Ars Glossopoetica
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pottery Technology As a Revealer of Cultural And
Pottery technology as a revealer of cultural and symbolic shifts: Funerary and ritual practices in the Sion ‘Petit-Chasseur’ megalithic necropolis (3100–1600 BC, Western Switzerland) Eve Derenne, Vincent Ard, Marie Besse To cite this version: Eve Derenne, Vincent Ard, Marie Besse. Pottery technology as a revealer of cultural and symbolic shifts: Funerary and ritual practices in the Sion ‘Petit-Chasseur’ megalithic necropolis (3100–1600 BC, Western Switzerland). Journal of Anthropological Archaeology, Elsevier, 2020, 58, pp.101170. 10.1016/j.jaa.2020.101170. hal-03051558 HAL Id: hal-03051558 https://hal.archives-ouvertes.fr/hal-03051558 Submitted on 10 Dec 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Journal of Anthropological Archaeology 58 (2020) 101170 Contents lists available at ScienceDirect Journal of Anthropological Archaeology journal homepage: www.elsevier.com/locate/jaa Pottery technology as a revealer of cultural and symbolic shifts: Funerary and ritual practices in the Sion ‘Petit-Chasseur’ megalithic necropolis T (3100–1600 BC, -

LCC5 CONLANG RELAY — ITHKUIL TEXT: AIFQLAL ÖMMOL Âmmël Tê
LCC5 CONLANG RELAY — ITHKUIL TEXT: AIFQLAL ÖMMOL Âmmël tê, iekawel tiö. Ikàmküz iam-mra ârtwail mmëu’a Ĝi smî’âškôx. Iefqlaromdi ük ho kai’ál. Š. Ailayël egbulak –çoe, aumrawelönar vyelíup qü. Iek’amtoçqár isvala Ħ qo ârtwel kî. Hmuqwat Ĝara č’ óext’ai’l. Hra Ŝnasar –qawe smâ’âškôx. Eswilúk xas –ça hmaigralî Ħ uqwot Ĝukt –č’içewa. Ke uqwat ĜaĦ ia Ńt’aluib eswolúk. Š. Epšal oqwas uqwêt Ĝ óek hwai’l. Aigrawelönar –qowe ocetip. Uqwat Ĝ vyaliup. Vyaliupi’m! Hmi čhal ko ârtwala Ħ lt heĜ mmêĜ. –Ça vyaliup. Ti xat hint. Aigrayëlint to uqwiat Ĝ óek hwai’l _ip’ayûluc’ar ek ho ítu’liu Ń ke. Âmmël tê, auntawél –ça: –aigrayëlar ko uqwet Ĝ óek hwai’l –ieçtraluc’ –qowe. Snalakir uqwat Ĝ áugrala řo. Âdhayëlilliud uqwit Ĝipt, augrayûluc’ eqolekt –qewe. Augrayûl qo –qewe. Az, âmmël tê, aukawél ârtwail kî áula’al ku ltweol. Ir! HELPFUL NOTES • Default word order is VSO or VOS. Placement of a noun before the verb gives it semantic focus. Placement of a noun at the beginning of a sentence topicalizes it. • Ithkuil nominal formatives (i.e., nouns) mandatorily inflect for eight morphological categories, while verbal formatives (i.e., verbs) mandatorily inflect for 22 categories. However, the majority of these categories are often in their default/baseline modes which are unmarked. In order to simplify the intralinears below, I have not indicated unmarked categories, and for default categories that are marked but do not impact the semantics, I have indicated these by empty brackets [ ]. • Many Ithkuil affixes are portmanteau in nature, i.e., combining many separate morphemes into a single affix. -

Revisiting the Insular Celtic Hypothesis Through Working Towards an Original Phonetic Reconstruction of Insular Celtic
Mind Your P's and Q's: Revisiting the Insular Celtic hypothesis through working towards an original phonetic reconstruction of Insular Celtic Rachel N. Carpenter Bryn Mawr and Swarthmore Colleges 0.0 Abstract: Mac, mac, mac, mab, mab, mab- all mean 'son', inis, innis, hinjey, enez, ynys, enys - all mean 'island.' Anyone can see the similarities within these two cognate sets· from orthographic similarity alone. This is because Irish, Scottish, Manx, Breton, Welsh, and Cornish2 are related. As the six remaining Celtic languages, they unsurprisingly share similarities in their phonetics, phonology, semantics, morphology, and syntax. However, the exact relationship between these languages and their predecessors has long been disputed in Celtic linguistics. Even today, the battle continues between two firmly-entrenched camps of scholars- those who favor the traditional P-Celtic and Q-Celtic divisions of the Celtic family tree, and those who support the unification of the Brythonic and Goidelic branches of the tree under Insular Celtic, with this latter idea being the Insular Celtic hypothesis. While much reconstructive work has been done, and much evidence has been brought forth, both for and against the existence of Insular Celtic, no one scholar has attempted a phonetic reconstruction of this hypothesized proto-language from its six modem descendents. In the pages that follow, I will introduce you to the Celtic languages; explore the controversy surrounding the structure of the Celtic family tree; and present a partial phonetic reconstruction of Insular Celtic through the application of the comparative method as outlined by Lyle Campbell (2006) to self-collected data from the summers of2009 and 2010 in my efforts to offer you a novel perspective on an on-going debate in the field of historical Celtic linguistics. -

817 CHRONOLOGY and BELL BEAKER COMMON WARE Martine
RADIOCARBON, Vol 51, Nr 2, 2009, p 817–830 © 2009 by the Arizona Board of Regents on behalf of the University of Arizona CHRONOLOGY AND BELL BEAKER COMMON WARE Martine Piguet • Marie Besse Laboratory of Prehistoric Archaeology and Human Population History, Department of Anthropology and Ecology, University of Geneva, Switzerland. Email: [email protected] and [email protected]. ABSTRACT. The Bell Beaker is a culture of the Final Neolithic, which spread across Europe between 2900 and 1800 BC. Since its origin is still widely discussed, we have been focusing our analysis on the transition from the Final Neolithic pre-Bell Beaker to the Bell Beaker. We thus seek to evaluate the importance of Neolithic influence in the establishment of the Bell Bea- ker by studying the common ware pottery and its chronology. Among the 26 main types of common ware defined by Marie Besse (2003), we selected the most relevant ones in order to determine—on the basis of their absolute dating—their appear- ance either in the Bell Beaker period or in the pre-Bell Beaker groups. INTRODUCTION This study is part of a research project now ongoing for several years and directed by M Besse. Its objective is to better explain the Bell Beaker phenomenon. Two projects funded by the Swiss National Science Foundation (FNS) made it possible to develop the study of the common ware pot- tery and its chronology (M Besse and M Piguet), territory analysis (M Besse and M Piguet), analysis of non-metric dental traits (J Desideri), and copper metallurgy (F Cattin). -

Haplogroup R1b (Y-DNA)
Eupedia Home > Genetics > Haplogroups (home) > Haplogroup R1b Haplogroup R1b (Y-DNA) Content 1. Geographic distribution Author: Maciamo. Original article posted on Eupedia. 2. Subclades Last update January 2014 (revised history, added lactase 3. Origins & History persistence, pigmentation and mtDNA correspondence) Paleolithic origins Neolithic cattle herders The Pontic-Caspian Steppe & the Indo-Europeans The Maykop culture, the R1b link to the steppe ? R1b migration map The Siberian & Central Asian branch The European & Middle Eastern branch The conquest of "Old Europe" The conquest of Western Europe IE invasion vs acculturation The Atlantic Celtic branch (L21) The Gascon-Iberian branch (DF27) The Italo-Celtic branch (S28/U152) The Germanic branch (S21/U106) How did R1b become dominant ? The Balkanic & Anatolian branch (L23) The upheavals ca 1200 BCE The Levantine & African branch (V88) Other migrations of R1b 4. Lactase persistence and R1b cattle pastoralists 5. R1 populations & light pigmentation 6. MtDNA correspondence 7. Famous R1b individuals Geographic distribution Distribution of haplogroup R1b in Europe 1/22 R1b is the most common haplogroup in Western Europe, reaching over 80% of the population in Ireland, the Scottish Highlands, western Wales, the Atlantic fringe of France, the Basque country and Catalonia. It is also common in Anatolia and around the Caucasus, in parts of Russia and in Central and South Asia. Besides the Atlantic and North Sea coast of Europe, hotspots include the Po valley in north-central Italy (over 70%), Armenia (35%), the Bashkirs of the Urals region of Russia (50%), Turkmenistan (over 35%), the Hazara people of Afghanistan (35%), the Uyghurs of North-West China (20%) and the Newars of Nepal (11%). -

Historical Background of the Contact Between Celtic Languages and English
Historical background of the contact between Celtic languages and English Dominković, Mario Master's thesis / Diplomski rad 2016 Degree Grantor / Ustanova koja je dodijelila akademski / stručni stupanj: Josip Juraj Strossmayer University of Osijek, Faculty of Humanities and Social Sciences / Sveučilište Josipa Jurja Strossmayera u Osijeku, Filozofski fakultet Permanent link / Trajna poveznica: https://urn.nsk.hr/urn:nbn:hr:142:149845 Rights / Prava: In copyright Download date / Datum preuzimanja: 2021-09-27 Repository / Repozitorij: FFOS-repository - Repository of the Faculty of Humanities and Social Sciences Osijek Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Osijek Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Odsjek za engleski jezik i književnost Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Znanstveno područje: humanističke znanosti Znanstveno polje: filologija Znanstvena grana: anglistika Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. J.J. Strossmayer University in Osijek Faculty of Humanities and Social Sciences Teaching English as -

A Brief Introduction to Constructed Languages
A Brief Introduction to Constructed Languages An essay by Laurier Rochon Piet Zwart Institute : June 2011 3750 words Abstract The aim of this essay will be to provide a general overview of what is considered a "constructed language" (also called conlang, formalized language or artificial language) and explore some similarities, differences and specific properties that set these languages apart from natural languages. This essay is not meant to be an exhaustive repertoire of all existing conlangs, nor should it be used as reference material to explain or dissect them. Rather, my intent is to explore and distill meaning from particular conlangs subjectively chosen for their proximity to my personal research practice based on empirical findings I could infer from their observation and brief use. I will not tackle the task of interpreting the various qualities and discrepancies of conlangs within this short study, as it would surely consist of an endeavour of its own. It should also be noted that the varying quality of documentation available for conlangs makes it difficult to find either peer-reviewed works or independent writings on these subjects. As a quick example, many artistic languages are conceived and solely used by the author himself/herself. This person is obviously the only one able to make sense of it. This short study will not focus on artlangs, but one would understand the challenge in analyzing such a creation: straying away from the beaten path affords an interesting quality to the work, but also renders difficult a precise analytical study of it. In many ways, I have realized that people involved in constructing languages are generally engaging in a fringe activity which typically does not gather much attention - understandably so, given the supremacy of natural languages in our world. -

Review of "The Romance Languages" by R. Posner
Swarthmore College Works Linguistics Faculty Works Linguistics 1998 Review Of "The Romance Languages" By R. Posner Donna Jo Napoli Swarthmore College, [email protected] Follow this and additional works at: https://works.swarthmore.edu/fac-linguistics Part of the Linguistics Commons Let us know how access to these works benefits ouy Recommended Citation Donna Jo Napoli. (1998). "Review Of "The Romance Languages" By R. Posner". Journal Of Linguistics. Volume 34, Issue 1. 302-303. https://works.swarthmore.edu/fac-linguistics/10 This work is brought to you for free by Swarthmore College Libraries' Works. It has been accepted for inclusion in Linguistics Faculty Works by an authorized administrator of Works. For more information, please contact [email protected]. The Romance Languages by Rebecca Posner Review by: Donna Jo Napoli Journal of Linguistics, Vol. 34, No. 1 (Mar., 1998), pp. 302-303 Published by: Cambridge University Press Stable URL: http://www.jstor.org/stable/4176472 . Accessed: 17/07/2014 15:00 Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at . http://www.jstor.org/page/info/about/policies/terms.jsp . JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. Cambridge University Press is collaborating with JSTOR to digitize, preserve and extend access to Journal of Linguistics. http://www.jstor.org This content downloaded from 130.58.65.13 on Thu, 17 Jul 2014 15:00:57 PM All use subject to JSTOR Terms and Conditions JOURNAL OF LINGUISTICS cliticin objectposition when quantification is involvedand the presenceof the resumptiveclitic when thereis no quantification,even if a wh-phraseis involved. -

KHAZAR UNIVERSITY Faculty
KHAZAR UNIVERSITY Faculty: School of Humanities and Social Sciences Department: English Language and Literature Specialty: English Language and Literature MA THESIS Theme: Historical English Borrowings Master Student: Aynura Huseynova Supervisor: Eldar Shahgaldiyev, Ph.D. January -2014 1 Contents Introduction…………………………………………………....3 – 9 Chapter I: Survey of the English language. Word Stock……………… 10-16 To which group does English language belong? …………… 16-23 Historical Background…………..………………................... 23-27 The historical periods of English language…………………. 27-31 Chapter II: English Borrowings and Their Structural Analysis. The History of English Language (Historical Approach)…… 32-68 Chapter III: Tendency of Future Development of English Borrowings……………………………................... 69-72 Conclusion…………………………………………............ 73-74 References………………………………………………… 75-76 2 INTRODUCTION Although at the end of the every century, learning Latin, Greek, Arabic, Spanish, German, French language spread while replacing each other. But for two centuries the English language got non-substitutive, unchanged status as the world's international language and learning of this language began to spread in our republic widely. The cause of widely spread of the English language all over the not only being the powerful maritime empire Great Britain‘s global colonization policy, but also was easy to master language. It is known that among world languages English has rich vocabulary reserve. The changes in nation's economic-political and cultural life, new production methods, new scientific achievements and technological progress, main turn in agriculture, changes in social structure, science, culture, trade, the development of literature, the creation of the state, and etc., such events were the cause of further enrichment and affect the structure of the dictionary of the English language. -

Gramley 2009
1 The Origins of English. 1. The origins of human language. According to some calculations the capacity for language – which is surely one of the most clearly human features we have – emerged approximately 145,000 years ago (± 70,000) (Bickerton 1990: 175). The emergence of human speech depended on both suitable physiological change in what were to become the organs of speech and on changes in the structure of the brain to allow humans to work with the complexity of language neurologically (ibid.: chap. 8). Furthermore, widespread opinion (e.g. Bickerton 1990: 4; Bloomfield 1933: 3; Chomsky 1968: 100; Diamond 1992: 141; Sapir 1921: 23) sees the acquisition of language as a unique phenomenon. As such it was then passed on to the descendants of the first group of speakers. Just how this mooted first language may have looked in detail is unknown, but the multiplicity and diversity of languages spoken in today’s world indicate one of the unchanging principles of human language – change: out of one many have developed. One of these many languages is English, itself a grouping of often very different varieties spoken all over the world by both native and non-native speakers. (Just how many speakers is a widely debated question, as is the question of what a native and what a non-native speakers is. See the discussion in chapters 7 and 13.) It is the aim of this book to explore how English came into being and developed the enormous amount of diversity which the label English covers. 2. Divergence, change, and the family model. -
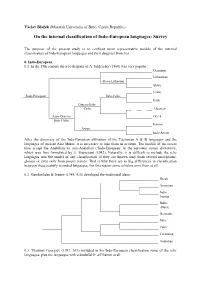
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

Inventors and Devotees of Artificial Languages
From SIAM News, Volume 43, Number 5, June 2010 Inventors and Devotees of Artificial Languages In the Land of Invented Languages: Esperanto Rock Stars, Klingon Poets, Loglan Lovers, and The Mad Dreamers Who Tried to Build a Perfect Language. By Arika Okrent, Spiegel and Grau, New York, 2009, 352 pages, $26.00. In the Land of Invented Languages is a remarkably entertaining historical survey of artificial languages and their inventors, from the Lingua Ignota of Hildegard von Bingen in the 12th century through Esperanto and, more recently, Klingon. The depth of the research is impressive. The author, Arika Okrent, attended conferences in Esperanto, Loglan, and Klingon, among others; hunted up obscure self-published tomes available only in a few rare book rooms; worked through scores of these languages in enough depth to translate BOOK REVIEW passages into them; and interviewed hundreds of people, both language inventors and enthusiasts, getting to know many By Ernest Davis of them well. One of the book’s two appendices lists 500 artificial languages; the other offers translations of the Lord’s Prayer into 17 languages and of the Story of Babel into another 11. The text contains samples from many more languages, carefully explained and analyzed. Nonetheless, the book wears its learning very lightly; it is delightfully personal, and as readable as a novel. It is in fact as much about the histories of the inventors and devotees of the languages as about the languages themselves; these histories are mostly strange and often sad. Invented languages can be categorized by the purposes of their inventors.