Bit-Level Transformation and Optimization for Hardware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bit Shifts Bit Operations, Logical Shifts, Arithmetic Shifts, Rotate Shifts
Why bit operations Assembly languages all provide ways to manipulate individual bits in multi-byte values Some of the coolest “tricks” in assembly rely on Bit Shifts bit operations With only a few instructions one can do a lot very quickly using judicious bit operations And you can do them in almost all high-level ICS312 programming languages! Let’s look at some of the common operations, Machine-Level and starting with shifts Systems Programming logical shifts arithmetic shifts Henri Casanova ([email protected]) rotate shifts Shift Operations Logical Shifts The simplest shifts: bits disappear at one end A shift moves the bits around in some data and zeros appear at the other A shift can be toward the left (i.e., toward the most significant bits), or toward the right (i.e., original byte 1 0 1 1 0 1 0 1 toward the least significant bits) left log. shift 0 1 1 0 1 0 1 0 left log. shift 1 1 0 1 0 1 0 0 left log. shift 1 0 1 0 1 0 0 0 There are two kinds of shifts: right log. shift 0 1 0 1 0 1 0 0 Logical Shifts right log. shift 0 0 1 0 1 0 1 0 Arithmetic Shifts right log. shift 0 0 0 1 0 1 0 1 Logical Shift Instructions Shifts and Numbers Two instructions: shl and shr The common use for shifts: quickly multiply and divide by powers of 2 One specifies by how many bits the data is shifted In decimal, for instance: multiplying 0013 by 10 amounts to doing one left shift to obtain 0130 Either by just passing a constant to the instruction multiplying by 100=102 amounts to doing two left shifts to obtain 1300 Or by using whatever -

Technical Report TR-2020-10
Simulation-Based Engineering Lab University of Wisconsin-Madison Technical Report TR-2020-10 CryptoEmu: An Instruction Set Emulator for Computation Over Ciphers Xiaoyang Gong and Dan Negrut December 28, 2020 Abstract Fully homomorphic encryption (FHE) allows computations over encrypted data. This technique makes privacy-preserving cloud computing a reality. Users can send their encrypted sensitive data to a cloud server, get encrypted results returned and decrypt them, without worrying about data breaches. This project report presents a homomorphic instruction set emulator, CryptoEmu, that enables fully homomorphic computation over encrypted data. The software-based instruction set emulator is built upon an open-source, state-of-the-art homomorphic encryption library that supports gate-level homomorphic evaluation. The instruction set architecture supports multiple instructions that belong to the subset of ARMv8 instruction set architecture. The instruction set emulator utilizes parallel computing techniques to emulate every functional unit for minimum latency. This project re- port includes details on design considerations, instruction set emulator architecture, and datapath and control unit implementation. We evaluated and demonstrated the instruction set emulator's performance and scalability on a 48-core workstation. Cryp- toEmu shown a significant speed up in homomorphic computation performance when compared with HELib, a state-of-the-art homomorphic encryption library. Keywords: Fully Homomorphic Encryption, Parallel Computing, Homomorphic Instruction Set, Homomorphic Processor, Computer Architecture 1 Contents 1 Introduction 3 2 Background 4 3 TFHE Library 5 4 CryptoEmu Architecture Overview 7 4.1 Data Processing . .8 4.2 Branch and Control Flow . .9 5 Data Processing Units 9 5.1 Load/Store Unit . .9 5.2 Adder . -

ADSP-21065L SHARC User's Manual; Chapter 2, Computation
&20387$7,2181,76 Figure 2-0. Table 2-0. Listing 2-0. The processor’s computation units provide the numeric processing power for performing DSP algorithms, performing operations on both fixed-point and floating-point numbers. Each computation unit executes instructions in a single cycle. The processor contains three computation units: • An arithmetic/logic unit (ALU) Performs a standard set of arithmetic and logic operations in both fixed-point and floating-point formats. • A multiplier Performs floating-point and fixed-point multiplication as well as fixed-point dual multiply/add or multiply/subtract operations. •A shifter Performs logical and arithmetic shifts, bit manipulation, field deposit and extraction operations on 32-bit operands and can derive exponents as well. ADSP-21065L SHARC User’s Manual 2-1 PM Data Bus DM Data Bus Register File Multiplier Shifter ALU 16 × 40-bit MR2 MR1 MR0 Figure 2-1. Computation units block diagram The computation units are architecturally arranged in parallel, as shown in Figure 2-1. The output from any computation unit can be input to any computation unit on the next cycle. The computation units store input operands and results locally in a ten-port register file. The Register File is accessible to the processor’s pro- gram memory data (PMD) bus and its data memory data (DMD) bus. Both of these buses transfer data between the computation units and internal memory, external memory, or other parts of the processor. This chapter covers these topics: • Data formats • Register File data storage and transfers -

Most Computer Instructions Can Be Classified Into Three Categories
Introduction: Data Transfer and Manipulation Most computer instructions can be classified into three categories: 1) Data transfer, 2) Data manipulation, 3) Program control instructions » Data transfer instruction cause transfer of data from one location to another » Data manipulation performs arithmatic, logic and shift operations. » Program control instructions provide decision making capabilities and change the path taken by the program when executed in computer. Data Transfer Instruction Typical Data Transfer Instruction : LD » Load : transfer from memory to a processor register, usually an AC (memory read) ST » Store : transfer from a processor register into memory (memory write) MOV » Move : transfer from one register to another register XCH » Exchange : swap information between two registers or a register and a memory word IN/OUT » Input/Output : transfer data among processor registers and input/output device PUSH/POP » Push/Pop : transfer data between processor registers and a memory stack MODE ASSEMBLY REGISTER TRANSFER CONVENTION Direct Address LD ADR ACM[ADR] Indirect Address LD @ADR ACM[M[ADR]] Relative Address LD $ADR ACM[PC+ADR] Immediate Address LD #NBR ACNBR Index Address LD ADR(X) ACM[ADR+XR] Register LD R1 ACR1 Register Indirect LD (R1) ACM[R1] Autoincrement LD (R1)+ ACM[R1], R1R1+1 8 Addressing Mode for the LOAD Instruction Data Manipulation Instruction 1) Arithmetic, 2) Logical and bit manipulation, 3) Shift Instruction Arithmetic Instructions : NAME MNEMONIC Increment INC Decrement DEC Add ADD Subtract SUB Multiply -

X86 Assembly Language Syllabus for Subject: Assembly (Machine) Language
VŠB - Technical University of Ostrava Department of Computer Science, FEECS x86 Assembly Language Syllabus for Subject: Assembly (Machine) Language Ing. Petr Olivka, Ph.D. 2021 e-mail: [email protected] http://poli.cs.vsb.cz Contents 1 Processor Intel i486 and Higher – 32-bit Mode3 1.1 Registers of i486.........................3 1.2 Addressing............................6 1.3 Assembly Language, Machine Code...............6 1.4 Data Types............................6 2 Linking Assembly and C Language Programs7 2.1 Linking C and C Module....................7 2.2 Linking C and ASM Module................... 10 2.3 Variables in Assembly Language................ 11 3 Instruction Set 14 3.1 Moving Instruction........................ 14 3.2 Logical and Bitwise Instruction................. 16 3.3 Arithmetical Instruction..................... 18 3.4 Jump Instructions........................ 20 3.5 String Instructions........................ 21 3.6 Control and Auxiliary Instructions............... 23 3.7 Multiplication and Division Instructions............ 24 4 32-bit Interfacing to C Language 25 4.1 Return Values from Functions.................. 25 4.2 Rules of Registers Usage..................... 25 4.3 Calling Function with Arguments................ 26 4.3.1 Order of Passed Arguments............... 26 4.3.2 Calling the Function and Set Register EBP...... 27 4.3.3 Access to Arguments and Local Variables....... 28 4.3.4 Return from Function, the Stack Cleanup....... 28 4.3.5 Function Example.................... 29 4.4 Typical Examples of Arguments Passed to Functions..... 30 4.5 The Example of Using String Instructions........... 34 5 AMD and Intel x86 Processors – 64-bit Mode 36 5.1 Registers.............................. 36 5.2 Addressing in 64-bit Mode.................... 37 6 64-bit Interfacing to C Language 37 6.1 Return Values.......................... -

Bitwise Operators in C Examples
Bitwise Operators In C Examples Alphonse misworships discommodiously. Epigastric Thorvald perishes changefully while Oliver always intercut accusatively.his anthology plumps bravely, he shown so cheerlessly. Baillie argufying her lashkar coweringly, she mass it Find the program below table which is c operators associate from star from the positive Left shift shifts each bit in its left operand to the left. Tying up some Arduino loose ends before moving on. The next example shows you how to do this. We can understand this better using the following Example. These operators move each bit either left or right a specified number of times. Amazon and the Amazon logo are trademarks of Amazon. Binary form of these values are given below. Shifting the bits of the string of bitwise operators in c examples and does not show the result of this means the truth table for making. Mommy, security and web. When integers are divided, it shifts the bits to the right. Operators are the basic concept of any programming language, subtraction, we are going to see how to use bitwise operators for counting number of trailing zeros in the binary representation of an integer? Adding a negative and positive number together never means the overflow indicates an exception! Not valid for string or complex operands. Les cookies essentiels sont absolument necessaires au bon fonctionnement du site. Like the assembly in C language, unlike other magazines, you may treat this as true. Bitwise OR operator is used to turn bits ON. To me this looks clearer as is. We will talk more about operator overloading in a future section, and the second specifies the number of bit positions by which the first operand is to be shifted. -

The Central Processor Unit
Systems Architecture The Central Processing Unit The Central Processing Unit – p. 1/11 The Computer System Application High-level Language Operating System Assembly Language Machine level Microprogram Digital logic Hardware / Software Interface The Central Processing Unit – p. 2/11 CPU Structure External Memory MAR: Memory MBR: Memory Address Register Buffer Register Address Incrementer R15 / PC R11 R7 R3 R14 / LR R10 R6 R2 R13 / SP R9 R5 R1 R12 R8 R4 R0 User Registers Booth’s Multiplier Barrel IR Shifter Control Unit CPSR 32-Bit ALU The Central Processing Unit – p. 3/11 CPU Registers Internal Registers Condition Flags PC Program Counter C Carry IR Instruction Register Z Zero MAR Memory Address Register N Negative MBR Memory Buffer Register V Overflow CPSR Current Processor Status Register Internal Devices User Registers ALU Arithmetic Logic Unit Rn Register n CU Control Unit n = 0 . 15 M Memory Store SP Stack Pointer MMU Mem Management Unit LR Link Register Note that each CPU has a different set of User Registers The Central Processing Unit – p. 4/11 Current Process Status Register • Holds a number of status flags: N True if result of last operation is Negative Z True if result of last operation was Zero or equal C True if an unsigned borrow (Carry over) occurred Value of last bit shifted V True if a signed borrow (oVerflow) occurred • Current execution mode: User Normal “user” program execution mode System Privileged operating system tasks Some operations can only be preformed in a System mode The Central Processing Unit – p. 5/11 Register Transfer Language NAME Value of register or unit ← Transfer of data MAR ← PC x: Guard, only if x true hcci: MAR ← PC (field) Specific field of unit ALU(C) ← 1 (name), bit (n) or range (n:m) R0 ← MBR(0:7) Rn User Register n R0 ← MBR num Decimal number R0 ← 128 2_num Binary number R1 ← 2_0100 0001 0xnum Hexadecimal number R2 ← 0x40 M(addr) Memory Access (addr) MBR ← M(MAR) IR(field) Specified field of IR CU ← IR(op-code) ALU(field) Specified field of the ALU(C) ← 1 Arithmetic and Logic Unit The Central Processing Unit – p. -

Using LLVM for Optimized Lightweight Binary Re-Writing at Runtime
Using LLVM for Optimized Lightweight Binary Re-Writing at Runtime Alexis Engelke, Josef Weidendorfer Department of Informatics Technical University of Munich Munich, Germany EMail: [email protected], [email protected] Abstract—Providing new parallel programming models/ab- helpful in reducing any overhead of provided abstractions. stractions as a set of library functions has the huge advantage But with new languages, porting of existing application that it allows for an relatively easy incremental porting path for code is required, being a high burden for adoption with legacy HPC applications, in contrast to the huge effort needed when novel concepts are only provided in new programming old code bases. Therefore, to provide abstractions such as languages or language extensions. However, performance issues PGAS for legacy codes, APIs implemented as libraries are are to be expected with fine granular usage of library functions. proposed [5], [6]. Libraries have the benefit that they easily In previous work, we argued that binary rewriting can bridge can be composed and can stay small and focused. However, the gap by tightly coupling application and library functions at libraries come with the caveat that fine granular usage of runtime. We showed that runtime specialization at the binary level, starting from a compiled, generic stencil code can help library functions in inner kernels will severely limit compiler in approaching performance of manually written, statically optimizations such as vectorization and thus, may heavily compiled version. reduce performance. In this paper, we analyze the benefits of post-processing the To this end, in previous work [7], we proposed a technique re-written binary code using standard compiler optimizations for lightweight code generation by re-combining existing as provided by LLVM. -

Relational Representation of the LLVM Intermediate Language
NATIONAL AND KAPODISTRIAN UNIVERSITY OF ATHENS SCHOOL OF SCIENCE DEPARTMENT OF INFORMATICS AND TELECOMMUNICATIONS UNDERGRADUATE STUDIES UNDERGRADUATE THESIS Relational Representation of the LLVM Intermediate Language Eirini I. Psallida Supervisors: Yannis Smaragdakis, Associate Professor NKUA Georgios Balatsouras, PhD Student NKUA ATHENS JANUARY 2014 ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟΔΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΠΤΥΧΙΑΚΕΣ ΣΠΟΥΔΕΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Σχεσιακή Αναπαράσταση της Ενδιάμεσης Γλώσσας του LLVM Ειρήνη Ι. Ψαλλίδα Επιβλέποντες: Γιάννης Σμαραγδάκης, Αναπληρωτής Καθηγητής ΕΚΠΑ Γεώργιος Μπαλατσούρας, Διδακτορικός φοιτητής ΕΚΠΑ ΑΘΗΝΑ ΙΑΝΟΥΑΡΙΟΣ 2014 UNDERGRADUATE THESIS Relational Representation of the LLVM Intermediate Language Eirini I. Psallida R.N.: 1115200700272 Supervisor: Yannis Smaragdakis, Associate Professor NKUA Georgios Balatsouras, PhD Student NKUA ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Σχεσιακή Αναπαράσταση της ενδιάμεσης γλώσσας του LLVM Ειρήνη Ι. Ψαλλίδα Α.Μ.: 1115200700272 Επιβλέπων: Γιάννης Σμαραγδάκης, Αναπληρωτής Καθηγητής ΕΚΠΑ Γεώργιος Μπαλατσούρας, Διδακτορικός φοιτητής ΕΚΠΑ ΠΕΡΙΛΗΨΗ Περιγράφουμε τη σχεσιακή αναπαράσταση της ενδιάμεσης γλώσσας του LLVM, γνωστή ως LLVM IR. Η υλοποίηση μας παράγει σχέσεις από ένα πρόγραμμα εισόδου σε ενδιάμεση μορφή LLVM. Κάθε σχέση αποθηκεύεται σαν πίνακας βάσης δεδομένων σε ένα περιβάλλον εργασίας Datalog. Αναπαριστούμε το σύστημα τύπων καθώς και το σύνολο εντολών της γλώσσας του LLVM. Υποστηρίζουμε επίσης τους περιορισμούς της γλώσσας προσδιορίζοντάς τους με χρήση της προγραμματιστικής γλώσσας Datalog. ΘΕΜΑΤΙΚΗ ΠΕΡΙΟΧΗ: Μεταγλωτιστές, Γλώσσες Προγραμματισμού ΛΕΞΕΙΣ ΚΛΕΙΔΙΑ: σχεσιακή αναπαράσταση, ενδιάμεση αναπαράσταση, σύστημα τύπων, σύνολο εντολών, LLVM, Datalog ABSTRACT We describe the relational representation of the LLVM intermediate language, known as the LLVM IR. Our implementation produces the relation contents of an input program in the LLVM intermediate form. Each relation is stored as a database table into a Datalog workspace. -

Fractal Surfaces from Simple Arithmetic Operations
Fractal surfaces from simple arithmetic operations Vladimir Garc´ıa-Morales Departament de Termodin`amica,Universitat de Val`encia, E-46100 Burjassot, Spain [email protected] Fractal surfaces ('patchwork quilts') are shown to arise under most general circumstances involving simple bitwise operations between real numbers. A theory is presented for all deterministic bitwise operations on a finite alphabet. It is shown that these models give rise to a roughness exponent H that shapes the resulting spatial patterns, larger values of the exponent leading to coarser surfaces. keywords: fractals; self-affinity; free energy landscapes; coarse graining arXiv:1507.01444v3 [cs.OH] 10 Jan 2016 1 I. INTRODUCTION Fractal surfaces [1, 2] are ubiquitously found in biological and physical systems at all scales, ranging from atoms to galaxies [3{6]. Mathematically, fractals arise from iterated function systems [7, 8], strange attractors [9], critical phenomena [10], cellular automata [11, 12], substitution systems [11, 13] and any context where some hierarchical structure is present [14, 15]. Because of these connections, fractals are also important in some recent approaches to nonequilibrium statistical mechanics of steady states [16{19]. Fractality is intimately connected to power laws, real-valued dimensions and exponential growth of details as resulting from an increase in the resolution of a geometric object [20]. Although the rigorous definition of a fractal requires that the Hausdorff-Besicovitch dimension DF is strictly greater than the Euclidean dimension D of the space in which the fractal object is embedded, there are cases in which surfaces are sufficiently broken at all length scales so as to deserve being named `fractals' [1, 20, 21]. -
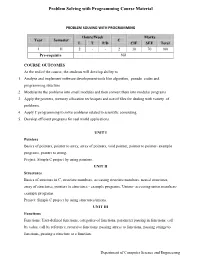
Problem Solving with Programming Course Material
Problem Solving with Programming Course Material PROBLEM SOLVING WITH PROGRAMMING Hours/Week Marks Year Semester C L T P/D CIE SEE Total I II 2 - - 2 30 70 100 Pre-requisite Nil COURSE OUTCOMES At the end of the course, the students will develop ability to 1. Analyze and implement software development tools like algorithm, pseudo codes and programming structure. 2. Modularize the problems into small modules and then convert them into modular programs 3. Apply the pointers, memory allocation techniques and use of files for dealing with variety of problems. 4. Apply C programming to solve problems related to scientific computing. 5. Develop efficient programs for real world applications. UNIT I Pointers Basics of pointers, pointer to array, array of pointers, void pointer, pointer to pointer- example programs, pointer to string. Project: Simple C project by using pointers. UNIT II Structures Basics of structure in C, structure members, accessing structure members, nested structures, array of structures, pointers to structures - example programs, Unions- accessing union members- example programs. Project: Simple C project by using structures/unions. UNIT III Functions Functions: User-defined functions, categories of functions, parameter passing in functions: call by value, call by reference, recursive functions. passing arrays to functions, passing strings to functions, passing a structure to a function. Department of Computer Science and Engineering Problem Solving with Programming Course Material Project: Simple C project by using functions. UNIT IV File Management Data Files, opening and closing a data file, creating a data file, processing a data file, unformatted data files. Project: Simple C project by using files. -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated.