ● Independent Processes Use s of GPUs Gaming ● Gra phics ● Focuses on High Frames per Second ● Low Polygon Count ● Predefined Textures Workstation ● Computation ● Focuses on Floating Point Precision ● CAD Gra p hics - Billions of Polygons Brief Timeline of NVidia GPUs 1999 - World’s First GPU: GeForce 256 2001 - First Programmable GPU: GeForce3 2004 - Sca la ble Link Inte rfa ce 2006 - CUDA Architecture Announced 2007 - Launch of Tesla Computation GPUs with Tesla Microarchitecture 2009 - Fermi Architecture Introduced 2 0 13 - Kepler Architecture Launched 2 0 16 - Pascal Architecture Tesla - First microarchitecture to implement the unified shader model, which uses the same hardware resources for all fragment processing - Consists of a number of stream processors, which are scalar and can only operate on one component at a time - Increased clock speed in GPUs - Round robin scheduling for warps - Contained local, shared, and global memory - Conta ins Spe cia l-Function Units which are specialized for interpolating points - Allowed for two instructions to execute per clock cycle per SP Fermi Peak Performance Overview: ● Each SM has 32 -

Solid State Tesla Coils and Their Uses
Solid State Tesla Coils and Their Uses Sean Soleyman Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-265 http://www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-265.html December 14, 2012 Copyright © 2012, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. Solid State Tesla Coils and Their Uses by Sean Soleyman Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California at Berkeley, in partial satisfaction of the requirements for the degree of Master of Science, Plan II. Approval for the Report and Comprehensive Examination: Committee: Jaijeet Roychowdhury Research Advisor 2012/12/13 (Date) Michael Lustig ,tG/t; (Date) Abstract – The solid state Tesla coil is a recently- discovered high voltage power supply. It has similarities to both the traditional Tesla coil and to the modern switched-mode flyback converter. This report will document the design, operation, and construction of such a system. Possible industrial applications for the device will also be considered. I. INTRODUCTION – THE TESLA COIL For reasons that will be discussed later, the traditional Tesla coil now has very few practical Around 1891, Nikola Tesla designed a system uses other than the production of sparks and special consisting of two coupled resonant circuits.