A Library for Generating Character Bitmaps from Adobe Type 1 Fonts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WORDS MADE FLESH Code, Culture, Imagination Florian Cramer
WORDS MADE FLESH Code, Culture, Imagination Florian Cramer Me dia De s ign Re s e arch Pie t Z w art Ins titute ins titute for pos tgraduate s tudie s and re s e arch W ille m de Kooning Acade m y H oge s ch ool Rotte rdam 3 ABSTRACT: Executable code existed centuries before the invention of the computer in magic, Kabbalah, musical composition and exper- imental poetry. These practices are often neglected as a historical pretext of contemporary software culture and electronic arts. Above all, they link computations to a vast speculative imagination that en- compasses art, language, technology, philosophy and religion. These speculations in turn inscribe themselves into the technology. Since even the most simple formalism requires symbols with which it can be expressed, and symbols have cultural connotations, any code is loaded with meaning. This booklet writes a small cultural history of imaginative computation, reconstructing both the obsessive persis- tence and contradictory mutations of the phantasm that symbols turn physical, and words are made flesh. Media Design Research Piet Zwart Institute institute for postgraduate studies and research Willem de Kooning Academy Hogeschool Rotterdam http://www.pzwart.wdka.hro.nl The author wishes to thank Piet Zwart Institute Media Design Research for the fellowship on which this book was written. Editor: Matthew Fuller, additional corrections: T. Peal Typeset by Florian Cramer with LaTeX using the amsbook document class and the Bitstream Charter typeface. Front illustration: Permutation table for the pronounciation of God’s name, from Abraham Abulafia’s Or HaSeichel (The Light of the Intellect), 13th century c 2005 Florian Cramer, Piet Zwart Institute Permission is granted to copy, distribute and/or modify this document under the terms of any of the following licenses: (1) the GNU General Public License as published by the Free Software Foun- dation; either version 2 of the License, or any later version. -

Bitstream Fonts in May 2005 at Totaling 350 Font Families with a Total of 1357 Font Styles
Bitstream Fonts in May 2005 at http://www.myfonts.com/fonts/bitstream totaling 350 font families with a total of 1357 font styles The former Bitstream typeface libraries consisted mainly of forgeries of Linotype fonts and of ITC fonts. See the list below on the pages 24–29 about the old Bitstream Typeface Library of 1992. The 2005 Bitstream typeface library contains the same forgeries of Linotype fonts as formerly and also the same ITC fonts, but it also includes a lot of new mediocre „rubbish fonts“ (e.g. „Alphabet Soup“, „Arkeo“, „Big Limbo“), but also a few new quality fonts (e.g. „Drescher Grotesk“, „Prima Serif“ etc.). On the other hand, a few old fonts (e.g. „Caxton“) were removed. See the list below on pages 1–23. The typeface collection of CorelDraw comprises almost the entire former old Bitstream typeface library (see the list below on pages 24–29) with the following exceptions: 1. A few (ca. 3) forgeries of Linotype fonts are missing in the CorelDraw font collections, e.g. the fonts „Baskerville No. 2“ (= Linotype Baskerville No. 2), „Italian Garamond“ (= Linotype Garamond Simoncini), and „Revival 555“ (= Linotype Horley Old Style). 2. A lot (ca. 11) of ITC fonts are not contained in the CorelDraw font collections, e.g. „ITC Berkeley Oldstyle“, „ITC Century“, „ITC Clearface“, „ITC Isbell“, „ITC Italia“, „ITC Modern No. 216“, „ITC Ronda“, „ITC Serif Gothic“, „ITC Tom’s Roman“, „ITC Zapf Book“, and „ITC Zapf International“. Ulrich Stiehl, Heidelberg 3-May 2005 Aachen – 2 styles Ad Lib™ – 1 styles Aerospace Pi – 1 styles Aldine -

Chapter 13, Using Fonts with X
13 Using Fonts With X Most X clients let you specify the font used to display text in the window, in menus and labels, or in other text fields. For example, you can choose the font used for the text in fvwm menus or in xterm windows. This chapter gives you the information you need to be able to do that. It describes what you need to know to select display fonts for use with X client applications. Some of the topics the chapter covers are: The basic characteristics of a font. The font-naming conventions and the logical font description. The use of wildcards and aliases for simplifying font specification The font search path. The use of a font server for accessing fonts resident on other systems on the network. The utilities available for managing fonts. The use of international fonts and character sets. The use of TrueType fonts. Font technology suffers from a tension between what printers want and what display monitors want. For example, printers have enough intelligence built in these days to know how best to handle outline fonts. Sending a printer a bitmap font bypasses this intelligence and generally produces a lower quality printed page. With a monitor, on the other hand, anything more than bitmapped information is wasted. Also, printers produce more attractive print with variable-width fonts. While this is true for monitors as well, the utility of monospaced fonts usually overrides the aesthetic of variable width for most contexts in which we’re looking at text on a monitor. This chapter is primarily concerned with the use of fonts on the screen. -

P Font-Change Q UV 3
p font•change q UV Version 2015.2 Macros to Change Text & Math fonts in TEX 45 Beautiful Variants 3 Amit Raj Dhawan [email protected] September 2, 2015 This work had been released under Creative Commons Attribution-Share Alike 3.0 Unported License on July 19, 2010. You are free to Share (to copy, distribute and transmit the work) and to Remix (to adapt the work) provided you follow the Attribution and Share Alike guidelines of the licence. For the full licence text, please visit: http://creativecommons.org/licenses/by-sa/3.0/legalcode. 4 When I reach the destination, more than I realize that I have realized the goal, I am occupied with the reminiscences of the journey. It strikes to me again and again, ‘‘Isn’t the journey to the goal the real attainment of the goal?’’ In this way even if I miss goal, I still have attained goal. Contents Introduction .................................................................................. 1 Usage .................................................................................. 1 Example ............................................................................... 3 AMS Symbols .......................................................................... 3 Available Weights ...................................................................... 5 Warning ............................................................................... 5 Charter ....................................................................................... 6 Utopia ....................................................................................... -

(2009), No. 2 TEX People: the TUG Interviews Project and Book Karl
196 TUGboat, Volume 30 (2009), No. 2 TEX People: The TUG interviews project 2 The interview method and book Interview subjects are1 chosen based on (a) seeking Karl Berry and David Walden diversity in many dimensions, (b) recommendations from people about who should be interviewed, and Abstract (c) potential interview subjects being willing to be We present the history and evolution of the TUG interviewed. interviews project. We discuss the interviewing pro- The interviews have almost all been done via cess as well as our methods for creating web pages exchange of email using plain text; a couple of ex- and a printed book from the interviews, using m4 as ceptions were done in LATEX. a preprocessor targeting either HTML or LATEX. We For the first several interviews, Dave sent a also describe some business decisions relating to the more or less complete list of questions (once the book. We don't claim great generality for what we interviewee agreed to participate), on the theory that have done, but we hope some of our experience will this would minimize the burden on the interviewee. be educational. However, having a dozen questions to answer at one time proved to be daunting to interviewees. Thus, Dave switched to a process wherein he sent a couple of standard initial questions (namely, \Tell me a 1 Introduction bit about yourself and your history outside of TEX," Dave had two ideas in mind when he suggested (orig- and \How and when did you first get involved with inally to Karl) this interview series in 2004: (a) tech- TEX?"). -

Optimal Use of Fonts on Linux
Optimal Use of Fonts on Linux Avi Alkalay Donovan Rebbechi Hal Burgiss Copyright © 2006 Avi Alkalay, Donovan Rebbechi, Hal Burgiss 2007−04−15 Revision History Revision 2007−04−15 15 Apr 2007 Revised by: avi Included support to SUSE installation for the RPM scriptlets on template spec file, listed SUSE as a BCI−enabled distro. Revision 2007−02−08 08 Feb 2007 Revised by: avi Fixed some typos, updated Luc's page URL, added DejaVu sections, added link to FC6 Freetype RPMs, added link to Debian MS Core fonts, and added reference to the gnome−font−properties command. Revision 2006−07−02 02 Jul 2006 Revised by: avi Included link to Debian FreeType BCI package, improved the glossary with Latin1 descriptions, more clear links on the webcore fonts section, instructions on how to rebuild source RPM packages in the BCI appendix, updated the freetype recompilation appendix to cover new versions of the lib, authorship section reorganized. Revision 2006−04−02 02 Apr 2006 Revised by: avi Included link to FC5 Freetype.bci contribution by Cody DeHaan. Revision 2006−03−25 25 Mar 2006 Revised by: avi Updated link to BCI Freetype RPMs to be more distro version specific. Revision 2005−07−19 19 May 2005 Revised by: avi Renamed Microsoft Fonts to Webcore Fonts, and links updated.Added X.org Subsystems section. Revision 2005−05−25 25 May 2005 Revised by: avi Comment related to web pages in the Microsoft Fonts section Revision 2005−05−10 10 May 2005 Revised by: avi Old section−based glossary converted to real DocBook glossary.Modernized terms and explanations on the glossary.Included concepts as charsets, Unicode and UTF−8 in the glossary. -

GET, Arris QAM Gateway, DTV Decoder SW
Open Source Used In SUNGW CUG- 96.1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-151990932 Open Source Used In SUNGW CUG-96.1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-151990932 Contents 1.1 ASN1C 0.9.23 1.1.1 Available under license 1.2 BSD Readelf.h NON_PRISTINE 1.9 1.2.1 Available under license 1.3 busybox 1.18.5 1.3.1 Available under license 1.4 cjson 2009 1.4.1 Available under license 1.5 crc32 1.1.1.1 1.5.1 Available under license 1.6 curl 7.26.0 1.6.1 Available under license 1.7 EGL headers 1.4 1.7.1 Available under license 1.8 expat 2.1.0 1.8.1 Available under license 1.9 ffmpeg 0.11.1 1.9.1 Available under license 1.10 flex 2.5.35 1.10.1 Available under license 1.11 freeBSD 4.8 :distro-fusion 1.11.1 Available under license 1.12 FREETYPE2 2.4.4 1.12.1 Available under license 1.13 iptables 1.4.1 1.13.1 Available under license Open Source Used In SUNGW CUG-96.1 2 1.14 isc dhcp 4.1-ESV-R4 1.14.1 Available under license 1.15 -

„Bitstream“ Fonts
Key to the „Bitstream“ Fonts The history of typefaces is the history of forgeries. One of the greatest forgers of the 20th century was Matthew Carter. The Bitstream website (http://www.myfonts.com) describes him as follows: Matthew Carter of United Kingdom. Born: 1937 Son of Harry Carter, Royal Designer for Industry, contemporary British type designer and ultimate craftsman, trained as a punchcutter at Enschedé by Paul Rädisch, responsible for Crosfield's typographic program in the early 1960s, Mergenthaler Linotype's house designer 1965-1981. Carter co-founded Bitstream with Mike Parker in 1981. In 1991 he left Bitstream to form Carter & Cone with Cherie Cone. In 1997 he was awarded the TDC Medal, the award from the Type Directors Club presented to those „who have made significant contributions to the life, art, and craft of typography“. Carter’s „significant contribution to the life, art, and craft of typography“ consisted of forging the Linotype typeface collection. Carter can be characterized as a split personality. On the one hand, he has designed several original typefaces. On the other hand, he has forged hundreds of fonts. The following lists reveal that ca. 90% of the „Bitstream“ fonts are forgeries of the fonts contained in the catalog „LinoTypeCollection 1987“ („Mergenthaler Type Library“), i.e. the „Bitstream“ fonts are „nefarious evil knock-off clones“ (Bruno Steinert) of fonts sold by Linotype in the mid-1980s.1 „L“ in the following lists denotes that the font is contained in the „LinoTypeCollection 1987“. In the mid-1980s, the Linotype library comprised hundreds of typefaces with a total of 1700 fonts. -

Open Source Used in Cisco Video Surveillance 3000 Series IP Cameras
Open Source Used In Cisco Video Surveillance 3000 Series IP Cameras Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-48273221 Open Source Used In Cisco Video Surveillance 3000 Series IP Cameras 1 This document contains the licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of the source code to which you are entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-48273221 Contents 1.1 base64 0.00.00B 1.1.1 Available under license 1.2 bridge-utils 1.1 1.2.1 Available under license 1.3 busybox 1.12.4 1.3.1 Available under license 1.4 cmake 2.8 1.4.1 Available under license 1.5 cron 1.0 1.5.1 Available under license 1.6 curl 7.30.0 1.6.1 Available under license 1.7 Denx uboot U-Boot-1.3.4 1.7.1 Available under license 1.8 DHCP server and client 0.9.8 1.8.1 Available under license 1.9 dhcpv6 20051211 1.9.1 Available under license 1.10 dibbler 0.7.1 1.10.1 Available under license 1.11 ebtables 2.0.8-2 1.11.1 Available under license 1.12 eventlog 0.2.5 1.12.1 Available under license 1.13 fcgi 2.4.1 1.13.1 Available under license Open Source Used In Cisco Video Surveillance -
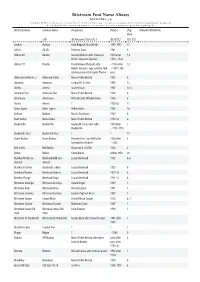
Bitstream Font Name Aliases Fontotéka 3.0 Compiled by Petr Somol, Based on Jon A
Bitstream Font Name Aliases fontotéka 3.0 Compiled by Petr Somol, based on Jon A. Pastor‘s list from http://cgm.cs.mcgill.ca/~luc/jonpastor.txt. E-mail: [email protected] The list should not be considered complete, nor accurate. It is more a work in progress than anything else. Bitstream Name Common Name Designer(s) Date(s) Orig. Remarks/Attributions Vend. (all) (M.Macrone/J.Pastor,P.S.) (M.M,P.S.) (J.P., P.S.) Aachen Aachen Colin Brignall, Alan Meeks 1969-1977 17 Ad Lib Ad Lib Freeman Craw 1961 6 Aldine 401 Bembo Stanley Morison after Francesco 1929 after 1,4 Griffo / Giovanni Tagliente 1495 / 1520 Aldine 721 Plantin Frank Hinman Pierpont after ~1930 after 1,4 Robert Granjon‘s type used by 16th ~1550 / 16h century printer Christophe Plantin cent. Alternate Gothic No. 2 Alternate Gothic Morris Fuller Benton 1903 6 Amazone Amazone Leonard H. D. Smit 1958 12 Amelia Amelia Stanley Davis 1967 18, 2 American Text American Text Morris Fuller Benton 1932 6 Americana Americana Richard Isbell, Whedon Davis 1965 6 Aurora Aurora ? 1928 (c.) 11 Baker Signet Baker Signet Arthur Baker 1965 18 Balloon Balloon Max R. Kaufmann 1939 6 Bank Gothic Bank Gothic Morris Fuller Benton 1930-33 6 Baskerville Baskerville George W. Jones after John 1929 after 2 Baskerville ~1754-1775 Baskerville No.2 Baskerville No.2 ? ? 19 Bauer Bodoni Bauer Bodoni Heinrich Jost, Louis Höll after 1926 after 8 Giambattista Bodoni ~1800 Bell Gothic Bell Gothic Chauncey H. Griffith 1938 2 Belwe Belwe Georg Belwe before 1950 20 Bernhard Bold Con- Bernhard Bold Con- Lucian Bernhard -

The UK Tex FAQ Your 469 Questions Answered Version 3.28, Date 2014-06-10
The UK TeX FAQ Your 469 Questions Answered version 3.28, date 2014-06-10 June 10, 2014 NOTE This document is an updated and extended version of the FAQ article that was published as the December 1994 and 1995, and March 1999 editions of the UK TUG magazine Baskerville (which weren’t formatted like this). The article is also available via the World Wide Web. Contents Introduction 10 Licence of the FAQ 10 Finding the Files 10 A The Background 11 1 Getting started.............................. 11 2 What is TeX?.............................. 11 3 What’s “writing in TeX”?....................... 12 4 How should I pronounce “TeX”?................... 12 5 What is Metafont?........................... 12 6 What is Metapost?........................... 12 7 Things with “TeX” in the name.................... 13 8 What is CTAN?............................ 14 9 The (CTAN) catalogue......................... 15 10 How can I be sure it’s really TeX?................... 15 11 What is e-TeX?............................ 15 12 What is PDFTeX?........................... 16 13 What is LaTeX?............................ 16 14 What is LaTeX2e?........................... 16 15 How should I pronounce “LaTeX(2e)”?................. 17 16 Should I use Plain TeX or LaTeX?................... 17 17 How does LaTeX relate to Plain TeX?................. 17 18 What is ConTeXt?............................ 17 19 What are the AMS packages (AMSTeX, etc.)?............ 18 20 What is Eplain?............................ 18 21 What is Texinfo?............................ 19 22 Lollipop................................ 19 23 If TeX is so good, how come it’s free?................ 19 24 What is the future of TeX?....................... 19 25 Reading (La)TeX files......................... 19 26 Why is TeX not a WYSIWYG system?................. 20 27 TeX User Groups............................ 21 B Documentation and Help 21 28 Books relevant to TeX and friends................... -

Font List for the Cisco Edge 340 Series, Release 1.1
Font List for the Cisco Edge 340 Series, Release 1.1 First Published: August 4, 2014 This document describes the default fonts of the Cisco Edge 340 Series, Release 1.1. Font List The following fonts are supported on the Cisco Edge 340 Series, Release 1.1: • Umpush:style=Oblique • Utopia:style=Bold Italic • Nimbus Sans L:style=Regular Italic • URW Palladio L:style=Roman • Century Schoolbook L:style=Bold Italic • DejaVu Sans,DejaVu Sans Condensed:style=Condensed Oblique,Oblique • Norasi:style=Oblique • TlwgTypewriter:style=Oblique • TlwgMono:style=Medium • Tlwg Typo:style=Medium • Nimbus Sans L:style=Bold • Norasi:style=BoldOblique • Utopia:style=Bold • Tlwg Typo:style=BoldOblique • Purisa:style=BoldOblique • URW Chancery L:style=Medium Italic • Bitstream Charter:style=Bold Italic • DejaVu Sans:style=Bold Oblique Cisco Systems, Inc. www.cisco.com Font List • Nimbus Roman No9 L:style=Regular • Loma:style=Oblique • Century Schoolbook L:style=Bold • Century Schoolbook L:style=Italic • Norasi:style=BoldItalic • Nimbus Sans L:style=Regular • URW Palladio L:style=Italic • Cursor:style=Regular • Garuda:style=Oblique • Nimbus Sans L:style=Bold Condensed • TlwgTypewriter:style=Medium • URW Gothic L:style=Demi • Nimbus Roman No9 L:style=Medium Italic • Bitstream Charter:style=Regular • Purisa:style=Bold • Garuda:style=BoldOblique • Nimbus Mono L:style=Bold Oblique • Kinnari:style=Medium • Norasi:style=Italic • Dingbats:style=Regular • TlwgMono:style=Bold • Loma:style=BoldOblique • Waree:style=Oblique • Nimbus Roman No9 L:style=Medium • Nimbus Sans