Architecture 2 CPU, DSP, GPU, NPU Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Release Notes for X11R6.8.2 the X.Orgfoundation the Xfree86 Project, Inc
Release Notes for X11R6.8.2 The X.OrgFoundation The XFree86 Project, Inc. 9February 2005 Abstract These release notes contains information about features and their status in the X.Org Foundation X11R6.8.2 release. It is based on the XFree86 4.4RC2 RELNOTES docu- ment published by The XFree86™ Project, Inc. Thereare significant updates and dif- ferences in the X.Orgrelease as noted below. 1. Introduction to the X11R6.8.2 Release The release numbering is based on the original MIT X numbering system. X11refers to the ver- sion of the network protocol that the X Window system is based on: Version 11was first released in 1988 and has been stable for 15 years, with only upwardcompatible additions to the coreX protocol, a recordofstability envied in computing. Formal releases of X started with X version 9 from MIT;the first commercial X products werebased on X version 10. The MIT X Consortium and its successors, the X Consortium, the Open Group X Project Team, and the X.OrgGroup released versions X11R3 through X11R6.6, beforethe founding of the X.OrgFoundation. Therewill be futuremaintenance releases in the X11R6.8.x series. However,efforts arewell underway to split the X distribution into its modular components to allow for easier maintenance and independent updates. We expect a transitional period while both X11R6.8 releases arebeing fielded and the modular release completed and deployed while both will be available as different consumers of X technology have different constraints on deployment. Wehave not yet decided how the modular X releases will be numbered. We encourage you to submit bug fixes and enhancements to bugzilla.freedesktop.orgusing the xorgproduct, and discussions on this server take place on <[email protected]>. -

Reviving the Development of Openchrome
Reviving the Development of OpenChrome Kevin Brace OpenChrome Project Maintainer / Developer XDC2017 September 21st, 2017 Outline ● About Me ● My Personal Story Behind OpenChrome ● Background on VIA Chrome Hardware ● The History of OpenChrome Project ● Past Releases ● Observations about Standby Resume ● Developmental Philosophy ● Developmental Challenges ● Strategies for Further Development ● Future Plans 09/21/2017 XDC2017 2 About Me ● EE (Electrical Engineering) background (B.S.E.E.) who specialized in digital design / computer architecture in college (pretty much the only undergraduate student “still” doing this stuff where I attended college) ● Graduated recently ● First time conference presenter ● Very experienced with Xilinx FPGA (Spartan-II through 7 Series FPGA) ● Fluent in Verilog / VHDL design and verification ● Interest / design experience with external communication interfaces (PCI / PCIe) and external memory interfaces (SDRAM / DDR3 SDRAM) ● Developed a simple DMA engine for PCI I/F validation w/Windows WDM (Windows Driver Model) kernel device driver ● Almost all the knowledge I have is self taught (university engineering classes were not very useful) 09/21/2017 XDC2017 3 Motivations Behind My Work ● General difficulty in obtaining meaningful employment in the digital hardware design field (too many students in the field, difficulty obtaining internship, etc.) ● Collects and repairs abandoned computer hardware (It’s like rescuing puppies!) ● Owns 100+ desktop computers and 20+ laptop computers (mostly abandoned old stuff I -

NVIDIA Opengl in 2012 Mark Kilgard
NVIDIA OpenGL in 2012 Mark Kilgard • Principal System Software Engineer – OpenGL driver and API evolution – Cg (“C for graphics”) shading language – GPU-accelerated path rendering • OpenGL Utility Toolkit (GLUT) implementer • Author of OpenGL for the X Window System • Co-author of Cg Tutorial Outline • OpenGL’s importance to NVIDIA • OpenGL API improvements & new features – OpenGL 4.2 – Direct3D interoperability – GPU-accelerated path rendering – Kepler Improvements • Bindless Textures • Linux improvements & new features • Cg 3.1 update NVIDIA’s OpenGL Leverage Cg GeForce Parallel Nsight Tegra Quadro OptiX Example of Hybrid Rendering with OptiX OpenGL (Rasterization) OptiX (Ray tracing) Parallel Nsight Provides OpenGL Profiling Configure Application Trace Settings Parallel Nsight Provides OpenGL Profiling Magnified trace options shows specific OpenGL (and Cg) tracing options Parallel Nsight Provides OpenGL Profiling Parallel Nsight Provides OpenGL Profiling Trace of mix of OpenGL and CUDA shows glFinish & OpenGL draw calls Only Cross Platform 3D API OpenGL 3D Graphics API • cross-platform • most functional • peak performance • open standard • inter-operable • well specified & documented • 20 years of compatibility OpenGL Spawns Closely Related Standards Congratulations: WebGL officially approved, February 2012 “The web is now 3D enabled” Buffer and OpenGL 4 – DirectX 11 Superset Event Interop • Interop with a complete compute solution – OpenGL is for graphics – CUDA / OpenCL is for compute • Shaders can be saved to and loaded from binary -

Pcbs : 465 in 1 Babystar PCB
PCBs : 465 in 1 BabyStar PCB 465 in 1 BabyStar PCB 465 in 1 BabyStar PCB 465 Games in 1 BabyStar PCB Rating: Not Rated Yet Price: Sales price: $274.95 Discount: Ask a question about this product Description 465 in 1 BabyStar PCB ***ATX Power Supply with P4 connector required for operation*** JAMMA ready arcade system containing 465 vertical ready to play games. Choose from classics like Ms. Pac man, Donkey Kong, and Frogger to great shooters like 19XX, Strikers 1945 II, and Varth! The game selection menu is easy to understand and navigate. To select a game, scroll through the list and press your button to select. At anytime during the active game aplayer can return back to main game selection menu by holding in the start button for 3 seconds. This sytem runs on a stable flash drive. No hard drive to ever fail! Supports Vertically mounted monitors only. Universal JAMMA Connector. User Friendly Game Selection Screen. P4 Motherboard using genuine Intel Processor and Card Flash memory creates a faster/more stable system! User Adjustable Game Options (Game Dip Switch Settings; Number of Lives, Difficulty, etc). Supports 1-4 Player Games (players 3 & 4 via linking - kit included). Supports two-channel audio (Stereo Sound). Supports CGA Standard Arcade Monitor (15kHz). Supports Upright Cabinets (will not flip screen for cocktails). Enable One Game (for a dedicated machine if desired) or All Games. Enable/Disable Individual Game Categories From Showing. Delete/Undelete Each Game. Set Coin/Credit Ratio of All Games with One Setting. Supports a Coin Counter. System Specifications: JAMMA Controller/Interface PCB. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

Parallel Rendering on Hybrid Multi-GPU Clusters
Eurographics Symposium on Parallel Graphics and Visualization (2012) H. Childs and T. Kuhlen (Editors) Parallel Rendering on Hybrid Multi-GPU Clusters S. Eilemann†1, A. Bilgili1, M. Abdellah1, J. Hernando2, M. Makhinya3, R. Pajarola3, F. Schürmann1 1Blue Brain Project, EPFL; 2CeSViMa, UPM; 3Visualization and MultiMedia Lab, University of Zürich Abstract Achieving efficient scalable parallel rendering for interactive visualization applications on medium-sized graphics clusters remains a challenging problem. Framerates of up to 60hz require a carefully designed and fine-tuned parallel rendering implementation that fits all required operations into the 16ms time budget available for each rendered frame. Furthermore, modern commodity hardware embraces more and more a NUMA architecture, where multiple processor sockets each have their locally attached memory and where auxiliary devices such as GPUs and network interfaces are directly attached to one of the processors. Such so called fat NUMA processing and graphics nodes are increasingly used to build cost-effective hybrid shared/distributed memory visualization clusters. In this paper we present a thorough analysis of the asynchronous parallelization of the rendering stages and we derive and implement important optimizations to achieve highly interactive framerates on such hybrid multi-GPU clusters. We use both a benchmark program and a real-world scientific application used to visualize, navigate and interact with simulations of cortical neuron circuit models. Categories and Subject Descriptors (according to ACM CCS): I.3.2 [Computer Graphics]: Graphics Systems— Distributed Graphics; I.3.m [Computer Graphics]: Miscellaneous—Parallel Rendering 1. Introduction Hybrid GPU clusters are often build from so called fat render nodes using a NUMA architecture with multiple The decomposition of parallel rendering systems across mul- CPUs and GPUs per machine. -

Developer Tools Showcase
Developer Tools Showcase Randy Fernando Developer Tools Product Manager NVISION 2008 Software Content Creation Performance Education Development FX Composer Shader PerfKit Conference Presentations Debugger mental mill PerfHUD Whitepapers Artist Edition Direct3D SDK PerfSDK GPU Programming Guide NVIDIA OpenGL SDK Shader Library GLExpert Videos CUDA SDK NV PIX Plug‐in Photoshop Plug‐ins Books Cg Toolkit gDEBugger GPU Gems 3 Texture Tools NVSG GPU Gems 2 Melody PhysX SDK ShaderPerf GPU Gems PhysX Plug‐Ins PhysX VRD PhysX Tools The Cg Tutorial NVIDIA FX Composer 2.5 The World’s Most Advanced Shader Authoring Environment DirectX 10 Support NVIDIA Shader Debugger Support ShaderPerf 2.0 Integration Visual Models & Styles Particle Systems Improved User Interface Particle Systems All-New Start Page 350Z Sample Project Visual Models & Styles Other Major Features Shader Creation Wizard Code Editor Quickly create common shaders Full editor with assisted Shader Library code generation Hundreds of samples Properties Panel Texture Viewer HDR Color Picker Materials Panel View, organize, and apply textures Even More Features Automatic Light Binding Complete Scripting Support Support for DirectX 10 (Geometry Shaders, Stream Out, Texture Arrays) Support for COLLADA, .FBX, .OBJ, .3DS, .X Extensible Plug‐in Architecture with SDK Customizable Layouts Semantic and Annotation Remapping Vertex Attribute Packing Remote Control Capability New Sample Projects 350Z Visual Styles Atmospheric Scattering DirectX 10 PCSS Soft Shadows Materials Post‐Processing Simple Shadows -

Programming Graphics Hardware Overview of the Tutorial: Afternoon
Tutorial 5 ProgrammingProgramming GraphicsGraphics HardwareHardware Randy Fernando, Mark Harris, Matthias Wloka, Cyril Zeller Overview of the Tutorial: Morning 8:30 Introduction to the Hardware Graphics Pipeline Cyril Zeller 9:30 Controlling the GPU from the CPU: the 3D API Cyril Zeller 10:15 Break 10:45 Programming the GPU: High-level Shading Languages Randy Fernando 12:00 Lunch Tutorial 5: Programming Graphics Hardware Overview of the Tutorial: Afternoon 12:00 Lunch 14:00 Optimizing the Graphics Pipeline Matthias Wloka 14:45 Advanced Rendering Techniques Matthias Wloka 15:45 Break 16:15 General-Purpose Computation Using Graphics Hardware Mark Harris 17:30 End Tutorial 5: Programming Graphics Hardware Tutorial 5: Programming Graphics Hardware IntroductionIntroduction toto thethe HardwareHardware GraphicsGraphics PipelinePipeline Cyril Zeller Overview Concepts: Real-time rendering Hardware graphics pipeline Evolution of the PC hardware graphics pipeline: 1995-1998: Texture mapping and z-buffer 1998: Multitexturing 1999-2000: Transform and lighting 2001: Programmable vertex shader 2002-2003: Programmable pixel shader 2004: Shader model 3.0 and 64-bit color support PC graphics software architecture Performance numbers Tutorial 5: Programming Graphics Hardware Real-Time Rendering Graphics hardware enables real-time rendering Real-time means display rate at more than 10 images per second 3D Scene = Image = Collection of Array of pixels 3D primitives (triangles, lines, points) Tutorial 5: Programming Graphics Hardware Hardware Graphics Pipeline -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
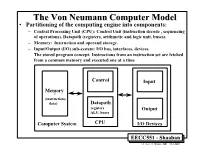
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Parallel Texture-Based Vector Field Visualization on Curved Surfaces Using GPU Cluster Computers
Eurographics Symposium on Parallel Graphics and Visualization (2006) Alan Heirich, Bruno Raffin, and Luis Paulo dos Santos (Editors) Parallel Texture-Based Vector Field Visualization on Curved Surfaces Using GPU Cluster Computers S. Bachthaler1, M. Strengert1, D. Weiskopf2, and T. Ertl1 1Institute of Visualization and Interactive Systems, University of Stuttgart, Germany 2School of Computing Science, Simon Fraser University, Canada Abstract We adopt a technique for texture-based visualization of flow fields on curved surfaces for parallel computation on a GPU cluster. The underlying LIC method relies on image-space calculations and allows the user to visualize a full 3D vector field on arbitrary and changing hypersurfaces. By using parallelization, both the visualization speed and the maximum data set size are scaled with the number of cluster nodes. A sort-first strategy with image-space decomposition is employed to distribute the workload for the LIC computation, while a sort-last approach with an object-space partitioning of the vector field is used to increase the total amount of available GPU memory. We specifically address issues for parallel GPU-based vector field visualization, such as reduced locality of memory accesses caused by particle tracing, dynamic load balancing for changing camera parameters, and the combination of image-space and object-space decomposition in a hybrid approach. Performance measurements document the behavior of our implementation on a GPU cluster with AMD Opteron CPUs, NVIDIA GeForce 6800 Ultra GPUs, and Infiniband network connection. Categories and Subject Descriptors (according to ACM CCS): I.3.3 [Computer Graphics]: Viewing algorithms I.3.3 [Three-Dimensional Graphics and Realism]: Color, shading, shadowing, and texture 1. -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -
Matrox MGA-1064SG Developer Specification
Matrox Graphics Inc. Matrox MGA-1064SG Developer Specification Document Number 10524-MS-0100 February 10, 1997 Trademark Acknowledgements MGA,™ MGA-1064SG,™ MGA-1164SG,™ MGA-2064W,™ MGA-2164W,™ MGA-VC064SFB,™ MGA-VC164SFB,™ MGA Marvel,™ MGA Millennium,™ MGA Mystique,™ MGA Rainbow Run- ner,™ MGA DynaView,™ PixelTOUCH,™ MGA Control Panel,™ and Instant ModeSWITCH,™ are trademarks of Matrox Graphics Inc. Matrox® is a registered trademark of Matrox Electronic Systems Ltd. VGA,® is a registered trademark of International Business Machines Corporation; Micro Channel™ is a trademark of International Business Machines Corporation. Intel® is a registered trademark, and 386,™ 486,™ Pentium,™ and 80387™ are trademarks of Intel Corporation. Windows™ is a trademark of Microsoft Corporation; Microsoft,® and MS-DOS® are registered trade- marks of Microsoft Corporation. AutoCAD® is a registered trademark of Autodesk Inc. Unix™ is a trademark of AT&T Bell Laboratories. X-Windows™ is a trademark of the Massachusetts Institute of Technology. AMD™ is a trademark of Advanced Micro Devices. Atmel® is a registered trademark of Atmel Corpora- tion. Catalyst™ is a trademark of Catalyst Semiconductor Inc. SGS™ is a trademark of SGS-Thompson. Toshiba™ is a trademark of Toshiba Corporation. Texas Instruments™ is a trademark of Texas Instru- ments. National™ is a trademark of National Semiconductor Corporation. Microchip™ is a trademark of Microchip Technology Inc. All other nationally and internationally recognized trademarks and tradenames are hereby acknowledged. This document contains confidential proprietary information that may not be disclosed without written permission from Matrox Graphics Inc. © Copyright Matrox Graphics Inc., 1997. All rights reserved. Disclaimer: Matrox Graphics Inc. reserves the right to make changes to specifications at any time and without notice.