ISO/IEC JTC 1/SC 2 N 3514/ W G 2 N2328 Date: 2001-03-09
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Armenian Secret and Invented Languages and Argots
Armenian Secret and Invented Languages and Argots The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Russell, James R. Forthcoming. Armenian secret and invented languages and argots. Proceedings of the Institute of Linguistics of the Russian Academy of Sciences. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:9938150 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Open Access Policy Articles, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#OAP 1 ARMENIAN SECRET AND INVENTED LANGUAGES AND ARGOTS. By James R. Russell, Harvard University. Светлой памяти Карена Никитича Юзбашяна посвящается это исследование. CONTENTS: Preface 1. Secret languages and argots 2. Philosophical and hypothetical languages 3. The St. Petersburg Manuscript 4. The Argot of the Felt-Beaters 5. Appendices: 1. Description of St. Petersburg MS A 29 2. Glossary of the Ṙuštuni language 3. Glossary of the argot of the Felt-Beaters of Moks 4. Texts in the “Third Script” of MS A 29 List of Plates Bibliography PREFACE Much of the research for this article was undertaken in Armenia and Russia in June and July 2011 and was funded by a generous O’Neill grant through the Davis Center for Russian and Eurasian Studies at Harvard. For their eager assistance and boundless hospitality I am grateful to numerous friends and colleagues who made my visit pleasant and successful. For their generous assistance in Erevan and St. -

Chapter 2 Working with Text: Basics Copyright
Writer Guide Chapter 2 Working with Text: Basics Copyright This document is Copyright © 2021 by the LibreOffice Documentation Team. Contributors are listed below. You may distribute it and/or modify it under the terms of either the GNU General Public License (https://www.gnu.org/licenses/gpl.html), version 3 or later, or the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), version 4.0 or later. All trademarks within this guide belong to their legitimate owners. Contributors To this edition Rafael Lima Jean Hollis Weber Kees Kriek To previous editions Jean Hollis Weber Bruce Byfield Gillian Pollack Ron Faile Jr. John A. Smith Hazel Russman John M. Długosz Shravani Bellapukonda Kees Kriek Feedback Please direct any comments or suggestions about this document to the Documentation Team’s mailing list: [email protected] Note Everything you send to a mailing list, including your email address and any other personal information that is written in the message, is publicly archived and cannot be deleted. Publication date and software version Published April 2021. Based on LibreOffice 7.1 Community. Other versions of LibreOffice may differ in appearance and functionality. Using LibreOffice on macOS Some keystrokes and menu items are different on macOS from those used in Windows and Linux. The table below gives some common substitutions for the instructions in this document. For a detailed list, see the application Help. Windows or Linux macOS equivalent Effect Tools > Options LibreOffice > -
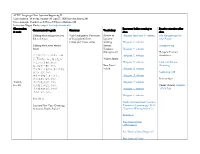
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

The Degree of the Speaker's Negative Attitude in a Goal-Shifting
In Christopher Brown and Qianping Gu and Cornelia Loos and Jason Mielens and Grace Neveu (eds.), Proceedings of the 15th Texas Linguistics Society Conference, 150-169. 2015. The degree of the speaker’s negative attitude in a goal-shifting comparison Osamu Sawada∗ Mie University [email protected] Abstract The Japanese comparative expression sore-yori ‘than it’ can be used for shifting the goal of a conversation. What is interesting about goal-shifting via sore-yori is that, un- like ordinary goal-shifting with expressions like tokorode ‘by the way,’ using sore-yori often signals the speaker’s negative attitude toward the addressee. In this paper, I will investigate the meaning and use of goal-shifting comparison and consider the mecha- nism by which the speaker’s emotion is expressed. I will claim that the meaning of the pragmatic sore-yori conventionally implicates that the at-issue utterance is preferable to the previous utterance (cf. metalinguistic comparison (e.g. (Giannakidou & Yoon 2011))) and that the meaning of goal-shifting is derived if the goal associated with the at-issue utterance is considered irrelevant to the goal associated with the previous utterance. Moreover, I will argue that the speaker’s negative attitude is shown by the competition between the speaker’s goal and the hearer’s goal, and a strong negativity emerges if the goals are assumed to be not shared. I will also compare sore-yori to sonna koto-yori ‘than such a thing’ and show that sonna koto-yori directly expresses a strong negative attitude toward the previous utterance. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Petit Manuel Unix®
Août 2010 Petit Manuel Unix® Jacques MADELAINE Département d’informatique Université de CAEN 14032 CAEN CEDEX La première édition de ce manuel décrivait SMX un Unix développé à l’INRIA pour la machine française SM90, la deuxième édition une adaptation pour SPIX, un Unix pour SM90 basé sur System V et développé par Bull. Il a été ensuite modifié et corrigé pour SunOS l’Unix de Sun Microsystems, puis pour Solaris. La cinquième version a été adaptée pour tenir compte des particularités du système GNU-Linux. Un chapitre supplémentaire dédié aux accès réseau a été ensuite ajouté. Rappelons que presque toutes les commandes décrites vont fonctionner comme indiqué sur tout système Unix commercial (Solaris, HP-UX, AIX, ...) ou libre (Linux, OpenBSD, FreeBSD, NetBSD, ...). Mes remerciements à Sara Aubry pour sa relecture attentive etàFrançois Girault pour avoir fourni la mise en tableau des commandes d’emacs. Mes remerciements à Davy Gigan pour m’avoir poussé à publier la version html en octobre 2003. 1 INTRODUCTION() INTRODUCTION() 2Petit manuel Unix 2002 INTRODUCTION NOM intro − introduction to the mini manual − introduction au petit manuel DESCRIPTION Ce manuel donne les principales commandes de Unix. Unix est une famille de systèmes d’exploitation ; les commandes décrites existent, sauf précision contraire, sous Linux et Solaris, les deux systèmes disponibles au département. Seules les principales options sont données, reportez-vous au manuel en ligne pour une liste exhaustive.Chaque commande est décrite par trois sections : NOM qui donne le nom de la commande, son nom en anglais (le nom Unix étant un mnémonique anglais ne correspondant pas toujours bien aveclefrançais) et en français. -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

A Study of Borrowing in Contemporary Spoken Japanese
California State University, San Bernardino CSUSB ScholarWorks Theses Digitization Project John M. Pfau Library 1996 Integration of the American English lexicon: A study of borrowing in contemporary spoken Japanese Bradford Michael Frischkorn Follow this and additional works at: https://scholarworks.lib.csusb.edu/etd-project Part of the First and Second Language Acquisition Commons Recommended Citation Frischkorn, Bradford Michael, "Integration of the American English lexicon: A study of borrowing in contemporary spoken Japanese" (1996). Theses Digitization Project. 1107. https://scholarworks.lib.csusb.edu/etd-project/1107 This Thesis is brought to you for free and open access by the John M. Pfau Library at CSUSB ScholarWorks. It has been accepted for inclusion in Theses Digitization Project by an authorized administrator of CSUSB ScholarWorks. For more information, please contact [email protected]. INTEGRATION OF THE AMERICAN ENGLISH LEXICON: A STUDY OF BORROWING IN CONTEMPORARY SPOKEN JAPANESE A Thesis Presented to the Faculty of California State University, San Bernardino In Partial Fulfilliiient of the Requirements for the Degree Master of Arts in English Composition by Bradford Michael Frischkorn March 1996 INTEGRATION OF THE AMERICAN ENGLISH LEXICON: A STUDY OF BORROWING IN CONTEMPORARY SPOKEN JAPANESE A Thesis Presented to the Faculty of California State University,,, San Bernardino , by Y Bradford Michael Frischkorn ' March 1996 Approved by: Dr. Wendy Smith, Chair, English " Date Dr. Rong Chen ~ Dr. Sunny Hyonf ABSTRACT The purpose of this thesis was to determine some of the behavioral characteristics of English loanwords in Japanese (ELJ) as they are used by native speakers in news telecasts. Specifically, I sought to examine ELJ from four perspectives: 1) part of speech, 2) morphology, 3) semantics, and 4) usage domain. -

Guide to the Use of Character Set Standards in Europe
CEN TECHNICAL REPORT Draft 3 for CEN Trnnnn:1999 1999-07-23 Descriptors: Data processing, information interchange, text processing, text communication, graphic characters, character sets, representation of characters, coded character sets, architecture Information Technology - Guide to the use of character set standards in Europe This CEN Technical Report has been drawn up by CEN/TC 304 This CEN Technical Report was established by TC 304 in one official version (English). A version in any other language made by translation under the responsibility of a CEN member into its own lan- guage and notified to the Central Secretariat has the same status as the official version. CEN members are the national bodies of Austria, Belgium, the Czech Republic, Denmark, Finland, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, Netherlands, Norway, Portugal, Spain, Sweden, Switzerland, and the United Kingdom. CEN European Committee for Standardization Comité Européen de Normalisation Europäisches Komitee für Normung Central Secretariat: rue de Stassart 36, B-1050 Brussels © CEN 1999 Copyright reserved to all CEN members Ref.No. TR xxxx:1999 E CEN TR nnnn : Draft 2 Guide to the use of character set standards in Europe ii Guide to the use of character set standards in Europe CEN TR nnnn : Draft 2 FOREWORD This report was produced by a CEN/TC 304 Project Team, set up in June, 1998, as one of several to carry out the funded work program of TC 304 (documented in CEN/TC 304 N 666 R2). A first draft was discussed at the TC meeting in Brussels in November, 1998. A revised draft was circulated for comments within the TC and thereafter discussed at the TC plenary meeting in April, 1999. -

International Language Environments Guide
International Language Environments Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 806–6642–10 May, 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, Java, XView, ToolTalk, Solstice AdminTools, SunVideo and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. SunOS, Solaris, X11, SPARC, UNIX, PostScript, OpenWindows, AnswerBook, SunExpress, SPARCprinter, JumpStart, Xlib The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

A Performer's Guide to Minoru Miki's Sohmon III for Soprano, Marimba and Piano (1988)
University of Cincinnati Date: 4/22/2011 I, Margaret T Ozaki-Graves , hereby submit this original work as part of the requirements for the degree of Doctor of Musical Arts in Voice. It is entitled: A Performer’s Guide to Minoru Miki’s _Sohmon III for Soprano, Marimba and Piano_ (1988) Student's name: Margaret T Ozaki-Graves This work and its defense approved by: Committee chair: Jeongwon Joe, PhD Committee member: William McGraw, MM Committee member: Barbara Paver, MM 1581 Last Printed:4/29/2011 Document Of Defense Form A Performer’s Guide to Minoru Miki’s Sohmon III for Soprano, Marimba and Piano (1988) A document submitted to the Graduate School of the University of Cincinnati in partial fulfillment of the requirements for the degree of Doctor of Musical Arts in the Performance Studies Division of the College-Conservatory of Music by Margaret Ozaki-Graves B.M., Lawrence University, 2003 M.M., University of Cincinnati, 2007 April 22, 2011 Committee Chair: Jeongwon Joe, Ph.D. ABSTRACT Japanese composer Minoru Miki (b. 1930) uses his music as a vehicle to promote cross- cultural awareness and world peace, while displaying a self-proclaimed preoccupation with ethnic mixture, which he calls konketsu. This document intends to be a performance guide to Miki’s Sohmon III: for Soprano, Marimba and Piano (1988). The first chapter provides an introduction to the composer and his work. It also introduces methods of intercultural and artistic borrowing in the Japanese arts, and it defines the four basic principles of Japanese aesthetics. The second chapter focuses on the interpretation and pronunciation of Sohmon III’s song text.