Approaching DRAM Performance by Using Microsecond-Latency Flash Memory for Small-Sized Random Read Accesses: a New Access Method and Its Graph Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 3 Semiconductor Memories
Chapter 3 Semiconductor Memories Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Introduction Random Access Memories Content Addressable Memories Read Only Memories Flash Memories Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 2 Overview of Memory Types Semiconductor Memories Read/Write Memory or Random Access Memory (RAM) Read Only Memory (ROM) Random Access Non-Random Access Memory (RAM) Memory (RAM) •Mask (Fuse) ROM •Programmable ROM (PROM) •Erasable PROM (EPROM) •Static RAM (SRAM) •FIFO/LIFO •Electrically EPROM (EEPROM) •Dynamic RAM (DRAM) •Shift Register •Flash Memory •Register File •Content Addressable •Ferroelectric RAM (FRAM) Memory (CAM) •Magnetic RAM (MRAM) Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 3 Memory Elements – Memory Architecture Memory elements may be divided into the following categories Random access memory Serial access memory Content addressable memory Memory architecture 2m+k bits row decoder row decoder 2n-k words row decoder row decoder column decoder k column mux, n-bit address sense amp, 2m-bit data I/Os write buffers Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 4 1-D Memory Architecture S0 S0 Word0 Word0 S1 S1 Word1 Word1 S2 S2 Word2 Word2 A0 S3 S3 A1 Decoder Ak-1 Sn-2 Storage Sn-2 Wordn-2 element Wordn-2 Sn-1 Sn-1 Wordn-1 Wordn-1 m-bit m-bit Input/Output Input/Output n select signals are reduced n select signals: S0-Sn-1 to k address signals: A0-Ak-1 Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 5 Memory Architecture S0 Word0 Wordi-1 S1 A0 A1 Ak-1 Row Decoder Sn-1 Wordni-1 A 0 Column Decoder Aj-1 Sense Amplifier Read/Write Circuit m-bit Input/Output Advanced Reliable Systems (ARES) Lab. -
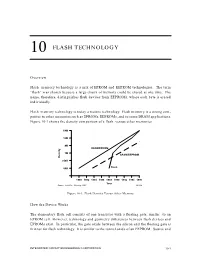
Section 10 Flash Technology
10 FLASH TECHNOLOGY Overview Flash memory technology is a mix of EPROM and EEPROM technologies. The term “flash” was chosen because a large chunk of memory could be erased at one time. The name, therefore, distinguishes flash devices from EEPROMs, where each byte is erased individually. Flash memory technology is today a mature technology. Flash memory is a strong com- petitor to other memories such as EPROMs, EEPROMs, and to some DRAM applications. Figure 10-1 shows the density comparison of a flash versus other memories. 64M 16M 4M DRAM/EPROM 1M SRAM/EEPROM Density 256K Flash 64K 1980 1982 1984 1986 1988 1990 1992 1994 1996 Year Source: Intel/ICE, "Memory 1996" 18613A Figure 10-1. Flash Density Versus Other Memory How the Device Works The elementary flash cell consists of one transistor with a floating gate, similar to an EPROM cell. However, technology and geometry differences between flash devices and EPROMs exist. In particular, the gate oxide between the silicon and the floating gate is thinner for flash technology. It is similar to the tunnel oxide of an EEPROM. Source and INTEGRATED CIRCUIT ENGINEERING CORPORATION 10-1 Flash Technology drain diffusions are also different. Figure 10-2 shows a comparison between a flash cell and an EPROM cell with the same technology complexity. Due to thinner gate oxide, the flash device will be more difficult to process. CMOS Flash Cell CMOS EPROM Cell Mag. 10,000x Mag. 10,000x Flash Memory Cell – Larger transistor – Thinner floating gate – Thinner oxide (100-200Å) Photos by ICE 17561A Figure 10-2. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

MSP430 Flash Memory Characteristics (Rev. B)
Application Report SLAA334B–September 2006–Revised August 2018 MSP430 Flash Memory Characteristics ........................................................................................................................ MSP430 Applications ABSTRACT Flash memory is a widely used, reliable, and flexible nonvolatile memory to store software code and data in a microcontroller. Failing to handle the flash according to data-sheet specifications can result in unreliable operation of the application. This application report explains the physics behind these specifications and also gives recommendations for the correct management of flash memory on MSP430™ microcontrollers (MCUs). All examples are based on the flash memory used in the MSP430F1xx, MSP430F2xx, and MSP430F4xx microcontroller families. Contents 1 Flash Memory ................................................................................................................ 2 2 Simplified Flash Memory Cell .............................................................................................. 2 3 Flash Memory Parameters ................................................................................................. 3 3.1 Data Retention ...................................................................................................... 3 3.2 Flash Endurance.................................................................................................... 5 3.3 Cumulative Program Time......................................................................................... 5 4 -

The Rise of the Flash Memory Market: Its Impact on Firm
The Rise of the Flash Web version: Memory Market: Its Impact July 2007 on Firm Behavior and Author: Global Semiconductor Falan Yinug1 Trade Patterns Abstract This article addresses three questions about the flash memory market. First, will the growth of the flash memory market be a short- or long-term phenomenon? Second, will the growth of the flash memory market prompt changes in firm behavior and industry structure? Third, what are the implications for global semiconductor trade patterns of flash memory market growth? The analysis concludes that flash memory market growth is a long-term phenomenon to which producers have responded in four distinct ways. It also concludes that the rise in flash memory demand has intensified current semiconductor trade patterns but has not shifted them fundamentally. 1 Falan Yinug ([email protected]) is a International Trade Analyst from the Office of Industries. His words are strictly his own and do not represent the opinions of the US International Trade Commission or of any of its Commissioners. 1 Introduction The past few years have witnessed rapid growth in a particular segment of the 2 semiconductor market known as flash memory. In each of the past five years, for example, flash memory market growth has either outpaced or equaled that 3 of the total integrated circuit (IC) market (McClean et al 2004-2007, section 5). One observer expects flash memory to have the third-strongest market growth rate over the next six years among all IC product categories (McClean et al 2007, 5-6). As a result, the flash memory share of the total IC market has increased from 5.5 percent in 2002, to 8.1 percent in 2005. -

Charles Lindsey the Mechanical Differential Analyser Built by Metropolitan Vickers in 1935, to the Order of Prof
Issue Number 51 Summer 2010 Computer Conservation Society Aims and objectives The Computer Conservation Society (CCS) is a co-operative venture between the British Computer Society (BCS), the Science Museum of London and the Museum of Science and Industry (MOSI) in Manchester. The CCS was constituted in September 1989 as a Specialist Group of the British Computer Society. It is thus covered by the Royal Charter and charitable status of the BCS. The aims of the CCS are: To promote the conservation of historic computers and to identify existing computers which may need to be archived in the future, To develop awareness of the importance of historic computers, To develop expertise in the conservation and restoration of historic computers, To represent the interests of Computer Conservation Society members with other bodies, To promote the study of historic computers, their use and the history of the computer industry, To publish information of relevance to these objectives for the information of Computer Conservation Society members and the wider public. Membership is open to anyone interested in computer conservation and the history of computing. The CCS is funded and supported by voluntary subscriptions from members, a grant from the BCS, fees from corporate membership, donations, and by the free use of the facilities of both museums. Some charges may be made for publications and attendance at seminars and conferences. There are a number of active Projects on specific computer restorations and early computer technologies and software. -

A Hybrid Swapping Scheme Based on Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018)
Received August 19, 2018, accepted September 14, 2018, date of publication October 1, 2018, date of current version October 25, 2018. Digital Object Identifier 10.1109/ACCESS.2018.2872794 A Hybrid Swapping Scheme Based On Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018) JUNYEONG HAN 1, SUNGEUN KIM1, SUNGYOUNG LEE1, JAEHWAN LEE2, AND SUNG JO KIM2 1LG Electronics, Seoul 07336, South Korea 2School of Software, Chung-Ang University, Seoul 06974, South Korea Corresponding author: Sung Jo Kim ([email protected]) This work was supported in part by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education under Grant 2016R1D1A1B03931004 and in part by the Chung-Ang University Research Scholarship Grants in 2015. ABSTRACT As a way to increase the actual main memory capacity of Android smartphones, most of them make use of zRAM swapping, but it has limitation in increasing its capacity since it utilizes main memory. Unfortunately, they cannot use secondary storage as a swap space due to the long response time and wear-out problem. In this paper, we propose a hybrid swapping scheme based on per-process reclaim that supports both secondary-storage swapping and zRAM swapping. It attempts to swap out all the pages in the working set of a process to a zRAM swap space rather than killing the process selected by a low-memory killer, and to swap out the least recently used pages into a secondary storage swap space. The main reason being is that frequently swap- in/out pages use the zRAM swap space while less frequently swap-in/out pages use the secondary storage swap space, in order to reduce the page operation cost. -

AN568: EEPROM Emulation for Flash Microcontrollers
AN568 EEPROM EMULATION FOR FLASH MICROCONTROLLERS 1. Introduction Non-volatile data storage is an important feature of many embedded systems. Dedicated, byte-writeable EEPROM devices are commonly used in such systems to store calibration constants and other parameters that may need to be updated periodically. These devices are typically accessed by an MCU in the system using a serial bus. This solution requires PCB real estate as well as I/O pins and serial bus resources on the MCU. Some cost efficiencies can be realized by using a small amount of the MCU’s flash memory for the EEPROM storage. This note describes firmware designed to emulate EEPROM storage on Silicon Laboratories’ flash-based C8051Fxxx MCUs. Figure 1 shows a map of the example firmware. The highlighted functions are the interface for the main application code. 2. Key Features Compile-Time Configurable Size: Between 4 and 255 bytes Portable: Works across C8051Fxxx device families and popular 8051 compilers Fault Tolerant: Resistant to corruption from power supply events and errant code Small Code Footprint: Less than 1 kB for interface functions + minimum two pages of Flash for data storage User Code Fxxx_EEPROM_Interface.c EEPROM_WriteBlock() EEPROM_ReadBlock() copySector() findCurrentSector() getBaseAddress() findNextSector() Fxxx_Flash_Interface.c FLASH_WriteErase() FLASH_BlankCheck() FLASH_Read() Figure 1. EEPROM Emulation Firmware Rev. 0.1 12/10 Copyright © 2010 by Silicon Laboratories AN568 AN568 3. Basic Operation A very simple example project and wrapper code is included with the source firmware. The example demonstrates how to set up a project with the appropriate files within the Silicon Labs IDE and how to call the EEPROM access functions from user code. -

Data Remanence in Flash Memory Devices
Data Remanence in Flash Memory Devices Sergei Skorobogatov University of Cambridge, Computer Laboratory, 15 JJ Thomson Avenue, Cambridge CB3 0FD, United Kingdom [email protected] Abstract. Data remanence is the residual physical representation of data that has been erased or overwritten. In non-volatile programmable devices, such as UV EPROM, EEPROM or Flash, bits are stored as charge in the floating gate of a transistor. After each erase operation, some of this charge remains. Security protection in microcontrollers and smartcards with EEPROM/Flash memories is based on the assumption that information from the memory disappears completely after erasing. While microcontroller manufacturers successfully hardened already their designs against a range of attacks, they still have a common problem with data remanence in floating-gate transistors. Even after an erase operation, the transistor does not return fully to its initial state, thereby allowing the attacker to distinguish between previously programmed and not programmed transistors, and thus restore information from erased memory. The research in this direction is summarised here and it is shown how much information can be extracted from some microcontrollers after their memory has been ‘erased’. 1 Introduction Data remanence as a problem was first discovered in magnetic media [1,2]. Even if the information is overwritten several times on disks and tapes, it can still be possible to extract the initial data. This led to the development of special methods for reliably removing confidential information from magnetic media. Semiconductor memory in security modules was found to have similar prob- lems with reliable data deletion [3,4]. Data remanence affects not only SRAM, but also memory types like DRAM, UV EPROM, EEPROM and Flash [5]. -

Low-Cost Integration of Serial Eeproms and Flash Memory Devices
White Paper Low-Cost Integration of Serial EEPROMs and Flash Memory Devices Introduction In many applications, non-volatile memory needs are addressed by general-purpose serial-interface electrically erasable programmable read-only memories (EEPROMs) or flash memory devices, especially since they offer low pin-count, small packages, low voltage operation, and low power consumption. Nevertheless, designers still face the challenge of reducing board space and total system cost. Many of the uses for these memory devices are related to system configuration, manufacturing, and security. The functionality provided by serial EEPROMs and some flash devices in these applications can be integrated into a MAX® II CPLD, which offers an 8-Kbit flash storage block called the user flash memory (UFM). The UFM allows users to integrate existing serial EEPROMs on a board, reducing total system cost, minimizing board space, and offering higher reliability and better manufacturability. Serial EEPROM and Flash Memory Device Challenges As electronic systems continue to shrink, the demand for smaller board sizes increases. The packaging of a product is defined by board size and is driven by the number of components. Board components are a direct function of the end-product cost: the more components on a board, the more expensive the end product. Assembly costs, shipping costs, programming costs, and additional support circuitry for serial EEPROMs and flash devices add to total board cost, increasing the cost of the end product. Power consumption and reliability are other challenges design engineers face; the fewer devices resident on the board, the lower the power consumption. The potential for improved reliability of the end product also increases. -

Comparing SLC and MLC Flash Technologies and Structure
September, 2009 Version 1.0 Comparing SLC and MLC Flash Technologies and Structure Author: Ethan Chen/ Tones Yen E-mail: [email protected]; [email protected] www.advantech.com September, 2009 Version 1.0 Table of Contents NOR versus NAND Memory .......................................................................................................1 NOR and NAND Technologies ................................................................................................1 The Cell Structure of NOR and NAND Memory ......................................................................1 Comparing Single-Level Cell and Multi-Level Cell Flash Technologies and Structure ......................................................................................................................................3 Conclusion...................................................................................................................................4 www.advantech.com NOR versus NAND Memory NOR and NAND Technologies In simplest terms, NAND Flash memory refers to sequential access devices that are best suited for handling data storage such as pictures, music, or data files. NOR Flash, on the other hand, is designed for random access devices that are best suited for storage and execution of program code. Code storage applications include STBs (Set-Top Boxes), PCs (Personal Computers), and cell phones. NAND Flash memory can also be used for some boot-up operations. The Cell Structure of NOR and NAND Memory A NAND Flash array is grouped -
MSP430™ Flash Devices Bootloader (BSL) User's Guide (Rev
www.ti.com Table of Contents User’s Guide MSP430™ Flash Devices Bootloader (BSL) ABSTRACT The MSP430™ bootloader (BSL) (formerly known as the bootstrap loader) allows users to communicate with embedded memory in the MSP430 microcontroller (MCU) during the prototyping phase, final production, and in service. Both the programmable memory (flash memory) and the data memory (RAM) can be modified as required. Do not confuse the bootloader with the bootstrap loader programs found in some digital signal processors (DSPs) that automatically load program code (and data) from external memory to the internal memory of the DSP. To use the bootloader, a specific BSL entry sequence must be applied. An added sequence of commands initiates the desired function. A bootloading session can be exited by continuing operation at a defined user program address or by the reset condition. If the device is secured by disabling JTAG, it is still possible to use the BSL. Access to the MSP430 MCU memory through the BSL is protected against misuse by the BSL password. The BSL password is equal to the content of the interrupt vector table on the device. Table of Contents 1 Introduction.............................................................................................................................................................................3 1.1 Supplementary Online Information.....................................................................................................................................3 1.2 Overview of BSL Features................................................................................................................................................