AN5125, Introduction to Device Trees
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Device Tree 101
Device Tree 101 Device Tree 101 Organized in partnership with ST February 9, 2021 Thomas Petazzoni embedded Linux and kernel engineering [email protected] © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Corrections, suggestions, contributions and translations are welcome! - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/56 Who is speaking ? I Thomas Petazzoni I Chief Technical Officer at Bootlin I Joined in 2008, employee #1 I Embedded Linux & Linux kernel engineer, open-source contributor I Author of the Device Tree for Dummies talk in 2013/2014 I Buildroot co-maintainer I Linux kernel contributor: ≈ 900 contributions I Member of Embedded Linux Conference (Europe) program committee I Based in Toulouse, France - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/56 Agenda I Bootlin introduction I STM32MP1 introduction I Why the Device Tree ? I Basic Device Tree syntax I Device Tree inheritance I Device Tree specifications and bindings I Device Tree and Linux kernel drivers I Common properties and examples - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/56 Bootlin I In business since 2004 I Team based in France I Serving customers worldwide I 18% revenue from France I 44% revenue from EU except France I 38% revenue outside EU I Highly focused and recognized expertise I Embedded Linux I Linux kernel I Embedded Linux build systems I Activities -

Balanced Trees Part One
Balanced Trees Part One Balanced Trees ● Balanced search trees are among the most useful and versatile data structures. ● Many programming languages ship with a balanced tree library. ● C++: std::map / std::set ● Java: TreeMap / TreeSet ● Many advanced data structures are layered on top of balanced trees. ● We’ll see several later in the quarter! Where We're Going ● B-Trees (Today) ● A simple type of balanced tree developed for block storage. ● Red/Black Trees (Today/Thursday) ● The canonical balanced binary search tree. ● Augmented Search Trees (Thursday) ● Adding extra information to balanced trees to supercharge the data structure. Outline for Today ● BST Review ● Refresher on basic BST concepts and runtimes. ● Overview of Red/Black Trees ● What we're building toward. ● B-Trees and 2-3-4 Trees ● Simple balanced trees, in depth. ● Intuiting Red/Black Trees ● A much better feel for red/black trees. A Quick BST Review Binary Search Trees ● A binary search tree is a binary tree with 9 the following properties: 5 13 ● Each node in the BST stores a key, and 1 6 10 14 optionally, some auxiliary information. 3 7 11 15 ● The key of every node in a BST is strictly greater than all keys 2 4 8 12 to its left and strictly smaller than all keys to its right. Binary Search Trees ● The height of a binary search tree is the 9 length of the longest path from the root to a 5 13 leaf, measured in the number of edges. 1 6 10 14 ● A tree with one node has height 0. -

Trees: Binary Search Trees
COMP2012H Spring 2014 Dekai Wu Binary Trees & Binary Search Trees (data structures for the dictionary ADT) Outline } Binary tree terminology } Tree traversals: preorder, inorder and postorder } Dictionary and binary search tree } Binary search tree operations } Search } min and max } Successor } Insertion } Deletion } Tree balancing issue COMP2012H (BST) Binary Tree Terminology } Go to the supplementary notes COMP2012H (BST) Linked Representation of Binary Trees } The degree of a node is the number of children it has. The degree of a tree is the maximum of its element degree. } In a binary tree, the tree degree is two data } Each node has two links left right } one to the left child of the node } one to the right child of the node Left child Right child } if no child node exists for a node, the link is set to NULL root 32 32 79 42 79 42 / 13 95 16 13 95 16 / / / / / / COMP2012H (BST) Binary Trees as Recursive Data Structures } A binary tree is either empty … Anchor or } Consists of a node called the root } Root points to two disjoint binary (sub)trees Inductive step left and right (sub)tree r left right subtree subtree COMP2012H (BST) Tree Traversal is Also Recursive (Preorder example) If the binary tree is empty then Anchor do nothing Else N: Visit the root, process data L: Traverse the left subtree Inductive/Recursive step R: Traverse the right subtree COMP2012H (BST) 3 Types of Tree Traversal } If the pointer to the node is not NULL: } Preorder: Node, Left subtree, Right subtree } Inorder: Left subtree, Node, Right subtree Inductive/Recursive step } Postorder: Left subtree, Right subtree, Node template <class T> void BinaryTree<T>::InOrder( void(*Visit)(BinaryTreeNode<T> *u), template<class T> BinaryTreeNode<T> *t) void BinaryTree<T>::PreOrder( {// Inorder traversal. -

Devicetree BOF
Devicetree BOF Open Source Summit Japan 2018 Tokyo Frank Rowand, Sony June 20, 2018 180618_0351 My Goal Do NOT show all of the slides Agenda - Past events - Future events - New since elc 2017 (February 2017) - Tools status - dtc compiler - questions, comments, issues, concerns from the crowd - commit statistics Plumbers 2017 Summary September 2017 Los Angeles Was not scheduled -- not enough interest / commitment Devicetree Workshop Oct 2017 Prague, Czech Republic https://elinux.org/Device_tree_future #Kernel_Summit_2017.2C_Devicetree_Workshop - slides - notes === Validation Tools & Schema === Runtime usage === DTS maintenance issues === More stuff Devicetree Workshop Oct 2017 Prague, Czech Republic Devicetree Workshop 2017 9:30 Welcome and Schedule bashing 9:40 Encoding and Schema checking: Framing the problem 9:45 DT YAML encoding overview 10:00 YAML encoding discussion 10:20 DT Schema format - option 1 10:35 DT Schema format - option 2 10:50 DT Schema discussion - what should go in the spec? 11:50 Code Generation from DT 12:10 Runtime memory consumption 14:30 Overlay maintenance plan 14:45 Avoiding duplicate descriptions 15:00 Criteria for accepting board files 15:15 Location for maintaining bindings - how to handle foreign bindings 15:30 Sharing Generic bindings 15:45 ABI Stability 16:00 [break and overflow discussion] 16:30 DT health check 16:50 devicetree.org update 17:05 EBBR Discussion 17:20 Closing and feedback Plumbers 2018 November 13 - 15, 2018 Tuesday - Thursday Vancouver, British Columbia, Canada https://www.linuxplumbersconf.org/event/2/overview -

Q-Tree: a Multi-Attribute Based Range Query Solution for Tele-Immersive Framework
Q-Tree: A Multi-Attribute Based Range Query Solution for Tele-Immersive Framework Md Ahsan Arefin, Md Yusuf Sarwar Uddin, Indranil Gupta, Klara Nahrstedt Department of Computer Science University of Illinois at Urbana Champaign Illinois, USA {marefin2, mduddin2, indy, klara}@illinois.edu Abstract given in a high level description which are transformed into multi-attribute composite range queries. Some of the Users and administrators of large distributed systems are examples include “which site is highly congested?”, “which frequently in need of monitoring and management of its components are not working properly?” etc. To answer the various components, data items and resources. Though there first one, the query is transformed into a multi-attribute exist several distributed query and aggregation systems, the composite range query with constrains (range of values) on clustered structure of tele-immersive interactive frameworks CPU utilization, memory overhead, stream rate, bandwidth and their time-sensitive nature and application requirements utilization, delay and packet loss rate. The later one can represent a new class of systems which poses different chal- be answered by constructing a multi-attribute range query lenges on this distributed search. Multi-attribute composite with constrains on static and dynamic characteristics of range queries are one of the key features in this class. those components. Queries can also be made by defining Queries are given in high level descriptions and then trans- different multi-attribute ranges explicitly. Another mention- formed into multi-attribute composite range queries. Design- able property of such systems is that the number of site is ing such a query engine with minimum traffic overhead, low limited due to limited display space and limited interactions, service latency, and with static and dynamic nature of large but the number of data items to store and manage can datasets, is a challenging task. -

Introduction to Linux Kernel Driver Programming
IntroductionIntroduction toto LinuxLinux kernelkernel driverdriver programmingprogramming Introduction to Linux kernel driver programming The Linux kernel device model Authors and license ● Authors – Michael Opdenacker ([email protected]) Founder of Bootlin, kernel and embedded Linux engineering company https://bootlin.com/company/staff/michael-opdenacker ● License – Creative Commons Attribution – Share Alike 4.0 https://creativecommons.org/licenses/by-sa/4.0/ – Document sources: https://github.com/e-ale/Slides Need for a device model ● For the same device, need to use the same device driver on multiple CPU architectures (x86, ARM…), even though the hardware controllers are different. ● Need for a single driver to support multiple devices of the same kind. ● This requires a clean organization of the code, with the device drivers separated from the controller drivers, the hardware description separated from the drivers themselves, etc. Driver: between bus infrastructure and framework In Linux, a driver is always interfacing with: ● a framework that allows the driver to expose the hardware features in a generic way. ● a bus infrastructure, part of the device model, to detect/communicate with the hardware. Let’s focus on the bus infrastructure for now Device model data structures The device model is organized around three main data structures: ● The struct bus_type structure, which represent one type of bus (USB, PCI, I2C, etc.) ● The struct device_driver structure, which represents one driver capable of handling certain devices on a certain bus. ● The struct device structure, which represents one device connected to a bus The kernel uses inheritance to create more specialized versions of struct device_driver and struct device for each bus subsystem. -

Kernel Boot-Time Tracing
Kernel Boot-time Tracing Linux Plumbers Conference 2019 - Tracing Track Masami Hiramatsu <[email protected]> Linaro, Ltd. Speaker Masami Hiramatsu - Working for Linaro and Linaro members - Tech Lead for a Landing team - Maintainer of Kprobes and related tracing features/tools Why Kernel Boot-time Tracing? Debug and analyze boot time errors and performance issues - Measure performance statistics of kernel boot - Analyze driver init failure - Debug boot up process - Continuously tracing from boot time etc. What We Have There are already many ftrace options on kernel command line ● Setup options (trace_options=) ● Output to printk (tp_printk) ● Enable events (trace_events=) ● Enable tracers (ftrace=) ● Filtering (ftrace_filter=,ftrace_notrace=,ftrace_graph_filter=,ftrace_graph_notrace=) ● Add kprobe events (kprobe_events=) ● And other options (alloc_snapshot, traceoff_on_warning, ...) See Documentation/admin-guide/kernel-parameters.txt Example of Kernel Cmdline Parameters In grub.conf linux /boot/vmlinuz-5.1 root=UUID=5a026bbb-6a58-4c23-9814-5b1c99b82338 ro quiet splash tp_printk trace_options=”sym-addr” trace_clock=global ftrace_dump_on_oops trace_buf_size=1M trace_event=”initcall:*,irq:*,exceptions:*” kprobe_event=”p:kprobes/myevent foofunction $arg1 $arg2;p:kprobes/myevent2 barfunction %ax” What Issues? Size limitation ● kernel cmdline size is small (< 256bytes) ● A half of the cmdline is used for normal boot Only partial features supported ● ftrace has too complex features for single command line ● per-event filters/actions, instances, histograms. Solutions? 1. Use initramfs - Too late for kernel boot time tracing 2. Expand kernel cmdline - It is not easy to write down complex tracing options on bootloader (Single line options is too simple) 3. Reuse structured boot time data (Devicetree) - Well documented, structured data -> V1 & V2 series based on this. Boot-time Trace: V1 and V2 series V1 and V2 series posted at June. -

Devicetree Specification
Devicetree Specification Release unknown-rev devicetree.org unknown-rev 13 September 2021 Contents 1 Introduction 3 1.1 Purpose and Scope..............................................3 1.2 Relationship to IEEE™ 1275 and ePAPR..................................4 1.3 32-bit and 64-bit Support...........................................4 1.4 Definition of Terms..............................................4 2 The Devicetree 6 2.1 Overview...................................................6 2.2 Devicetree Structure and Conventions....................................7 2.2.1 Node Names............................................7 2.2.2 Generic Names Recommendation.................................8 2.2.3 Path Names............................................. 10 2.2.4 Properties.............................................. 10 2.3 Standard Properties.............................................. 12 2.3.1 compatible............................................. 12 2.3.2 model................................................ 13 2.3.3 phandle............................................... 13 2.3.4 status................................................ 14 2.3.5 #address-cells and #size-cells.................................... 14 2.3.6 reg.................................................. 15 2.3.7 virtual-reg.............................................. 15 2.3.8 ranges................................................ 15 2.3.9 dma-ranges.............................................unknown-rev 16 2.3.10 dma-coherent........................................... -
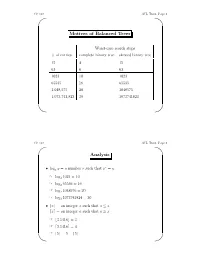
AVL Trees, Page 1 ' $
CS 310 AVL Trees, Page 1 ' $ Motives of Balanced Trees Worst-case search steps #ofentries complete binary tree skewed binary tree 15 4 15 63 6 63 1023 10 1023 65535 16 65535 1,048,575 20 1048575 1,073,741,823 30 1073741823 & % CS 310 AVL Trees, Page 2 ' $ Analysis r • logx y =anumberr such that x = y ☞ log2 1024 = 10 ☞ log2 65536 = 16 ☞ log2 1048576 = 20 ☞ log2 1073741824 = 30 •bxc = an integer a such that a ≤ x dxe = an integer a such that a ≥ x ☞ b3.1416c =3 ☞ d3.1416e =4 ☞ b5c =5=d5e & % CS 310 AVL Trees, Page 3 ' $ • If a binary search tree of N nodes happens to be complete, then a search in the tree requires at most b c log2 N +1 steps. • Big-O notation: We say f(x)=O(g(x)) if f(x)isbounded by c · g(x), where c is a constant, for sufficiently large x. ☞ x2 +11x − 30 = O(x2) (consider c =2,x ≥ 6) ☞ x100 + x50 +2x = O(2x) • If a BST happens to be complete, then a search in the tree requires O(log2 N)steps. • In a linked list of N nodes, a search requires O(N)steps. & % CS 310 AVL Trees, Page 4 ' $ AVL Trees • A balanced binary search tree structure proposed by Adelson, Velksii and Landis in 1962. • In an AVL tree of N nodes, every searching, deletion or insertion operation requires only O(log2 N)steps. • AVL tree searching is exactly the same as that of the binary search tree. & % CS 310 AVL Trees, Page 5 ' $ Definition • An empty tree is balanced. -

7. Hierarchies & Trees Visualizing Topological Relations
7. Hierarchies & Trees Visualizing topological relations Vorlesung „Informationsvisualisierung” Prof. Dr. Andreas Butz, WS 2011/12 Konzept und Basis für Folien: Thorsten Büring LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 1 Outline • Hierarchical data and tree representations • 2D Node-link diagrams – Hyperbolic Tree Browser – SpaceTree – Cheops – Degree of interest tree – 3D Node-link diagrams • Enclosure – Treemap – Ordererd Treemaps – Various examples – Voronoi treemap – 3D Treemaps • Circular visualizations • Space-filling node-link diagram LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 2 Hierarchical Data • Card et al. 1999: data repository in which data cases are related to subcases • Many data collections have an inherent hierarchical organization – Organizational Charts – Websites (approximately hierarchical) Yee et al. 2001 – File system – Family tree – OO programming • Hierarchies are usually represented as tree visual structures • Trees tend to be easier to lay out and interpret than networks (e.g. no cycles) • But: as shown in the example, networks may in some cases be visualized as a tree LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 3 Tree Representations • Two kinds of representations • Node-link diagram (see previous lecture): represent connections as edges between vertices (data cases) http://www.icann.org • Enclosure: space-filling approaches by visually nesting the hierarchy LMU -

Device Tree the Disaster So Far
Device Tree The Disaster so Far Mark Rutland <[email protected]> ELC Europe 2013 Agenda Disaster is a strong word. Let's talk about: I What was wrong with board files I What device tree is (and what it isn't) I The ARM conversion so far I The problems we have, and how to fix them I What we need to do in future Where we came from Two big problems: I Hard-coded board description I Kernel must know every possible configuration I Minor revisions require a new kernel I Separate kernels per platform I Uncoordinated { \stepping on each others toes" I Difficult to test I Painful for distributions Planned solution: I Single image I Dynamic configuration I Move board description out of the kernel Device Tree { Overview I A data structure for describing hardware I Defined by OpenFirmware (IEEE1275-1994) I Extended by ePAPR & other supplements I Handled by OpenFirmware, U-Boot, ... I Used by *BSD, Linux, OS X, Solaris, Xen I Used on ARC, ARM(64) C6X, META, MicroBlaze, MIPS, OpenRISC, PowerPC, SPARC, x86, Xtensa I Generated by KVM tool, Xen, others Device Tree { Overview I Declarative hardware description I Describes hardware topology I Format not tied to OS internals I Hierarchical key value(-list) I Just a data structure I Conventions, not rigid rules I Bindings I Conventions for describing a particular devices I Typically matched by compatible string I Device classes share common bindings I No central authority I Bindings created by users I No coordination of implementors Device Tree { Bindings Vendor dev2000 bindings ======================= The Vendor dev2000 is a memory-mapped device that may or may not do something useful. -

EXTENDING the LIFECYCLE of IOT DEVICES USING SELECTIVE DEACTIVATION a Dissertation Presented to the Academic Faculty by Michael
EXTENDING THE LIFECYCLE OF IOT DEVICES USING SELECTIVE DEACTIVATION A Dissertation Presented to The Academic Faculty By Michael Hesse In Partial Fulfillment of the Requirements for the Degree Master of Science in the School of Computer Science Georgia Institute of Technology August 2020 Copyright c Michael Hesse 2020 EXTENDING THE LIFECYCLE OF IOT DEVICES USING SELECTIVE DEACTIVATION Approved by: Professor Taesoo Kim, Advisor School of Computer Science Georgia Institute of Technology Professor Brendan Saltaformaggio School of Electrical and Computer Engineering Georgia Institute of Technology Professor Mustaque Ahmad School of Computer Science Georgia Institute of Technology Date Approved: April 29, 2020 ACKNOWLEDGEMENTS I would like to thank my advisor Taesoo Kim and the other members of the committee, Brendan Saltaformaggio and Mustaque Ahmad, for their time, patience and guidance, as this thesis would not have been possible without them. I would further like to thank Meng Xu and Fan San for their continued support and feedback during the course of my research. Ranjani and Sundar, thank you for emotional support and interest in my work. Finally, I would like to thank my parents and my sister for all the love and support they continue to provide throughout my entire life. iii TABLE OF CONTENTS Acknowledgments . iii List of Tables . viii List of Figures . ix Nomenclature . x Chapter 1: Introduction . 1 1.1 Problem Description . 2 1.2 Goal . 2 1.3 Assumptions & Threat Model . 4 1.4 Security Properties . 5 1.5 Challenges . 6 1.6 Thesis Overview . 6 Chapter 2: Background . 8 2.1 Platform Architecture . 8 2.2 Hardware Assisted Security Mechanisms .