Computer Architecture: a Constructive Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison of Parallel and Pipelined CORDIC Algorithm Using RCA and CSA
Comparison of Parallel and Pipelined CORDIC algorithm using RCA and CSA Diego Barragan´ Guerrero Lu´ıs Geraldo P. Meloni FEEC - UNICAMP FEEC - UNICAMP Campinas, Sao˜ Paulo, Brazil, 13083-852 Campinas, Sao˜ Paulo, Brazil, 13083-852 +5519 9308-9952 +5519 9778-1523 [email protected] [email protected] Abstract— This paper presents an implementation of the algorithm has two modes of operation: the rotational mode CORDIC algorithm in digital hardware using two types of (RM) where the vector (xi; yi) is rotated by an angle θ to algebraic adders: Ripple-Carry Adder (RCA) and Carry-Select obtain a new vector (x ; y ), and the vectoring mode (VM) Adder (CSA), both in parallel and pipelined architectures. Anal- N N ysis of time performance and resources utilization was carried in which the algorithm computes the modulus R and phase α out by changing the algorithm number of iterations. These results from the x-axis of the vector (x0; y0). The basic principle of demonstrate the efficiency in operating frequency of the pipelined the algorithm is shown in Figure 1. architecture with respect to the parallel architecture. Also it is shown that the use of CSA reduce the timing processing without significantly increasing the slice use. The code was synthesized us- ing FPGA development tools for the Xilinx Spartan-3E xc3s500e ' ' E N y family. N E N Index Terms— CORDIC, pipelined, parallel, RCA, CSA, y N trigonometrics functions. Rotação Pseudo-rotação R N I. INTRODUCTION E i In Digital Signal Processing with FPGA, trigonometric y i R i functions are used in many signal algorithms, for instance N synchronization and equalization [12]. -

Basics of Logic Design Arithmetic Logic Unit (ALU) Today's Lecture
Basics of Logic Design Arithmetic Logic Unit (ALU) CPS 104 Lecture 9 Today’s Lecture • Homework #3 Assigned Due March 3 • Project Groups assigned & posted to blackboard. • Project Specification is on Web Due April 19 • Building the building blocks… Outline • Review • Digital building blocks • An Arithmetic Logic Unit (ALU) Reading Appendix B, Chapter 3 © Alvin R. Lebeck CPS 104 2 Review: Digital Design • Logic Design, Switching Circuits, Digital Logic Recall: Everything is built from transistors • A transistor is a switch • It is either on or off • On or off can represent True or False Given a bunch of bits (0 or 1)… • Is this instruction a lw or a beq? • What register do I read? • How do I add two numbers? • Need a method to reason about complex expressions © Alvin R. Lebeck CPS 104 3 Review: Boolean Functions • Boolean functions have arguments that take two values ({T,F} or {0,1}) and they return a single or a set of ({T,F} or {0,1}) value(s). • Boolean functions can always be represented by a table called a “Truth Table” • Example: F: {0,1}3 -> {0,1}2 a b c f1f2 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 © Alvin R. Lebeck CPS 104 4 Review: Boolean Functions and Expressions F(A, B, C) = (A * B) + (~A * C) ABCF 0000 0011 0100 0111 1000 1010 1101 1111 © Alvin R. Lebeck CPS 104 5 Review: Boolean Gates • Gates are electronics devices that implement simple Boolean functions Examples a a AND(a,b) OR(a,b) a NOT(a) b b a XOR(a,b) a NAND(a,b) b b a NOR(a,b) a XNOR(a,b) b b © Alvin R. -

Implementation of Carry Tree Adders and Compare with RCA and CSLA
International Journal of Emerging Engineering Research and Technology Volume 4, Issue 1, January 2016, PP 1-11 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Implementation of Carry Tree Adders and Compare with RCA and CSLA 1 2 G. Venkatanaga Kumar , C.H Pushpalatha Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (PG Scholar) Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (Associate Professor) ABSTRACT The binary adder is the critical element in most digital circuit designs including digital signal processors (DSP) and microprocessor data path units. As such, extensive research continues to be focused on improving the power delay performance of the adder. In VLSI implementations, parallel-prefix adders are known to have the best performance. Binary adders are one of the most essential logic elements within a digital system. In addition, binary adders are also helpful in units other than Arithmetic Logic Units (ALU), such as multipliers, dividers and memory addressing. Therefore, binary addition is essential that any improvement in binary addition can result in a performance boost for any computing system and, hence, help improve the performance of the entire system. Parallel-prefix adders (also known as carry-tree adders) are known to have the best performance in VLSI designs. This paper investigates three types of carry-tree adders (the Kogge- Stone, sparse Kogge-Stone, Ladner-Fischer and spanning tree adder) and compares them to the simple Ripple Carry Adder (RCA) and Carry Skip Adder (CSA). In this project Xilinx-ISE tool is used for simulation, logical verification, and further synthesizing. This algorithm is implemented in Xilinx 13.2 version and verified using Spartan 3e kit. -
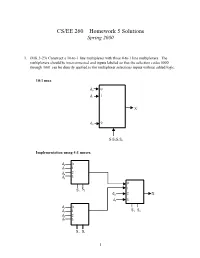
CS/EE 260 – Homework 5 Solutions Spring 2000
CS/EE 260 – Homework 5 Solutions Spring 2000 1. (MK 3-23) Construct a 10-to-1 line multiplexer with three 4-to-1 line multiplexers. The multiplexers should be interconnected and inputs labeled so that the selection codes 0000 through 1001 can be directly applied to the multiplexer selections inputs without added logic. 10:1 mux d0 0 1 d1 1 X d9 9 S3S2S1S0 Implementation using 4:1 muxes. d0 0 d2 1 d4 2 d6 3 0 S 1 S2 1 d8 2 X d9 3 d 0 1 S S d3 1 3 0 d5 2 d7 3 S2 S1 1 2. (MK 3-27) Implement a binary full adder with a dual 4-to-1 line multiplexer and a single inverter. AB Ci S Co 00 0 0 0 C 0 00 1 1 i 0 01 0 1 0 C ´ C 01 1 0 i 1 i 10 0 1 0 10 1 0Ci´ 1 Ci 11 0 0 1 C 1 11 1 1 i 1 0 C 1 i 4:1 2 S 3 mux S1 S0 A B 0 0 1 4:1 Co 2 mux 1 3 S1S0 2 3. (MK 3-34) Design a combinational circuit that forms the 2-bit binary sum S1S0 of two 2-bit numbers A1A0 and B1B0 and has both input C0 and a carry output C2. Do not use half adders or full adders, but instead use a two-level circuit plus inverters for the input variables, as needed. Design the circuit by starting with the following equations for each of the two bits of the adder. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

Design of High Speed and Low Power Six Transistor Full Adder Using Two Transistor Xor Gate
International Journal of Electronics, Communication & Instrumentation Engineering Research and Development (IJECIERD) ISSN 2249-684X Vol. 3, Issue 1, Mar 2013, 87-96 © TJPRC Pvt. Ltd. DESIGN OF HIGH SPEED AND LOW POWER SIX TRANSISTOR FULL ADDER USING TWO TRANSISTOR XOR GATE B. DILLI KUMAR, K. CHARAN KUMAR & T. NAVEEN KUMAR M. Tech (VLSI), Department of ECE, Sree Vidyanikethan Engineering College (Autonomous), Tirupati, India ABSTRACT Full adder is one of the major components in the design of many sophisticated hardware circuits. In this paper the full adder has been designed by using a new efficient design with less number of transistors. A 2 transistor XOR gate has been proposed with the help of two PMOS (Positive Metal Oxide Semiconductor) transistors. By using this 2T XOR gate the size of the full adder has been decreased to a large extent which can be implemented with only 6 transistors. The proposed full adder has a significant improvement in silicon area and power delay product when compared to the previous 8T full adder circuits. Further the proposed adder requires less area to perform a required logic function. Further, the proposed full adder has less power dissipation which makes it suitable for many of the low power applications and because of less area requirement the proposed design can be used in many of the portable applications also . KEYWORDS: Full Adder, XOR, Less Area, Speed, Low Power, Delay, Less Transistor Count, Low Power VLSI INTRODUCTION Full adder is one of the basic building blocks of many of the digital VLSI circuits. Several refinements has been made regarding its structure since its invention. -

Half Adder, Which Finds the Sum of Two Bits
CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 21, SPRING 2013 TOPICS TODAY • Circuits for Addition • Standard Logic Components • Logisim Demo CIRCUITS FOR ADDITION 3.5 Combinational Circuits • Combinational logic circuits give us many useful devices. • One of the simplest is the half adder, which finds the sum of two bits. • We can gain some insight as to the construction of a half adder by looking at its truth table, shown at the right. 30 Half Adder • Inputs: A and B • Outputs: S = lower bit of A + B, cout = carry bit A B S cout 0 0 0 0 0 1 1 0 1 0 1 0 1 1 0 1 • Using Sum-of-Products: S = AB + AB, cout = AB. • Alternatively, we could use XOR: S = A ⊕ B. ! ! ! ! 1 3.5 Combinational Circuits • As we see, the sum can be found using the XOR operation and the carry using the AND operation. 31 3.5 Combinational Circuits • We can change our half adder into to a full adder by including gates for processing the carry bit. • The truth table for a full adder is shown at the right. 32 Full Adder • Inputs: A, B and cin • Outputs: S = lower bit of A + B, cout = carry bit A B cin S cout 0 0 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 1 0 1 1 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 • S = A BC + ABC + AB C + ABC = A ⊕ B ⊕ C. -

Systems Architecture of the English Electric KDF9 Computer
Version 1, September 2009 CCS-N4X2 Systems Architecture of the English Electric KDF9 computer. This transistor-based machine was developed by an English Electric team under ACD Haley, of which the leading light was RH Allmark – (see section N4X5 for a full list of technical references). The KDF9 was remarkable because it is believed to be the first zero-address instruction format computer to have been announced (in 1960). It was first delivered at about the same time (early 1963) as the other famous zero-address computer, the Burroughs B5000 in America. A zero-address machine allows the use of Reverse Polish arithmetic; this offers certain advantages to compiler writers. It is believed that the attention of the English Electric team was first drawn to the zero-address concept through contact with George (General Order Generator), an autocode programming system written for a Deuce computer by the University of Sydney, Australia, in the latter half of the 1950s. George used Reversed Polish, and the KDF9 team was attracted to this convention for the pragmatic reason of wishing to enhance performance by minimising accesses to main store. This may be contrasted with the more theoretical line taken independently by Burroughs. To quote Bob Beard’s article in the autumn 1997 issue of Resurrection, the KDF9 had the following architectural features: Zero Address instruction format (a first?); Reverse Polish notation (for arithmetic operations); Stacks used for arithmetic operations and Flow Control (Jumps) and I/O using ferrite cores with a one microsecond cycle; Separate Arithmetic and Main Controls with instruction prefetch; Hardware Multiply and Divide occupying a complete cabinet with clock doubled; Separate I/O control; A word length of 48 bits, comprising six 8-bit 'syllables' (the precursor of the byte). -

Lecture 4 Adders
Lecture 4 Adders Computer Systems Laboratory Stanford University [email protected] Copyright © 2006 Mark Horowitz Some figures from High-Performance Microprocessor Design © IEEE M Horowitz EE 371 Lecture 4 1 Overview • Readings • Today’s topics – Fast adders generally use a tree structure for parallelism – We will cover basic tree terminology and structures – Look at a few example adder architectures – Examples will spill into next lecture as well M Horowitz EE 371 Lecture 4 2 Adders • Task of an adder is conceptually simple – Sum[n:0]=A[n:0]+B[n:0]+C0 – Subtractors also very simple: -B = ~B+1, so invert B and set C0=1 • Per bit formulas –Sumi = Ai XOR Bi XOR Ci – Couti = Ci+1 = majority(Ai,Bi,Ci) • Fundamental problem is calculating the carry to the nth bit – All carry terms are dependent on all previous terms – So LSB input has a fanout of n • And an absolute minimum of log4n FO4 delays without any logic M Horowitz EE 371 Lecture 4 3 Single-Bit Adders • Adders are chock-full of XORs, which make them interesting – One of the few circuits where pass-gate logic is attractive – A complicated differential passgate logic (DPL) block from the text Lousy way to draw a pair of inverters M Horowitz EE 371 Lecture 4 4 G and P and K, Oh My! • Most fast adders “G”enerate, “P”ropagate, or “K”ill the carry – Usually only G and P are used; K only appears in some carry chains • When does a bit Generate a carry out? –Gi = Ai AND Bi – If Gi is true, then Couti = Ci+1 is forced to be true • When does a bit Propagate a carry in to the carry out? –Pi -

CLOSED SYLLABLES Short a 5-8 Short I 9-12 Mix: A, I 13 Short O 14-15 Mix: A, I, O 16-17 Short U 18-20 Short E 21-24 Y As a Vowel 25-26
DRILL BITS I INTRODUCTION Drill Bits Phonics-oriented word lists for teachers If you’re helping some- CAT and FAN, which they may one learn to read, you’re help- have memorized without ing them unlock the connection learning the sounds associated between the printed word and with the letters. the words we speak — the • Teach students that ex- “sound/symbol” connection. ceptions are also predictable, This book is a compila- and there are usually many ex- tion of lists of words which fol- amples of each kind of excep- low the predictable associa- tion. These are called special tions of letters, syllables and categories or special patterns. words to the sounds we use in speaking to each other. HOW THE LISTS ARE ORGANIZED This book does not at- tempt to be a reading program. Word lists are presented Recognizing words and pat- in the order they are taught in terns in sound/symbol associa- many structured, multisensory tions is just one part of read- language programs: ing, though a critical one. This Syllable type 1: Closed book is designed to be used as syllables — short vowel a reference so that you can: sounds (TIN, EX, SPLAT) • Meet individual needs Syllable type 2: Vowel- of students from a wide range consonant-e — long vowel of ages and backgrounds; VAT sounds (BAKE, DRIVE, SCRAPE) and TAX may be more appro- Syllable Type 3: Open priate examples of the short a syllables — long vowel sound sound for some students than (GO, TRI, CU) www.resourceroom.net BITS DRILL INTRODUCTION II Syllable Type 4: r-con- those which do not require the trolled syllables (HARD, PORCH, student to have picked up PERT) common patterns which have Syllable Type 5: conso- not been taught. -

Introduction to Computer Data Representation
Introduction to Computer Data Representation Peter Fenwick The University of Auckland (Retired) New Zealand Bentham Science Publishers Bentham Science Publishers Bentham Science Publishers Executive Suite Y - 2 P.O. Box 446 P.O. Box 294 PO Box 7917, Saif Zone Oak Park, IL 60301-0446 1400 AG Bussum Sharjah, U.A.E. USA THE NETHERLANDS [email protected] [email protected] [email protected] Please read this license agreement carefully before using this eBook. Your use of this eBook/chapter constitutes your agreement to the terms and conditions set forth in this License Agreement. This work is protected under copyright by Bentham Science Publishers to grant the user of this eBook/chapter, a non- exclusive, nontransferable license to download and use this eBook/chapter under the following terms and conditions: 1. This eBook/chapter may be downloaded and used by one user on one computer. The user may make one back-up copy of this publication to avoid losing it. The user may not give copies of this publication to others, or make it available for others to copy or download. For a multi-user license contact [email protected] 2. All rights reserved: All content in this publication is copyrighted and Bentham Science Publishers own the copyright. You may not copy, reproduce, modify, remove, delete, augment, add to, publish, transmit, sell, resell, create derivative works from, or in any way exploit any of this publication’s content, in any form by any means, in whole or in part, without the prior written permission from Bentham Science Publishers. 3. The user may print one or more copies/pages of this eBook/chapter for their personal use.