University of Southampton Research Repository Eprints Soton
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture Notes in Computer Science 6159 Commenced Publication in 1973 Founding and Former Series Editors: Gerhard Goos, Juris Hartmanis, and Jan Van Leeuwen
Lecture Notes in Computer Science 6159 Commenced Publication in 1973 Founding and Former Series Editors: Gerhard Goos, Juris Hartmanis, and Jan van Leeuwen Editorial Board David Hutchison Lancaster University, UK Takeo Kanade Carnegie Mellon University, Pittsburgh, PA, USA Josef Kittler University of Surrey, Guildford, UK Jon M. Kleinberg Cornell University, Ithaca, NY, USA Alfred Kobsa University of California, Irvine, CA, USA Friedemann Mattern ETH Zurich, Switzerland John C. Mitchell Stanford University, CA, USA Moni Naor Weizmann Institute of Science, Rehovot, Israel Oscar Nierstrasz University of Bern, Switzerland C. Pandu Rangan Indian Institute of Technology, Madras, India Bernhard Steffen TU Dortmund University, Germany Madhu Sudan Microsoft Research, Cambridge, MA, USA Demetri Terzopoulos University of California, Los Angeles, CA, USA Doug Tygar University of California, Berkeley, CA, USA Gerhard Weikum Max-Planck Institute of Computer Science, Saarbruecken, Germany Yeunsook Lee Z. Zenn Bien Mounir Mokhtari Jeong Tai Kim Mignon Park Jongbae Kim Heyoung Lee Ismail Khalil (Eds.) Aging Friendly Technology for Health and Independence 8th International Conference on Smart Homes and Health Telematics, ICOST 2010 Seoul, Korea, June 22-24, 2010 Proceedings 13 Volume Editors Yeunsook Lee Yonsei University, Seoul, Korea, [email protected] Z. Zenn Bien Ulsan National Institute of Science and Technology, Korea, [email protected] Mounir Mokhtari Institut Télécom SudParis, Evry, France, [email protected] Jeong Tai Kim Kyung -

Asia in Motion: Geographies and Genealogies
Asia in Motion: Geographies and Genealogies Organized by With support from from PRIMUS Visual Histories of South Asia Foreword by Christopher Pinney Edited by Annamaria Motrescu-Mayes and Marcus Banks This book wishes to introduce the scholars of South Asian and Indian History to the in-depth evaluation of visual research methods as the research framework for new historical studies. This volume identifies and evaluates the current developments in visual sociology and digital anthropology, relevant to the study of contemporary South Asian constructions of personal and national identities. This is a unique and excellent contribution to the field of South Asian visual studies, art history and cultural analysis. This text takes an interdisciplinary approach while keeping its focus on the visual, on material cultural and on art and aesthetics. – Professor Kamran Asdar Ali, University of Texas at Austin 978-93-86552-44-0 u Royal 8vo u 312 pp. u 2018 u HB u ` 1495 u $ 71.95 u £ 55 Hidden Histories Religion and Reform in South Asia Edited by Syed Akbar Hyder and Manu Bhagavan Dedicated to Gail Minault, a pioneering scholar of women’s history, Islamic Reformation and Urdu Literature, Hidden Histories raises questions on the role of identity in politics and private life, memory and historical archives. Timely and thought provoking, this book will be of interest to all who wish to study how the diverse and plural past have informed our present. Hidden Histories powerfully defines and celebrates a field that has refused to be occluded by majoritarian currents. – Professor Kamala Visweswaran, University of California, San Diego 978-93-86552-84-6 u Royal 8vo u 324 pp. -
Robust Copper Metal–Organic Framework-Embedded Polysiloxanes for Biomedical Applications: Its Antibacterial Effects on MRSA and in Vitro Cytotoxicity
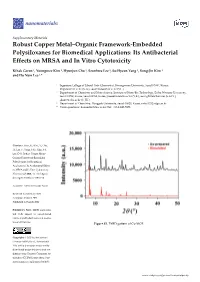
Supplementary Materials Robust Copper Metal–Organic Framework-Embedded Polysiloxanes for Biomedical Applications: Its Antibacterial Effects on MRSA and In Vitro Cytotoxicity Kihak Gwon 1, Youngmee Kim 2, Hyunjun Cho 3, Seonhwa Lee 1, So-Hyeon Yang 2, Sung-Jin Kim 2 and Do Nam Lee 1,* 1 Ingenium College of Liberal Arts (Chemistry), Kwangwoon University, Seoul 01897, Korea; [email protected] (K.G.); [email protected] (S.L.) 2 Department of Chemistry and Nano Science, Institute of Nano-Bio Technology, Ewha Womans University, Seoul 03760, Korea, Seoul 03760, Korea; [email protected] (Y.K.); [email protected] (S.-H.Y.); [email protected] (S.-J.K.) 3 Department of Chemistry, Dongguk University, Seoul 04620, Korea; [email protected] * Correspondence: [email protected]; Tel.: +82-2-940-5658 Citation: Gwon, K.; Kim, Y.; Cho, H.; Lee, S.; Yang, S.-H.; Kim, S.-J; Lee, D.N. Robust Copper Metal– Organic Framework-Embedded Polysiloxanes for Biomedical Applications: Its Antibacterial Effects on MRSA and In Vitro Cytotoxicity. Nanomaterials 2021, 11, 719. https:// doi.org/10.3390/nano11030719 Academic Editor: Fernando Novio Received: 14 February 2021 Accepted: 8 March 2021 Published: 12 March 2021 Publisher’s Note: MDPI stays neu- tral with regard to jurisdictional claims in published maps and institu- tional affiliations. Figure S1. PXRD pattern of Cu-MOF. Copyright: © 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and con- ditions of the Creative Commons At- tribution (CC BY) license (http://cre- ativecommons.org/licenses/by/4.0/). -

Honorary Co-Chairs: Sadaoki Furui (Tokyo Institute of Technology, Japan) K.J. Ray Liu (University of Maryland, USA) Wan-Chi Si
Honorary Co-Chairs: Sadaoki Furui (Tokyo Institute of Technology, Japan) K.J. Ray Liu (University of Maryland, USA) Wan-Chi Siu (Hong Kong Polytechnic University, Hong Kong) Sang Uk Lee (Seoul National University, Korea) General Co-Chairs: Yo-Sung Ho (Gwangju Institute of Science and Technology, Korea) C.-C. Jay Kuo (University of Southern California, USA) Haizhou Li (Institute for Infocomm Research, A*STAR, Singapore) Technical Program Co-Chairs: Nam Ik Cho (Seoul National University, Korea) Thomas Fang Zheng (Tsinghua University, China) Hitoshi Kiya (Tokyo Metropolitan University, Japan) Chris Lee (National Cheng-Kung University, Taiwan) Akira Hirabayashi (Ritsumeikan University, Japan) Changchun Bao (Beijing University of Technology, China) Tomasz M. Rutkowski (University of Tsukuba, Japan) Supavadee Aramvith (Chulanlongkorn University, Thailand) Kazunori Hayashi (University of Kyoto, Japan) Invited Overview Session Co-Chairs: Changick Kim (Korea Advanced Institute of Science and Technology, Korea) Byeungwoo Jeon (Sungkyunkwan University, Korea) Kwanghoon Sohn (Yonsei University, Korea) Woon Seng Gan (Nanyang Technological University, Singapore) Waleed Abdulla (University of Auckland, New Zealand) Anthony Kuh (University of Hawaii at Manoa, USA) Jiwu Huang (Shenzhen University, China) Industrial Panel Session Co-Chairs: Shan Liu (MediaTek, USA) Nam Soo Kim (Seoul National University, Korea) Yong Man Ro (Korea Advanced Institute of Science and Technology, Korea) Wonha Kim (Kyung Hee University, Korea) Ming-Ting Sun (University of Washington, -

1997 Conference Program Book (Hangul)
W ELCOME Korea Teachers of English to Speakers of Other Languages 대한영어교육학회 1997 National Conference and Publishers Exposition Technology in Education; Communicating Beyond Traditional networks October 3-5, 1997 Kyoung-ju Education and Cultural Center Kyoung-ju, South Korea Conference Co-chairs; Demetra Gates Taegu University of Education Kari Kugler Keimyung Junior University, Taegu 1996-97 KOTESOL President; Park Joo-kyung Honam University, Kwangju 1997-98 KOTESOL President Carl Dusthimer Hannam University, Taejon Presentation Selection Committee: Carl Dusthimer, Student Coordination: Steve Garrigues Demetra Gates, Kari Kugler, Jack Large Registration: Rodney Gillett, AeKyoung Large, Jack Program: Robert Dickey, Greg Wilson Large, Lynn Gregory, Betsy Buck Cover: Everette Busbee International Affairs: Carl Dusthimer, Kim Jeong- ryeol, Park Joo Kyung, Mary Wallace Publicity: Oryang Kwon Managing Information Systems: AeKyoung Large, Presiders: Kirsten Reitan Jack Large, Marc Gautron, John Phillips, Thomas Special Events: Hee-Bon Park Duvernay, Kim Jeong-ryeol, Sung Yong Gu, Ryu Seung Hee, The Kyoung-ju Board Of Education W ELCOME DEAR KOTESOL MEMBERS, SPEAKERS, AND FRIENDS: s the 1997 Conference Co-Chairs we would like to welcome you to this year's conference, "Technology Ain Education: Communicating Beyond Traditional Networks." While Korea TESOL is one of the youngest TESOL affiliates in this region of the world, our goal was to give you one of the finest opportunities for professional development available in Korea. The 1997 conference has taken a significant step in this direction. The progress we have made in this direction is based on the foundation developed by the coachers of the past: our incoming President Carl Dusthimer, Professor Woo Sang-do, and Andy Kim. -

Communication and the City Intro&Schedulefinal
Schedule Communication and the City: The Role of the Community June 4 8:30am – 9:30am Registration 9:30am – 10:00am Opening Remarks Gary Gumpert (President of Urban Communication Foundation) Peter Haratonik (The New School, Executive Coordinator, Urban Communication Foundation) Yong-Chan Kim (Local Chair, Yonsei University) 10:00am – 11:00am Keynote Speech Professor Chang-Hyun Lee (Kookmin University) “Seoul storytelling in the age of risk society” 11:00am – 11:15am Break 11:15am – 12:15pm Paper session (1) Urban Media and Urban Politics Chair: Matthew Matsaganis (University at Albany-State University of New York) Intersection between urban communication and urban politics Yongjun Shin (Bridgewater State University) Cultural practices of community radio and its effectivity on local community members: A case study of Seoul’s Changshin-dong radio <Dum> Myeong Jin Ban (Hankuk University of Foreign Studies), Young Chan Kim (Hankuk University of Foreign Studies) Urban neighborhood media (UNM) in Seoul as community storytellers Yong-Chan Kim (Yonsei University), Young-Gil Chae (Hankuk University of Foreign Studies), Euojong Kim (Munhwa Broadcasting Corporation), Yeran Kim (Kwangwoon University), Young Min Baek (Yonsei University) 12:15pm – 1:15pm Lunch 1:15pm – 2:15pm Paper Session (2) Community engagement in urban neighborhoods 1 Chair: Younggil Chae (Hankuk University of Foreign Studies) Relating communication capital to residents’ civic engagement, community attachment and perceptions of the quality of life in urban areas Leo W Jeffres (Cleveland -

Chip-Package Hybrid Clock Distribution
274 IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL. 41, NO. 1, JANUARY 2006 Chip-Package Hybrid Clock Distribution Network and DLL for Low Jitter Clock Delivery Daehyun Chung, Chunghyun Ryu, Hyungsoo Kim, Choonheung Lee, Jinhan Kim, Kicheol Bae, Jiheon Yu, Hoijun Yoo, Senior Member, IEEE, and Joungho Kim Abstract—This paper presents a chip-package hybrid clock There are numerous noise coupling paths of the SSN to noise distribution network and delay-locked loop (DLL) with which to sensitive circuits, including clock generation circuits, such achieve extremely low jitter clock delivery. The proposed hybrid as phase-locked loops (PLLs) or delay-locked loops (DLLs). clock distribution network and DLL provide digital noise-free and low-jitter clock signals by utilizing lossless package layer Since they have either a voltage-controlled oscillator (VCO) or a interconnections instead of lossy on-chip global wires with cas- voltage controlled delay line (VCDL), both of which are highly caded repeaters. The lossless package layer interconnections sensitive to the power supply noise, the clock signal already become high-frequency waveguides and provide a repeater-free contains a small amount of jitter even immediately after being clock distribution network; thus, the clock signal becomes free of generated. However, the PLL or DLL circuits can be localized on-chip power supply noise. The proposed chip-package hybrid on an area of a chip, and the power supply to the PLL or DLL clock scheme has demonstrated a 78-ps peak-to-peak jitter at 500 MHz under a 240-mV on-chip simultaneous switching noise can be separated from other power supplies of noisy digital condition versus a conventional clock scheme, which produced a logic blocks. -

Seoul National University, Seoul, Korea
The Korea Association of Teachers of English 2014 International Conference Making Connections in ELT : Form, Meaning, and Functions July 4 (Friday) - July 5 (Saturday), 2014 Seoul National University, Seoul, Korea Hosted by Seoul National University Organized by The Korea Association of Teachers of English Department of English, Seoul National University Sponsored by The National Research Foundation of Korea Seoul National University Korea Institute for Curriculum and Evaluation British Council Korea Embassy of the United States International Communication Foundation CHUNGDAHM Learning English Mou Mou Hyundae Yong-O-Sa Daekyo ETS Global Neungyule Education Cambridge University Press YBM Sisa This work was supported by the National Research Foundation of Korea Grant funded by the Korean Government. 2014 KATE International Conference KATE Executive Board July 2012 - June 2014 President Junil Oh (Pukyong Nationa University) Vice Presidents - Journal Editing & Publication Jeongwon Lee (Chungnam National Univ) - Planning & Coordination Hae-Dong Kim (Hankuk University of Foreign Studies) - Research & Development Yong-Yae Park (Seoul National University) - Public Relations Seongwon Lee (Gyeonsang National University) - International Affairs & Information Jeongsoon Joh (Konkuk University) Secretary Generals Hee-Kyung Lee (Yonsei University) Hyunsook Yoon (Hankuk University of Foreign Studies) Treasurer Yunkyoung Cho (Pukyong National University) International Affairs Officers Hikyoung Lee (Korea University) Isaiah WonHo Yoo (Sogang University) -

Schedule of Accreditations, by Year and University
Comprehensive University Accreditation System Schedule of Accreditations, by Year and University Korean Council for University Education Center for University Accreditation 2nd Cycle Accreditations (2001-2006) Table 1a: General Accreditations, by Year Conducted Section(s) of University Evaluated # of Year Universities Undergraduate Colleges Undergraduate Colleges Only Graduate Schools Only Evaluated & Graduate Schools 2001 Kyungpook National University 1 2002 Chonbuk National University Chonnam National University 4 Chungnam National University Pusan National University 2003 Cheju National University Mokpo National University Chungbuk National University Daegu University Daejeon University 9 Kangwon National University Korea National Sport University Sunchon National University Yonsei University (Seoul campus) 2004 Ajou University Dankook University (Cheonan campus) Mokpo National University 41 1 Name changed from Kyungsan University to Daegu Haany University in May 2003. 1 Andong National University Hanyang University (Ansan campus) Catholic University of Daegu Yonsei University (Wonju campus) Catholic University of Korea Changwon National University Chosun University Daegu Haany University1 Dankook University (Seoul campus) Dong-A University Dong-eui University Dongseo University Ewha Womans University Gyeongsang National University Hallym University Hanshin University Hansung University Hanyang University Hoseo University Inha University Inje University Jeonju University Konkuk University Korea -

KOREA at SOAS Centre of Korean Studies, SOAS Annual Review ISSUE 3: September 2009 - August 2010 SOAS
SCHOOL OF ORIENTAL AND AFRICAN STUDIES KOREA at SOAS Centre of Korean Studies, SOAS Annual Review ISSUE 3: September 2009 - August 2010 SOAS The School of Oriental and African Studies (SOAS) is a college of the University of London and the only Higher Education institution in the UK specialising in the study of Asia, Africa and the Near and Middle East. SOAS is a remarkable institution. Uniquely combining language scholarship, disciplinary expertise and regional focus, it has the largest concentration in Europe of academic staff concerned with Africa, Asia and the Middle East. On the one hand, this means that SOAS remains a guardian of specialised knowledge in languages and periods and regions not available anywhere else in the UK. On the other hand, it means that SOAS scholars grapple with pressing issues - democracy, development, human rights, identity, STUDYING AT SOAS legal systems, poverty, religion, social change - confronting two-thirds of humankind. The international environment and cosmopolitan character of the School make student life a challenging, rewarding and exciting experience. We This makes SOAS synonymous with intellectual excitement and welcome students from more than 100 countries, and more than 35% of achievement. It is a global academic base and a crucial resource for them are from outside the UK. London. We live in a world of shrinking borders and of economic and technological simultaneity. Yet it is also a world in which difference The SOAS Library has more than 1.2 million items and extensive and regionalism present themselves acutely. It is a world that SOAS is electronic resources. It is the national library the study of Africa, Asia and distinctively positioned to analyse, understand and explain. -

College Codes (Outside the United States)
COLLEGE CODES (OUTSIDE THE UNITED STATES) ACT CODE COLLEGE NAME COUNTRY 7143 ARGENTINA UNIV OF MANAGEMENT ARGENTINA 7139 NATIONAL UNIVERSITY OF ENTRE RIOS ARGENTINA 6694 NATIONAL UNIVERSITY OF TUCUMAN ARGENTINA 7205 TECHNICAL INST OF BUENOS AIRES ARGENTINA 6673 UNIVERSIDAD DE BELGRANO ARGENTINA 6000 BALLARAT COLLEGE OF ADVANCED EDUCATION AUSTRALIA 7271 BOND UNIVERSITY AUSTRALIA 7122 CENTRAL QUEENSLAND UNIVERSITY AUSTRALIA 7334 CHARLES STURT UNIVERSITY AUSTRALIA 6610 CURTIN UNIVERSITY EXCHANGE PROG AUSTRALIA 6600 CURTIN UNIVERSITY OF TECHNOLOGY AUSTRALIA 7038 DEAKIN UNIVERSITY AUSTRALIA 6863 EDITH COWAN UNIVERSITY AUSTRALIA 7090 GRIFFITH UNIVERSITY AUSTRALIA 6901 LA TROBE UNIVERSITY AUSTRALIA 6001 MACQUARIE UNIVERSITY AUSTRALIA 6497 MELBOURNE COLLEGE OF ADV EDUCATION AUSTRALIA 6832 MONASH UNIVERSITY AUSTRALIA 7281 PERTH INST OF BUSINESS & TECH AUSTRALIA 6002 QUEENSLAND INSTITUTE OF TECH AUSTRALIA 6341 ROYAL MELBOURNE INST TECH EXCHANGE PROG AUSTRALIA 6537 ROYAL MELBOURNE INSTITUTE OF TECHNOLOGY AUSTRALIA 6671 SWINBURNE INSTITUTE OF TECH AUSTRALIA 7296 THE UNIVERSITY OF MELBOURNE AUSTRALIA 7317 UNIV OF MELBOURNE EXCHANGE PROGRAM AUSTRALIA 7287 UNIV OF NEW SO WALES EXCHG PROG AUSTRALIA 6737 UNIV OF QUEENSLAND EXCHANGE PROGRAM AUSTRALIA 6756 UNIV OF SYDNEY EXCHANGE PROGRAM AUSTRALIA 7289 UNIV OF WESTERN AUSTRALIA EXCHG PRO AUSTRALIA 7332 UNIVERSITY OF ADELAIDE AUSTRALIA 7142 UNIVERSITY OF CANBERRA AUSTRALIA 7027 UNIVERSITY OF NEW SOUTH WALES AUSTRALIA 7276 UNIVERSITY OF NEWCASTLE AUSTRALIA 6331 UNIVERSITY OF QUEENSLAND AUSTRALIA 7265 UNIVERSITY -

Jiman Hong Ph.D./Professor Director, Embedded Operating System Research Institute E-Mail : [email protected] Homepage
Jiman Hong Ph.D./Professor Director, Embedded Operating System Research Institute E-mail : [email protected] HomePage : http://eoslab.kw.ac.kr/∼gman/ Work Address Home Address School of Computer Science and Engineering 103-ho 106-dong Dong-A Apt Kwangwoon University Bongchun-dong, Kwanak-gu Seoul Korea Seoul 151-762 Korea Voice : +82-2-940-5652 Voice : +82-2-874-0789 Fax :+82-2-909-5670 Cellular Phone : +82-11-706-8864 Research Interest Operating Systems, Embedded Operating Systems Fault Tolerance Systems Mobile Computing, Ubiquitous Computing, Sensor Network Education Seoul National University Ph.D in Computer Science and Engineering, Feb. 1997 Seoul National University Master in Computer Science and Engineering, Feb. 1994 Korea University Bachelor in Computer Science and Engineering, Feb. 1991 Experience Institute of Computer Technology, Seoul National University, Seoul Korea 1995–1997 Senior Researcher GmanTech Inc., Seoul Korea 2000–2003 Chief of Technical Officer Infomore Inc., Seoul Korea 1997–2000 Senior Researcher, R&D center Awards Won a grand prize at the 2nd Linux software contest by Minister of Informa- tion and Communication, Korea, 2001 Research Projects MDS Technology Inc. Project Manager 2005 2007 Projects : Design and Implementation of NanoRTOS HM Soft Inc. Project Manager 2005 2006 Projects : Email Marketing Server Engine for Linux Operating System Ministry of Commerce, Industry and Energy Vice Project Manager, 2003 2007 Projects : 3GSM Phone Development and Design Education Program Ministry of Commerce, Industry and Energy Senior Researcher, 2004 2008 Projects : System Development and Design Education Program Ministry of Commerce, Industry and Energy Researcher, 2003 Projects : System Development Education Program Institute of Computer Technology, Seoul National University Researcher 2000-2003 Projects : An Efficient System Management Tools BIT Computer Inc.