Many-Cores-On-Chip Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
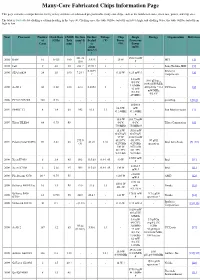
Many-Core Fabricated Chips Information Page
Many-Core Fabricated Chips Information Page This page contains a comprehensive listing of key attributes of fabricated programmable many-core chips, such as the number of cores, clock rate, power, and chip area. The table is Sortable by clicking a column heading in the top row. Clicking once, the table will be sorted from low to high, and clicking twice, the table will be sorted from high to low. Year Processor Number Clock Rate CMOS Die Size Die Size Voltage Chip Single Energy Organization Reference of (GHz) Tech (mm^2) Scaled (V) Power Processor Cores (nm) * to (W) Power 22nm (mW) (mm^2) † 331.24 1562.5 mW 2002 RAW 16 0.425 180 3.975 - 25 W - MIT [1] (16) # 2005 Cell 9 4.0 90 221 ? 17.76 ? 1 - - - Sony,Toshiba,IBM [2] 0.0875 Intelesys 2006 SEAforth24 24 1.0 180 7.29 ? - 0.15 W 6.25 mW # - [3] ? Corporation 2.4 mW 93.0 pJ/Op = @0.9V, 0.093 mW/MHz 116MHz 2006 AsAP 1 36 0.60 180 32.1 0.3852 2 - 300 pJ/Op = 0.3 UC Davis [4] 32 mW mW/MHz @1.8V, @1.8V 475MHz 2006 PC202/203/205 248 0.16 - - - - - - - picoChip [5] [6] 10500.0 84.0 W mW 2007 SPARC T2 8 1.4 65 342 51.3 1.1 - Sun Microsystems [7] @1.4GHz @1.4GHz # 10.8 W 168.75 mW 2007 Tilera TILE64 64 0.75 90 - - - @1V, @1V, - Tilera Corporation [8] 750MHz 750MHz # 15.6 W 195.0 mW @670mV @670mV 97 W 1212.5 mW 275.0 @1.07V, @1.07V, 97 pJ/fl 2007 Polaris(TeraFLOPS) 80 5.67 65 41.25 1.35 Intel Tera-Scale [9] [10] (3) 4.27GHz 4.27GHz operation 230 W 2875 mW @1.35V, @1.35V, 5.67GHz 5.67GHz 15000 mW 2008 Xeon E7450 6 2.4 45 503 115.69 0.9-1.45 90 W - Intel [11] # 21666.7 2008 Xeon X7460 6 2.66 45 503 -

Parallel Architecture Hardware and General Purpose Operating System
Parallel Architecture Hardware and General Purpose Operating System Co-design Oskar Schirmer G¨ottingen, 2018-07-10 Abstract Because most optimisations to achieve higher computational performance eventually are limited, parallelism that scales is required. Parallelised hard- ware alone is not sufficient, but software that matches the architecture is required to gain best performance. For decades now, hardware design has been guided by the basic design of existing software, to avoid the higher cost to redesign the latter. In doing so, however, quite a variety of supe- rior concepts is excluded a priori. Consequently, co-design of both hardware and software is crucial where highest performance is the goal. For special purpose application, this co-design is common practice. For general purpose application, however, a precondition for usability of a computer system is an arXiv:1807.03546v1 [cs.DC] 10 Jul 2018 operating system which is both comprehensive and dynamic. As no such op- erating system has ever been designed, a sketch for a comprehensive dynamic operating system is presented, based on a straightforward hardware architec- ture to demonstrate how design decisions regarding software and hardware do coexist and harmonise. 1 Contents 1 Origin 4 1.1 Performance............................ 4 1.2 Limits ............................... 5 1.3 TransparentStructuralOptimisation . 8 1.4 VectorProcessing......................... 9 1.5 Asymmetric Multiprocessing . 10 1.6 SymmetricMulticore ....................... 11 1.7 MultinodeComputer ....................... 12 2 Review 14 2.1 SharedMemory.......................... 14 2.2 Cache ............................... 15 2.3 Synchronisation .......................... 15 2.4 Time-Shared Multitasking . 15 2.5 Interrupts ............................. 16 2.6 Exceptions............................. 16 2.7 PrivilegedMode.......................... 17 2.8 PeripheralI/O ......................... -

High-Performance Optimizations on Tiled Many-Core Embedded Systems: a Matrix Multiplication Case Study
J Supercomput (2013) 66:431–487 DOI 10.1007/s11227-013-0916-9 High-performance optimizations on tiled many-core embedded systems: a matrix multiplication case study Arslan Munir · Farinaz Koushanfar · Ann Gordon-Ross · Sanjay Ranka Published online: 5 April 2013 © Springer Science+Business Media New York 2013 Abstract Technological advancements in the silicon industry, as predicted by Moore’s law, have resulted in an increasing number of processor cores on a single chip, giving rise to multicore, and subsequently many-core architectures. This work focuses on identifying key architecture and software optimizations to attain high per- formance from tiled many-core architectures (TMAs)—an architectural innovation in the multicore technology. Although embedded systems design is traditionally power- centric, there has been a recent shift toward high-performance embedded computing due to the proliferation of compute-intensive embedded applications. The TMAs are suitable for these embedded applications due to low-power design features in many of these TMAs. We discuss the performance optimizations on a single tile (processor core) as well as parallel performance optimizations, such as application decompo- sition, cache locality, tile locality, memory balancing, and horizontal communica- tion for TMAs. We elaborate compiler-based optimizations that are applicable to A. Munir () · F. Koushanfar Department of Electrical and Computer Engineering, Rice University, Houston, TX, USA e-mail: [email protected] F. Koushanfar e-mail: [email protected] A. Gordon-Ross Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL, USA e-mail: [email protected]fl.edu A. Gordon-Ross NSF Center for High-Performance Reconfigurable Computing (CHREC), University of Florida, Gainesville, FL, USA S. -

Power and Performance Optimization for Network-On-Chip Based Many-Core Processors
Power and Performance Optimization for Network-on-Chip based Many-Core Processors YUAN YAO Doctoral Thesis in Information and Communication Technology (INFKOMTE) School of Electrical Engineering and Computer Science KTH Royal Institute of Technology Stockholm, Sweden 2019 KTH School of Electrical Engineering and Computer Science TRITA-EECS-AVL-2019:44 Electrum 229, SE-164 40 Stockholm ISBN 978-91-7873-182-4 SWEDEN Akademisk avhandling som med tillstånd av Kungl Tekniska högskolan framlägges till offentlig granskning för avläggande av teknologie doktorsexamen i Informations- och Kommunikationsteknik fredag den 23 Augusti 2019 klockan 9.00 i Sal B, Elect- rum, Kungl Tekniska högskolan, Kistagången 16, Kista. © Yuan Yao, May 27, 2019 Tryck: Universitetsservice US AB iii Abstract Network-on-Chip (NoC) is emerging as a critical shared architecture for CMPs (Chip Multi-/Many-Core Processors) running parallel and concurrent applications. As the core count scales up and the transistor size shrinks, how to optimize power and performance for NoC open new research challenges. As it can potentially consume 20–40% of the entire chip power [20, 40, 81], NoC power efficiency has emerged as one of the main design constraints in today’s and future high performance CMPs. For NoC power management, we propose a novel on-chip DVFS technique that is able to adjust per-region NoC V/F according to voted V/F levels from communicating threads. A thread periodically votes for a preferred NoC V/F level that best suits its individual performance interests. The final DVFS decision of each region is adjusted by a region DVFS controller democratically based on the majority of votes it receives. -

EMERGING 2012, the Fourth International Conference on Emerging Network Intelligence
EMERGING 2012 The Fourth International Conference on Emerging Network Intelligence ISBN: 978-1-61208-239-4 September 23-28, 2012 Barcelona, Spain EMERGING 2012 Editors Michael D. Logothetis, University of Patras, Greece Tulin Atmaca, IT/Telecom&Management SudParis, France 1 / 84 EMERGING 2012 Forward The Fourth International Conference on Emerging Network Intelligence (EMERGING 2012) held on September 23-28, 2012 in Barcelona, Spain, constituted a stage to present and evaluate the advances in emerging solutions for next-generation architectures, devices, and communications protocols. Particular focus was aimed at optimization, quality, discovery, protection, and user profile requirements supported by special approaches such as network coding, configurable protocols, context-aware optimization, ambient systems, anomaly discovery, and adaptive mechanisms. Next-generation large distributed networks and systems require substantial reconsideration of existing ‘de facto’ approaches and mechanisms to sustain an increasing demand on speed, scale, bandwidth, topology and flow changes, user complex behavior, security threats, and service and user ubiquity. As a result, growing research and industrial forces are focusing on new approaches for advanced communications considering new devices and protocols, advanced discovery mechanisms, and programmability techniques to express, measure, and control the service quality, security, environmental and user requirements. We take here the opportunity to warmly thank all the members of the EMERGING 2012 technical program committee as well as the numerous reviewers. The creation of such a broad and high quality conference program would not have been possible without their involvement. We also kindly thank all the authors that dedicated much of their time and efforts to contribute to the EMERGING 2012. -
Tilera from Wikipedia, the Free Encyclopedia
Tilera From Wikipedia, the free encyclopedia Tilera Corporation is a fabless semiconductor company focusing on scalable manycore embedded processor design. The company ships multiple processors, including the TILE64, TILEPro64, and the TILEPro36, TILE-Gx72, TILE-Gx36, TILE-Gx16 Tilera Corporation and TILE-Gx9. Industry Semiconductor industry Founded October 2004 Founder Anant Agarwal, Devesh Contents Garg, and Vijay K. Aggarwal Headquarters San Jose, California, 1 History USA 2 Products Key people Devesh Garg, President & CEO 3 The Angstrom Project Products Central processing units Owner Privately funded 4 Board of directors Parent EZchip Semiconductor 5 See also Website www.tilera.com (http:// www.tilera.com) 6 References 7 External links History In 1990, Anant Agarwal led a team of researchers at Massachusetts Institute of Technology to develop scalable multi-processor system built out of large numbers of single chip processors. Alewife machines integrated both shared memory and user-level message passing for inter-node communications.[1] In 1997, Agarwal proposed a follow-on project using a mesh technology to connect multiple cores. The follow-on project, named RAW, commenced in 1997, and was supported by DARPA/NSF's funding of tens of millions, resulting in the world's first 16-processor tiles multicore and proving the mesh and compiler technology. Tilera was founded in October 2004, by Agarwal, Devesh Garg, and Vijay K. Aggarwal. Tilera launched its first product, the 64-core TILE64 processor, in August 2007. Tilera raised more than $100 million in venture funding from Bessemer Venture Partners, Walden International, Columbia Capital and VentureTech Alliance, with strategic investments from Broadcom, Quanta Computer and NTT. -

Architecture 2 CPU, DSP, GPU, NPU Contents
Architecture 2 CPU, DSP, GPU, NPU Contents 1 Central processing unit 1 1.1 History ................................................. 1 1.1.1 Transistor CPUs ....................................... 2 1.1.2 Small-scale integration CPUs ................................. 3 1.1.3 Large-scale integration CPUs ................................. 3 1.1.4 Microprocessors ....................................... 4 1.2 Operation ............................................... 4 1.2.1 Fetch ............................................. 5 1.2.2 Decode ............................................ 5 1.2.3 Execute ............................................ 5 1.3 Structure and implementation ..................................... 5 1.3.1 Control unit .......................................... 6 1.3.2 Arithmetic logic unit ..................................... 6 1.3.3 Memory management unit .................................. 6 1.3.4 Integer range ......................................... 6 1.3.5 Clock rate ........................................... 7 1.3.6 Parallelism .......................................... 8 1.4 Performance .............................................. 11 1.5 See also ................................................ 11 1.6 Notes ................................................. 11 1.7 References ............................................... 12 1.8 External links ............................................. 13 2 Digital signal processor 14 2.1 Overview ............................................... 14 2.2 Architecture ............................................. -

Lightweight, Scalable, Shared-Memory Computing on Many-Core Processors
LIGHTWEIGHT, SCALABLE, SHARED-MEMORY COMPUTING ON MANY-CORE PROCESSORS By BRYANT C. LAM A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY UNIVERSITY OF FLORIDA 2015 © 2015 Bryant C. Lam ACKNOWLEDGMENTS I would like to thank three important groups of people for their assistance and support in the creation of this dissertation: my committee members, my close friends and colleagues, and my wonderful family. I personally would like to thank my chair and cochair, Dr. Alan George and Dr. Herman Lam, for their academic, career, and personal advice and opportunities; my parents, Hoa and Jun, for their encouragement; and my loving wife, Phoebe, for her compassion and years of support. And last, but certainly not least, this work was supported in part by the I/UCRC Program of the National Science Foundation under Grant Nos. EEC-0642422 and IIP-1161022. 3 TABLE OF CONTENTS page ACKNOWLEDGMENTS...................................3 LIST OF TABLES......................................7 LIST OF FIGURES.....................................8 ABSTRACT......................................... 10 CHAPTER 1 INTRODUCTION................................... 12 2 LOW-LEVEL PGAS COMPUTING ON MANY-CORE PROCESSORS WITH TSHMEM 15 2.1 Background................................... 16 2.1.1 SHMEM and OpenSHMEM....................... 16 2.1.2 GASNet and the OpenSHMEM Reference Implementation....... 18 2.1.3 GSHMEM................................ 18 2.1.4 OSHMPI: OpenSHMEM using MPI-3.................. 19 2.1.5 OpenMP................................. 19 2.1.6 Tilera Many-Core Processors....................... 20 2.2 Device Performance Studies........................... 21 2.2.1 Memory Hierarchy............................ 22 2.2.2 TMC Common Memory......................... 23 2.2.3 TMC UDN Helper Functions...................... -

Optimizing Datacenter TCO with Scale-Out Processors
Accepted for publication in IEEE Micro, Special Issue on Energy-Aware Computing, Sep/Oct 2012 Optimizing Datacenter TCO with Scale-Out Processors Boris Grot1 Damien Hardy2 Pejman Lotfi-Kamran1 Chrysostomos Nicopoulos 2 Yanos Sazeides2 Babak Falsafi1 1EPFL 2University of Cyprus Abstract Large-scale datacenters use performance and total cost of ownership (TCO) as key optimization metrics. Conventional server processors, designed for a wide range of workloads, fall short in their ability to maximize these metrics due to inefficient utilization of their area and energy bud- gets. Emerging scale-out workloads are memory-intensive and require processors that can take full advantage of the available memory bandwidth and capacity to maximize the performance per TCO. While recently introduced processors based on low-power cores improve both throughput and energy-efficiency as compared to conventional server chips, we show that a specialized Scale-Out Processor architecture that maximizes on-chip computational density delivers the highest perfor- mace/TCO and performance/Watt at the datacenter level. 1 Motivation Our world is in the midst of an information revolution, driven by ubiquitous access to vast data stores via a variety of richly-networked platforms. Datacenters are the workhorses powering this revolution. Companies leading the transformation to the digital universe, such as Google, Microsoft, and Facebook, rely on networks of mega-scale datacenters to provide search, social connectivity, media streaming, and a growing number of other offerings to large, distributed audiences. A scale- out datacenter powering cloud services houses tens of thousands of servers, necessary for high scalability, availability, and resilience [8]. The massive scale of such datacenters requires an enormous capital outlay for infrastructure and hardware, often exceeding $100 million per datacenter [14].