Genome-Scale Detection of Positive Selection in Nine Primates Predicts Human-Virus Evolutionary Conflicts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CENPT (NM 025082) Human 3' UTR Clone – SC200995 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for SC200995 CENPT (NM_025082) Human 3' UTR Clone Product data: Product Type: 3' UTR Clones Product Name: CENPT (NM_025082) Human 3' UTR Clone Vector: pMirTarget (PS100062) Symbol: CENPT Synonyms: C16orf56; CENP-T; SSMGA ACCN: NM_025082 Insert Size: 140 bp Insert Sequence: >SC200995 3’UTR clone of NM_025082 The sequence shown below is from the reference sequence of NM_025082. The complete sequence of this clone may contain minor differences, such as SNPs. Blue=Stop Codon Red=Cloning site GGCAAGTTGGACGCCCGCAAGATCCGCGAGATTCTCATTAAGGCCAAGAAGGGCGGAAAGATCGCCGTG TAACAATTGGCAGAGCTCAGAATTCAAGCGATCGCC AGTGGCAACTCTGTCTTCCCTGCCCAGTAGTGGCCAGGCTTCAACACTTTCCCTGTCCCCACCTGGGGA CTCTTGCCCCCACATATTTCTCCAGGTCTCCTCCCCACCCCCCCAGCATCAATAAAGTGTCATAAACAG AA ACGCGTAAGCGGCCGCGGCATCTAGATTCGAAGAAAATGACCGACCAAGCGACGCCCAACCTGCCATCA CGAGATTTCGATTCCACCGCCGCCTTCTATGAAAGG Restriction Sites: SgfI-MluI OTI Disclaimer: Our molecular clone sequence data has been matched to the sequence identifier above as a point of reference. Note that the complete sequence of this clone is largely the same as the reference sequence but may contain minor differences , e.g., single nucleotide polymorphisms (SNPs). RefSeq: NM_025082.4 Summary: The centromere is a specialized chromatin domain, present throughout the cell cycle, that acts as a platform on which the transient assembly of the kinetochore occurs during mitosis. All active centromeres are characterized by the presence of long arrays of nucleosomes in which CENPA (MIM 117139) replaces histone H3 (see MIM 601128). CENPT is an additional factor required for centromere assembly (Foltz et al., 2006 [PubMed 16622419]).[supplied by OMIM, Mar 2008] Locus ID: 80152 This product is to be used for laboratory only. Not for diagnostic or therapeutic use. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

PDF Output of CLIC (Clustering by Inferred Co-Expression)
PDF Output of CLIC (clustering by inferred co-expression) Dataset: Num of genes in input gene set: 13 Total number of genes: 16493 CLIC PDF output has three sections: 1) Overview of Co-Expression Modules (CEMs) Heatmap shows pairwise correlations between all genes in the input query gene set. Red lines shows the partition of input genes into CEMs, ordered by CEM strength. Each row shows one gene, and the brightness of squares indicates its correlations with other genes. Gene symbols are shown at left side and on the top of the heatmap. 2) Details of each CEM and its expansion CEM+ Top panel shows the posterior selection probability (dataset weights) for top GEO series datasets. Bottom panel shows the CEM genes (blue rows) as well as expanded CEM+ genes (green rows). Each column is one GEO series dataset, sorted by their posterior probability of being selected. The brightness of squares indicates the gene's correlations with CEM genes in the corresponding dataset. CEM+ includes genes that co-express with CEM genes in high-weight datasets, measured by LLR score. 3) Details of each GEO series dataset and its expression profile: Top panel shows the detailed information (e.g. title, summary) for the GEO series dataset. Bottom panel shows the background distribution and the expression profile for CEM genes in this dataset. Overview of Co-Expression Modules (CEMs) with Dataset Weighting Scale of average Pearson correlations Num of Genes in Query Geneset: 13. Num of CEMs: 1. 0.0 0.2 0.4 0.6 0.8 1.0 Cenpk Cenph Cenpp Cenpu Cenpn Cenpq Cenpl Apitd1 -
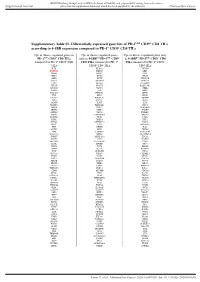
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

1 AGING Supplementary Table 2
SUPPLEMENTARY TABLES Supplementary Table 1. Details of the eight domain chains of KIAA0101. Serial IDENTITY MAX IN COMP- INTERFACE ID POSITION RESOLUTION EXPERIMENT TYPE number START STOP SCORE IDENTITY LEX WITH CAVITY A 4D2G_D 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ B 4D2G_E 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ C 6EHT_D 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ D 6EHT_E 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ E 6GWS_D 41-72 41 72 100 100 3.2Å PCNA X-RAY DIFFRACTION √ F 6GWS_E 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ G 6GWS_F 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ H 6IIW_B 2-11 2 11 100 100 1.699Å UHRF1 X-RAY DIFFRACTION √ www.aging-us.com 1 AGING Supplementary Table 2. Significantly enriched gene ontology (GO) annotations (cellular components) of KIAA0101 in lung adenocarcinoma (LinkedOmics). Leading Description FDR Leading Edge Gene EdgeNum RAD51, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, CENPW, HJURP, NDC80, CDCA5, NCAPH, BUB1, ZWILCH, CENPK, KIF2C, AURKA, CENPN, TOP2A, CENPM, PLK1, ERCC6L, CDT1, CHEK1, SPAG5, CENPH, condensed 66 0 SPC24, NUP37, BLM, CENPE, BUB3, CDK2, FANCD2, CENPO, CENPF, BRCA1, DSN1, chromosome MKI67, NCAPG2, H2AFX, HMGB2, SUV39H1, CBX3, TUBG1, KNTC1, PPP1CC, SMC2, BANF1, NCAPD2, SKA2, NUP107, BRCA2, NUP85, ITGB3BP, SYCE2, TOPBP1, DMC1, SMC4, INCENP. RAD51, OIP5, CDK1, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, ESCO2, CENPW, HJURP, TTK, NDC80, CDCA5, BUB1, ZWILCH, CENPK, KIF2C, AURKA, DSCC1, CENPN, CDCA8, CENPM, PLK1, MCM6, ERCC6L, CDT1, HELLS, CHEK1, SPAG5, CENPH, PCNA, SPC24, CENPI, NUP37, FEN1, chromosomal 94 0 CENPL, BLM, KIF18A, CENPE, MCM4, BUB3, SUV39H2, MCM2, CDK2, PIF1, DNA2, region CENPO, CENPF, CHEK2, DSN1, H2AFX, MCM7, SUV39H1, MTBP, CBX3, RECQL4, KNTC1, PPP1CC, CENPP, CENPQ, PTGES3, NCAPD2, DYNLL1, SKA2, HAT1, NUP107, MCM5, MCM3, MSH2, BRCA2, NUP85, SSB, ITGB3BP, DMC1, INCENP, THOC3, XPO1, APEX1, XRCC5, KIF22, DCLRE1A, SEH1L, XRCC3, NSMCE2, RAD21. -

CSE642 Final Version
Eindhoven University of Technology MASTER Dimensionality reduction of gene expression data Arts, S. Award date: 2018 Link to publication Disclaimer This document contains a student thesis (bachelor's or master's), as authored by a student at Eindhoven University of Technology. Student theses are made available in the TU/e repository upon obtaining the required degree. The grade received is not published on the document as presented in the repository. The required complexity or quality of research of student theses may vary by program, and the required minimum study period may vary in duration. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain Eindhoven University of Technology MASTER THESIS Dimensionality Reduction of Gene Expression Data Author: S. (Sako) Arts Daily Supervisor: dr. V. (Vlado) Menkovski Graduation Committee: dr. V. (Vlado) Menkovski dr. D.C. (Decebal) Mocanu dr. N. (Nikolay) Yakovets May 16, 2018 v1.0 Abstract The focus of this thesis is dimensionality reduction of gene expression data. I propose and test a framework that deploys linear prediction algorithms resulting in a reduced set of selected genes relevant to a specified case. Abstract In cancer research there is a large need to automate parts of the process of diagnosis, this is mainly to reduce cost, make it faster and more accurate. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Greg's Awesome Thesis
Analysis of alignment error and sitewise constraint in mammalian comparative genomics Gregory Jordan European Bioinformatics Institute University of Cambridge A dissertation submitted for the degree of Doctor of Philosophy November 30, 2011 To my parents, who kept us thinking and playing This dissertation is the result of my own work and includes nothing which is the out- come of work done in collaboration except where specifically indicated in the text and acknowledgements. This dissertation is not substantially the same as any I have submitted for a degree, diploma or other qualification at any other university, and no part has already been, or is currently being submitted for any degree, diploma or other qualification. This dissertation does not exceed the specified length limit of 60,000 words as defined by the Biology Degree Committee. November 30, 2011 Gregory Jordan ii Analysis of alignment error and sitewise constraint in mammalian comparative genomics Summary Gregory Jordan November 30, 2011 Darwin College Insight into the evolution of protein-coding genes can be gained from the use of phylogenetic codon models. Recently sequenced mammalian genomes and powerful analysis methods developed over the past decade provide the potential to globally measure the impact of natural selection on pro- tein sequences at a fine scale. The detection of positive selection in particular is of great interest, with relevance to the study of host-parasite conflicts, immune system evolution and adaptive dif- ferences between species. This thesis examines the performance of methods for detecting positive selection first with a series of simulation experiments, and then with two empirical studies in mammals and primates. -

Looking for Missing Proteins in the Proteome Of
Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, Christophe Bruley, Charlotte Macron, Anne Gonzalez de Peredo, Yohann Coute, Karima Chaoui, et al. To cite this version: Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, et al.. Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update. Journal of Proteome Research, American Chemical Society, 2016, 15 (11), pp.3998-4019. 10.1021/acs.jproteome.6b00400. hal-02191502 HAL Id: hal-02191502 https://hal.archives-ouvertes.fr/hal-02191502 Submitted on 19 Mar 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Journal of Proteome Research 1 2 3 Looking for missing proteins in the proteome of human spermatozoa: an 4 update 5 6 Yves Vandenbrouck1,2,3,#,§, Lydie Lane4,5,#, Christine Carapito6, Paula Duek5, Karine Rondel7, 7 Christophe Bruley1,2,3, Charlotte Macron6, Anne Gonzalez de Peredo8, Yohann Couté1,2,3, 8 Karima Chaoui8, Emmanuelle Com7, Alain Gateau5, AnneMarie Hesse1,2,3, Marlene 9 Marcellin8, Loren Méar7, Emmanuelle MoutonBarbosa8, Thibault Robin9, Odile Burlet- 10 Schiltz8, Sarah Cianferani6, Myriam Ferro1,2,3, Thomas Fréour10,11, Cecilia Lindskog12,Jérôme 11 1,2,3 7,§ 12 Garin , Charles Pineau . -

Cellular and Molecular Aspects of the Response of the Testis to Nutrition In
Cellular and molecular aspects of the response of the testis to nutrition in sexually mature sheep Yongjuan Guan 21004548 This thesis is presented for the degree of Doctor of Philosophy of The University of Western Australia School of Animal Biology Institute of Agriculture March 2015 Declaration Declaration The work presented in this thesis is original work of the author, and none of the material in this thesis has been submitted either in full, or part, for a degree at this university or any other universities or institutions before. The experimental designs and manuscript preparation were carried out by myself after discussion with my supervisors Prof Graeme Martin, A/Prof Irek Malecki and Dr Penny Hawken. Yongjuan Guan March 2015 1 Contents Contents Summary ....................................................................................................................................... 4 Acknowledgements ....................................................................................................................... 8 Publications ................................................................................................................................. 10 Chapter 1: General Introduction ................................................................................................. 12 Chapter 2: Literature Review ...................................................................................................... 16 2.1 Male reproduction ............................................................................................................ -

How Does SUMO Participate in Spindle Organization?
cells Review How Does SUMO Participate in Spindle Organization? Ariane Abrieu * and Dimitris Liakopoulos * CRBM, CNRS UMR5237, Université de Montpellier, 1919 route de Mende, 34090 Montpellier, France * Correspondence: [email protected] (A.A.); [email protected] (D.L.) Received: 5 July 2019; Accepted: 30 July 2019; Published: 31 July 2019 Abstract: The ubiquitin-like protein SUMO is a regulator involved in most cellular mechanisms. Recent studies have discovered new modes of function for this protein. Of particular interest is the ability of SUMO to organize proteins in larger assemblies, as well as the role of SUMO-dependent ubiquitylation in their disassembly. These mechanisms have been largely described in the context of DNA repair, transcriptional regulation, or signaling, while much less is known on how SUMO facilitates organization of microtubule-dependent processes during mitosis. Remarkably however, SUMO has been known for a long time to modify kinetochore proteins, while more recently, extensive proteomic screens have identified a large number of microtubule- and spindle-associated proteins that are SUMOylated. The aim of this review is to focus on the possible role of SUMOylation in organization of the spindle and kinetochore complexes. We summarize mitotic and microtubule/spindle-associated proteins that have been identified as SUMO conjugates and present examples regarding their regulation by SUMO. Moreover, we discuss the possible contribution of SUMOylation in organization of larger protein assemblies on the spindle, as well as the role of SUMO-targeted ubiquitylation in control of kinetochore assembly and function. Finally, we propose future directions regarding the study of SUMOylation in regulation of spindle organization and examine the potential of SUMO and SUMO-mediated degradation as target for antimitotic-based therapies. -

Mouse Ssmem1 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Ssmem1 Knockout Project (CRISPR/Cas9) Objective: To create a Ssmem1 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Ssmem1 gene (NCBI Reference Sequence: NM_027073 ; Ensembl: ENSMUSG00000029784 ) is located on Mouse chromosome 6. 3 exons are identified, with the ATG start codon in exon 1 and the TGA stop codon in exon 3 (Transcript: ENSMUST00000031797). Exon 2~3 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 2 starts from about 6.8% of the coding region. Exon 2~3 covers 93.37% of the coding region. The size of effective KO region: ~2401 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 Legends Exon of mouse Ssmem1 Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. Tandem repeats are found in the dot plot matrix. The gRNA site is selected outside of these tandem repeats. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of stop codon is aligned with itself to determine if there are tandem repeats.