6.3 Treemaps: a Space-Filling Approach to the Visualization of Hierarchical Information Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Balanced Trees Part One
Balanced Trees Part One Balanced Trees ● Balanced search trees are among the most useful and versatile data structures. ● Many programming languages ship with a balanced tree library. ● C++: std::map / std::set ● Java: TreeMap / TreeSet ● Many advanced data structures are layered on top of balanced trees. ● We’ll see several later in the quarter! Where We're Going ● B-Trees (Today) ● A simple type of balanced tree developed for block storage. ● Red/Black Trees (Today/Thursday) ● The canonical balanced binary search tree. ● Augmented Search Trees (Thursday) ● Adding extra information to balanced trees to supercharge the data structure. Outline for Today ● BST Review ● Refresher on basic BST concepts and runtimes. ● Overview of Red/Black Trees ● What we're building toward. ● B-Trees and 2-3-4 Trees ● Simple balanced trees, in depth. ● Intuiting Red/Black Trees ● A much better feel for red/black trees. A Quick BST Review Binary Search Trees ● A binary search tree is a binary tree with 9 the following properties: 5 13 ● Each node in the BST stores a key, and 1 6 10 14 optionally, some auxiliary information. 3 7 11 15 ● The key of every node in a BST is strictly greater than all keys 2 4 8 12 to its left and strictly smaller than all keys to its right. Binary Search Trees ● The height of a binary search tree is the 9 length of the longest path from the root to a 5 13 leaf, measured in the number of edges. 1 6 10 14 ● A tree with one node has height 0. -

Trees: Binary Search Trees
COMP2012H Spring 2014 Dekai Wu Binary Trees & Binary Search Trees (data structures for the dictionary ADT) Outline } Binary tree terminology } Tree traversals: preorder, inorder and postorder } Dictionary and binary search tree } Binary search tree operations } Search } min and max } Successor } Insertion } Deletion } Tree balancing issue COMP2012H (BST) Binary Tree Terminology } Go to the supplementary notes COMP2012H (BST) Linked Representation of Binary Trees } The degree of a node is the number of children it has. The degree of a tree is the maximum of its element degree. } In a binary tree, the tree degree is two data } Each node has two links left right } one to the left child of the node } one to the right child of the node Left child Right child } if no child node exists for a node, the link is set to NULL root 32 32 79 42 79 42 / 13 95 16 13 95 16 / / / / / / COMP2012H (BST) Binary Trees as Recursive Data Structures } A binary tree is either empty … Anchor or } Consists of a node called the root } Root points to two disjoint binary (sub)trees Inductive step left and right (sub)tree r left right subtree subtree COMP2012H (BST) Tree Traversal is Also Recursive (Preorder example) If the binary tree is empty then Anchor do nothing Else N: Visit the root, process data L: Traverse the left subtree Inductive/Recursive step R: Traverse the right subtree COMP2012H (BST) 3 Types of Tree Traversal } If the pointer to the node is not NULL: } Preorder: Node, Left subtree, Right subtree } Inorder: Left subtree, Node, Right subtree Inductive/Recursive step } Postorder: Left subtree, Right subtree, Node template <class T> void BinaryTree<T>::InOrder( void(*Visit)(BinaryTreeNode<T> *u), template<class T> BinaryTreeNode<T> *t) void BinaryTree<T>::PreOrder( {// Inorder traversal. -

Q-Tree: a Multi-Attribute Based Range Query Solution for Tele-Immersive Framework
Q-Tree: A Multi-Attribute Based Range Query Solution for Tele-Immersive Framework Md Ahsan Arefin, Md Yusuf Sarwar Uddin, Indranil Gupta, Klara Nahrstedt Department of Computer Science University of Illinois at Urbana Champaign Illinois, USA {marefin2, mduddin2, indy, klara}@illinois.edu Abstract given in a high level description which are transformed into multi-attribute composite range queries. Some of the Users and administrators of large distributed systems are examples include “which site is highly congested?”, “which frequently in need of monitoring and management of its components are not working properly?” etc. To answer the various components, data items and resources. Though there first one, the query is transformed into a multi-attribute exist several distributed query and aggregation systems, the composite range query with constrains (range of values) on clustered structure of tele-immersive interactive frameworks CPU utilization, memory overhead, stream rate, bandwidth and their time-sensitive nature and application requirements utilization, delay and packet loss rate. The later one can represent a new class of systems which poses different chal- be answered by constructing a multi-attribute range query lenges on this distributed search. Multi-attribute composite with constrains on static and dynamic characteristics of range queries are one of the key features in this class. those components. Queries can also be made by defining Queries are given in high level descriptions and then trans- different multi-attribute ranges explicitly. Another mention- formed into multi-attribute composite range queries. Design- able property of such systems is that the number of site is ing such a query engine with minimum traffic overhead, low limited due to limited display space and limited interactions, service latency, and with static and dynamic nature of large but the number of data items to store and manage can datasets, is a challenging task. -
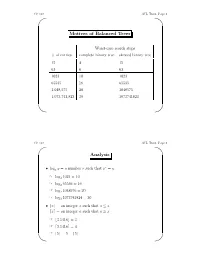
AVL Trees, Page 1 ' $
CS 310 AVL Trees, Page 1 ' $ Motives of Balanced Trees Worst-case search steps #ofentries complete binary tree skewed binary tree 15 4 15 63 6 63 1023 10 1023 65535 16 65535 1,048,575 20 1048575 1,073,741,823 30 1073741823 & % CS 310 AVL Trees, Page 2 ' $ Analysis r • logx y =anumberr such that x = y ☞ log2 1024 = 10 ☞ log2 65536 = 16 ☞ log2 1048576 = 20 ☞ log2 1073741824 = 30 •bxc = an integer a such that a ≤ x dxe = an integer a such that a ≥ x ☞ b3.1416c =3 ☞ d3.1416e =4 ☞ b5c =5=d5e & % CS 310 AVL Trees, Page 3 ' $ • If a binary search tree of N nodes happens to be complete, then a search in the tree requires at most b c log2 N +1 steps. • Big-O notation: We say f(x)=O(g(x)) if f(x)isbounded by c · g(x), where c is a constant, for sufficiently large x. ☞ x2 +11x − 30 = O(x2) (consider c =2,x ≥ 6) ☞ x100 + x50 +2x = O(2x) • If a BST happens to be complete, then a search in the tree requires O(log2 N)steps. • In a linked list of N nodes, a search requires O(N)steps. & % CS 310 AVL Trees, Page 4 ' $ AVL Trees • A balanced binary search tree structure proposed by Adelson, Velksii and Landis in 1962. • In an AVL tree of N nodes, every searching, deletion or insertion operation requires only O(log2 N)steps. • AVL tree searching is exactly the same as that of the binary search tree. & % CS 310 AVL Trees, Page 5 ' $ Definition • An empty tree is balanced. -

7. Hierarchies & Trees Visualizing Topological Relations
7. Hierarchies & Trees Visualizing topological relations Vorlesung „Informationsvisualisierung” Prof. Dr. Andreas Butz, WS 2011/12 Konzept und Basis für Folien: Thorsten Büring LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 1 Outline • Hierarchical data and tree representations • 2D Node-link diagrams – Hyperbolic Tree Browser – SpaceTree – Cheops – Degree of interest tree – 3D Node-link diagrams • Enclosure – Treemap – Ordererd Treemaps – Various examples – Voronoi treemap – 3D Treemaps • Circular visualizations • Space-filling node-link diagram LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 2 Hierarchical Data • Card et al. 1999: data repository in which data cases are related to subcases • Many data collections have an inherent hierarchical organization – Organizational Charts – Websites (approximately hierarchical) Yee et al. 2001 – File system – Family tree – OO programming • Hierarchies are usually represented as tree visual structures • Trees tend to be easier to lay out and interpret than networks (e.g. no cycles) • But: as shown in the example, networks may in some cases be visualized as a tree LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 3 Tree Representations • Two kinds of representations • Node-link diagram (see previous lecture): represent connections as edges between vertices (data cases) http://www.icann.org • Enclosure: space-filling approaches by visually nesting the hierarchy LMU -

CSE 326: Data Structures B-Trees and B+ Trees
Announcements (4/30/08) • Midterm on Friday CSE 326: Data Structures • Special office hour: 4:30-5:30 Thursday in Jaech B-Trees and B+ Trees Gallery (6th floor of CSE building) – This is instead of my usual 11am office hour. Brian Curless • Reading for this lecture: Weiss Sec. 4.7 Spring 2008 2 Traversing very large datasets Memory considerations Suppose we had very many pieces of data (as in a What is in a tree node? In an object? database), e.g., n = 230 ≈ 109. Node: How many (worst case) hops through the tree to find a Object obj; node? Node left; Node right; •BST Node parent; Object: Key key; • AVL …data… Suppose the data is 1KB. How much space does the tree take? •Splay How much of the data can live in 1GB of RAM? 3 4 Cycles to access: CPU Minimizing random disk access Registers 1 In our example, almost all of our data structure is on L1 Cache 2 disk. L2 Cache 30 Thus, hopping through a tree amounts to random accesses to disk. Ouch! Main memory 250 How can we address this problem? Disk Random: 30,000,000 Streamed: 5000 5 6 M-ary Search Tree B-Trees Suppose, somehow, we devised a search tree with How do we make an M-ary search tree work? maximum branching factor M: • Each node has (up to) M-1 keys. •Order property: – subtree between two keys x and y 3 7 12 21 contain leaves with values v such that x < v < y Complete tree has height: # hops for find: x<3 3<x<7 7<x<12 12<x<21 21<x Runtime of find: 7 8 B-Tree Structure Properties B-Tree: Example Root (special case) B-Tree with M = 4 – has between 2 and M children (or root could be a -

Generic Red-Black Tree and Its C# Implementation
JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering ©JOT, 2005 Vol. 4, No. 2, March-April 2005 Generic Red-Black Tree and its C# Implementation Dr. Richard Wiener, Editor-in-Chief, JOT, Associate Professor of Computer Science, University of Colorado at Colorado Springs The focus of this installment of the Educator’s Corner is on tree construction – red-black trees. Some of the material for this column is taken from Chapter 13 of the forthcoming book “Modern Software Development Using C#/.NET” by Richard Wiener. This book will be published by Thomson, Course Technology in the Fall, 2005. A fascinating and important balanced binary search tree is the red-black tree. Rudolf Bayer invented this important tree structure in 1972, about 10 years after the introduction of AVL trees. He is also credited with the invention of the B-tree, a structure used extensively in database systems. Bayer referred to his red-black trees as “symmetric binary B-trees.” Red-black trees, as they are now known, like AVL trees, are “self-balancing”. Whenever a new object is inserted or deleted, the resulting tree continues to satisfy the conditions required to be a red-black tree. The computational complexity for insertion or deletion can be shown to be O(log2n), similar to an AVL tree. Red black trees are important in practice. They are used as the basis for Java’s implementation of its standard SortedSet collection class. There is no comparable collection in the C# standard collections so a C# implementation of red-black trees might be useful. -

Concept Mapping, Mind Mapping and Argument Mapping: What Are the Differences and Do They Matter?
Concept Mapping, Mind Mapping and Argument Mapping: What are the Differences and Do They Matter? W. Martin Davies The University of Melbourne, Australia [email protected] Abstract: In recent years, academics and educators have begun to use software mapping tools for a number of education-related purposes. Typically, the tools are used to help impart critical and analytical skills to students, to enable students to see relationships between concepts, and also as a method of assessment. The common feature of all these tools is the use of diagrammatic relationships of various kinds in preference to written or verbal descriptions. Pictures and structured diagrams are thought to be more comprehensible than just words, and a clearer way to illustrate understanding of complex topics. Variants of these tools are available under different names: “concept mapping”, “mind mapping” and “argument mapping”. Sometimes these terms are used synonymously. However, as this paper will demonstrate, there are clear differences in each of these mapping tools. This paper offers an outline of the various types of tool available and their advantages and disadvantages. It argues that the choice of mapping tool largely depends on the purpose or aim for which the tool is used and that the tools may well be converging to offer educators as yet unrealised and potentially complementary functions. Keywords: Concept mapping, mind mapping, computer-aided argument mapping, critical thinking, argument, inference-making, knowledge mapping. 1. INTRODUCTION The era of computer-aided mapping tools is well and truly here. In the past five to ten years, a variety of software packages have been developed that enable the visual display of information, concepts and relations between ideas. -

Paradigm Shift in How People Interact with Media
THE PARSONS INSTITUTE 68 Fifth Avenue 212 229 6825 FOR INFORMATION MAPPING New York, NY 10011 piim.newschool.edu Paradigm Shift in How People Interact with Media MI-SUN KIM, BFA KEYWORDS Data visualization, information graphics, interactive media, news graphics, reader participation URL http://infographics.chosun.com/ ABSTRACT Today’s newsreaders seek to effectively extract accurate and trustworthy information from the over- whelming flood of available media. Various mass media organizations have contributed considerable effort to meet Figure 1: InfoGraphics, Chosun.com: three aspects of these readers’ expectations. Such effort has also created media are composed together, these include information, a uniquely competitive marketing endeavor to find new graphics, and news. methods of presentation. After over two years of thorough preparations and strategic trials focused on meeting read- Presenting news content through information graphics ers’ needs, Chosun.com officially launched InfoGraphics to enhances the storytelling process, however, our objective provide highly compelling presentations of news through is to go beyond this to present more highly sophisticated the paradigm of information visualization (Figure 1). news content. Creating quality information graphics Chosun.com is one of the leading news websites in South requires a more thorough analyses and reconstruction of Korea; it is affiliated with The Chosun Ilbo (Korea Daily content. The process entails the comprehensive collection News), the largest and most read newspaper in South of the core information, as well as its contextual informa- Korea (Figure 2, next page). tion and related social issues. Therefore, when we present The term InfoGraphics, as used by Chosun.com, seeks our information graphics, we need to synchronize the core to combine the following three media aspects: informa- information with rich contextual issues. -

R-Trees: Introduction
1. Introduction The paper entitled “The ubiquitous B-tree” by Comer was published in ACM Computing Surveys in 1979 [49]. Actually, the keyword “B-tree” was standing as a generic term for a whole family of variations, namely the B∗-tree, the B+-tree and several other variants [111]. The title of the paper might have seemed provocative at that time. However, it represented a big truth, which is still valid now, because all textbooks on databases or data structures devote a considerable number of pages to explain definitions, characteristics, and basic procedures for searches, inserts, and deletes on B-trees. Moreover, B+-trees are not just a theoretical notion. On the contrary, for years they have been the de facto standard access method in all prototype and commercial relational systems for typical transaction processing applications, although one could observe that some quite more elegant and efficient structures have appeared in the literature. The 1980s were a period of wide acceptance of relational systems in the market, but at the same time it became apparent that the relational model was not adequate to host new emerging applications. Multimedia, CAD/CAM, geo- graphical, medical and scientific applications are just some examples, in which the relational model had been proven to behave poorly. Thus, the object- oriented model and the object-relational model were proposed in the sequel. One of the reasons for the shortcoming of the relational systems was their inability to handle the new kinds of data with B-trees. More specifically, B- trees were designed to handle alphanumeric (i.e., one-dimensional) data, like integers, characters, and strings, where an ordering relation can be defined. -

Tile-Based Methods for Online Choropleth Mapping: a Scalability Evaluation by Myung-Hwa Hwang
Tile-based Methods for Online Choropleth Mapping: A Scalability Evaluation by Myung-Hwa Hwang A Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy Approved September 2013 by the Graduate Supervisory Committee: Luc Anselin, Chair Sergio J. Rey Elizabeth A. Wentz ARIZONA STATE UNIVERSITY December 2013 ABSTRACT Choropleth maps are a common form of online cartographic visualization. They reveal patterns in spatial distributions of a variable by associating colors with data values measured at areal units. Although this capability of pattern revelation has popularized the use of choropleth maps, existing methods for their online delivery are limited in supporting dynamic map generation from large areal data. This limitation has become increasingly problematic in online choropleth mapping as access to small area statistics, such as high- resolution census data and real-time aggregates of geospatial data streams, has never been easier due to advances in geospatial web technologies. The current literature shows that the challenge of large areal data can be mitigated through tiled maps where pre-processed map data are hierarchically partitioned into tiny rectangular images or map chunks for ef- ficient data transmission. Various approaches have emerged lately to enable this tile-based choropleth mapping, yet little empirical evidence exists on their ability to handle spatial data with large numbers of areal units, thus complicating technical decision making in the development of online choropleth mapping applications. To fill this knowledge gap, this dissertation study conducts a scalability evaluation of three tile-based methods discussed in the literature: raster, scalable vector graphics (SVG), and HTML5 Canvas. -

A Symphony of Flavours: Using the Device Tree to Describe Embedded Hardware
A Symphony of Flavours: Using the device tree to describe embedded hardware Grant Likely Josh Boyer Secret Lab IBM [email protected] [email protected] Abstract The embedded world is different. Systems vary wildly, and since the software is customized for the system, As part of the merger of 32-bit and 64-bit PowerPC sup- there isn’t the same market pressure to standardize port in the kernel, the decision was to also standardize firmware interfaces. You can see this reflected in the the firmware interface by using an OpenFirmware-style boot schemes used by embedded Linux. Often the op- device tree for all PowerPC platforms; server, desktop, erating system is compiled for a specific board (plat- and embedded. Up to this point, most PowerPC em- form) with the boot loader providing minimal informa- bedded systems were using an inflexible and fragile, tion about the hardware layout, and the platform initial- board-specific data structure to pass data between the ization code is hard coded with the system configura- boot loader and the kernel. The move to using a device tion. tree is expected to simplify and generalize the PowerPC boot sequence. Similarly, data that is provided by the boot firmware is This paper discusses the implications of using a device often laid out in an ad-hoc manner specific to the board tree in the context of embedded systems. We’ll cover port. The old embedded PowerPC support in the ker- the current state of device tree support in arch/powerpc, nel (found in the arch/ppc subdirectory) uses a par- and both the advantages and disadvantages for embed- ticularly bad method for transferring data between the ded system support.