Looking for Missing Proteins in the Proteome Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Frontiers in Integrative Genomics and Translational Bioinformatics
BioMed Research International Frontiers in Integrative Genomics and Translational Bioinformatics Guest Editors: Zhongming Zhao, Victor X. Jin, Yufei Huang, Chittibabu Guda, and Jianhua Ruan Frontiers in Integrative Genomics and Translational Bioinformatics BioMed Research International Frontiers in Integrative Genomics and Translational Bioinformatics Guest Editors: Zhongming Zhao, Victor X. Jin, Yufei Huang, Chittibabu Guda, and Jianhua Ruan Copyright © òýÔ Hindawi Publishing Corporation. All rights reserved. is is a special issue published in “BioMed Research International.” All articles are open access articles distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Contents Frontiers in Integrative Genomics and Translational Bioinformatics, Zhongming Zhao, Victor X. Jin, Yufei Huang, Chittibabu Guda, and Jianhua Ruan Volume òýÔ , Article ID Þò ¥ÀÔ, ç pages Building Integrated Ontological Knowledge Structures with Ecient Approximation Algorithms, Yang Xiang and Sarath Chandra Janga Volume òýÔ , Article ID ýÔ ò, Ô¥ pages Predicting Drug-Target Interactions via Within-Score and Between-Score, Jian-Yu Shi, Zun Liu, Hui Yu, and Yong-Jun Li Volume òýÔ , Article ID ç ýÀç, À pages RNAseq by Total RNA Library Identies Additional RNAs Compared to Poly(A) RNA Library, Yan Guo, Shilin Zhao, Quanhu Sheng, Mingsheng Guo, Brian Lehmann, Jennifer Pietenpol, David C. Samuels, and Yu Shyr Volume òýÔ , Article ID âòÔçý, À pages Construction of Pancreatic Cancer Classier Based on SVM Optimized by Improved FOA, Huiyan Jiang, Di Zhao, Ruiping Zheng, and Xiaoqi Ma Volume òýÔ , Article ID ÞÔýòç, Ôò pages OperomeDB: A Database of Condition-Specic Transcription Units in Prokaryotic Genomes, Kashish Chetal and Sarath Chandra Janga Volume òýÔ , Article ID çÔòÔÞ, Ôý pages How to Choose In Vitro Systems to Predict In Vivo Drug Clearance: A System Pharmacology Perspective, Lei Wang, ChienWei Chiang, Hong Liang, Hengyi Wu, Weixing Feng, Sara K. -

Number 2 February 2014
Atlas of Genetics and Cytogenetics in Oncology and Haematology OPEN ACCESS JOURNAL INIST -CNRS Volume 18 - Number 2 February 2014 The PDF version of the Atlas of Genetics and Cytogenetics in Oncology and Haematology is a reissue of the original articles published in collaboration with the Institute for Scientific and Technical Information (INstitut de l’Information Scientifique et Technique - INIST) of the French National Center for Scientific Research (CNRS) on its electronic publishing platform I-Revues. Online and PDF versions of the Atlas of Genetics and Cytogenetics in Oncology and Haematology are hosted by INIST-CNRS. Atlas of Genetics and Cytogenetics in Oncology and Haematology OPEN ACCESS JOURNAL INIST -CNRS Scope The Atlas of Genetics and Cytogenetics in Oncology and Haematology is a peer reviewed on-line journal in open access, devoted to genes, cytogenetics, and clinical entities in cancer, and cancer-prone diseases. It presents structured review articles (“cards”) on genes, leukaemias, solid tumours, cancer-prone diseases, and also more traditional review articles (“deep insights”) on the above subjects and on surrounding topics. It also present case reports in hematology and educational items in the various related topics for students in Medicine and in Sciences. Editorial correspondance Jean-Loup Huret Genetics, Department of Medical Information, University Hospital F-86021 Poitiers, France tel +33 5 49 44 45 46 or +33 5 49 45 47 67 [email protected] or [email protected] Staff Mohammad Ahmad, Mélanie Arsaban, Marie-Christine Jacquemot-Perbal, Vanessa Le Berre, Anne Malo, Carol Moreau, Catherine Morel-Pair, Laurent Rassinoux, Alain Zasadzinski. Philippe Dessen is the Database Director, and Alain Bernheim the Chairman of the on-line version (Gustave Roussy Institute – Villejuif – France). -

Autism Multiplex Family with 16P11.2P12.2 Microduplication Syndrome in Monozygotic Twins and Distal 16P11.2 Deletion in Their Brother
European Journal of Human Genetics (2012) 20, 540–546 & 2012 Macmillan Publishers Limited All rights reserved 1018-4813/12 www.nature.com/ejhg ARTICLE Autism multiplex family with 16p11.2p12.2 microduplication syndrome in monozygotic twins and distal 16p11.2 deletion in their brother Anne-Claude Tabet1,2,3,4, Marion Pilorge2,3,4, Richard Delorme5,6,Fre´de´rique Amsellem5,6, Jean-Marc Pinard7, Marion Leboyer6,8,9, Alain Verloes10, Brigitte Benzacken1,11,12 and Catalina Betancur*,2,3,4 The pericentromeric region of chromosome 16p is rich in segmental duplications that predispose to rearrangements through non-allelic homologous recombination. Several recurrent copy number variations have been described recently in chromosome 16p. 16p11.2 rearrangements (29.5–30.1 Mb) are associated with autism, intellectual disability (ID) and other neurodevelopmental disorders. Another recognizable but less common microdeletion syndrome in 16p11.2p12.2 (21.4 to 28.5–30.1 Mb) has been described in six individuals with ID, whereas apparently reciprocal duplications, studied by standard cytogenetic and fluorescence in situ hybridization techniques, have been reported in three patients with autism spectrum disorders. Here, we report a multiplex family with three boys affected with autism, including two monozygotic twins carrying a de novo 16p11.2p12.2 duplication of 8.95 Mb (21.28–30.23 Mb) characterized by single-nucleotide polymorphism array, encompassing both the 16p11.2 and 16p11.2p12.2 regions. The twins exhibited autism, severe ID, and dysmorphic features, including a triangular face, deep-set eyes, large and prominent nasal bridge, and tall, slender build. The eldest brother presented with autism, mild ID, early-onset obesity and normal craniofacial features, and carried a smaller, overlapping 16p11.2 microdeletion of 847 kb (28.40–29.25 Mb), inherited from his apparently healthy father. -

Manual Annotation and Analysis of the Defensin Gene Cluster in the C57BL
BMC Genomics BioMed Central Research article Open Access Manual annotation and analysis of the defensin gene cluster in the C57BL/6J mouse reference genome Clara Amid*†1, Linda M Rehaume*†2, Kelly L Brown2,3, James GR Gilbert1, Gordon Dougan1, Robert EW Hancock2 and Jennifer L Harrow1 Address: 1Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Hinxton, Cambridgeshire CB10 1SA, UK, 2University of British Columbia, Centre for Microbial Disease & Immunity Research, 2259 Lower Mall, Vancouver, BC, V6T 1Z4, Canada and 3Department of Rheumatology and Inflammation Research, Göteborg University, Guldhedsgatan 10, S-413 46 Göteborg, Sweden Email: Clara Amid* - [email protected]; Linda M Rehaume* - [email protected]; Kelly L Brown - [email protected]; James GR Gilbert - [email protected]; Gordon Dougan - [email protected]; Robert EW Hancock - [email protected]; Jennifer L Harrow - [email protected] * Corresponding authors †Equal contributors Published: 15 December 2009 Received: 15 May 2009 Accepted: 15 December 2009 BMC Genomics 2009, 10:606 doi:10.1186/1471-2164-10-606 This article is available from: http://www.biomedcentral.com/1471-2164/10/606 © 2009 Amid et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Host defense peptides are a critical component of the innate immune system. Human alpha- and beta-defensin genes are subject to copy number variation (CNV) and historically the organization of mouse alpha-defensin genes has been poorly defined. -

The Molecular Karyotype of 25 Clinical-Grade Human Embryonic Stem Cell Lines Received: 07 August 2015 1 1 2 3,4 Accepted: 27 October 2015 Maurice A
www.nature.com/scientificreports OPEN The Molecular Karyotype of 25 Clinical-Grade Human Embryonic Stem Cell Lines Received: 07 August 2015 1 1 2 3,4 Accepted: 27 October 2015 Maurice A. Canham , Amy Van Deusen , Daniel R. Brison , Paul A. De Sousa , 3 5 6 5 7 Published: 26 November 2015 Janet Downie , Liani Devito , Zoe A. Hewitt , Dusko Ilic , Susan J. Kimber , Harry D. Moore6, Helen Murray3 & Tilo Kunath1 The application of human embryonic stem cell (hESC) derivatives to regenerative medicine is now becoming a reality. Although the vast majority of hESC lines have been derived for research purposes only, about 50 lines have been established under Good Manufacturing Practice (GMP) conditions. Cell types differentiated from these designated lines may be used as a cell therapy to treat macular degeneration, Parkinson’s, Huntington’s, diabetes, osteoarthritis and other degenerative conditions. It is essential to know the genetic stability of the hESC lines before progressing to clinical trials. We evaluated the molecular karyotype of 25 clinical-grade hESC lines by whole-genome single nucleotide polymorphism (SNP) array analysis. A total of 15 unique copy number variations (CNVs) greater than 100 kb were detected, most of which were found to be naturally occurring in the human population and none were associated with culture adaptation. In addition, three copy-neutral loss of heterozygosity (CN-LOH) regions greater than 1 Mb were observed and all were relatively small and interstitial suggesting they did not arise in culture. The large number of available clinical-grade hESC lines with defined molecular karyotypes provides a substantial starting platform from which the development of pre-clinical and clinical trials in regenerative medicine can be realised. -

List of Genes Associated with Sudden Cardiac Death (Scdgseta) Gene
List of genes associated with sudden cardiac death (SCDgseta) mRNA expression in normal human heart Entrez_I Gene symbol Gene name Uniprot ID Uniprot name fromb D GTEx BioGPS SAGE c d e ATP-binding cassette subfamily B ABCB1 P08183 MDR1_HUMAN 5243 √ √ member 1 ATP-binding cassette subfamily C ABCC9 O60706 ABCC9_HUMAN 10060 √ √ member 9 ACE Angiotensin I–converting enzyme P12821 ACE_HUMAN 1636 √ √ ACE2 Angiotensin I–converting enzyme 2 Q9BYF1 ACE2_HUMAN 59272 √ √ Acetylcholinesterase (Cartwright ACHE P22303 ACES_HUMAN 43 √ √ blood group) ACTC1 Actin, alpha, cardiac muscle 1 P68032 ACTC_HUMAN 70 √ √ ACTN2 Actinin alpha 2 P35609 ACTN2_HUMAN 88 √ √ √ ACTN4 Actinin alpha 4 O43707 ACTN4_HUMAN 81 √ √ √ ADRA2B Adrenoceptor alpha 2B P18089 ADA2B_HUMAN 151 √ √ AGT Angiotensinogen P01019 ANGT_HUMAN 183 √ √ √ AGTR1 Angiotensin II receptor type 1 P30556 AGTR1_HUMAN 185 √ √ AGTR2 Angiotensin II receptor type 2 P50052 AGTR2_HUMAN 186 √ √ AKAP9 A-kinase anchoring protein 9 Q99996 AKAP9_HUMAN 10142 √ √ √ ANK2/ANKB/ANKYRI Ankyrin 2 Q01484 ANK2_HUMAN 287 √ √ √ N B ANKRD1 Ankyrin repeat domain 1 Q15327 ANKR1_HUMAN 27063 √ √ √ ANKRD9 Ankyrin repeat domain 9 Q96BM1 ANKR9_HUMAN 122416 √ √ ARHGAP24 Rho GTPase–activating protein 24 Q8N264 RHG24_HUMAN 83478 √ √ ATPase Na+/K+–transporting ATP1B1 P05026 AT1B1_HUMAN 481 √ √ √ subunit beta 1 ATPase sarcoplasmic/endoplasmic ATP2A2 P16615 AT2A2_HUMAN 488 √ √ √ reticulum Ca2+ transporting 2 AZIN1 Antizyme inhibitor 1 O14977 AZIN1_HUMAN 51582 √ √ √ UDP-GlcNAc: betaGal B3GNT7 beta-1,3-N-acetylglucosaminyltransfe Q8NFL0 -

Dual Proteome-Scale Networks Reveal Cell-Specific Remodeling of the Human Interactome
bioRxiv preprint doi: https://doi.org/10.1101/2020.01.19.905109; this version posted January 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Dual Proteome-scale Networks Reveal Cell-specific Remodeling of the Human Interactome Edward L. Huttlin1*, Raphael J. Bruckner1,3, Jose Navarrete-Perea1, Joe R. Cannon1,4, Kurt Baltier1,5, Fana Gebreab1, Melanie P. Gygi1, Alexandra Thornock1, Gabriela Zarraga1,6, Stanley Tam1,7, John Szpyt1, Alexandra Panov1, Hannah Parzen1,8, Sipei Fu1, Arvene Golbazi1, Eila Maenpaa1, Keegan Stricker1, Sanjukta Guha Thakurta1, Ramin Rad1, Joshua Pan2, David P. Nusinow1, Joao A. Paulo1, Devin K. Schweppe1, Laura Pontano Vaites1, J. Wade Harper1*, Steven P. Gygi1*# 1Department of Cell Biology, Harvard Medical School, Boston, MA, 02115, USA. 2Broad Institute, Cambridge, MA, 02142, USA. 3Present address: ICCB-Longwood Screening Facility, Harvard Medical School, Boston, MA, 02115, USA. 4Present address: Merck, West Point, PA, 19486, USA. 5Present address: IQ Proteomics, Cambridge, MA, 02139, USA. 6Present address: Vor Biopharma, Cambridge, MA, 02142, USA. 7Present address: Rubius Therapeutics, Cambridge, MA, 02139, USA. 8Present address: RPS North America, South Kingstown, RI, 02879, USA. *Correspondence: [email protected] (E.L.H.), [email protected] (J.W.H.), [email protected] (S.P.G.) #Lead Contact: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2020.01.19.905109; this version posted January 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
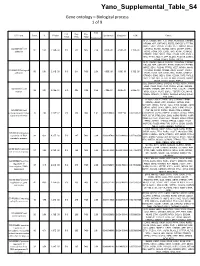
Supplemental Tables4.Pdf
Yano_Supplemental_Table_S4 Gene ontology – Biological process 1 of 9 Fold List Pop Pop GO Term Count % PValue Bonferroni Benjamini FDR Genes Total Hits Total Enrichment DLC1, CADM1, NELL2, CLSTN1, PCDHGA8, CTNNB1, NRCAM, APP, CNTNAP2, FERT2, RAPGEF1, PTPRM, MPDZ, SDK1, PCDH9, PTPRS, VEZT, NRXN1, MYH9, GO:0007155~cell CTNNA2, NCAM1, NCAM2, DDR1, LSAMP, CNTN1, 50 5.61 2.14E-08 510 311 7436 2.34 4.50E-05 4.50E-05 3.70E-05 adhesion ROR2, VCAN, DST, LIMS1, TNC, ASTN1, CTNND2, CTNND1, CDH2, NEO1, CDH4, CD24A, FAT3, PVRL3, TRO, TTYH1, MLLT4, LPP, NLGN1, PCDH19, LAMA1, ITGA9, CDH13, CDON, PSPC1 DLC1, CADM1, NELL2, CLSTN1, PCDHGA8, CTNNB1, NRCAM, APP, CNTNAP2, FERT2, RAPGEF1, PTPRM, MPDZ, SDK1, PCDH9, PTPRS, VEZT, NRXN1, MYH9, GO:0022610~biological CTNNA2, NCAM1, NCAM2, DDR1, LSAMP, CNTN1, 50 5.61 2.14E-08 510 311 7436 2.34 4.50E-05 4.50E-05 3.70E-05 adhesion ROR2, VCAN, DST, LIMS1, TNC, ASTN1, CTNND2, CTNND1, CDH2, NEO1, CDH4, CD24A, FAT3, PVRL3, TRO, TTYH1, MLLT4, LPP, NLGN1, PCDH19, LAMA1, ITGA9, CDH13, CDON, PSPC1 DCC, ENAH, PLXNA2, CAPZA2, ATP5B, ASTN1, PAX6, ZEB2, CDH2, CDH4, GLI3, CD24A, EPHB1, NRCAM, GO:0006928~cell CTTNBP2, EDNRB, APP, PTK2, ETV1, CLASP2, STRBP, 36 4.04 3.46E-07 510 205 7436 2.56 7.28E-04 3.64E-04 5.98E-04 motion NRG1, DCLK1, PLAT, SGPL1, TGFBR1, EVL, MYH9, YWHAE, NCKAP1, CTNNA2, SEMA6A, EPHA4, NDEL1, FYN, LRP6 PLXNA2, ADCY5, PAX6, GLI3, CTNNB1, LPHN2, EDNRB, LPHN3, APP, CSNK2A1, GPR45, NRG1, RAPGEF1, WWOX, SGPL1, TLE4, SPEN, NCAM1, DDR1, GRB10, GRM3, GNAQ, HIPK1, GNB1, HIPK2, PYGO1, GO:0007166~cell RNF138, ROR2, CNTN1, -
DLC1 Expression Is Reduced in Human Cutaneous Melanoma And
Modern Pathology (2014) 27, 1203–1211 & 2014 USCAP, Inc. All rights reserved 0893-3952/14 $32.00 1203 DLC1 expression is reduced in human cutaneous melanoma and correlates with patient survival Cecilia Sjoestroem1, Shahram Khosravi1, Yabin Cheng1, Gholamreza Safaee Ardekani1, Magdalena Martinka2 and Gang Li1 1Department of Dermatology and Skin Science, Vancouver Coastal Health Research Institute, University of British Columbia, Vancouver, BC, Canada and 2Department of Pathology, Vancouver General Hospital, Vancouver, BC, Canada Deleted in Liver Cancer-1 (DLC1) is a Rho-GTPase-activating protein known to be downregulated and function as a tumor suppressor in numerous solid and hematological cancers. Its expression status in melanoma is currently unknown however, prompting us to examine this. Using immunohistochemistry and tissue microarrays containing a large set of melanocytic lesions (n ¼ 539), we examined the expression profile of DLC1 in melanoma progression, as well as the association between DLC1 and patient survival. We detected both cytoplasmic and nuclear DLC1 expression, and found that whereas cytoplasmic DLC1 was significantly downregulated in metastatic melanoma compared with nevi and primary melanoma, nuclear DLC1 expression was significantly down in primary melanoma compared with nevi, and then further down in metastatic melanoma. Loss of cytoplasmic DLC1 was significantly associated with poorer overall and disease-specific 5-year survival rates of all melanoma (Po0.001 and P ¼ 0.001, respectively) and metastatic melanoma patients (P ¼ 0.020 and 0.008, respectively), and similar results were seen for nuclear DLC1 (Po0.001 for both overall and disease-specific survival for all melanoma patients, and P ¼ 0.004 for metastatic melanoma patients). -

Investigation of Candidate Genes and Mechanisms Underlying Obesity
Prashanth et al. BMC Endocrine Disorders (2021) 21:80 https://doi.org/10.1186/s12902-021-00718-5 RESEARCH ARTICLE Open Access Investigation of candidate genes and mechanisms underlying obesity associated type 2 diabetes mellitus using bioinformatics analysis and screening of small drug molecules G. Prashanth1 , Basavaraj Vastrad2 , Anandkumar Tengli3 , Chanabasayya Vastrad4* and Iranna Kotturshetti5 Abstract Background: Obesity associated type 2 diabetes mellitus is a metabolic disorder ; however, the etiology of obesity associated type 2 diabetes mellitus remains largely unknown. There is an urgent need to further broaden the understanding of the molecular mechanism associated in obesity associated type 2 diabetes mellitus. Methods: To screen the differentially expressed genes (DEGs) that might play essential roles in obesity associated type 2 diabetes mellitus, the publicly available expression profiling by high throughput sequencing data (GSE143319) was downloaded and screened for DEGs. Then, Gene Ontology (GO) and REACTOME pathway enrichment analysis were performed. The protein - protein interaction network, miRNA - target genes regulatory network and TF-target gene regulatory network were constructed and analyzed for identification of hub and target genes. The hub genes were validated by receiver operating characteristic (ROC) curve analysis and RT- PCR analysis. Finally, a molecular docking study was performed on over expressed proteins to predict the target small drug molecules. Results: A total of 820 DEGs were identified between -

Copy Number Variation in Fetal Alcohol Spectrum Disorder
Biochemistry and Cell Biology Copy number variation in fetal alcohol spectrum disorder Journal: Biochemistry and Cell Biology Manuscript ID bcb-2017-0241.R1 Manuscript Type: Article Date Submitted by the Author: 09-Nov-2017 Complete List of Authors: Zarrei, Mehdi; The Centre for Applied Genomics Hicks, Geoffrey G.; University of Manitoba College of Medicine, Regenerative Medicine Reynolds, James N.; Queen's University School of Medicine, Biomedical and Molecular SciencesDraft Thiruvahindrapuram, Bhooma; The Centre for Applied Genomics Engchuan, Worrawat; Hospital for Sick Children SickKids Learning Institute Pind, Molly; University of Manitoba College of Medicine, Regenerative Medicine Lamoureux, Sylvia; The Centre for Applied Genomics Wei, John; The Centre for Applied Genomics Wang, Zhouzhi; The Centre for Applied Genomics Marshall, Christian R.; The Centre for Applied Genomics Wintle, Richard; The Centre for Applied Genomics Chudley, Albert; University of Manitoba Scherer, Stephen W.; The Centre for Applied Genomics Is the invited manuscript for consideration in a Special Fetal Alcohol Spectrum Disorder Issue? : Keyword: Fetal alcohol spectrum disorder, FASD, copy number variations, CNV https://mc06.manuscriptcentral.com/bcb-pubs Page 1 of 354 Biochemistry and Cell Biology 1 Copy number variation in fetal alcohol spectrum disorder 2 Mehdi Zarrei,a Geoffrey G. Hicks,b James N. Reynolds,c,d Bhooma Thiruvahindrapuram,a 3 Worrawat Engchuan,a Molly Pind,b Sylvia Lamoureux,a John Wei,a Zhouzhi Wang,a Christian R. 4 Marshall,a Richard F. Wintle,a Albert E. Chudleye,f and Stephen W. Scherer,a,g 5 aThe Centre for Applied Genomics and Program in Genetics and Genome Biology, The Hospital 6 for Sick Children, Toronto, Ontario, Canada 7 bRegenerative Medicine Program, University of Manitoba, Winnipeg, Canada 8 cCentre for Neuroscience Studies, Queen's University, Kingston, Ontario, Canada.