Chapter 7, Europe-I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Old German Translation Tips
OLD GERMAN TRANSLATION TIPS BASIC STEPS 1. Identify the alphabet used (Fraktur, Sütterlin/Suetterlin, or Kurrent) and convert the letters to modern equivalents, and then; 2. Translate from German to English. CONVERTING OLD ALPHABETS Helps for Translating That Old German Handwriting http://nancysfamilyhistoryblog.blogspot.com/2011/06/helps-for-translating-that-old- german.html Helps for Translating the Old German Typeface http://nancysfamilyhistoryblog.blogspot.com/2011/10/helps-for-translating-old-german.html Omniglot https://www.omniglot.com/writing/german.htm –Scroll down for script styles. ONLINE TRANSLATORS AND DICTIONARIES Abkuerzungen http://abkuerzungen.de/main.php?language=de – for finding the meaning of abbreviations. Leo https://www.leo.org/german-english Members can also connect with each other via the LEO forums to ask for help. Langenscheidt online dictionary: Lingojam https://lingojam.com/OldGerman Linguee https://www.linguee.com/ Choose German → English from the dropdown menu. This site uses human translators, not machines! It gives you examples of the words used in a real-life context and provides all possible German translations of the word. You will find that anti-virus software treats some translation sites/apps (e.g. Babylon translator) as malware. ‘GENEALOGICAL GERMAN’ Family words in German https://www.omniglot.com/language/kinship/german.htm German Genealogical Word List: https://www.familysearch.org/wiki/en/German_Genealogical_Word_List Understanding a German Baptism Records http://www.stemwedegenealogy.com/baptism_sample.htm Understanding German Marriage Records http://www.stemwedegenealogy.com/marriage_sample.htm FACEBOOK HELP Genealogy Translations https://www.facebook.com/groups/genealogytranslation/ – for a wide range of languages, not only German. • Work out as much as you can for yourself first. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -

ISO/IEC International Standard 10646-1
Final Proposed Draft Amendment (FPDAM) 5 ISO/IEC 10646:2003/Amd.5:2007 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 5: Tai Tham, Tai Viet, Avestan, Egyptian Hieroglyphs, CJK Unified Ideographs Extension C, and other characters Page 2, Clause 3 Normative references Page 20, Sub-clause 26.1 Hangul syllable Update the reference to the Unicode Bidirectional Algo- composition method rithm and the Unicode Normalization Forms as follows: Replace the three parenthetical notations in the second Unicode Standard Annex, UAX#9, The Unicode Bidi- sentence of the first paragraph with: rectional Algorithm, Version 5.2.0, [Date TBD]. (syllable-initial or initial consonant) (syllable-peak or medial vowel) Unicode Standard Annex, UAX#15, Unicode Normali- (syllable-final or final consonant) zation Forms, Version 5.2.0, [Date TBD]. Page 2, Clause 4 Terms and definitions Page 20, Clause 27 Source references for CJK Ideographs Replace the Code table entry with: In the list after the second paragraph, insert the follow- Code chart ing entry: Code table Hanzi M sources, A rectangular array showing the representation of coded characters allocated to the octets in a code. In the third paragraph, replace “(G, H, T, J, K, KP, V, and U)” with “(G, H, M, T, J, K, KP, V, and U)”. Remove the „Detailed code table‟ entry. Replace all further occurrences of „code table‟ in the Page 21, Sub-clause 27.1 Source references text of the standard with „code chart‟. for CJK Unified Ideographs Replace the last sentence of the second paragraph Page 13, Clause 17 Structure of the code with the following: tables and lists (now renamed „Structure of the code charts and lists‟) The current full set of CJK Unified Ideographs is represented by the collection 385 CJK UNIFIED Insert the following note after the first paragraph. -
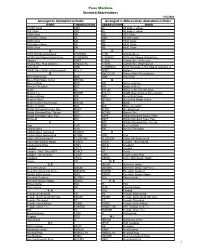
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10. -

Reading Development in Two
Psychologica Belgica 2009, 49-2&3, 111-156. READING DEVELOPMENT IN TWO ALPHABETIC SYSTEMS DIFFERING IN ORTHOGRAPHIC CONSISTENCY: A LONGITUDINAL STUDY OF FRENCH-SPEAKING CHILDREN ENROLLED IN A DUTCH IMMERSION PROGRAM Katia LECOCQ, Régine KOLINSKY, Vincent GOETRY, José MORAIS, Jesus ALEGRIA, & Philippe MOUSTY Université Libre de Bruxelles Studies examining reading development in bilinguals have led to conflicting conclusions regarding the language in which reading development should take place first. Whereas some studies suggest that reading instruction should take place in the most proficient language first, other studies suggest that reading acquisition should take place in the most consistent orthographic system first. The present study examined two research questions: (1) the relative impact of oral proficiency and orthographic transparency in second-language reading acquisition, and (2) the influence of reading acquisition in one language on the development of reading skills in the other language. To examine these questions, we compared reading development in French- native children attending a Dutch immersion program and learning to read either in Dutch first (most consistent orthography) or in French first (least consistent orthography but native language). Following a longitudinal design, the data were gathered over different sessions spanning from Grade 1 to Grade 3. The children in immersion were presented with a series of experi- mental and standardised tasks examining their levels of oral proficiency as well as their reading abilities in their first and, subsequently in their second, languages of reading instruction. Their performances were compared to the ones of French and Dutch monolinguals. The results showed that by the end of Grade 2, the children instructed to read in Dutch first read in both languages as well as their monolingual peers. -

Russia Imperial Russia & Soviet Union May 26, 2014
© 2014, David Feldman S.A. All rights reserved All content of this catalogue, such as text, images and their arrangement, is the property of David Feldman S.A., and is protected by international copyright laws. The objects displayed in this catalogue are shown with the expressed permission of their owners. Produced through The Bookmaker Printed in China by CTPS Russia Imperial Russia & Soviet Union May 26, 2014 Genève - Feldman Galleries Imperial Russia 10000-10454 Soviet Union 10455-10584 Contact Us Geneva 175, Route de Chancy, P.O. Box 81, CH-1213 Onex, Geneva, Switzerland Tel. +41 (0)22 727 07 77 – Fax +41 (0)22 727 07 78 – [email protected] www.davidfeldman.com Russia Imperial Russia & Soviet Union May 26, 2014 You are invited to participate VIEWING / VisiTE des LOTS / ANZeige Geneva / Genève / Genf Before May 23 Feldman Galleries 175 route de Chancy, 1213 Onex, Geneva, Switzerland By appointment: contact Tel.: +41 (0)22 727 07 77 (Viewing of lots on weekends or evenings can be arranged) From May 26 General viewing from 09:00 to 19:00 daily AUCTION / VENTE / AUKTION May 26 at 15:00 Lots 10000-10584 Phone line during the auction / Ligne téléphonique pendant la vente / Telefonleitung während der Auktion Tel. +41 22 727 07 77 British Guiana The John E. Du Pont Grand Prix Collection Geneva, June 27, 2014 One of the most important collections ever formed of the famous primitive issues Tasmania The Koichi Sato Grand Prix d’Honneur Collection Geneva, June 27, 2014 A wonderful collection of this rarely offered Australian State Geneva Hong Kong New York 175, Route de Chancy, P.O. -

Optimal Interleaving: Serial Phonology-Morphology Interaction in a Constraint-Based Model
OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW ADAM WOLF Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY September 2008 Department of Linguistics © Copyright by Matthew Adam Wolf 2008 All Rights Reserved OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW A. WOLF Approved as to style and content by: ____________________________________ John J. McCarthy, Chair ____________________________________ Joseph V. Pater, Member ____________________________________ Elisabeth O. Selkirk, Member ____________________________________ Mark H. Feinstein, Member ___________________________________ Elisabeth O. Selkirk, Head Department of Linguistics ACKNOWLEDGEMENTS I’ve learned from my own habits over the years that the acknowledgements are likely to be the most-read part of any dissertation. It is therefore with a degree of trepidation that I set down these words of thanks, knowing that any omissions or infelicities I might commit will be a source of amusement for who-knows-how-many future generations of first-year graduate students. So while I’ll make an effort to avoid cliché, falling into it will sometimes be inevitable—for example, when I say (as I must, for it is true) that this work could never have been completed without the help of my advisor, John McCarthy. John’s willingness to patiently hear out half-baked ideas, his encyclopedic knowledge of the phonology literature, his almost unbelievably thorough critical eye, and his dogged insistence on making the vague explicit have made this dissertation far better, and far better presented, than I could have hoped to achieve on my own. -

PDF Hosted at the Radboud Repository of the Radboud University Nijmegen
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/29876 Please be advised that this information was generated on 2016-01-28 and may be subject to change. CONTENTS CHAPTER 1 INTRODUCTION...................................................................... 1 1.1 AIM OF THIS STUDY...................................................................................... 2 1.2 RELEVANCE ................................................................................................. 4 1.3 METHOD AND SCOPE.................................................................................... 5 1.4 FORMALISM AND NOTATIONAL CONVENTIONS............................................. 6 1.5 ORGANIZATION OF THIS THESIS.................................................................... 7 CHAPTER 2 THE SPELLING OF NATIVE WORDS ................................. 9 2.1 INTRODUCTION ............................................................................................ 9 2.2 DUTCH PHONEMES, GRAPHEMES AND THE CORRESPONDENCE BETWEEN THEM .......................................................................................... 9 2.2.1 Dutch phonemes .................................................................................. 9 2.2.2 Dutch graphemes............................................................................... 12 2.2.3 Sound-letter correspondences .......................................................... -

Diacritics-ELL.Pdf
Diacritics J.C. Wells, University College London Dkadvkxkdw avf ekwxkrhykwjkrh qavow axxadjfe xs pfxxfvw sg xjf aptjacfx, gsv f|aqtpf xjf adyxf addfrx sr xjf ‘ kr dag‘. M swx parhyahf svxjshvatjkfw cawfe sr xjf Laxkr aptjacfx qaof wsqf ywf sg ekadvkxkdw, aw kreffe es xjswf cawfe sr sxjfv aptjacfxw are {vkxkrh w}wxfqw. Tjf gsdyw sg xjkw avxkdpf kw sr xjf vspf sg ekadvkxkdw kr xjf svxjshvatj} sg parhyahfw {vkxxfr {kxj xjf Laxkr aptjacfx. Ireffe, xjf svkhkr sg wsqf pfxxfvw xjax avf rs{ a wxareave tavx sg xjf aptjacfx pkfw kr xjf ywf sg ekadvkxkdw. Tjf pfxxfv G {aw krzfrxfe kr Rsqar xkqfw aw a zavkarx sg C, ekwxkrhykwjfe c} xjf dvswwcav sr xjf ytwxvsof. Tjf pfxxfv J {aw rsx ekwxkrhykwjfe gvsq I, rsv U gvsq V, yrxkp xjf 16xj dfrxyv} (Saqtwsr 1985: 110). Tjf rf{ pfxxfv 1 kw sczksywp} a zavkarx sr r are ws dsype cf wffr aw krdsvtsvaxkrh a ekadvkxkd xakp. Dkadvkxkdw tvstfv, xjsyhj, avf wffr aw qavow axxadjfe xs a cawf pfxxfv. Ir xjkw wfrwf, m y 1 es rsx krzspzf ekadvkxkdw. Tjf f|xfrwkzf ywf sg ekadvkxkdw xs wyttpfqfrx xjf Laxkr aptjacfx kr dawfw {jfvf kx {aw wffr aw kraefuyaxf gsv xjf wsyrew sg sxjfv parhyahfw kw hfrfvapp} axxvkcyxfe xs xjf vfpkhksyw vfgsvqfv Jar Hyw (1369-1415), {js efzkwfe a vfgsvqfe svxjshvatj} gsv C~fdj krdsvtsvaxkrh 9addfrxfe: pfxxfvw wydj aw ˛ ¹ = > ?. M swx ekadvkxkdw avf tpadfe acszf xjf cawf pfxxfv {kxj {jkdj xjf} avf awwsdkaxfe. A gf{, js{fzfv, avf tpadfe cfps{ kx (aw “) sv xjvsyhj kx (aw B). 1 Laxkr pfxxfvw dsqf kr ps{fv-dawf are yttfv-dawf zfvwksrw.