Morphology-Rich Alphasyllabary Embeddings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Similarities and Dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: a Comparative Study
Similarities and dissimilarities of English and Arabic 94 Similarities and dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: A Comparative Study MD YEAQUB Research Scholar Aligarh Muslim University, India Email: [email protected] Abstract: This paper will focus on a comparative study about similarities and dissimilarities of the pronunciation between the syllables of English and Arabic with the help of phonetic and phonological tools i.e. manner of articulation, point of articulation and their distribution at different positions in English and Arabic Alphabets. A phonetic and phonological analysis of the alphabets of English and Arabic can be useful in overcoming the hindrances for those want to improve the pronunciation of both English and Arabic languages. We all know that Arabic is a Semitic language from the Afro-Asiatic Language Family. On the other hand, English is a West Germanic language from the Indo- European Language Family. Both languages show many linguistic differences at all levels of linguistic analysis, i.e. phonology, morphology, syntax, semantics, etc. For this we will take into consideration, the segmental features only, i.e. the consonant and vowel system of the two languages. So, this is better and larger to bring about pedagogical changes that can go a long way in improving pronunciation and ensuring the occurrence of desirable learners’ outcomes. Keywords: Arabic Alphabets, English Alphabets, Pronunciations, Phonetics, Phonology, manner of articulation, point of articulation. Introduction: We all know that sounds are generally divided into two i.e. consonants and vowels. A consonant is a speech sound, which obstruct the flow of air through the vocal tract. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -
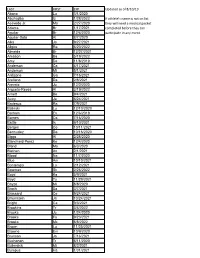
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Arabic Alphabet - Wikipedia, the Free Encyclopedia Arabic Alphabet from Wikipedia, the Free Encyclopedia
2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia Arabic alphabet From Wikipedia, the free encyclopedia َأﺑْ َﺠ ِﺪﯾﱠﺔ َﻋ َﺮﺑِﯿﱠﺔ :The Arabic alphabet (Arabic ’abjadiyyah ‘arabiyyah) or Arabic abjad is Arabic abjad the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[1] stand for consonants, it is classified as an abjad. Type Abjad Languages Arabic Time 400 to the present period Parent Proto-Sinaitic systems Phoenician Aramaic Syriac Nabataean Arabic abjad Child N'Ko alphabet systems ISO 15924 Arab, 160 Direction Right-to-left Unicode Arabic alias Unicode U+0600 to U+06FF range (http://www.unicode.org/charts/PDF/U0600.pdf) U+0750 to U+077F (http://www.unicode.org/charts/PDF/U0750.pdf) U+08A0 to U+08FF (http://www.unicode.org/charts/PDF/U08A0.pdf) U+FB50 to U+FDFF (http://www.unicode.org/charts/PDF/UFB50.pdf) U+FE70 to U+FEFF (http://www.unicode.org/charts/PDF/UFE70.pdf) U+1EE00 to U+1EEFF (http://www.unicode.org/charts/PDF/U1EE00.pdf) Note: This page may contain IPA phonetic symbols. Arabic alphabet ا ب ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع en.wikipedia.org/wiki/Arabic_alphabet 1/20 2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia غ ف ق ك ل م ن ه و ي History · Transliteration ء Diacritics · Hamza Numerals · Numeration V · T · E (//en.wikipedia.org/w/index.php?title=Template:Arabic_alphabet&action=edit) Contents 1 Consonants 1.1 Alphabetical order 1.2 Letter forms 1.2.1 Table of basic letters 1.2.2 Further notes -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Proposal for Ethiopic Script Root Zone LGR
Proposal for Ethiopic Script Root Zone LGR LGR Version 2 Date: 2017-05-17 Document version:5.2 Authors: Ethiopic Script Generation Panel Contents 1 General Information/ Overview/ Abstract ........................................................................................ 3 2 Script for which the LGR is proposed ................................................................................................ 3 3 Background on Script and Principal Languages Using It .................................................................... 4 3.1 Local Languages Using the Script .............................................................................................. 4 3.2 Geographic Territories of the Language or the Language Map of Ethiopia ................................ 7 4 Overall Development Process and Methodology .............................................................................. 8 4.1 Sources Consulted to Determine the Repertoire....................................................................... 8 4.2 Team Composition and Diversity .............................................................................................. 9 4.3 Analysis of Code Point Repertoire .......................................................................................... 10 4.4 Analysis of Code Point Variants .............................................................................................. 11 5 Repertoire .................................................................................................................................... -

Dual Script E2E Framework for Multilingual and Code-Switching ASR
Dual Script E2E Framework for Multilingual and Code-Switching ASR Mari Ganesh Kumar, Jom Kuriakose, Anand Thyagachandran, Arun Kumar A*, Ashish Seth*, Lodagala V S V Durga Prasad*, Saish Jaiswal*, Anusha Prakash, and Hema A Murthy Indian Institute of Technology Madras [email protected] (MGK), [email protected] (JK), [email protected] (AP), [email protected] (HAM) Abstract have different written scripts, they share a common phonetic base. Inspired by this, a common label set for 13 Indian lan- India is home to multiple languages, and training automatic guages was developed for TTS synthesis [6]. In [7], a rule-based speech recognition (ASR) systems is challenging. Over time, unified parser for 13 Indian languages was proposed to convert each language has adopted words from other languages, such grapheme-based Indian language text to phoneme-based CLS. as English, leading to code-mixing. Most Indian languages also CLS has shown to be successful for TTS systems developed us- have their own unique scripts, which poses a major limitation in ing both hidden Markov model (HMM) based approaches [6], training multilingual and code-switching ASR systems. and recent end-to-end frameworks [4, 5]. For training multilin- Inspired by results in text-to-speech synthesis, in this paper, gual ASR systems, recent studies use transliterated text pooled we use an in-house rule-based phoneme-level common label set across various languages [8, 9]. In the context of multilingual (CLS) representation to train multilingual and code-switching ASR systems for Indian languages, [10] used a simple character ASR for Indian languages. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Orthographic Transparency and the Ottoman Abjad Maithili Jais
Orthographic Transparency and the Ottoman Abjad Maithili Jais University of Florida Spring 2018 I. Introduction In 2014, the debate over whether Ottoman Turkish was to be taught in schools or not was once again brought to the forefront of Turkish society and the Turkish conscience, as Erdogan began to push for Ottoman Turkish to be taught in all high schools across the country (Yeginsu, 2014). This became an obsession of a news topic for media in the West as well as in Turkey. Turkey’s tumultuous history with politics inevitably led this proposal of teaching Ottoman Turkish in all high schools to become a hotbed of controversy and debate. For all those who are perfectly contented to let bygones be bygones, there are many who assert that the Ottoman Turkish alphabet is still relevant and important. In fact, though this may be a personal anecdote, there are still certainly people who believe that the Ottoman script is, or was, superior to the Latin alphabet with which modern Turkish is written. This thesis does not aim to undertake a task so grand as sussing out which of the two was more appropriate for Turkish. No, such a task would be a behemoth for this paper. Instead, it aims to answer the question, “How?” Rather, “How was the Arabic script moulded to fit Turkish and to what consequence?” Often the claim that one script it superior to another suggests inherent judgement of value, but of the few claims seen circulating Facebook on the efficacy of the Ottoman script, it seems some believe that it represented Turkish more accurately and efficiently. -

Program Bantu Belajar Bahasa Korea Untuk Pemula Berbasis Multimedia”
PROGRAM BANTU BELAJAR BAHASA KOREA UNTUK PEMULA BERBASIS MULTIMEDIA Tugas Akhir disusun untuk memenuhi syarat mencapai gelar Kesarjanaan Komputer pada program Studi Teknik Informatika Jenjang Program Srata–1 Oleh : NUR ISROATI HIDAYAH 08.01.53.0161 9391 FAKULTAS TEKNOLOGI INFORMASI UNIVERSITAS STIKUBANK (UNISBANK) SEMARANG 2012 HALAMAN PERSETUJUAN PERNYATAAN KESIAPAN UJIAN TUGAS AKHIR Saya, Nur Isroati Hidayah, dengan ini menyatakan bahwa Laporan Tugas Akhir yang berjudul : “PROGRAM BANTU BELAJAR BAHASA KOREA UNTUK PEMULA BERBASIS MULTIMEDIA” Adalah benar hasil saya dan belum pernah diajukan sebagai karya ilmiah, sebagian atau seluruhnya, atas nama saya atau pihak lain. Disetujui oleh Pembimbing Kami setuju Laporan tersebut diajukan untuk Ujian Tugas Akhir Semarang: Juli 2012 Semarang: Juli 2012 ii HALAMAN PENGESAHAN Telah dipertahankan di depan tim dosen penguji Tugas Akhir Fakultas Teknologi Informasi UNIVERSITAS STIKUBANK (UNISBANK) Semarang dan diterima sebagai salah satu syarat guna menyelesaikan Jenjang Program Strata 1, Program Studi: Teknik Informatika. Semarang, 6 Agustus 2012 MENGETAHUI : UNIVERSITAS STIKUBANK (UNISBANK) SEMARANG Fakultas Teknologi Informasi Dekan (Dwi Agus Diartono, S.Kom, M.Kom) iii MOTTO DAN PERSEMBAHAN MOTTO : 1. Sesuatu yang kita peroleh dengan usaha kita sendiri tanpa ada kecurangan pasti hasilnya akan sangat membanggakan dan berguna untuk diri sendiri maupun orang lain. 2. Tidak ada sesuatu yang tidak mungkin selama kita terus berusaha dan berdoa kepada Allah SWT, Insyaallah akan diberi kemudahan untuk mencapainya. SKRIPSI INI AKU PERSEMBAHKAN UNTUK: Ayah dan ibu tercinta serta kedua kakakku yang kusayang dan semua keluarga besarku. Teman – teman Teknik Informatika angkatan 2008 terutama B-1 Dan almamaterku. iv FAKULTAS TEKNOLOGI INFORMASI UNIVERSITAS STIKUBANK (UNISBANK) SEMARANG Program Studi Teknik Informatika Semester Genap Tahun 2012 PROGRAM BANTU BELAJAR BAHASA KOREA UNTUK PEMULA BERBASIS MULTIMEDIA NUR ISROATI HIDAYAH (08.01.53.0161) Abstrak Bahasa merupakan sarana sebuah bangsa untuk berkomunikasi.