Ground Truth and Models for 17Th C. French Prints (And Hopefully More) Simon Gabay, Thibault Clérice, Christian Reul
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Essential Chomsky
CURRENT AFFAIRS $19.95 U.S. CHOMSKY IS ONE OF A SMALL BAND OF NOAM INDIVIDUALS FIGHTING A WHOLE INDUSTRY. AND CHOMSKY THAT MAKES HIM NOT ONLY BRILLIANT, BUT HEROIC. NOAM CHOMSKY —ARUNDHATI ROY EDITED BY ANTHONY ARNOVE THEESSENTIAL C Noam Chomsky is one of the most significant Better than anyone else now writing, challengers of unjust power and delusions; Chomsky combines indignation with he goes against every assumption about insight, erudition with moral passion. American altruism and humanitarianism. That is a difficult achievement, —EDWARD W. SAID and an encouraging one. THE —IN THESE TIMES For nearly thirty years now, Noam Chomsky has parsed the main proposition One of the West’s most influential of American power—what they do is intellectuals in the cause of peace. aggression, what we do upholds freedom— —THE INDEPENDENT with encyclopedic attention to detail and an unflagging sense of outrage. Chomsky is a global phenomenon . —UTNE READER perhaps the most widely read voice on foreign policy on the planet. ESSENTIAL [Chomsky] continues to challenge our —THE NEW YORK TIMES BOOK REVIEW assumptions long after other critics have gone to bed. He has become the foremost Chomsky’s fierce talent proves once gadfly of our national conscience. more that human beings are not —CHRISTOPHER LEHMANN-HAUPT, condemned to become commodities. THE NEW YORK TIMES —EDUARDO GALEANO HO NE OF THE WORLD’S most prominent NOAM CHOMSKY is Institute Professor of lin- Opublic intellectuals, Noam Chomsky has, in guistics at MIT and the author of numerous more than fifty years of writing on politics, phi- books, including For Reasons of State, American losophy, and language, revolutionized modern Power and the New Mandarins, Understanding linguistics and established himself as one of Power, The Chomsky-Foucault Debate: On Human the most original and wide-ranging political and Nature, On Language, Objectivity and Liberal social critics of our time. -

Adobe Font Folio Opentype Edition 2003
Adobe Font Folio OpenType Edition 2003 The Adobe Folio 9.0 containing PostScript Type 1 fonts was replaced in 2003 by the Adobe Folio OpenType Edition ("Adobe Folio 10") containing 486 OpenType font families totaling 2209 font styles (regular, bold, italic, etc.). Adobe no longer sells PostScript Type 1 fonts and now sells OpenType fonts. OpenType fonts permit of encrypting and embedding hidden private buyer data (postal address, email address, bank account number, credit card number etc.). Embedding of your private data is now also customary with old PS Type 1 fonts, but here you can detect more easily your hidden private data. For an example of embedded private data see http://www.sanskritweb.net/forgers/lino17.pdf showing both encrypted and unencrypted private data. If you are connected to the internet, it is easy for online shops to spy out your private data by reading the fonts installed on your computer. In this way, Adobe and other online shops also obtain email addresses for spamming purposes. Therefore it is recommended to avoid buying fonts from Adobe, Linotype, Monotype etc., if you use a computer that is connected to the internet. See also Prof. Luc Devroye's notes on Adobe Store Security Breach spam emails at this site http://cgm.cs.mcgill.ca/~luc/legal.html Note 1: 80% of the fonts contained in the "Adobe" FontFolio CD are non-Adobe fonts by ITC, Linotype, and others. Note 2: Most of these "Adobe" fonts do not permit of "editing embedding" so that these fonts are practically useless. Despite these serious disadvantages, the Adobe Folio OpenType Edition retails presently (March 2005) at US$8,999.00. -
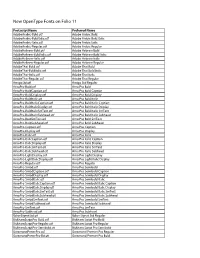
New Opentype Fonts on Folio 11
New OpenType Fonts on Folio 11 Postscript Name Preferred Name AdobeArabic-Bold.otf Adobe Arabic Bold AdobeArabic-BoldItalic.otf Adobe Arabic Bold Italic AdobeArabic-Italic.otf Adobe Arabic Italic AdobeArabic-Regular.otf Adobe Arabic Regular AdobeHebrew-Bold.otf Adobe Hebrew Bold AdobeHebrew-BoldItalic.otf Adobe Hebrew Bold Italic AdobeHebrew-Italic.otf Adobe Hebrew Italic AdobeHebrew-Regular.otf Adobe Hebrew Regular AdobeThai-Bold.otf Adobe Thai Bold AdobeThai-BoldItalic.otf Adobe Thai Bold Italic AdobeThai-Italic.otf Adobe Thai Italic AdobeThai-Regular.otf Adobe Thai Regular AmigoStd.otf Amigo Std Regular ArnoPro-Bold.otf Arno Pro Bold ArnoPro-BoldCaption.otf Arno Pro Bold Caption ArnoPro-BoldDisplay.otf Arno Pro Bold Display ArnoPro-BoldItalic.otf Arno Pro Bold Italic ArnoPro-BoldItalicCaption.otf Arno Pro Bold Italic Caption ArnoPro-BoldItalicDisplay.otf Arno Pro Bold Italic Display ArnoPro-BoldItalicSmText.otf Arno Pro Bold Italic SmText ArnoPro-BoldItalicSubhead.otf Arno Pro Bold Italic Subhead ArnoPro-BoldSmText.otf Arno Pro Bold SmText ArnoPro-BoldSubhead.otf Arno Pro Bold Subhead ArnoPro-Caption.otf Arno Pro Caption ArnoPro-Display.otf Arno Pro Display ArnoPro-Italic.otf Arno Pro Italic ArnoPro-ItalicCaption.otf Arno Pro Italic Caption ArnoPro-ItalicDisplay.otf Arno Pro Italic Display ArnoPro-ItalicSmText.otf Arno Pro Italic SmText ArnoPro-ItalicSubhead.otf Arno Pro Italic Subhead ArnoPro-LightDisplay.otf Arno Pro Light Display ArnoPro-LightItalicDisplay.otf Arno Pro Light Italic Display ArnoPro-Regular.otf Arno Pro Regular ArnoPro-Smbd.otf -

264 Tugboat, Volume 37 (2016), No. 3 Typographers' Inn Peter Flynn
264 TUGboat, Volume 37 (2016), No. 3 A Typographers’ Inn X LE TEX Peter Flynn Back at the ranch, we have been experimenting with X LE ATEX in our workflow, spurred on by two recent Dashing it off requests to use a specific set of OpenType fonts for A I recently put up a new version of Formatting Infor- some GNU/Linux documentation. X LE TEX offers A mation (http://latex.silmaril.ie), and in the two major improvements on pdfLTEX: the use of section on punctuation I described the difference be- OpenType and TrueType fonts, and the handling of tween hyphens, en rules, em rules, and minus signs. UTF-8 multibyte characters. In particular I explained how to type a spaced Font packages. You can’t easily use the font pack- dash — like that, using ‘dash~---Ђlike’ to put a A ages you use with pdfLTEX because the default font tie before the dash and a normal space afterwards, encoding is EU1 in the fontspec package which is key so that if the dash occurred near a line-break, it to using OTF/TTF fonts, rather than the T1 or OT1 would never end up at the start of a line, only at A conventionally used in pdfLTEX. But late last year the end. I somehow managed to imply that a spaced Herbert Voß kindly posted a list of the OTF/TTF dash was preferable to an unspaced one (probably fonts distributed with TEX Live which have packages because it’s my personal preference, but certainly A of their own for use with X LE TEX [6]. -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

The Selnolig Package: Selective Suppression of Typographic Ligatures*
The selnolig package: Selective suppression of typographic ligatures* Mico Loretan† 2015/10/26 Abstract The selnolig package suppresses typographic ligatures selectively, i.e., based on predefined search patterns. The search patterns focus on ligatures deemed inappropriate because they span morpheme boundaries. For example, the word shelfful, which is mentioned in the TEXbook as a word for which the ff ligature might be inappropriate, is automatically typeset as shelfful rather than as shelfful. For English and German language documents, the selnolig package provides extensive rules for the selective suppression of so-called “common” ligatures. These comprise the ff, fi, fl, ffi, and ffl ligatures as well as the ft and fft ligatures. Other f-ligatures, such as fb, fh, fj and fk, are suppressed globally, while making exceptions for names and words of non-English/German origin, such as Kafka and fjord. For English language documents, the package further provides ligature suppression rules for a number of so-called “discretionary” or “rare” ligatures, such as ct, st, and sp. The selnolig package requires use of the LuaLATEX format provided by a recent TEX distribution, e.g., TEXLive 2013 and MiKTEX 2.9. Contents 1 Introduction ........................................... 1 2 I’m in a hurry! How do I start using this package? . 3 2.1 How do I load the selnolig package? . 3 2.2 Any hints on how to get started with LuaLATEX?...................... 4 2.3 Anything else I need to do or know? . 5 3 The selnolig package’s approach to breaking up ligatures . 6 3.1 Free, derivational, and inflectional morphemes . -

Green Illusions Is Not a Litany of Despair
“In this terrific book, Ozzie Zehner explains why most current approaches to the world’s gathering climate and energy crises are not only misguided but actually counterproductive. We fool ourselves in innumerable ways, and Zehner is especially good at untangling sloppy thinking. Yet Green Illusions is not a litany of despair. It’s full of hope—which is different from false hope, and which requires readers with open, skeptical minds.”— David Owen, author of Green Metropolis “Think the answer to global warming lies in solar panels, wind turbines, and biofuels? Think again. In this thought-provoking and deeply researched critique of popular ‘green’ solutions, Zehner makes a convincing case that such alternatives won’t solve our energy problems; in fact, they could make matters even worse.”—Susan Freinkel, author of Plastic: A Toxic Love Story “There is no obvious competing or comparable book. Green Illusions has the same potential to sound a wake-up call in the energy arena as was observed with Silent Spring in the environment, and Fast Food Nation in the food system.”—Charles Francis, former director of the Center for Sustainable Agriculture Systems at the University of Nebraska “This is one of those books that you read with a yellow marker and end up highlighting most of it.”—David Ochsner, University of Texas at Austin Green Illusions Our Sustainable Future Series Editors Charles A. Francis University of Nebraska–Lincoln Cornelia Flora Iowa State University Paul A. Olson University of Nebraska–Lincoln The Dirty Secrets of Clean Energy and the Future of Environmentalism Ozzie Zehner University of Nebraska Press Lincoln and London Both text and cover are printed on acid-free paper that is 100% ancient forest free (100% post-consumer recycled). -

Massxpert User Manual
massXpert is part of the msXpertSuite sofware package Modelling, simulating and analyzing ionized ying species massXpert User Manual Modelling and simulation of mass spectrometric data of linear polymers massXpert 5.7.0 massXpert User Manual: Modelling and simulation of mass spectrometric data of linear polymers by Filippo Rusconi January 15, 2019 , 5.7.0 Copyright 2009,...,2019 Filippo Rusconi msXpertSuite - mass spectrometry sofware suite http://www.msxpertsuite.org/ This book is part of the msXpertSuite project. The msXpertSuite project is the successor of the massXpert project. This project now includes various independent modules: massXpert, program to model polymer chemistries and simulate mass spectrometric data; mineXpert, program to visualize and mine mass spectral data (mass spectrum, drif spectrum, XIC chromatograms) starting from the TIC chromatogram. This program is free sofware: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Sofware Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program. If not, see http:// www.gnu.org (http://www.gnu.org/licenses/) . The ying frog picture is courtesy http://www.papuaweb.org . The specic license as of 20190104 is: Please acknowledge the use of Papuaweb resources in your publications. To do this include the complete item URL (for example "http:// www.papuaweb.org/gb/ref/hinton-1974/63.html") or a general reference to "http://www.papuaweb.org" in your citation/ bibliography. -

Junicode 1234567890 ¼ ½ ¾ ⅜ ⅝ 27/64 ⅟7⒉27 (Smcp) C2sc Ff Ffi Ffl Fi Fl
Various glyphs accessed through OpenType tags in five different fonts: Junicode 1234567890 ¼ ½ ¾ ⅜ ⅝ 27/64 ⅟7⒉27 (smcp) c2sc ff ffi ffl fi fl Qu Th ct ſpecieſ ſſ ſſi ſſlſiſl ⁰¹²³⁴⁵⁶⁷⁸⁹⁺-⁼⁽⁾ⁿ ₀₁₂₃₄₅₆₇₈₉₊-₌₍₎ H₂O EB Garamond 1234567890 1234567890 1234567890 1234567890 1⁄4 1⁄2 3⁄4 3⁄8 5⁄8 27⁄64 1⁄72.27 small caps (smcp) SMALL CAPS (c2sc) ff ffi ffl fi fl Quo Th ct ſt ſpecies ſs ſſa ſſi ſſl ſi ſl 0123456789+-=()n 0123456789+-=() 1st 2nd 3rd H2O H2SO4 Sorts Mill Goudy 1234567890 1234567890 1⁄4 1⁄2 3⁄4 3⁄8 5⁄8 27⁄64 1⁄72.27 small caps (smcp) small caps (c2sc) ff ffi ffl fi fl QuThctſt ſpecieſ ſſ ſſi ſſ l ſi ſ l 0123456789+-=()n 0123456789+-=() H2O IM FELL English 1234567890 small caps (smcp) ff ffi ffl fi fl Qu Th ct ſtſpecies ß ſſa ſſi ſſl ſiſl Cardo 1234567890 1234567890 Sᴍᴀᴌᴌ ᴄᴀᴘS (smcp) ff ffi ffl fi fl Qu ſt ſpecieſ ſſ ſſi ſſlſiſl Not all the fonts have the same tags e.g. EB Garamond is the only font with four numeral variants and the ordn tag, Junicode and Cardo don’t have the sinf tag. IM Fell and EB Garamond are clever enough to distinguish between initial and medial ſ and terminal s. Junicode and Cardo are the only two fonts in which all the glyphs survive being copied and pasted into a word processor.* * In Word 2003 running on Windows 7 at least. 1 Other methods of setting fractions ⒤ using TEX math mode (ii) using the Eplain \frac macro (iii) using the font’s own pre-composed action glyphs (iv) using the numr and dnom OpenType tags (if the font has these) ⒱ using the OpenType frac tag as in the previous examples. -

Using Opentype Features in Libreofiie
Using OpenType Features in LibreOfiie David J. Perry Ver. 1.2 updated August 4, 2017 Note: Part I provides background for those who have litle or no experience using OpenType. If you are already familiar with OpenType features and just want to learn how to access the in Libre# O$ce% you can go directly to Part II. tou might also need to read Part Ii if you have worked with OT features through a graphical interface rather than by using four-character codes. N.B.: names o keys on the key#oard are s"o$n in smal% capitals (enter, tab, etc.(. I. About OpenType A. Introduction )penType (ab#reviated O* herea+er( is a font te&"no%ogy t"at enab%es t"e appearance o &"aracters to be c"anged without altering the under%ying te,t. W"y wou%d one want su&" a thing? /n some languages, c"aracters may need to be res"aped depending on conte,t. In Arabi&, for instance, le0ers have diferent s"apes depending on w"ether t"ey come at the beginning o a $ord, in t"e midd%e, or at the end. Te user types a le0er and t"e appropriate s"ape is dis3 p%ayed. In languages li!e Arabi&, the operating system automati&al%y app%ies the needed O* eatures wit"out intervention by the user. Windo$s and Linu, use O* to support su&" com3 p%e, s&ripts (5ac O6 X uses a diferent te&"no%ogy for this(. /n languages t"at do not re8uire res"aping, O* provides ac&ess to many re9nements tradition3 al%y used in hig"38ua%ity typograp"y. -

Abcdefghijklmnopqrstuv
UNIVERSITY OF CALIFORNIA, RIVERSIDE Visual Identity Guidelines June 15, 2020 TABLE of contents Table of Contents Pg 2 Introduction Pg 3 Primary Color Palette Pg 4 Extended Color Palette Pg 5 SECTION 1 - Institutional Identity Pg 6 UCR Primary Logo - Horizontal Pg 7 UCR Primary Logo - Vertical Pg 8 UCR Monogram Pg 9 UCR Primary Logos - Minimum Size Requirement Pg 10 UCR Primary Logos - Area of Isolation Pg 11 UCR Primary Logos - Common Misuse Pg 12 UCR Primary Logos - Black and Grayscale Pg 13 Typography - Headline/Sub-Headline Pg 14 Typography - Body Copy Pg 15 College Logo Lockup - Horizontal Pg 16 College Logo Lockup - Vertical Pg 17 College Logo Lockup - Super Horizontal Pg 18 College Logo Lockup - Monogram Horizontal Pg 19 College Logo Lockup - Monogram Stacked Pg 20 SECTION 2 - University Seal Pg 21 UC Riverside Seal Pg 22 UC Riverside Seal - Area of Isolation Pg 23 UC Riverside Seal - Minimum Size Requirement Pg 23 UC Riverside Seal - Correct Cropping Pg 24 UC Riverside Seal - Common Misuse Pg 25 SECTION 3 - Patterns Pg 26 Pattern - Rising Ray of Light Pg 27 Pattern - Overlapping Shapes Pg 28 SECTION 4 - University Stationery Pg 29 Letterheads - Primary Version Pg 30 Letterheads - Secondary Version Pg 31 Letterheads - Second Page Pg 32 #10 Envelope Pg 32 Standard Business Cards - Horizontal Options Pg 33 Standard Business Cards - Vertical Options Pg 34 Double-Sided Business Cards - Horizontal Options Pg 35 Double-Sided Business Cards - Vertical Options Pg 36 UCR Sub-Brands & Brand Extensions Pg 37 UCR Anniversary Logos Pg 37 UC Riverside - Visual Identity Guidelines 2 Introduction WHY A UNIFIED IDENTITY? To convey an image consistent with who we are and to communicate effectively with many diverse constituents and key stakeholders, UC Riverside has established a unified institutional brand and marketing program. -

Visual Identity System
Visual Identity System Last Update: May 2020 Visual Identity Elements BEYOND THE ACADEMY PRIMARY IDENTITY This is the main logo of the Beyond The Academy brand. Its form represents transformation and the “breaking out” of established structures. BEYOND THE ACADEMY SECONDARY IDENTITY This graphic element can be used on it’s own, within existing branded environments. Note: This mark should never be used as the sole representation of Beyond The Academy. BEYOND THE ACADEMY WORD MARK A typography expression of the identity is available as a secondary identity element that can be used when space or context permits it. 2 Color System Primary Colors WARM BLACK WHITE RGB: 45, 42, 38 RGB: 255,255, 255 CMYK: 67, 64, 67, 67 CMYK: 0, 0, 0, 0 HTML: 2D2A26 HTML: FFFFFF Secondary Colors Gradients GREEN BLUE GREEN COOL GRADIENT RGB: 175, 204, 108 RGB: 127, 187, 176 A BLEND OF CMYK: 35, 4, 74, 0 CMYK: 51, 9, 34. 0 #AFCC6C AND #7FBBB0 HTML: AFCC6C HTML: 7FBBB0 LIGHT YELLOW WARM RED WARM GRADIENT RGB: 254, 240, 132 RGB: 229, 100, 37 A BLEND OF CMYK: 2, 1, 59. 0 CMYK: 5, 75, 100, 0 #FEF084 AND #E56425 HTML: FEF084 HTML: E56425 Color Hierarchy This visual represents how to consider the amount of each color when applying them within a branded environment. 3 Color Application For Visual Identity Elements (WARM) BLACK AND WHITE The Beyond The Academy visual identity elements are always applied in two brand colors: warm black and white. Either is appropriate, Choice should be informed by optimum contrast and legibility.