Schema Representation: the Logical-To-Physical Mapping
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Hexadecimal Number System and Memory Addressing
C5537_App C_1107_03/16/2005 APPENDIX C The Hexadecimal Number System and Memory Addressing nderstanding the number system and the coding system that computers use to U store data and communicate with each other is fundamental to understanding how computers work. Early attempts to invent an electronic computing device met with disappointing results as long as inventors tried to use the decimal number sys- tem, with the digits 0–9. Then John Atanasoff proposed using a coding system that expressed everything in terms of different sequences of only two numerals: one repre- sented by the presence of a charge and one represented by the absence of a charge. The numbering system that can be supported by the expression of only two numerals is called base 2, or binary; it was invented by Ada Lovelace many years before, using the numerals 0 and 1. Under Atanasoff’s design, all numbers and other characters would be converted to this binary number system, and all storage, comparisons, and arithmetic would be done using it. Even today, this is one of the basic principles of computers. Every character or number entered into a computer is first converted into a series of 0s and 1s. Many coding schemes and techniques have been invented to manipulate these 0s and 1s, called bits for binary digits. The most widespread binary coding scheme for microcomputers, which is recog- nized as the microcomputer standard, is called ASCII (American Standard Code for Information Interchange). (Appendix B lists the binary code for the basic 127- character set.) In ASCII, each character is assigned an 8-bit code called a byte. -

Midterm-2020-Solution.Pdf
HONOR CODE Questions Sheet. A Lets C. [6 Points] 1. What type of address (heap,stack,static,code) does each value evaluate to Book1, Book1->name, Book1->author, &Book2? [4] 2. Will all of the print statements execute as expected? If NO, write print statement which will not execute as expected?[2] B. Mystery [8 Points] 3. When the above code executes, which line is modified? How many times? [2] 4. What is the value of register a6 at the end ? [2] 5. What is the value of register a4 at the end ? [2] 6. In one sentence what is this program calculating ? [2] C. C-to-RISC V Tree Search; Fill in the blanks below [12 points] D. RISCV - The MOD operation [8 points] 19. The data segment starts at address 0x10000000. What are the memory locations modified by this program and what are their values ? E Floating Point [8 points.] 20. What is the smallest nonzero positive value that can be represented? Write your answer as a numerical expression in the answer packet? [2] 21. Consider some positive normalized floating point number where p is represented as: What is the distance (i.e. the difference) between p and the next-largest number after p that can be represented? [2] 22. Now instead let p be a positive denormalized number described asp = 2y x 0.significand. What is the distance between p and the next largest number after p that can be represented? [2] 23. Sort the following minifloat numbers. [2] F. Numbers. [5] 24. What is the smallest number that this system can represent 6 digits (assume unsigned) ? [1] 25. -

2018-19 MAP 160 Byte File Layout Specifications
2018-19 MAP 160 Byte File Layout Specifications OVERVIEW: A) ISAC will provide an Eligibility Status File (ESF) record for each student to all schools listed as a college choice on the student’s Student Aid Report (SAR). The ESF records will be available daily as Record Type = 7. ESF records may be retrieved via the File Extraction option in MAP. B) Schools will transmit Payment Requests to ISAC via File Transfer Protocol (FTP) using the MAP 160byte layout and identify these with Record Type = 4. C) When payment requests are processed, ISAC will provide payment results to schools through the MAP system. The payment results records can be retrieved in the 160 byte format using the MAP Payment Results File Extraction Option. MAP results records have a Record Type = 5. The MAP Payment Results file contains some eligibility status data elements. Also, the same student record may appear on both the Payment Results and the Eligibility Status extract files. Schools may also use the Reports option in MAP to obtain payment results. D) To cancel Payment Requests, the school with the current Payment Results record on ISAC's Payment Database must transmit a matching record with MAP Payment Request Code = C, with the Requested Award Amount field equal to zero and the Enrollment Hours field equal to 0 along with other required data elements. These records must be transmitted to ISAC as Record Type = 4. E) Summary of Data Element Changes, revision (highlighted in grey) made to the 2018-19 layout. NONE 1 2018-19 MAP 160 Byte File Layout Specifications – 9/17 2018-19 MAP 160 Byte File Layout Specifications F) The following 160 byte record layout will be used for transmitting data between schools and ISAC. -

The Pros of Cons: Programming with Pairs and Lists
The Pros of cons: Programming with Pairs and Lists CS251 Programming Languages Spring 2016, Lyn Turbak Department of Computer Science Wellesley College Racket Values • booleans: #t, #f • numbers: – integers: 42, 0, -273 – raonals: 2/3, -251/17 – floang point (including scien3fic notaon): 98.6, -6.125, 3.141592653589793, 6.023e23 – complex: 3+2i, 17-23i, 4.5-1.4142i Note: some are exact, the rest are inexact. See docs. • strings: "cat", "CS251", "αβγ", "To be\nor not\nto be" • characters: #\a, #\A, #\5, #\space, #\tab, #\newline • anonymous func3ons: (lambda (a b) (+ a (* b c))) What about compound data? 5-2 cons Glues Two Values into a Pair A new kind of value: • pairs (a.k.a. cons cells): (cons v1 v2) e.g., In Racket, - (cons 17 42) type Command-\ to get λ char - (cons 3.14159 #t) - (cons "CS251" (λ (x) (* 2 x)) - (cons (cons 3 4.5) (cons #f #\a)) Can glue any number of values into a cons tree! 5-3 Box-and-pointer diagrams for cons trees (cons v1 v2) v1 v2 Conven3on: put “small” values (numbers, booleans, characters) inside a box, and draw a pointers to “large” values (func3ons, strings, pairs) outside a box. (cons (cons 17 (cons "cat" #\a)) (cons #t (λ (x) (* 2 x)))) 17 #t #\a (λ (x) (* 2 x)) "cat" 5-4 Evaluaon Rules for cons Big step seman3cs: e1 ↓ v1 e2 ↓ v2 (cons) (cons e1 e2) ↓ (cons v1 v2) Small-step seman3cs: (cons e1 e2) ⇒* (cons v1 e2); first evaluate e1 to v1 step-by-step ⇒* (cons v1 v2); then evaluate e2 to v2 step-by-step 5-5 cons evaluaon example (cons (cons (+ 1 2) (< 3 4)) (cons (> 5 6) (* 7 8))) ⇒ (cons (cons 3 (< 3 4)) -

POINTER (IN C/C++) What Is a Pointer?
POINTER (IN C/C++) What is a pointer? Variable in a program is something with a name, the value of which can vary. The way the compiler and linker handles this is that it assigns a specific block of memory within the computer to hold the value of that variable. • The left side is the value in memory. • The right side is the address of that memory Dereferencing: • int bar = *foo_ptr; • *foo_ptr = 42; // set foo to 42 which is also effect bar = 42 • To dereference ted, go to memory address of 1776, the value contain in that is 25 which is what we need. Differences between & and * & is the reference operator and can be read as "address of“ * is the dereference operator and can be read as "value pointed by" A variable referenced with & can be dereferenced with *. • Andy = 25; • Ted = &andy; All expressions below are true: • andy == 25 // true • &andy == 1776 // true • ted == 1776 // true • *ted == 25 // true How to declare pointer? • Type + “*” + name of variable. • Example: int * number; • char * c; • • number or c is a variable is called a pointer variable How to use pointer? • int foo; • int *foo_ptr = &foo; • foo_ptr is declared as a pointer to int. We have initialized it to point to foo. • foo occupies some memory. Its location in memory is called its address. &foo is the address of foo Assignment and pointer: • int *foo_pr = 5; // wrong • int foo = 5; • int *foo_pr = &foo; // correct way Change the pointer to the next memory block: • int foo = 5; • int *foo_pr = &foo; • foo_pr ++; Pointer arithmetics • char *mychar; // sizeof 1 byte • short *myshort; // sizeof 2 bytes • long *mylong; // sizeof 4 byts • mychar++; // increase by 1 byte • myshort++; // increase by 2 bytes • mylong++; // increase by 4 bytes Increase pointer is different from increase the dereference • *P++; // unary operation: go to the address of the pointer then increase its address and return a value • (*P)++; // get the value from the address of p then increase the value by 1 Arrays: • int array[] = {45,46,47}; • we can call the first element in the array by saying: *array or array[0]. -

The Use of UML for Software Requirements Expression and Management
The Use of UML for Software Requirements Expression and Management Alex Murray Ken Clark Jet Propulsion Laboratory Jet Propulsion Laboratory California Institute of Technology California Institute of Technology Pasadena, CA 91109 Pasadena, CA 91109 818-354-0111 818-393-6258 [email protected] [email protected] Abstract— It is common practice to write English-language 1. INTRODUCTION ”shall” statements to embody detailed software requirements in aerospace software applications. This paper explores the This work is being performed as part of the engineering of use of the UML language as a replacement for the English the flight software for the Laser Ranging Interferometer (LRI) language for this purpose. Among the advantages offered by the of the Gravity Recovery and Climate Experiment (GRACE) Unified Modeling Language (UML) is a high degree of clarity Follow-On (F-O) mission. However, rather than use the real and precision in the expression of domain concepts as well as project’s model to illustrate our approach in this paper, we architecture and design. Can this quality of UML be exploited have developed a separate, ”toy” model for use here, because for the definition of software requirements? this makes it easier to avoid getting bogged down in project details, and instead to focus on the technical approach to While expressing logical behavior, interface characteristics, requirements expression and management that is the subject timeliness constraints, and other constraints on software using UML is commonly done and relatively straight-forward, achiev- of this paper. ing the additional aspects of the expression and management of software requirements that stakeholders expect, especially There is one exception to this choice: we will describe our traceability, is far less so. -

Bits and Bytes
BITS AND BYTES To understand how a computer works, you need to understand the BINARY SYSTEM. The binary system is a numbering system that uses only two digits—0 and 1. Although this may seem strange to humans, it fits the computer perfectly! A computer chip is made up of circuits. For each circuit, there are two possibilities: An electric current flows through the circuit (ON), or An electric current does not flow through the circuit (OFF) The number 1 represents an “on” circuit. The number 0 represents an “off” circuit. The two digits, 0 and 1, are called bits. The word bit comes from binary digit: Binary digit = bit Every time the computer “reads” an instruction, it translates that instruction into a series of bits (0’s and 1’s). In most computers every letter, number, and symbol is translated into eight bits, a combination of eight 0’s and 1’s. For example the letter A is translated into 01000001. The letter B is 01000010. Every single keystroke on the keyboard translates into a different combination of eight bits. A group of eight bits is called a byte. Therefore, a byte is a combination of eight 0’s and 1’s. Eight bits = 1 byte Capacity of computer memory, storage such as USB devices, DVD’s are measured in bytes. For example a Word file might be 35 KB while a picture taken by a digital camera might be 4.5 MG. Hard drives normally are measured in GB or TB: Kilobyte (KB) approximately 1,000 bytes MegaByte (MB) approximately 1,000,000 (million) bytes Gigabtye (GB) approximately 1,000,000,000 (billion) bytes Terabyte (TB) approximately 1,000,000,000,000 (trillion) bytes The binary code that computers use is called the ASCII (American Standard Code for Information Interchange) code. -

IEEE Standard 754 for Binary Floating-Point Arithmetic
Work in Progress: Lecture Notes on the Status of IEEE 754 October 1, 1997 3:36 am Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic Prof. W. Kahan Elect. Eng. & Computer Science University of California Berkeley CA 94720-1776 Introduction: Twenty years ago anarchy threatened floating-point arithmetic. Over a dozen commercially significant arithmetics boasted diverse wordsizes, precisions, rounding procedures and over/underflow behaviors, and more were in the works. “Portable” software intended to reconcile that numerical diversity had become unbearably costly to develop. Thirteen years ago, when IEEE 754 became official, major microprocessor manufacturers had already adopted it despite the challenge it posed to implementors. With unprecedented altruism, hardware designers had risen to its challenge in the belief that they would ease and encourage a vast burgeoning of numerical software. They did succeed to a considerable extent. Anyway, rounding anomalies that preoccupied all of us in the 1970s afflict only CRAY X-MPs — J90s now. Now atrophy threatens features of IEEE 754 caught in a vicious circle: Those features lack support in programming languages and compilers, so those features are mishandled and/or practically unusable, so those features are little known and less in demand, and so those features lack support in programming languages and compilers. To help break that circle, those features are discussed in these notes under the following headings: Representable Numbers, Normal and Subnormal, Infinite -

Numerical Computing with IEEE Floating Point Arithmetic This Page Intentionally Left Blank Numerical Computing with IEEE Floating Point Arithmetic
Numerical Computing with IEEE Floating Point Arithmetic This page intentionally left blank Numerical Computing with IEEE Floating Point Arithmetic Including One Theorem, One Rule of Thumb, and One Hundred and One Exercises Michael L. Overton Courant Institute of Mathematical Sciences New York University New York, New York siam. Society for Industrial and Applied Mathematics Philadelphia Copyright © 2001 by the Society for Industrial and Applied Mathematics. 1098765432 All rights reserved. Printed in the United States of America. No part of this book may be reproduced, stored, or transmitted in any manner without the written permission of the publisher. For information, write to the Society for Industrial and Applied Mathematics, 3600 University City Science Center, Philadelphia, PA 19104-2688. Library of Congress Cataloging-in-Publication Data Overton, Michael L Numerical computing with IEEE floating point arithmetic / Michael L Overton. p. cm. Includes bibliographical references and index. ISBN 0-89871-571-7 I. Computer arithmetic. 2. Floating-point arithmetic. 3. Numerical calculations. I. Title. QA76.9.M35O94200I O04'.0l'5l--dc2l 00-067941 SlcLJTL is a registered trademark. Dedicated to girls who like math especially my daughter Eleuthera Overton Sa This page intentionally left blank Contents Preface ix Acknowledgments xi 1 Introduction 1 2 The Real Numbers 5 3 Computer Representation of Numbers 9 4 IEEE Floating Point Representation 17 5 Rounding 25 6 Correctly Rounded Floating Point Operations 31 7 Exceptions 41 8 The Intel Microprocessors 49 9 Programming Languages 55 10 Floating Point in C 59 11 Cancellation 71 12 Conditioning of Problems 77 13 Stability of Algorithms 83 14 Conclusion 97 Bibliography 101 vii This page intentionally left blank Preface Numerical computing is a vital part of the modern scientific infrastructure. -
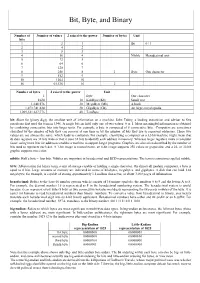
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

Java for Scientific Computing, Pros and Cons
Journal of Universal Computer Science, vol. 4, no. 1 (1998), 11-15 submitted: 25/9/97, accepted: 1/11/97, appeared: 28/1/98 Springer Pub. Co. Java for Scienti c Computing, Pros and Cons Jurgen Wol v. Gudenb erg Institut fur Informatik, Universitat Wurzburg wol @informatik.uni-wuerzburg.de Abstract: In this article we brie y discuss the advantages and disadvantages of the language Java for scienti c computing. We concentrate on Java's typ e system, investi- gate its supp ort for hierarchical and generic programming and then discuss the features of its oating-p oint arithmetic. Having found the weak p oints of the language we pro- p ose workarounds using Java itself as long as p ossible. 1 Typ e System Java distinguishes b etween primitive and reference typ es. Whereas this distinc- tion seems to b e very natural and helpful { so the primitives which comprise all standard numerical data typ es have the usual value semantics and expression concept, and the reference semantics of the others allows to avoid p ointers at all{ it also causes some problems. For the reference typ es, i.e. arrays, classes and interfaces no op erators are available or may b e de ned and expressions can only b e built by metho d calls. Several variables may simultaneously denote the same ob ject. This is certainly strange in a numerical setting, but not to avoid, since classes have to b e used to intro duce higher data typ es. On the other hand, the simple hierarchy of classes with the ro ot Object clearly b elongs to the advantages of the language. -

A Metaobject Protocol for Fault-Tolerant CORBA Applications
A Metaobject Protocol for Fault-Tolerant CORBA Applications Marc-Olivier Killijian*, Jean-Charles Fabre*, Juan-Carlos Ruiz-Garcia*, Shigeru Chiba** *LAAS-CNRS, 7 Avenue du Colonel Roche **Institute of Information Science and 31077 Toulouse cedex, France Electronics, University of Tsukuba, Tennodai, Tsukuba, Ibaraki 305-8573, Japan Abstract The corner stone of a fault-tolerant reflective The use of metalevel architectures for the architecture is the MOP. We thus propose a special implementation of fault-tolerant systems is today very purpose MOP to address the problems of general-purpose appealing. Nevertheless, all such fault-tolerant systems ones. We show that compile-time reflection is a good have used a general-purpose metaobject protocol (MOP) approach for developing a specialized runtime MOP. or are based on restricted reflective features of some The definition and the implementation of an object-oriented language. According to our past appropriate runtime metaobject protocol for implementing experience, we define in this paper a suitable metaobject fault tolerance into CORBA applications is the main protocol, called FT-MOP for building fault-tolerant contribution of the work reported in this paper. This systems. We explain how to realize a specialized runtime MOP, called FT-MOP (Fault Tolerance - MetaObject MOP using compile-time reflection. This MOP is CORBA Protocol), is sufficiently general to be used for other aims compliant: it enables the execution and the state evolution (mobility, adaptability, migration, security). FT-MOP of CORBA objects to be controlled and enables the fault provides a mean to attach dynamically fault tolerance tolerance metalevel to be developed as CORBA software. strategies to CORBA objects as CORBA metaobjects, enabling thus these strategies to be implemented as 1 .