Handwritten Hangul Recognition Using Deep Convolutional Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Devanagari in Luatex
Devanagari in LuaTeX Using OpenType features Ivo Geradts Kai Eigner 1. About us 2. Foreign scripts in TeX, past and present 3. OpenType features 4. OpenType rendering engines 5. ConTeXt engine 6. Example 1: Latin with mark and mkmk 7. Example 2: Arabic 8. Example 3: Devanagari 1. About us TAT Zetwerk offers academic typesetting services Specialties: - critical editions - foreign scripts PlainTeX, for two reasons: - our exotic needs - well documented 2. Foreign scripts in TeX, past and present Past: 8-bit PostScript fonts; e.g. approach for classical greek: - encoding: α = a, β = b, γ = g - ligature table: σ = s, ς = /s, ἄ = a)' - multitude of font-related files: tfm, vf, pfb, enc Present: new TeX-engines XeTeX and LuaTeX can handle OpenType fonts containing Unicode glyph table: - ἄ is unicode position 1F04 3. OpenType features OpenType fonts contain more information than traditional fonts - tfm: bounding boxes, kerning, ligaturen, etc. - OpenType additions: GPOS, GSUB, marks Introduction of XeTeX and LuaTeX removes old limitations: - vocalized Hebrew, Arabic - CJK - Devanagari 4. OpenType rendering engines OpenType fonts require rendering engine, such as: - Uniscribe (Windows) - AAT (OS X); XeTeX on OS X - Graphite (Windows and Linux); XeTeX on all platforms - ConTeXt engine: collection of Lua-scripts attached to various callbacks related to font calls and processing of node list 5. ConTeXt engine - independent of operating system - readable and modifiable - work in progress 6. Example 1: Latin script with mark and mkmk 7. Example 2: Arabic 8. Example 3: Devanagari - Introduction: what is Devanagari? - Devanagari and OpenType - Examples Devanagari Script - Sanskrit (old Indic) - Hindi - Nepali Abugida (consonant–vowel sequences are written as a unit) क = “ka” ◌ क् = “k” क + ् (halant) ◌ क = “ku” क + ु (matra) Mahabharata Syllable structure - Consonants: e.g. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

The Gurmukhi Astrolabe of the Maharaja of Patiala
Indian Journal of History of Science, 47.1 (2012) 63-92 THE GURMUKHI ASTROLABE OF THE MAHARAJA OF PATIALA SREERAMULA RAJESWARA SARMA* (Received 14 August 2011; revised 23 January 2012) Even though the telescope was widely in use in India, the production of naked eye observational instruments continued throughout the nineteenth century. In Punjab, in particular, several instrument makers produced astrolabes, celestial globes and other instruments of observation, some inscribed in Sanskrit, some in Persian and yet some others in English. A new feature was the production of instruments with legends in Punjabi language and Gurmukhi script. Three such instruments are known so far. One of these is a splendid astrolabe produced for the Maharaja of Patiala in 1850. This paper offers a full technical description of this Gurmukhi astrolabe and discusses the geographical and astrological data engraved on it. Attention is drawn to the similarities and differences between this astrolabe and the other astrolabes produced in India. Key words: Astrolabe, Astrological tables, Bha– lu– mal, – Geographical gazetteer, Gurmukhi script, Kursi , Maharaja of Patiala, – – Malayendu Su– ri, Rahim Bakhsh, Rete, Rishikes, Shadow squares, Star pointers, Zodiac signs INTRODUCTION For the historian of science and technology in India, the nineteenth century is an interesting period when traditional sciences and technologies continued to exist side by side with modern western science and technology before ultimately giving way to the latter. In the field of astronomical -
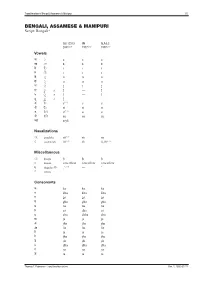
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T. -
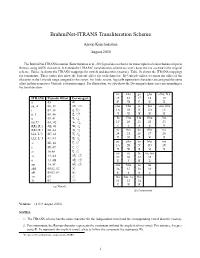
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

The Death of Sanskrit*
The Death of Sanskrit* SHELDON POLLOCK University of Chicago “Toutes les civilisations sont mortelles” (Paul Valéry) In the age of Hindu identity politics (Hindutva) inaugurated in the 1990s by the ascendancy of the Indian People’s Party (Bharatiya Janata Party) and its ideo- logical auxiliary, the World Hindu Council (Vishwa Hindu Parishad), Indian cultural and religious nationalism has been promulgating ever more distorted images of India’s past. Few things are as central to this revisionism as Sanskrit, the dominant culture language of precolonial southern Asia outside the Per- sianate order. Hindutva propagandists have sought to show, for example, that Sanskrit was indigenous to India, and they purport to decipher Indus Valley seals to prove its presence two millennia before it actually came into existence. In a farcical repetition of Romantic myths of primevality, Sanskrit is consid- ered—according to the characteristic hyperbole of the VHP—the source and sole preserver of world culture. The state’s anxiety both about Sanskrit’s role in shaping the historical identity of the Hindu nation and about its contempo- rary vitality has manifested itself in substantial new funding for Sanskrit edu- cation, and in the declaration of 1999–2000 as the “Year of Sanskrit,” with plans for conversation camps, debate and essay competitions, drama festivals, and the like.1 This anxiety has a longer and rather melancholy history in independent In- dia, far antedating the rise of the BJP. Sanskrit was introduced into the Eighth Schedule of the Constitution of India (1949) as a recognized language of the new State of India, ensuring it all the benefits accorded the other fourteen (now seventeen) spoken languages listed. -

The Formal Kharoṣṭhī Script from the Northern Tarim Basin in Northwest
Acta Orientalia Hung. 73 (2020) 3, 335–373 DOI: 10.1556/062.2020.00015 Th e Formal Kharoṣṭhī script from the Northern Tarim Basin in Northwest China may write an Iranian language1 FEDERICO DRAGONI, NIELS SCHOUBBEN and MICHAËL PEYROT* L eiden University Centre for Linguistics, Universiteit Leiden, Postbus 9515, 2300 RA Leiden, Th e Netherlands E-mail: [email protected]; [email protected]; *Corr esponding Author: [email protected] Received: February 13, 2020 •Accepted: May 25, 2020 © 2020 The Authors ABSTRACT Building on collaborative work with Stefan Baums, Ching Chao-jung, Hannes Fellner and Georges-Jean Pinault during a workshop at Leiden University in September 2019, tentative readings are presented from a manuscript folio (T II T 48) from the Northern Tarim Basin in Northwest China written in the thus far undeciphered Formal Kharoṣṭhī script. Unlike earlier scholarly proposals, the language of this folio can- not be Tocharian, nor can it be Sanskrit or Middle Indic (Gāndhārī). Instead, it is proposed that the folio is written in an Iranian language of the Khotanese-Tumšuqese type. Several readings are proposed, but a full transcription, let alone a full translation, is not possible at this point, and the results must consequently remain provisional. KEYWORDS Kharoṣṭhī, Formal Kharoṣṭhī, Khotanese, Tumšuqese, Iranian, Tarim Basin 1 We are grateful to Stefan Baums, Chams Bernard, Ching Chao-jung, Doug Hitch, Georges-Jean Pinault and Nicholas Sims-Williams for very helpful discussions and comments on an earlier draft. We also thank the two peer-reviewers of the manuscript. One of them, Richard Salomon, did not wish to remain anonymous, and espe- cially his observation on the possible relevance of Khotan Kharoṣṭhī has proved very useful. -

Flow Rate Indicator with Very Large Digits
FLOW RATE INDICATOR WITH VERY LARGE DIGITS Features Signal input • Displays instantaneous flow rate and Flow measuring unit. • Reed-switch. • Very large 26mm (1") digits. • NAMUR. • Piegraph indication: ten segments. • NPN/PNP pulse. • Selectable on-screen engineering units; • Sine wave (coil). volumetric or mass. • Active pulse signals. • Ability to process all types of flowmeter • (0)4 - 20mA. signals. • 0 - 10V DC. • Auto backup of all settings. • Operational temperature -40°C up to +80°C Applications (-40°F up to 176°F). • Flow measurement where a local flow rate • Rugged aluminum field mount enclosure indication is required without IP67/NEMA4X. re-transmission or totalizer functionality. DATASHEET INDICATOR RATE F010 - FLOW • Intrinsically Safe - ATEX, IECEx, FM and CSA Alternative advanced models: F012 - F013 - approval for gas and dust applications. F014 - F016 or even more advanced F110 • Explosion/flame proof II 2 GD EEx d IIB T5. and higher. • Easy configuration with clear alphanumerical display. • LED backlight option. • Loop or battery powered, 8 - 24V AC/DC or 115 - 230V AC power supply. • Sensor supply 3.2 / 8.2 / 12 / 24V DC. 1 General information Signal input Introduction The F010 accepts most pulse and analog input The F010 is a local indicator to display the signals for volumetric flow or mass flow actual flow rate. The measuring and time unit measurement. The input signal type can be to be displayed are simply selected through an selected by the user in the configuration menu alfa-numerical configuration menu. No adhesive without having to adjust any sensitive labels have to be put on the outside of the mechanical dip-switches, jumpers or trimmers. -

The Spread of Hindu-Arabic Numerals in the European Tradition of Practical Mathematics (13 Th -16 Th Centuries)
Figuring Out: The Spread of Hindu-Arabic Numerals in the European Tradition of Practical Mathematics (13 th -16 th centuries) Raffaele Danna PhD Candidate Faculty of History, University of Cambridge [email protected] CWPESH no. 35 1 Abstract: The paper contributes to the literature focusing on the role of ideas, practices and human capital in pre-modern European economic development. It argues that studying the spread of Hindu- Arabic numerals among European practitioners allows to open up a perspective on a progressive transmission of useful knowledge from the commercial revolution to the early modern period. The analysis is based on an original database recording detailed information on over 1200 texts, both manuscript and printed. This database provides the most detailed reconstruction available of the European tradition of practical arithmetic from the late 13 th to the end of the 16 th century. It can be argued that this is the tradition which drove the adoption of Hindu-Arabic numerals in Europe. The dataset is analysed with statistical and spatial tools. Since the spread of these texts is grounded on inland patterns, the evidence suggests that a continuous transmission of useful knowledge may have played a role during the shift of the core of European trade from the Mediterranean to the Atlantic. 2 Introduction Given their almost universal diffusion, Hindu-Arabic numerals can easily be taken for granted. Nevertheless, for a long stretch of European history numbers have been represented using Roman numerals, as the positional numeral system reached western Europe at a relatively late stage. This paper provides new evidence to reconstruct the transition of European practitioners from Roman to Hindu-Arabic numerals.