Development of Speech Corpus and Automatic Speech Recognition of Angami
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparative Study of Angami and Chakhesang Women
A SOCIOLOGICAL STUDY OF UNEMPLOYMENT PROBLEM : A COMPARATIVE STUDY OF ANGAMI AND CHAKHESANG WOMEN THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN SOCIOLOGY SCHOOL OF SOCIAL SCIENCES NAGALAND UNIVERSITY BY MEDONUO PIENYÜ Ph. D. REGISTRATION NO. 357/ 2008 UNDER THE SUPERVISION OF PROF. KSHETRI RAJENDRA SINGH DEPARTMENT OF SOCIOLOGY DEPARTMENT OF SOCIOLOGY NAGALAND UNIVERSITY H.Qs. LUMAMI, NAGALAND, INDIA NOVEMBER 2013 I would like to dedicate this thesis to my Mother Mrs. Mhasivonuo Pienyü who never gave up on me and supported me through the most difficult times of my life. NAGALAND UNIVERSITY (A Central University Estd. By the Act of Parliament No 35 of 1989) Headquaters- Lumami P.O. Mokokchung- 798601 Department of Sociology Ref. No……………. Date………………. CERTIFICATE This is certified that I have supervised and gone through the entire pages of the Ph.D. thesis entitled “A Sociological Study of Unemployment Problem: A Comparative Study of Angami and Chakhesang Women” submitted by Medonuo Pienyü. This is further certified that this research work of Medonuo Pienyü, carried out under my supervision is her original work and has not been submitted for any degree to any other university or institute. Supervisor Place: (Prof. Kshetri Rajendra Singh) Date: Department of Sociology, Nagaland University Hqs: Lumami DECLARATION The Nagaland University November, 2013. I, Miss. Medonuo Pienyü, hereby declare that the contents of this thesis is the record of my work done and the subject matter of this thesis did not form the basis of the award of any previous degree to me or to the best of my knowledge to anybody else, and that thesis has not been submitted by me for any research degree in any other university/ institute. -

A Phonetic, Phonological, and Morphosyntactic Analysis of the Mara Language
San Jose State University SJSU ScholarWorks Master's Theses Master's Theses and Graduate Research Spring 2010 A Phonetic, Phonological, and Morphosyntactic Analysis of the Mara Language Michelle Arden San Jose State University Follow this and additional works at: https://scholarworks.sjsu.edu/etd_theses Recommended Citation Arden, Michelle, "A Phonetic, Phonological, and Morphosyntactic Analysis of the Mara Language" (2010). Master's Theses. 3744. DOI: https://doi.org/10.31979/etd.v36r-dk3u https://scholarworks.sjsu.edu/etd_theses/3744 This Thesis is brought to you for free and open access by the Master's Theses and Graduate Research at SJSU ScholarWorks. It has been accepted for inclusion in Master's Theses by an authorized administrator of SJSU ScholarWorks. For more information, please contact [email protected]. A PHONETIC, PHONOLOGICAL, AND MORPHOSYNTACTIC ANALYSIS OF THE MARA LANGUAGE A Thesis Presented to The Faculty of the Department of Linguistics and Language Development San Jose State University In Partial Fulfillment of the Requirements for the Degree Master of Arts by Michelle J. Arden May 2010 © 2010 Michelle J. Arden ALL RIGHTS RESERVED The Designated Thesis Committee Approves the Thesis Titled A PHONETIC, PHONOLOGICAL, AND MORPHOSYNTACTIC ANALYSIS OF THE MARA LANGUAGE by Michelle J. Arden APPROVED FOR THE DEPARTMENT OF LINGUISTICS AND LANGUAGE DEVELOPMENT SAN JOSE STATE UNIVERSITY May 2010 Dr. Daniel Silverman Department of Linguistics and Language Development Dr. Soteria Svorou Department of Linguistics and Language Development Dr. Kenneth VanBik Department of Linguistics and Language Development ABSTRACT A PHONETIC, PHONOLOGICAL, AND MORPHOSYNTACTIC ANALYSIS OF THE MARA LANGUAGE by Michelle J. Arden This thesis presents a linguistic analysis of the Mara language, a Tibeto-Burman language spoken in northwest Myanmar and in neighboring districts of India. -

UC Berkeley Proceedings of the Annual Meeting of the Berkeley Linguistics Society
UC Berkeley Proceedings of the Annual Meeting of the Berkeley Linguistics Society Title Lexical Prefixes and Tibeto-Burman Laryngeal Contrasts Permalink https://escholarship.org/uc/item/1229x8bj Journal Proceedings of the Annual Meeting of the Berkeley Linguistics Society, 37(37) ISSN 2377-1666 Author Mortensen, David R Publication Date 2013 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Lexical prefixes and Tibeto-Burman laryngeal contrasts Author(s): David R. Mortensen Proceedings of the 37th Annual Meeting of the Berkeley Linguistics Society (2013), pp. 272-286 Editors: Chundra Cathcart, I-Hsuan Chen, Greg Finley, Shinae Kang, Clare S. Sandy, and Elise Stickles Please contact BLS regarding any further use of this work. BLS retains copyright for both print and screen forms of the publication. BLS may be contacted via http://linguistics.berkeley.edu/bls/. The Annual Proceedings of the Berkeley Linguistics Society is published online via eLanguage, the Linguistic Society of America's digital publishing platform. Lexical Prefixes and Tibeto-Burman Laryngeal Contrasts DAVID R. MORTENSEN University of Pittsburgh Introduction The correspondences between Tibeto-Burman onsets are complex and often diffi- cult to explain as products of regular, phonetically conditioned sound change. This is particularly true with regard to their laryngeal features. In his ground-breaking reconstruction of Proto-Tibeto-Burman (PTB), Benedict (1972:17–18) provides the following set of reflexes for his reconstructed PTB stops: PTB Tibetan Jingpho Burmese Garo Mizo *p ph pph p bph pph p bph b ∼ ∼ ∼ ∼ ∼ ∼ ∼ *t th tth t dth tth t dth t tsh ∼ ∼ ∼ ∼ ∼ ∼ ∼ ∼ *k kh kkh k gkh kkh k gkh k ∼ ∼ ∼ ∼ ∼ ∼ ∼ *b b b p ph pbp ph b ∼ ∼ ∼ ∼ *d d d t th tdt th d ∼ ∼ ∼ ∼ *g g g k kh kgk kh k ∼ ∼ ∼ ∼ Benedict reconstructs only two series of stops, despite the fact that there are a far larger number of consonant correspondences. -
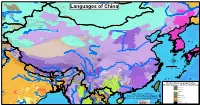
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Nominal Morphology in Korbong Language
==================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 14:11 November 2014 Nominal Morphology in Korbong Language Biman Debbarma, Ph.D. Scholar ========================================================== Korbong boys Bridge connecting Korbong village ==================================================================== Abstract Korbongs are one of the sub-tribes of Halam community which has been recognized as a scheduled tribe in the state of Tripura. Interestingly, the term ‘Korbong’ is also used to denote the ‘language’ spoken by the same tribe. Therefore the Korbong is the name of the language and the people. Korbongs are found only in two villages having only about 117 speakers in the state of Tripura, particularly in the districts of Khowai and West Tripura. Genetically, Korbong is closely related to Bongcher, Bong, Darlong, Hrangkhal, Kaipeng, Mizo, Moulsom, Pangkhua, Ranglong, etc., except Kalai and Rupini. Therefore Korbong seems to be a Kuki-Chin language Language in India www.languageinindia.com ISSN 1930-2940 14:11 November 2014 Biman Debbarma, Ph.D. Scholar Nominal Morphology in Korbong Language 31 of the Tibeto-Burman family. The main objective of the proposed study is to show the nominal morphology in the areas of person, number, gender and case in Korbong. Key words: Korbong language and people, Kuki-Chin group, nominal morphology, person, number, gender and case 1. Introduction Korbongs are one of the sub-tribes of Halam community which has been recognized as a scheduled tribe in the state of Tripura. Interestingly, the term ‘Korbong’ is also used to denote the ‘language’ spoken by the same tribe. Therefore the Korbong is the name of the language and the people. Korbongs are found only in two villages having a population of about 117 speakers in the state of Tripura, particularly in the districts of Khowai and West Tripura. -

Historical Account of British Legacy in the Naga Hills (1881- 1947)
Historical Account of British Legacy in the Naga Hills (1881- 1947) A thesis submitted to the Tilak Maharashtra Vidyapeeth, Pune For the degree of Vidyawachaspati (Ph.D) Department of History Under Faculty of Social Sciences Researcher Joseph Longkumer Research Supervisor: Dr. Shraddha Kumbhojkar March, 2011 1 Certificate I certify that the work presented here by Mr. Joseph Longkumer represents his original work that was carried out by him at Tilak Maharashtra Vidyapeeth, Pune under my guidance during the period 2007 to 2011. Work done by other scholars has been duly cited and acknowledged by him. I further certify that he has not submitted the same work to this or any other University for any research degree. Place: Signature of Research Supervisor 2 Declaration I hereby declare that this submission is my own work and that, to the best of my knowledge and belief, it contains no material previously published or written by another person nor material which has been accepted for the award of any degree or diploma of the University or other institute of higher learning, except where due acknowledgment has been made in the text. Signature Name Date 3 CONTENTS Page No. Acknowledgement CHAPTER – 1 Introduction……………………………………………………………………………………5 CHAPTER – II British Policy towards the Naga Hills with an Account of Tour in the Naga Hills………….54 CHAPTER – III State Of Affairs from 1910-1933…………………………………………………………...142 CHAPTER – IV Advent of Christianity and Modern Education……………………………………………..206 CHAPTER – V Nagas and the World War II………………………………………………………………...249 CHAPTER – VI Conclusion…………………………………………………………………………………..300 Bibliography….....................................................................................................................308 Appendices..........................................................................................................................327 4 Chapter 1 INTRODUCTION There is a saying among the Nagas that, at one point of time the Nagas wrote and maintained their history, written in some animal skin. -

Social Life of Angami Naga: a Study
Shikshan Sanshodhan : Journal of Arts, Humanities and Social Sciences ISSN: 2581-6241 Volume - 3, Issue - 1, Jan-Feb – 2020 Bi-Monthly, Peer-Reviewed, Refereed, Indexed Journal Impact Factor: 3.589 Received on : 28/12/2019 Accepted on : 12/01/2020 Publication Date: 28/02/2020 Social Life of Angami Naga: A Study Dr. Nabarun Purkayastha Head of the Department, Sociology University of Science and Technology, Meghalaya (USTM) Email: [email protected] Abstract: The Tribal represent an important social category of Indian social structure. The tribal’s are said to be the original inhabitants of India spread over the length and breadth of the country. Every tribal group have their own religion, custom and own way of life. The Angami is a major Naga ethnic group native to the state of Nagaland in North-East India settled in Kohima District and Dimapur District. They are one of the fifteen major tribes of Nagaland. The study mainly focuses on social life of Angami Naga of Peducha village in Nagaland. Keywords: Indian Tribe, Angami Naga, economic condition, village festivals, Impact of Christianity. 1. INTRODUCTION: A Tribe is a group of distinct people, dependent on their land for their livelihood, who are largely self-sufficient, and not integrated into the national society. Thus the term usually denotes a social group bound together by kin and duty and associated with a particular territory. Tribes in the Indian context today are normally referred to in the language of the Constitution as “Scheduled Tribes”. The Tribal represent an important social category of Indian social structure. They are said to be the original inhabitants of India spread over the length and breadth of the country. -

Tenyidie and Its Literary Networks
================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 18:2 February 2018 India’s Higher Education Authority UGC Approved List of Journals Serial Number 49042 ================================================================ History, Identity and Language: Tenyidie and Its Literary Networks Riku Khutso, M.A., M.Phil., Ph.D. Scholar =========================================================== Abstract Historically, the Tenyimia is a group of Naga tribes which trace common ancestry. According to the oral sources, these people basically dispersed from two villages known as Maikhel (Mekhrore) and Khezhakenoma to different parts of the present-day Nagaland, Manipur and Assam. Their claim of common descent is endorsed by shared memories and conjoined geographical spaces besides the close linguistic lineage that is found among the varied dialects. However, before the colonial and American missionary experience, this kinship relationship was limited by historical factors and Tenyimia as a socio-cultural and political entity was not as defined as in the contemporary times and neither was there a common language called Tenyidie. It is in this context that the influence of western cultural traditions since the nineteenth century made a durable impression on the socio-cultural and political processes of the Tenyimia people across vast geographical spaces. As a result, Tenyidie language, which is basically a language adapted from various dialects by the American Missionaries became standardized among the Tenyimia people over time. In this paper, one of the main objectives is to see how a literate tradition has been fostered and embraced across dialectal and geographical spaces. To understand this phenomenon, the paper would try to locate the nature and interplay of history, identity and language in reinforcing historical consciousness and creating new sensibilities. -
The PRINT VERSION of ALL the PAPERS OF
LANGUAGE IN INDIA Strength for Today and Bright Hope for Tomorrow Volume 16:6 June 2016 ISSN 1930-2940 Managing Editor: M. S. Thirumalai, Ph.D. Editors: B. Mallikarjun, Ph.D. Sam Mohanlal, Ph.D. B. A. Sharada, Ph.D. A. R. Fatihi, Ph.D. Lakhan Gusain, Ph.D. Jennifer Marie Bayer, Ph.D. S. M. Ravichandran, Ph.D. G. Baskaran, Ph.D. L. Ramamoorthy, Ph.D. C. Subburaman, Ph.D. (Economics) N. Nadaraja Pillai, Ph.D. Renuga Devi, Ph.D. Soibam Rebika Devi, M.Sc., Ph.D. Assistant Managing Editor: Swarna Thirumalai, M.A. Contents Materials published in Language in India www.languageinindia.com are indexed in EBSCOHost database, MLA International Bibliography and the Directory of Periodicals, ProQuest (Linguistics and Language Behavior Abstracts) and Gale Research. The journal is included in the Cabell’s Directory, a leading directory in the USA. Articles published in Language in India are peer-reviewed by one or more members of the Board of Editors or an outside scholar who is a specialist in the related field. Since the dissertations are already reviewed by the University-appointed examiners, dissertations accepted for publication in Language in India are not reviewed again. This is our 16th year of publication. All back issues of the journal are accessible through this link: http://languageinindia.com/backissues/2001.html Language in India www.languageinindia.com ISSN 1930-2940 16:6 June 2016 Contents i Heaven or Hell on Earth? An Insightful View from Philosopher, Educationist and Entrepreneur Jimmy Teo iv-v Aasma Pathan, MS Scholar Thrashing Learners Inactivity in Large Classes: An Action Research on the Secondary Students of Thano 1-11 Console Zamreinao Shimrei, M.Phil., NET., Ph.D. -

Investigating Differential Case Marking in Sümi, a Language Of
INVESTIGATING DIFFERENTIAL CASE MARKING IN SÜMI, A LANGUAGE OF NAGALAND, USING LANGUAGE DOCUMENTATION AND EXPERIMENTAL METHODS by AMOS BENJAMIN LENG YUAN TEO A DISSERTATION Presented to the Department of Linguistics and the Graduate School of the University of Oregon in partial fulfillment of the requirements for the degree of Doctor of Philosophy September 2019 DISSERTATION APPROVAL PAGE Student: Amos Benjamin Leng Yuan Teo Title: Investigating Differential Case Marking in Sümi, a Language of Nagaland, Using Language Documentation and Experimental Methods This dissertation has been accepted and approved in partial fulfillment of the requirements for the Doctor of Philosophy degree in the Linguistics by: Scott DeLancey Co-Chairperson Melissa Baese-Berk Co-Chairperson Spike Gildea Core Member Kaori Idemaru Institutional Representative and Janet Woodruff-Borden Vice Provost and Dean of the Graduate School Original approval signatures are on file with the University of Oregon Graduate School. Degree awarded September 2019 ii © 2019 Amos Benjamin Leng Yuan Teo This work is licensed under a Creative Commons CC-BY-NC-ND. iii DISSERTATION ABSTRACT Amos Benjamin Teo Doctor of Philosophy Department of Linguistics September 2019 Title: Investigating Differential Case Marking in Sümi, a Language of Nagaland, Using Language Documentation and Experimental Methods One goal in linguistics is to model how speakers use natural language to convey different kinds of information. In theories of grammar, two kinds of information: “who is doing what (and to whom)”, the technical term for which is case or case role; and pragmatic information about “what is important”, have been assumed to be expressed by different means within a language. -

KET Historyrevised
The History of Nagaland Reflected in its Literature (By Charles Chasie, President, Kohima Educational Society) Early History Before the advent of the American Missionaries, Nagas were illiterate, practised headhunting and lived in their village-states, mostly in isolation from each other. History and culture were passed down through word of mouth, from generation to generation. There was a rich tradition of oral literature but no question of books or written literature then. The first literary figure to make his presence felt in the region was E.W. Clarke, an American missionary of Dutch origin. With a journalistic background, he arrived in Assam in 1869 and was stationed at Sibsagar (Sivasagar) Mission. Armed with a printing press and an Assamese assistant (Godhula) in particular, he used to make forays into the Ao Naga hills. Slowly he started having converts. For the sake of his converts, he first translated and printed a hymn book and the Lord’s Prayer. He, finally, climbed the hills for a base at Molungyimsen Village in Ao Naga country in 1872. In 1884, the first printing press, called Molung Printing Press, was set up in Molunyimsen village. The same year The Gospels of Mathew and John were translated into Ao language. W.E Witter’s Grammar and Vocabulary in Lotha language came out in 1888. The book, St Mathew, in Angami language followed in 1889 and the Sema Primer by Rev H B Dickson in 1908. Later, E W Clarke brought out a “dictionary” in the Ao language in 1911. So while the primary objective was to teach the new Naga converts to pray, read the Bible and sing hymns, literacy/education slowly followed in its wake. -

Infinity Journals Article 4
DR. KAJAL JETHANAND SADHWANI VOLUME I ISSUE I INFINITY JOURNALS ARTICLE 4. INFINITY JOURNAL DR KAJAL JETHANAND SADHWANI ABSTRACT A tribe could also be a social division during a standard society consisting of families linked by social, economic, religious, or blood ties, with a typical culture and dialect. A tribe possesses certain qualities and characteristics that make it a singular cultural, social, and political entity. Tribes are also known by the name ‘Adivasis’ in India.I chose to research about north eastern people and their difficulties which led my study to tribal people. TRIBES IN INDIA Constitution of India has recognized tribal communities in India under ‘Schedule 5’ of the constitution. Hence the tribes recognized by the Constitution are mentioned as ‘ Scheduled Tribes’. There are around 645 distinct tribes in India. However, during this text , we concentrate only on the most names. What draws India closer to an obscure and indifferent picture are the indigenous tribes. away from the contemporary trend and economical development, they own their identity as Adivasi having their own language, religion, festivals, cuisine, dance and music. With such an enigmatic culture and hospitality they also significantly hold a contrasting patriarchal and matriarchal society. The lively tableau of the tribal community in India stretches from the remote villages tucked within the Indian Himalayan region to southern – most tip of India AND from the farthest corner of North Malay Archipelago to the dunes of Rajasthan. The tribal population in India covers approximately 15% of the country and thus the bulk is found in central India. INFINITY JOURNAL The tribes of India constitute 8.2% of the whole population.