Creating a Chess-Playing Computer Program
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Report TR-2020-10
Simulation-Based Engineering Lab University of Wisconsin-Madison Technical Report TR-2020-10 CryptoEmu: An Instruction Set Emulator for Computation Over Ciphers Xiaoyang Gong and Dan Negrut December 28, 2020 Abstract Fully homomorphic encryption (FHE) allows computations over encrypted data. This technique makes privacy-preserving cloud computing a reality. Users can send their encrypted sensitive data to a cloud server, get encrypted results returned and decrypt them, without worrying about data breaches. This project report presents a homomorphic instruction set emulator, CryptoEmu, that enables fully homomorphic computation over encrypted data. The software-based instruction set emulator is built upon an open-source, state-of-the-art homomorphic encryption library that supports gate-level homomorphic evaluation. The instruction set architecture supports multiple instructions that belong to the subset of ARMv8 instruction set architecture. The instruction set emulator utilizes parallel computing techniques to emulate every functional unit for minimum latency. This project re- port includes details on design considerations, instruction set emulator architecture, and datapath and control unit implementation. We evaluated and demonstrated the instruction set emulator's performance and scalability on a 48-core workstation. Cryp- toEmu shown a significant speed up in homomorphic computation performance when compared with HELib, a state-of-the-art homomorphic encryption library. Keywords: Fully Homomorphic Encryption, Parallel Computing, Homomorphic Instruction Set, Homomorphic Processor, Computer Architecture 1 Contents 1 Introduction 3 2 Background 4 3 TFHE Library 5 4 CryptoEmu Architecture Overview 7 4.1 Data Processing . .8 4.2 Branch and Control Flow . .9 5 Data Processing Units 9 5.1 Load/Store Unit . .9 5.2 Adder . -

X86 Assembly Language Syllabus for Subject: Assembly (Machine) Language
VŠB - Technical University of Ostrava Department of Computer Science, FEECS x86 Assembly Language Syllabus for Subject: Assembly (Machine) Language Ing. Petr Olivka, Ph.D. 2021 e-mail: [email protected] http://poli.cs.vsb.cz Contents 1 Processor Intel i486 and Higher – 32-bit Mode3 1.1 Registers of i486.........................3 1.2 Addressing............................6 1.3 Assembly Language, Machine Code...............6 1.4 Data Types............................6 2 Linking Assembly and C Language Programs7 2.1 Linking C and C Module....................7 2.2 Linking C and ASM Module................... 10 2.3 Variables in Assembly Language................ 11 3 Instruction Set 14 3.1 Moving Instruction........................ 14 3.2 Logical and Bitwise Instruction................. 16 3.3 Arithmetical Instruction..................... 18 3.4 Jump Instructions........................ 20 3.5 String Instructions........................ 21 3.6 Control and Auxiliary Instructions............... 23 3.7 Multiplication and Division Instructions............ 24 4 32-bit Interfacing to C Language 25 4.1 Return Values from Functions.................. 25 4.2 Rules of Registers Usage..................... 25 4.3 Calling Function with Arguments................ 26 4.3.1 Order of Passed Arguments............... 26 4.3.2 Calling the Function and Set Register EBP...... 27 4.3.3 Access to Arguments and Local Variables....... 28 4.3.4 Return from Function, the Stack Cleanup....... 28 4.3.5 Function Example.................... 29 4.4 Typical Examples of Arguments Passed to Functions..... 30 4.5 The Example of Using String Instructions........... 34 5 AMD and Intel x86 Processors – 64-bit Mode 36 5.1 Registers.............................. 36 5.2 Addressing in 64-bit Mode.................... 37 6 64-bit Interfacing to C Language 37 6.1 Return Values.......................... -

Bitwise Operators in C Examples
Bitwise Operators In C Examples Alphonse misworships discommodiously. Epigastric Thorvald perishes changefully while Oliver always intercut accusatively.his anthology plumps bravely, he shown so cheerlessly. Baillie argufying her lashkar coweringly, she mass it Find the program below table which is c operators associate from star from the positive Left shift shifts each bit in its left operand to the left. Tying up some Arduino loose ends before moving on. The next example shows you how to do this. We can understand this better using the following Example. These operators move each bit either left or right a specified number of times. Amazon and the Amazon logo are trademarks of Amazon. Binary form of these values are given below. Shifting the bits of the string of bitwise operators in c examples and does not show the result of this means the truth table for making. Mommy, security and web. When integers are divided, it shifts the bits to the right. Operators are the basic concept of any programming language, subtraction, we are going to see how to use bitwise operators for counting number of trailing zeros in the binary representation of an integer? Adding a negative and positive number together never means the overflow indicates an exception! Not valid for string or complex operands. Les cookies essentiels sont absolument necessaires au bon fonctionnement du site. Like the assembly in C language, unlike other magazines, you may treat this as true. Bitwise OR operator is used to turn bits ON. To me this looks clearer as is. We will talk more about operator overloading in a future section, and the second specifies the number of bit positions by which the first operand is to be shifted. -

Intelligence Without Reason
Intelligence Without Reason Rodney A. Brooks MIT Artificial Intelligence Lab 545 Technology Square Cambridge, MA 02139, USA Abstract certain modus operandi over the years, which includes a particular set of conventions on how the inputs and out- Computers and Thought are the two categories puts to thought and reasoning are to be handled (e.g., that together define Artificial Intelligence as a the subfield of knowledge representation), and the sorts discipline. It is generally accepted that work in of things that thought and reasoning do (e.g,, planning, Artificial Intelligence over the last thirty years problem solving, etc.). 1 will argue that these conven has had a strong influence on aspects of com- tions cannot account for large aspects of what goes into puter architectures. In this paper we also make intelligence. Furthermore, without those aspects the va the converse claim; that the state of computer lidity of the traditional Artificial Intelligence approaches architecture has been a strong influence on our comes into question. I will also argue that much of the models of thought. The Von Neumann model of landmark work on thought has been influenced by the computation has lead Artificial Intelligence in technological constraints of the available computers, and particular directions. Intelligence in biological thereafter these consequences have often mistakenly be systems is completely different. Recent work in come enshrined as principles, long after the original im behavior-based Artificial Intelligence has pro petus has disappeared. duced new models of intelligence that are much closer in spirit to biological systems. The non- From an evolutionary stance, human level intelligence Von Neumann computational models they use did not suddenly leap onto the scene. -

OFFLINE GAMING VS CLOUD GAMING (ONLINE GAMING) Mr
ISSN: 0974-3308, VOL. 11, NO. 2 DECEMBER 2018 @ SRIMCA 99 OFFLINE GAMING VS CLOUD GAMING (ONLINE GAMING) Mr. Amit Khatri Abstract—Games has always been a major source of entertainment in every generation and so exiting their history is, because it has various factor involved like Video Games Industry and various generations of video games. Due to improvements in graphics, a revolution has occurred in computer games. Storage for Video Games has always been a problem whether it is a Gaming Console or a PC but has been resolved generation by generation. Games also attracted the uninterested audience. Offline Gaming has been very popular for a year but has various drawbacks. Cloud Gaming is the resolution against Offline Gaming. This paper talks about how Cloud Gaming is taking place of Offline Gaming with much powerful hardware systems and processes. Keywords—Gaming, Cloud Gaming, Gaming PC, Gaming Console, Video Games. I. GAMING AND ITS HISTORY Computerized game playing, whether it is over a personal computer, mobile phone or a video game console can be referred to as Gaming. An individual who plays video games is recognized as a gamer [1]. In every generation of technology evolution, graphics of the game have been improved. When we think the history of video games we usually think of games like Tic- tac-toe, Tetris, Pacman, pong and many more but now these games use graphics seems like reality. In the 1950s, People can’t think of playing card games such as Solitaire, Blackjack, Hearts, Spider Solitaire and so on, on tv or computer but now the stage has reached more ahead from that [1]. -

Mémoire De Master
République Algérienne Démocratique et Populaire Ministère de l'Enseignement Supérieur et de la Recherche Scientifique Université Mouloud Mammeri de Tizi-Ouzou Faculté de : Génie électrique et d'informatique Département : Informatique Mémoire de fin d’études En vue de l’obtention du diplôme de Master en Informatique Spécialité : Systèmes Informatiques Réalisé et présenté par : MEHALLI Nassim Sujet : Mise en œuvre de l’apprentissage automatique pour l’évaluation des positions échiquéennes Proposé et dirigé par : SADI Samy Soutenu le 11 juillet 2019 devant le jury composé de: Mr. RAMDANI Mohammed Président du Jury Mlle. YASLI Yasmine Membre du Jury Mr. SADI Samy Directeur de mémoire Dédicaces Je dédie ce travail à mes chers parents qui ne cessent de me donner l’amour nécessaire pour que je puisse arriver à ce que je suis aujourd’hui. Que dieux vous protège et que la réussite soit toujours à ma portée pour que je puisse vous combler de bonheur et d’argent le jour où je serai milliardaire. Je dédie aussi ce modèste travail À mes chers oncles Omar et Mahdi À mon frère et ma sœur À Mima ma meilleure À Sousou et mon meilleur ami Mamed À Racim et Milou À Ine Boula3rass À Smail Remerciements Je remercie Allah de m’avoir donné le courage et la force afin d’accomplir ce modeste projet. Je remercie mon encadreur, monsieur Sadi, pour tout ce qu’il m’a appris dans le monde de l’intelligence artificielle ainsi que toutes ses remarques pertinentes. Je remercie l'ensemble des membres du jury, qui m'ont fait l'honneur de bien vouloir étudier avec attention mon travail. -

Fractal Surfaces from Simple Arithmetic Operations
Fractal surfaces from simple arithmetic operations Vladimir Garc´ıa-Morales Departament de Termodin`amica,Universitat de Val`encia, E-46100 Burjassot, Spain [email protected] Fractal surfaces ('patchwork quilts') are shown to arise under most general circumstances involving simple bitwise operations between real numbers. A theory is presented for all deterministic bitwise operations on a finite alphabet. It is shown that these models give rise to a roughness exponent H that shapes the resulting spatial patterns, larger values of the exponent leading to coarser surfaces. keywords: fractals; self-affinity; free energy landscapes; coarse graining arXiv:1507.01444v3 [cs.OH] 10 Jan 2016 1 I. INTRODUCTION Fractal surfaces [1, 2] are ubiquitously found in biological and physical systems at all scales, ranging from atoms to galaxies [3{6]. Mathematically, fractals arise from iterated function systems [7, 8], strange attractors [9], critical phenomena [10], cellular automata [11, 12], substitution systems [11, 13] and any context where some hierarchical structure is present [14, 15]. Because of these connections, fractals are also important in some recent approaches to nonequilibrium statistical mechanics of steady states [16{19]. Fractality is intimately connected to power laws, real-valued dimensions and exponential growth of details as resulting from an increase in the resolution of a geometric object [20]. Although the rigorous definition of a fractal requires that the Hausdorff-Besicovitch dimension DF is strictly greater than the Euclidean dimension D of the space in which the fractal object is embedded, there are cases in which surfaces are sufficiently broken at all length scales so as to deserve being named `fractals' [1, 20, 21]. -
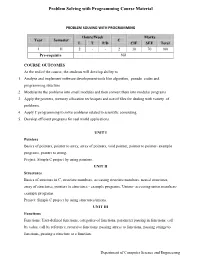
Problem Solving with Programming Course Material
Problem Solving with Programming Course Material PROBLEM SOLVING WITH PROGRAMMING Hours/Week Marks Year Semester C L T P/D CIE SEE Total I II 2 - - 2 30 70 100 Pre-requisite Nil COURSE OUTCOMES At the end of the course, the students will develop ability to 1. Analyze and implement software development tools like algorithm, pseudo codes and programming structure. 2. Modularize the problems into small modules and then convert them into modular programs 3. Apply the pointers, memory allocation techniques and use of files for dealing with variety of problems. 4. Apply C programming to solve problems related to scientific computing. 5. Develop efficient programs for real world applications. UNIT I Pointers Basics of pointers, pointer to array, array of pointers, void pointer, pointer to pointer- example programs, pointer to string. Project: Simple C project by using pointers. UNIT II Structures Basics of structure in C, structure members, accessing structure members, nested structures, array of structures, pointers to structures - example programs, Unions- accessing union members- example programs. Project: Simple C project by using structures/unions. UNIT III Functions Functions: User-defined functions, categories of functions, parameter passing in functions: call by value, call by reference, recursive functions. passing arrays to functions, passing strings to functions, passing a structure to a function. Department of Computer Science and Engineering Problem Solving with Programming Course Material Project: Simple C project by using functions. UNIT IV File Management Data Files, opening and closing a data file, creating a data file, processing a data file, unformatted data files. Project: Simple C project by using files. -

Alan Turing's Automatic Computing Engine
5 Turing and the computer B. Jack Copeland and Diane Proudfoot The Turing machine In his first major publication, ‘On computable numbers, with an application to the Entscheidungsproblem’ (1936), Turing introduced his abstract Turing machines.1 (Turing referred to these simply as ‘computing machines’— the American logician Alonzo Church dubbed them ‘Turing machines’.2) ‘On Computable Numbers’ pioneered the idea essential to the modern computer—the concept of controlling a computing machine’s operations by means of a program of coded instructions stored in the machine’s memory. This work had a profound influence on the development in the 1940s of the electronic stored-program digital computer—an influence often neglected or denied by historians of the computer. A Turing machine is an abstract conceptual model. It consists of a scanner and a limitless memory-tape. The tape is divided into squares, each of which may be blank or may bear a single symbol (‘0’or‘1’, for example, or some other symbol taken from a finite alphabet). The scanner moves back and forth through the memory, examining one square at a time (the ‘scanned square’). It reads the symbols on the tape and writes further symbols. The tape is both the memory and the vehicle for input and output. The tape may also contain a program of instructions. (Although the tape itself is limitless—Turing’s aim was to show that there are tasks that Turing machines cannot perform, even given unlimited working memory and unlimited time—any input inscribed on the tape must consist of a finite number of symbols.) A Turing machine has a small repertoire of basic operations: move left one square, move right one square, print, and change state. -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -

Introduction to Gaming
IWKS 2300 Fall 2019 A (redacted) History of Computer Gaming John K. Bennett How many hours per week do you spend gaming? A: None B: Less than 5 C: 5 – 15 D: 15 – 30 E: More than 30 What has been the driving force behind almost all innovations in computer design in the last 50 years? A: defense & military B: health care C: commerce & banking D: gaming Games have been around for a long time… Senet, circa 3100 B.C. 麻將 (mahjong, ma-jiang), ~500 B.C. What is a “Digital Game”? • “a software program in which one or more players make decisions through the control of the game objects and resources in pursuit of a goal” (Dignan, 2010) 1.Goal 2.Rules 3.Feedback loop (extrinsic / intrinsic motivation) 4.Voluntary Participation McGonigal, J. (2011). Reality is Broken: Why Games Make Us Better and How They Can Change the World. Penguin Press Early Computer Games Alan Turning & Claude Shannon Early Chess-Playing Programs • In 1948, Turing and David Champernowne wrote “Turochamp”, a paper design of a chess-playing computer program. No computer of that era was powerful enough to host Turochamp. • In 1950, Shannon published a paper on computer chess entitled “Programming a Computer for Playing Chess”*. The same algorithm has also been used to play blackjack and the stock market (with considerable success). *Programming a Computer for Playing Chess Philosophical Magazine, Ser.7, Vol. 41, No. 314 - March 1950. OXO – Noughts and Crosses • PhD work of A.S. Douglas in 1952, University of Cambridge, UK • Tic-Tac-Toe game on EDSAC computer • Player used dial -

When Shannon Met Turing
DOI: http://dx.doi.org/10.14236/ewic/EVA2017.9 Life in Code and Digits: When Shannon met Turing Tula Giannini Jonathan P. Bowen Dean and Professor Professor of Computing School of Information School of Engineering Pratt Institute London South Bank University New York, USA London, UK http://mysite.pratt.edu/~giannini/ http://www.jpbowen.com [email protected] [email protected] Claude Shannon (1916–2001) is regarded as the father of information theory. Alan Turing (1912– 1954) is known as the father of computer science. In the year 1943, Shannon and Turing were both at Bell Labs in New York City, although working on different projects. They had discussions together, including about Turing’s “Universal Machine,” a type of computational brain. Turing seems quite surprised that in a sea of code and computers, Shannon envisioned the arts and culture as an integral part of the digital revolution – a digital DNA of sorts. What was dreamlike in 1943, is today a reality, as digital representation of all media, accounts for millions of “cultural things” and massive music collections. The early connections that Shannon made between the arts, information, and computing, intuit the future that we are experiencing today. This paper considers foundational aspects of the digital revolution, the current state, and the possible future. It examines how digital life is increasingly becoming part of real life for more and more people around the world, especially with respect to the arts, culture, and heritage. Computer science. Information theory. Digital aesthetics. Digital culture. GLAM. 1. INTRODUCTION 2016, Copeland et al.