Trend Trend of Technology หนึ่งในความท้าทายที่ส าคัญที่สุดขอ
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Titan X Amd 1.2 V4 Ig 20210319
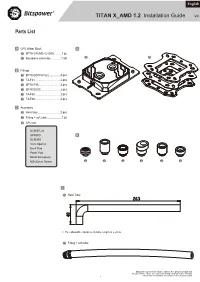
English TITAN X_AMD 1.2 Installation Guide V4 Parts List A CPU Water Block A A-1 BPTA-CPUMS-V2-SKA ..........1 pc A-1 A-2 A-2 Backplane assembly ..............1 set B Fittings B-1 BPTA-DOTFH1622 ...............4 pcs B-2 TA-F61 ...................................2 pcs B-3 BPTA-F95 ..............................2 pcs B-4 BP-RIGOS5 ...........................2 pcs B-5 TA-F60 ..................................2 pcs B-6 TA-F40 ..................................2 pcs C Accessory C-1 Hard tube ..............................2 pcs C-2 Fitting + soft tube ....................1 pc C-3 CPU set SCM3FL20 SPRING B SCM3F6 1mm Spacer Back Pad Paste Pad Metal Backplane M3x32mm Screw B-1 B-2 B-3 B-4 B-5 B-6 C C-1 Hard Tube ※ The allowable variance in tube length is ± 2mm C-2 Fitting + soft tube Bitspower reserves the right to change the product design and interpretations. These are subject to change without notice. Product colors and accessories are based on the actual product. — 1 — I. AMD Motherboard system 54 AMD SOCKET 939 / 754 / 940 IN 48 AMD SOCKET AM4 AMD SOCKET AM3 / AM3+ AMD SOCKET AM2 / AM2+ AMD SOCKET FM1 / FM2+ Bitspower Fan and DRGB RF Remote Controller Hub (Not included) are now available at microcenter.com DRGB PIN on Motherboard or other equipment. 96 90 BPTA-RFCHUB The CPU water block has a DRGB cable, which AMD SOCKET AM4 AMD SOCKET AM3 AM3+ / AMD SOCKET AM2 AM2+ / AMD SOCKET FM1 / FM2+ can be connected to the DRGB extension cable of the radiator fans. Fan and DRGB RF Remote Motherboard Controller Hub (Not included) OUT DRGB LED Do not over-tighten the thumb screws Installation (SCM3FL20). -

SOCKETS (Zocalos)
Instituto ITES Armado, Reparación y Mantención PC. Prof: Vladimir Zúñiga C. SOCKETS (zocalos) LGA 775 Especificaciones Tipo LGA Factores de forma Flip-chip land grid array del chip Contactos 775 Protocolo del FSB Quad-Pumped Frecuencia del 533 MT/s, 800 MT/s, 1066 FSB MT/s, 1333 MT/s, 1600 MT/s Dimesiones del 1.47 × 1.47 inches[1] procesador Procesadores Intel Pentium 4 (2.66 - 3.80 GHz) Intel Celeron D (2.53 - 3.60 GHz ) Intel Pentium 4 Extreme Edition (3.20 - 3.73 GHz) Intel Pentium D (2.66 - 3.60 GHz) Pentium Dual-Core (1.40 - 2.80 GHz) Intel Core 2 Duo (1.60 - 3.33 GHz) Intel Core 2 Extreme (2.66 - 3.20 GHz) Intel Core 2 Quad (2.33 - 3.00 GHz) Intel Xeon (1.86-3.40 GHz) Intel 'Core' Celeron (1.60 - 2.40 GHz) El zócalo LGA 775, también conocido como Socket T o Socket 775, es uno de los zócalos utilizados por Intel para dar soporte a los microprocesadores Pentium 4. Entre otros aspectos, se diferencia de los anteriores 370 (para Pentium III) y del Socket 423 y 478 (para los primeros Pentium 4) en que carece de pines. Las velocidades de bus disponibles para esta arquitectura van desde 533Mhz hasta 1600MHz. Este tipo de zócalo es el "estándar" para casi todos los procesadores de consumo de Intel para equipos sobremesa y algunos portátiles. Desde los "Celeron D" hasta los "Core 2 Duo", pasando por los "Pentium D", su principal atractivo es que los procesadores para LGA 775 carecen de pines; es decir que la placa base es la que contiene los contactos para comunicarse con el procesador. -

HDAMA Rev.G User's Guide
HDAMA rev.G HDAMA User’s Guide Release Date:Jul.2005 3.02 Version: Appendix BIOS Hardware Overview Setup Install Arima ServerBoard Manual COPYRIGHTS AND DISCLAIMERS ..........................................C-I ATTENTION: READ FIRST! ...................................... C-II Overview GENERAL SAFETY PRECAUTIONS .......................................C-2 ESD PRECAUTIONS ........................................................C-2 OPERATING PRECAUTIONS ................................................C-2 ABOUT THIS USER'S MANUAL ...........................................C-3 GETTING HELP ...............................................................C-3 SERVERBOARD SPECIFICATIONS ........................................C-5 SERVERBOARD LAYOUT ...................................................C-6 SERVERBOARD MAP .......................................................C-7 I/O PORT ARRAY ............................................................C-7 Hardware Installation MAP OF JUMPERS ...........................................................C-9 JUMPER SETTINGS ........................................................C-10 INSTALLING MEMORY .....................................................C-11 RECOMMENDED MEMORY CONFIGURATIONS .......................C-13 INSTALLING THE PROCESSOR AND HEATSINK ......................C-14 MAP OF SERVERBOARD CABLE CONNECTORS ...................C-16 ATX POWER CONNECTORS ............................................C-17 FLOPPY DISK DRIVE CONNECTOR ...................................C-18 PRIMARY IDE CONNECTORS ............................................C-18 -

Cray XT and Cray XE Y Y System Overview
Crayyy XT and Cray XE System Overview Customer Documentation and Training Overview Topics • System Overview – Cabinets, Chassis, and Blades – Compute and Service Nodes – Components of a Node Opteron Processor SeaStar ASIC • Portals API Design Gemini ASIC • System Networks • Interconnection Topologies 10/18/2010 Cray Private 2 Cray XT System 10/18/2010 Cray Private 3 System Overview Y Z GigE X 10 GigE GigE SMW Fibre Channels RAID Subsystem Compute node Login node Network node Boot /Syslog/Database nodes 10/18/2010 Cray Private I/O and Metadata nodes 4 Cabinet – The cabinet contains three chassis, a blower for cooling, a power distribution unit (PDU), a control system (CRMS), and the compute and service blades (modules) – All components of the system are air cooled A blower in the bottom of the cabinet cools the blades within the cabinet • Other rack-mounted devices within the cabinet have their own internal fans for cooling – The PDU is located behind the blower in the back of the cabinet 10/18/2010 Cray Private 5 Liquid Cooled Cabinets Heat exchanger Heat exchanger (XT5-HE LC only) (LC cabinets only) 48Vdc flexible Cage 2 buses Cage 2 Cage 1 Cage 1 Cage VRMs Cage 0 Cage 0 backplane assembly Cage ID controller Interconnect 01234567 Heat exchanger network cable Cage inlet (LC cabinets only) connection air temp sensor Airflow Heat exchanger (slot 3 rail) conditioner 48Vdc shelf 3 (XT5-HE LC only) 48Vdc shelf 2 L1 controller 48Vdc shelf 1 Blower speed controller (VFD) Blooewer PDU line filter XDP temperature XDP interface & humidity sensor -

AMD Multi-Core Processors Providing Multiple Benefits for the Future
hard hat area | white paper AMD Multi-Core Processors Providing Multiple Benefits For The Future y now you probably have heard of variations this year. In 2007 the chipmakers (page 50). This month, we’ll focus on what dual- and multi-core processors. expect to introduce several multi-core AMD has planned for 2006 and beyond. B Both AMD and Intel released chips, beginning with quad-core offerings. dual-core chips in 2005, and both have We discussed Intel’s multi-core proces- Dual-Core Chips plans to release dozens more dual-core chip sors in the January 2006 issue of CPU In April 2005, AMD released its first dual-core chip aimed at the server and workstation market, the Opteron proces- Direct Connect Architecture vs. sor. There are several Opteron dual-core Legacy Systems 90nm processors ranging in clock speeds from 1.6GHz to 2.4GHz. Direct Connect Architecture lives up to its name by providing a for the past few years in its single-core chips. direct connection between the processor, the memory But now AMD has extended the use of Direct Connect Architecture to controller, and the I/O area to improve overall system connect the cores on a dual- or multi-core chip die and to connect each performance. AMD has used Direct Connect Architecture core to its memory controller. ▲ With multi-core architecture, each core on the chip has its own memory con- When using a dual-processor x86 legacy architecture, troller, which significantly improves memory performance. Using Direct Connect however, two processors then have to share the same Architecture to make a connection with the memory controller eliminates most memory control hub, which creates bottlenecks in data bottlenecks and makes multitasking easier. -

User's Manual
User’s Manual (English version) CNPS9500 Intel Pentium 4 Socket 478 CPU Intel Dual Core Pentium/Pentium 4 Socket 775 CPU AMD Sempron/AMD64 (Athlon 64 X2/Opteron/Athlon 64) Socket 754/939/940 CPU * Applies to all versions of CNPS9500. * Please read before installation. http://www.zalman.co.kr http://www.zalmanusa.com 1. Features 1) 100% copper heatsink with aerodynamically optimized “tunnel” design for maximum cooling efficiency. 2) Innovative and patented, curved heatpipe design for a heat transfer capacity of up to 6 heatpipes with just 3. 3) Optimized heatsink layout for maximum cooling efficiency with minimal materials. 4) 0.2mm ultra-slim fins for minimized weight and reduced airflow resistance. 5) Ultra quiet CNPS 92mm opaque fan with blue LEDs. 6) Aerodynamically optimized heatsink for smoother airflow and minimal noise. 7) Compatible CPUs (Refer to “7. Compatible CPUs” on page 3. for more information.) - Intel : All Dual Core Pentium CPUs (Socket 775) All Pentium 4 CPUs (Socket 775/478) - AMD : All Dual Core AMD Athlon 64 X2 CPUs (Socket 939) All AMD Sempron/AMD64 CPUs (Socket 754/939/940) 8) Adjustable fan speed controller (FAN MATE 2) enables control of noise and fan speed. 2. Specifications 1) Flower Heatsink (FHS) Spec. Model CNPS9500 Materials Pure Copper Weight(g) 530(1) Thermal Resistance Silent Mode 0.16 (°C/W ) Normal Mode 0.12 Dimensions (mm) 85(L) X 112(W) X 125(H) Dissipation Area (㎠) 3,698 2) Fan - Bearing Type : 2-Ball - Rotation Speed : 1,350RPM ± 10 % (Silent Mode) 2,600RPM ± 10 % (Low-noise Mode) - Noise (dB) : 18.0dB ± 10% (Silent Mode) - measured at 1m from noise source 27.5dB ± 10% (Low-noise mode) - measured at 1m from noise source 3) FAN MATE 2 - Output Voltage : 5V ~ 11V ± 2 % - Allowable Power : 6W or lower (Note 1) The maximum weight for a cooler is specified as 450g for Intel Socket 775 and AMD Socket 754/939/940. -

Motherboard Basics
MOTHERBOARD BASICS A recent Tech Tip covered the basics of selecting a computer caseand made mention of the various sizes that correspond to motherboards of different form factors. A few people wrote in expressing interest in understanding more about the basics of motherboards, and that’s exactly what this Tech Tip intends to address. A motherboard, also known as a main board, is the primary circuit board inside of a computer, and is where the central processing unit (CPU), memory, expansion slots, drives, and other peripheral devices are connected. The circuitry on a motherboard facilitates the communication between all of the devices in the computer, making them as critical to a system’s performance as items such as the CPU or memory. The core circuitry of a motherboard is referred to as its chipset, and generally the manufacturer of the motherboard is not the manufacturer of the chipset. Intel does produce motherboards with their own chipsets, but buying a motherboard brand such as Gigabyte, Biostar, and ASUS means getting a board with either a VIA, Nvidia, SIS, or Intel brand chipset. 1. Form Factor The different basic shapes and sizes of motherboards are categorized as form factors. There are several standard form factors available, but some of the more common ones found in desktop computers include: (http://www.formfactors.org/developer/specs/atx2_2.pdf), ATX (http://www.formfactors.org/developer/specs/matxspe1.2.pdf), Micro ATX (mATX) (http://www.formfactors.org/developer/specs/FlexATXaddn1_0.pdf) FlexATX (http://www.via.com.tw/en/initiatives/spearhead/mini-itx/) and Mini-ITX The basic sizes of each are as follows: ATX: 12" x 9.6" (305mm x 244mm) Micro ATX: 9.6" x 9.6" (244mm x 244mm) FlexATX: 9.0" x 7.5" (229mm x 191mm) Mini ITX: 6.7" x 6.7" (170mm x 170mm) ATX and mATX are by far the most popular motherboard sizes for desktop computers, and as seen in the list above, are also some of the largest. -

Archana Subramanian Nikhat Farha
Archana Subramanian Nikhat Farha Application with multiple threads running within a process. Ability of a program or operating system to manage its use by more than one user at a time. Manage multiple requests without having multiple copies of the same program. Processes are insulated from each other by the operating system. Error in one process cannot bring down another process. Operating system keeps track of the tasks and goes from one task to the next without loss of information. PROCESS THREAD Executable object in an container, Stream of instruction within a an application process. Processes do not share memory Threads share the same memory Message passing. Inter thread communication. Security Speed Hybrid design of Multi threading and Multi processing leads to efficient parallel capability of Hardware Statement “The number of transistors on a chip will roughly double each year.” “Computer performance will double every 18 months.” 1st generation: • 1971: Intel 4004 (2300 transistors) • 1974: Intel 8080 (4500 transistors) Instruction processing was strictly sequential. Instructions were fetched, decoded and executed strictly one at a time 2nd generation: • 1979: Motorola MC68000 (68000 transistors) Primitive pipelining with three stages: fetch, decode, execute; only one instruction is in execution at a certain time 3rd generation: • 1984: Motorola MC68020 (240000 transistors) Five stage pipeline; increased parallelism 4th generation: • 1990: MotorolaMC88110, Intel 80960 - these are RISCs (over 1 Million transistors) • PowerPC604, Pentium Superscalar architectures; parallel execution based on multiple pipelines and functional units 5th generation: • 1996: P6, PowerPC 620 (over 5 Million transistors) • MIPS R10000, AMD K5/K6, UltraSparc (not exactly out of order) Superscalars with out of order execution and sophisticated scheduling and renaming strategies VLIW VLIW (very large instruction word) - a compiler schedules the instructions statically (instead of dynamic scheduling as with superscalars). -

939Dual-SATA2 Uli 1695 Chipset (Uli M1695/ Uli M1567) Detail Specification
Socket 939 for AMD Athlon 64x2 Athlon 64, Athlon 64FX and Sempron processorr 939Dual-SATA2 ULi 1695 chipset (ULi M1695/ ULi M1567) Detail Specification CPU - Socket 939 for AMD Athlon 64x2 Athlon 64FX / Athlon 64 and Sempron processor - FSB 1000 MHz (2.0GT/s) - Supports HyperTransport Technology - Supports AMD Cool'n'Quiet Technology Chipset - Northbridge: ULi M1695 - Southbridge: ULI M1567 Memory - DIMM slots: 4 supported - Max. capacity: 4GB Hybrid Booster- CPU Frequency Stepless control - CPU Multiplier - ASRock U-COP - Boot Failure Guard (B.F.G) Expansion Slot- 1 x ASRock Future CPU Port (Yellow-colored): Flexible Socket M2 upgrade interface for ASRock M2CPU Board - 1 x AGP8X/4X slot , 1.5V only - 1 x PCI Express x16 slot - 1 x PCI Express x1 slot - 3 x PCI slots Graphics N/A ASRock Future CPU Port: Flexible M2 Socket upgrade interface for ASRock M2CPU Board Audio - Realtek 850 7.1channel AC'97 audio codec Support AMD Dual Core Athlon 64 X2 processor LAN - Realtek RTL8201CL 10/100 Ethernet LAN PHY - 802.3u, WOL supported PCI Express (x16) and AGP8X/4X VGA Card Rear Panel I/O ASRock 8CH I/O Interface to adopt both PCI Express and AGP - 4 x USB2.0 ports - 1 x RJ45 LAN port display card - 1 x Serial port (COM1) - 1 x PS2 Keyboard connector PCI Express x1 slot for other hi-speed peripheral - 1 x PS2 Mouse connectors cards - 1 x Parallel port (LPT1) - 2 x Audio ports to support 8 Ch audio Advanced storage interface : 2 x Serial ATA ( Line In/Out, Mic In) 1.5Gb/s, RAID 0,1,JBOD, and 1 x SATAII 3.0Gb/s Connector - 2 x SerialATA connectors support RAID,0,1, JBOD Luxury sound effect: 7.1channel superior Audio - 1 x SATA2 connector (based on PCIE SATA2 controller JMB360) Adopts Worldwide First PCI Express SATA II - 2 x ATA 133/100/66 IDE connectors ( supports 4 x IDE devices) controller on board, optimizing the support for - 1 x Floppy connector SATA2 HDD - CPU/Chassis FAN connectors - 20 pin ATX power connector - 4 pin ATX 12V power connector Product brief - Power LED connector 1. -

5 Microprocessors
Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 5 Microprocessors “MEGAHERTZ: This is a really, really big hertz.” —DAVE BARRY In this chapter, you will learn or all practical purposes, the terms microprocessor and central processing how to Funit (CPU) mean the same thing: it’s that big chip inside your computer ■ Identify the core components of a that many people often describe as the brain of the system. You know that CPU CPU makers name their microprocessors in a fashion similar to the automobile ■ Describe the relationship of CPUs and memory industry: CPU names get a make and a model, such as Intel Core i7 or AMD ■ Explain the varieties of modern Phenom II X4. But what’s happening inside the CPU to make it able to do the CPUs amazing things asked of it every time you step up to the keyboard? ■ Install and upgrade CPUs 124 P:\010Comp\BaseTech\380-8\ch05.vp Friday, December 18, 2009 4:59:24 PM Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 Historical/Conceptual ■ CPU Core Components Although the computer might seem to act quite intelligently, comparing the CPU to a human brain hugely overstates its capabilities. A CPU functions more like a very powerful calculator than like a brain—but, oh, what a cal- culator! Today’s CPUs add, subtract, multiply, divide, and move billions of numbers per second. -

AMD Athlon™ 64 Processor Product Brief
AMD Athlon™ 64 Processor Product Brief Get powerful performance for your unique digital experience AMD Athlon™ 64 Processor Overview The AMD Athlon 64 processor is the first Windows®-compatible 64-bit PC processor. The AMD Athlon 64 processor runs on AMD64 technology, a revolutionary technology that allows the processor to run 32-bit applications at full speed while enabling a new generation of powerful 64- bit software applications. Advanced 64-bit operating systems designed for the AMD64 platform from Microsoft, Red Hat, SuSE, and TurboLinux have already been announced. With the introduction of the AMD Athlon 64 processor, AMD provides customers a solution that can address their current and future computing needs. As the first desktop PC processor to run on the AMD64 platform, the AMD Athlon 64 processor helps ensure superior performance on today’s software with readiness for the coming wave of 64-bit computing. With AMD64 technology, customers can embrace the new capabilities of 64-bit computing on their own terms and achieve compatibility with existing software and operating systems. Enhanced Virus Protection with Windows® XP Service Pack 2 With a unique combination of hardware and software technologies that offer you an added layer of protection, certain types of viruses don't stand a chance. The AMD Athlon 64 processor features Enhanced Virus Protection, when support by the OS*, and can help protect against viruses, worms, and other malicious attacks. When combined with protective software, Enhanced Virus Protection is part of an overall security solution that helps keep your information safer. Industry-leading performance for today’s software It 's not just about email, Web browsing and word processing anymore. -

AMD Socket 939/AM2/AM2+/AM3
10318 Bluegrass Parkway Ph: 502-499-0117 Louisville, KY 40299 Fax: 502-499-0981 www.computeroutlet.net Open M-F: 9:30 to 6:00 [email protected] Rev. 08/03/2012 Processors Motherboards Memory AMD Socket 939/AM2/AM2+/AM3/AM3+/FM1 AMD Socket 754 FP/EDO AMD 3200+ 939 $59 Jetway S755Twin $59 16 M/32M/64M FP/EDO 72 Pin Simm $11/21/49 Socket AM3: Athlon II 250 X2/ 960T X4 $80 / 129 AMD Socket FM1 SDRAM Socket AM3+: FX4100/FX6100/FX8120 $125/165/189 Gigabyte A75M-D2H $99 64/128 MB SDRAM 66 MHz $19/39 Socket FM1: AMD X4-631/A3300/A3650 APU $129/119/129 AM2+(DDR2) 64M/128M/256M/512M SDRAM PC100/133 $10/15/25/45 Intel Socket 775/1055/1056/2011/LGA771 ASRock mAtx A/V/Lan $69 512 MB SDRAM PC100 /133 Ecc/Reg $69 Socket 775:Celeron 430 1.8G $49 AM3(DDR3) DDR1 E6400/E6420/E7500/E8500 $135/139/145/169 Gigabyte M68MT-D3 $69 128/256M/512M/1 G DDR266/333/400 $15/19/29/39 Quad Q8300 $175 Gigabyte GA-880GM-UD2H $105 256M/512M/ 1G (ECC/REG )DDR266/333/400 $35/49/89 Socket 1156 G6950:i3-540/i5-760/i7-950 $119/142/239/315 Biostar A880G+ $69 256M /512M/1G DDR266/333/400 Notebook $20/25/45 Socket 1155: i3-2100/i5-2400/i5-3450/i7-2600/i7-2600k $146/222/219/359/369 Biostar N68S3+ $69 DDR2 Socket 2011: i7- 3820/3930K $344/677 Foxconn A7DA-S 3.0 $119 256M/512M/ 1G/ 2G/4G 400/533/667/800 $10/20/29/39/89 Foxconn M61PMP-K $69 512M/ 1GB /2GB 400/533/667 ECC only $29/39/55 Xeon ASRock N68-VS3 UCC $69 1G/2G/4G ECC/REG or ECC Full Buffered $45/89/159 3065/3110/3430 $199/235/279 MSI 760GM-E51 $99 256M/512M Notebook $10/20 Xeon Dual Core MSI 790X-G45 $129 1G/2G/4G Notebook