Lightweight, Scalable, Shared-Memory Computing on Many-Core Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mellanox Scalableshmem Support the Openshmem Parallel Programming Language Over Infiniband
SOFTWARE PRODUCT BRIEF Mellanox ScalableSHMEM Support the OpenSHMEM Parallel Programming Language over InfiniBand The SHMEM programming library is a one-side communications library that supports a unique set of parallel programming features including point-to-point and collective routines, synchronizations, atomic operations, and a shared memory paradigm used between the processes of a parallel programming application. SHMEM Details API defined by the OpenSHMEM.org consortium. There are two types of models for parallel The library works with the OpenFabrics RDMA programming. The first is the shared memory for Linux stack (OFED), and also has the ability model, in which all processes interact through a to utilize Mellanox Messaging libraries (MXM) globally addressable memory space. The other as well as Mellanox Fabric Collective Accelera- HIGHLIGHTS is a distributed memory model, in which each tions (FCA), providing an unprecedented level of FEATURES processor has its own memory, and interaction scalability for SHMEM programs running over – Use of symmetric variables and one- with another processors memory is done though InfiniBand. sided communication (put/get) message communication. The PGAS model, The use of Mellanox FCA provides for collective – RDMA for performance optimizations or Partitioned Global Address Space, uses a optimizations by taking advantage of the high for one-sided communications combination of these two methods, in which each performance features within the InfiniBand fabric, – Provides shared memory data transfer process has access to its own private memory, including topology aware coalescing, hardware operations (put/get), collective and also to shared variables that make up the operations, and atomic memory multicast and separate quality of service levels for global memory space. -
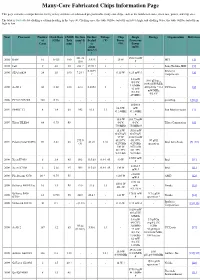
Many-Core Fabricated Chips Information Page
Many-Core Fabricated Chips Information Page This page contains a comprehensive listing of key attributes of fabricated programmable many-core chips, such as the number of cores, clock rate, power, and chip area. The table is Sortable by clicking a column heading in the top row. Clicking once, the table will be sorted from low to high, and clicking twice, the table will be sorted from high to low. Year Processor Number Clock Rate CMOS Die Size Die Size Voltage Chip Single Energy Organization Reference of (GHz) Tech (mm^2) Scaled (V) Power Processor Cores (nm) * to (W) Power 22nm (mW) (mm^2) † 331.24 1562.5 mW 2002 RAW 16 0.425 180 3.975 - 25 W - MIT [1] (16) # 2005 Cell 9 4.0 90 221 ? 17.76 ? 1 - - - Sony,Toshiba,IBM [2] 0.0875 Intelesys 2006 SEAforth24 24 1.0 180 7.29 ? - 0.15 W 6.25 mW # - [3] ? Corporation 2.4 mW 93.0 pJ/Op = @0.9V, 0.093 mW/MHz 116MHz 2006 AsAP 1 36 0.60 180 32.1 0.3852 2 - 300 pJ/Op = 0.3 UC Davis [4] 32 mW mW/MHz @1.8V, @1.8V 475MHz 2006 PC202/203/205 248 0.16 - - - - - - - picoChip [5] [6] 10500.0 84.0 W mW 2007 SPARC T2 8 1.4 65 342 51.3 1.1 - Sun Microsystems [7] @1.4GHz @1.4GHz # 10.8 W 168.75 mW 2007 Tilera TILE64 64 0.75 90 - - - @1V, @1V, - Tilera Corporation [8] 750MHz 750MHz # 15.6 W 195.0 mW @670mV @670mV 97 W 1212.5 mW 275.0 @1.07V, @1.07V, 97 pJ/fl 2007 Polaris(TeraFLOPS) 80 5.67 65 41.25 1.35 Intel Tera-Scale [9] [10] (3) 4.27GHz 4.27GHz operation 230 W 2875 mW @1.35V, @1.35V, 5.67GHz 5.67GHz 15000 mW 2008 Xeon E7450 6 2.4 45 503 115.69 0.9-1.45 90 W - Intel [11] # 21666.7 2008 Xeon X7460 6 2.66 45 503 -

Introduction to Parallel Programming
Introduction to Parallel Programming Martin Čuma Center for High Performance Computing University of Utah [email protected] Overview • Types of parallel computers. • Parallel programming options. • How to write parallel applications. • How to compile. • How to debug/profile. • Summary, future expansion. 3/13/2009 http://www.chpc.utah.edu Slide 2 Parallel architectures Single processor: • SISD – single instruction single data. Multiple processors: • SIMD - single instruction multiple data. • MIMD – multiple instruction multiple data. Shared Memory Distributed Memory 3/13/2009 http://www.chpc.utah.edu Slide 3 Shared memory Dual quad-core node • All processors have BUS access to local memory CPU Memory • Simpler programming CPU Memory • Concurrent memory access Many-core node (e.g. SGI) • More specialized CPU Memory hardware BUS • CHPC : CPU Memory Linux clusters, 2, 4, 8 CPU Memory core nodes CPU Memory 3/13/2009 http://www.chpc.utah.edu Slide 4 Distributed memory • Process has access only BUS CPU to its local memory Memory • Data between processes CPU Memory must be communicated • More complex Node Network Node programming Node Node • Cheap commodity hardware Node Node • CHPC: Linux clusters Node Node (Arches, Updraft) 8 node cluster (64 cores) 3/13/2009 http://www.chpc.utah.edu Slide 5 Parallel programming options Shared Memory • Threads – POSIX Pthreads, OpenMP – Thread – own execution sequence but shares memory space with the original process • Message passing – processes – Process – entity that executes a program – has its own -

An Open Standard for SHMEM Implementations Introduction
OpenSHMEM: An Open Standard for SHMEM Implementations Introduction • OpenSHMEM is an effort to create a standardized SHMEM library for C , C++, and Fortran • OpenSHMEM is a Partitioned Global Address Space (PGAS) library and supports Single Program Multiple Data (SPMD) style of programming • SGI’s SHMEM API is the baseline for OpenSHMEM Specification 1.0 • One-sided communication is achieved through Symmetric variables • globals C/C++: Non-stack variables Fortran: objects in common blocks or with the SAVE attribute • dynamically allocated and managed by the OpenSHMEM Library Figure 1. Dynamic allocation of symmetric variable ‘x’ OpenSHMEM API • OpenSHMEM Specification 1.0 provides support for data transfer operations, collective and point- to-point synchronization mechanisms (barrier, fence, quiet, wait), collective operations (broadcast, collection, reduction), atomic memory operations (swap, fetch/add, increment), and distributed locks. • Open to the community for reviews and contributions. Current Status • University of Houston has developed a portable reference OpenSHMEM library. • OpenSHMEM Specification 1.0 man pages are available. • OpenSHMEM mailing list for discussions and contributions can be joined by emailing [email protected] • Website for OpenSHMEM and a Wiki for community use are available. Figure 2. University of Houston http://www.openshmem.org/ Implementation Future Work and Goals • Develop OpenSHMEM Specification 2.0 with co-operation and contribution from the OpenSHMEM community • Discuss and extend specification with important new capabilities • Improve on the OpenSHMEM reference implementation by providing support for scalable collective algorithms • Explore innovative hardware platforms . -

Enabling Efficient Use of UPC and Openshmem PGAS Models on GPU Clusters
Enabling Efficient Use of UPC and OpenSHMEM PGAS Models on GPU Clusters Presented at GTC ’15 Presented by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: [email protected] hCp://www.cse.ohio-state.edu/~panda Accelerator Era GTC ’15 • Accelerators are becominG common in hiGh-end system architectures Top 100 – Nov 2014 (28% use Accelerators) 57% use NVIDIA GPUs 57% 28% • IncreasinG number of workloads are beinG ported to take advantage of NVIDIA GPUs • As they scale to larGe GPU clusters with hiGh compute density – hiGher the synchronizaon and communicaon overheads – hiGher the penalty • CriPcal to minimize these overheads to achieve maximum performance 3 Parallel ProGramminG Models Overview GTC ’15 P1 P2 P3 P1 P2 P3 P1 P2 P3 LoGical shared memory Shared Memory Memory Memory Memory Memory Memory Memory Shared Memory Model Distributed Memory Model ParPPoned Global Address Space (PGAS) DSM MPI (Message PassinG Interface) Global Arrays, UPC, Chapel, X10, CAF, … • ProGramminG models provide abstract machine models • Models can be mapped on different types of systems - e.G. Distributed Shared Memory (DSM), MPI within a node, etc. • Each model has strenGths and drawbacks - suite different problems or applicaons 4 Outline GTC ’15 • Overview of PGAS models (UPC and OpenSHMEM) • Limitaons in PGAS models for GPU compuPnG • Proposed DesiGns and Alternaves • Performance Evaluaon • ExploiPnG GPUDirect RDMA 5 ParPPoned Global Address Space (PGAS) Models GTC ’15 • PGAS models, an aracPve alternave to tradiPonal message passinG - Simple -

Introduction to Parallel Computing
Introduction to Parallel Computing https://computing.llnl.gov/tutorials/parallel_comp/ | | | | | | Introduction to Parallel Computing Table of Contents 1. Abstract 2. Overview 1. What is Parallel Computing? 2. Why Use Parallel Computing? 3. Concepts and Terminology 1. von Neumann Computer Architecture 2. Flynn's Classical Taxonomy 3. Some General Parallel Terminology 4. Parallel Computer Memory Architectures 1. Shared Memory 2. Distributed Memory 3. Hybrid Distributed-Shared Memory 5. Parallel Programming Models 1. Overview 2. Shared Memory Model 3. Threads Model 4. Message Passing Model 5. Data Parallel Model 6. Other Models 6. Designing Parallel Programs 1. Automatic vs. Manual Parallelization 2. Understand the Problem and the Program 3. Partitioning 4. Communications 5. Synchronization 6. Data Dependencies 7. Load Balancing 8. Granularity 9. I/O 10. Limits and Costs of Parallel Programming 11. Performance Analysis and Tuning 7. Parallel Examples 1. Array Processing 2. PI Calculation 3. Simple Heat Equation 4. 1-D Wave Equation 8. References and More Information 1 of 44 04/18/2008 08:28 AM Introduction to Parallel Computing https://computing.llnl.gov/tutorials/parallel_comp/ Abstract This presentation covers the basics of parallel computing. Beginning with a brief overview and some concepts and terminology associated with parallel computing, the topics of parallel memory architectures and programming models are then explored. These topics are followed by a discussion on a number of issues related to designing parallel programs. The last portion of the presentation is spent examining how to parallelize several different types of serial programs. Level/Prerequisites: None Overview What is Parallel Computing? Traditionally, software has been written for serial computation: To be run on a single computer having a single Central Processing Unit (CPU); A problem is broken into a discrete series of instructions. -

Bridging Parallel and Reconfigurable Computing with Multilevel PGAS and SHMEM+
Bridging Parallel and Reconfigurable Computing with Multilevel PGAS and SHMEM+ Vikas Aggarwal Alan D. George HPRCTA 2009 Kishore Yalamanchalli Changil Yoon Herman Lam Greg Stitt NSF CHREC Center ECE Department, University of Florida 30 September 2009 Outline Introduction Motivations Background Approach Multilevel PGAS model SHMEM+ Experimental Testbed and Results Performance benchmarking Case study: content-based image recognition (CBIR) Conclusions & Future Work 2 Motivations RC systems offer much superior performance 10x to 1000x higher application speed, lower energy consumption Characteristic differences from traditional HPC systems Multiple levels of memory hierarchy Heterogeneous execution contexts Lack of integrated, system-wide, parallel-programming models HLLs for RC do not address scalability/multi-node designs Existing parallel models insufficient; fail to address needs of RC systems Productivity for scalable, parallel, RC applications very low 3 Background Traditionally HPC applications developed using Message-passing models, e.g. MPI, PVM, etc. Shared-memory models, e.g. OpenMP, etc. More recently, PGAS models, e.g. UPC, SHMEM, etc. Extend memory hierarchy to include high-level global memory layer, partitioned between multiple nodes PGAS has common goals & concepts P Requisite syntax, and semantics to meet needs of G coordination for reconfigurable HPC systems A SHMEM: Shared MEMory comm. library S However, needs adaptation and extension for reconfigurable HPC systems Introduce multilevel PGAS and SHMEM+ PGAS: Partitioned, Global Address Space 4 Background: SHMEM Shared and local variables Why program using SHMEM in SHMEM Based on SPMD; easier to program in than MPI (or PVM) Low latency, high bandwidth one-sided data transfers (put s and get s) Provides synchronization mechanisms Barrier Fence, quiet Provides efficient collective communication Broadcast Collection Reduction 5 Background: SHMEM Array copy example 1. -

Distributed Shared Memory – a Survey and Implementation Using Openshmem
Ryan Saptarshi Ray Int. Journal of Engineering Research and Applications www.ijera.com ISSN: 2248-9622, Vol. 6, Issue 2, (Part - 1) February 2016, pp.49-52 RESEARCH ARTICLE OPEN ACCESS Distributed Shared Memory – A Survey and Implementation Using Openshmem Ryan Saptarshi Ray, Utpal Kumar Ray, Ashish Anand, Dr. Parama Bhaumik Junior Research Fellow Department of Information Technology, Jadavpur University Kolkata, India Assistant Professor Department of Information Technology, Jadavpur University Kolkata, India M. E. Software Engineering Student Department of Information Technology, Jadavpur University Kolkata, India Assistant Professor Department of Information Technology, Jadavpur University Kolkata, India Abstract Parallel programs nowadays are written either in multiprocessor or multicomputer environment. Both these concepts suffer from some problems. Distributed Shared Memory (DSM) systems is a new and attractive area of research recently, which combines the advantages of both shared-memory parallel processors (multiprocessors) and distributed systems (multi-computers). An overview of DSM is given in the first part of the paper. Later we have shown how parallel programs can be implemented in DSM environment using Open SHMEM. I. Introduction networks of workstation using cluster technologies Parallel Processing such as the MPI programming interface [3]. Under The past few years have marked the start of a MPI, machines may explicitly pass messages, but do historic transition from sequential to parallel not share variables or memory regions directly. computation. The necessity to write parallel programs Parallel computing systems usually fall into two is increasing as systems are getting more complex large classifications, according to their memory while processor speed increases are slowing down. system organization: shared and distributed-memory Generally one has the idea that a program will run systems. -

NUG Monthly Meeting
NUG Monthly Meeting Helen He, David Turner, Richard Gerber NUG Monthly Mee-ng July 10, 2014 - 1 - Edison Issues Since the 6/25 upgrade! Zhengji Zhao " NERSC User Services Group" " NUG Monthly 2014 " July 10, 2014! Upgrades on Edison on 6/25 (partial list)! • Maintenance/Configura-on Modifica-ons – set CDT 1.16 to default • Upgrades on Edison login nodes – SLES 11 SP3 – BCM 6.1 – ESM-XX-3.0.0 – ESL-XC-2.2.0 • Upgrades on main frame – Sonexion update_cs.1.3.1-007 • /scratch3 only – CLE 5.2 UP01 - 3 - MPT 7.0.0 and CLE 5.2 UP01 upgrades require all MPI codes to be recompiled! • Release note for MPT 7.0.0 – MPT 7.0 ABI compability change in this release. An ABI change in the MPT 7.0 release requires all MPI user code to be recompiled. ScienLfic libraries, Performance Tools, Cray Compiling Environment and third party libraries compable with the new ABI are included in this PE release. • Release overview for CLE 5.2 UP01 regarding binary compa-bility – Applicaons and binaries compiled for plaorms other than Cray XC30 systems may need to be recompiled. – Binaries compiled for Cray XC30 systems running earlier releases of CLE should run on Cray XC30 systems running CLE 5.2 without needing to be recompiled, provided the binaries are dynamically linked. – However, stacally linked binaries which are direct or indirect consumers of the network interface libraries (uGNI/DMAPP) must be relinked. This is because the DMAPP and uGNI libraries are Led to specific kernel versions and no backward or forward compability is provided. -

A Space Exploration Framework for GPU Application and Hardware Codesign
SESH framework: A Space Exploration Framework for GPU Application and Hardware Codesign Joo Hwan Lee Jiayuan Meng Hyesoon Kim School of Computer Science Leadership Computing Facility School of Computer Science Georgia Institute of Technology Argonne National Laboratory Georgia Institute of Technology Atlanta, GA, USA Argonne, IL, USA Atlanta, GA, USA [email protected] [email protected] [email protected] Abstract—Graphics processing units (GPUs) have become needs to attempt tens of transformations in order to fully increasingly popular accelerators in supercomputers, and this understand the performance potential of a specific hardware trend is likely to continue. With its disruptive architecture configuration. Fourth, evaluating the performance of a partic- and a variety of optimization options, it is often desirable to ular implementation on a future hardware may take significant understand the dynamics between potential application transfor- time using simulators. Fifth, the current performance tools mations and potential hardware features when designing future (e.g., simulators, hardware models, profilers) investigate either GPUs for scientific workloads. However, current codesign efforts have been limited to manual investigation of benchmarks on hardware or applications in a separate manner, treating the microarchitecture simulators, which is labor-intensive and time- other as a black box and therefore, offer limited insights for consuming. As a result, system designers can explore only a small codesign. portion of the design space. In this paper, we propose SESH framework, a model-driven codesign framework for GPU, that is To efficiently explore the design space and provide first- able to automatically search the design space by simultaneously order insights, we propose SESH, a model-driven framework exploring prospective application and hardware implementations that automatically searches the design space by simultaneously and evaluate potential software-hardware interactions. -

Parallel Computing, Models and Their Performances
Parallel computing models and their performances A high level exploration of the parallel computing world George Bosilca [email protected] Overview • Definition of parallel application • Architectures taxonomy • What is quantifiable ? Laws managing the parallel applications field • Modeling performance of parallel applications Formal definition of parallelism The Bernstein Conditions Let’s define: • I(P) all variables, registers and memory locations used by P • O(P) all variables, registers and memory locations written by P Then P1; P2 is equivalent to P1 || P2 if and only if {I(P1) Ç O(P2) = Æ & I(P2) Ç O(P1) = Æ & O(P1) Ç O(P2) = Æ} General case: P1… Pn are parallel if and only if each for each pair Pi, Pj we have Pi || Pj. 3 limit to the parallel applications: I1 I2 1. Data dependencies 2. Flow dependencies P1 P2 3. Resources dependencies O1 O2 Data dependencies I1 I1 A A I1: A = B + C I2 I2 I2: E = D + A I3: A = F + G A I3 I3 Flow dependency (RAW): a variable assigned in a statement is used in a later statement Anti-dependency (WAR): a variable used in a statement is assigned in a subsequent statement Output dependency (WAW): a variable assigned in a statement is subsequently re-assigned How to avoid them? Which type of data dependency can be avoided ? Flow dependencies I1 I1 I2 I1: A = B + C I2 I2: if( A ) { I3: D = E + F } I3 I3 I4: G = D + H I4 I4 Data dependency Control dependency How to avoid ? Resources dependencies I1 I2 I1: A = B + C I2: G = D + H + How to avoid ? A more complicated example (loop) for i = 0 to 9 for i = 1 to 9 A[i] = B[i] A[i] = A[i-1] A[1] = A[0] All statements All statements are independent, A[2] = A[1] are dependent, as they relate to A[3] = A[2] as every 2 different data. -

Benchmarking Parallel Performance on Many-Core Processors
Benchmarking Parallel Performance on Many-Core Processors Bryant C. Lam (speaker) OpenSHMEM Workshop 2014 Ajay Barboza Ravi Agrawal Dr. Alan D. George Dr. Herman Lam NSF Center for High-Performance Reconfigurable Computing (CHREC), University of Florida March 4-6, 2014 Motivation and Approach Motivation Emergent many-core processors in HPC and scientific computing require performance profiling with existing parallelization tools, libraries, and models HPC typically distributed cluster systems of multi-core devices New shifts toward heterogeneous computing for better power utilization Can many-core processors replace several servers? Can computationally dense servers of many-core devices scale? Can many-core replace other accelerators (e.g., GPU) in heterogeneous systems? Approach Evaluate architectural strengths of two current-generation many-core processors Tilera TILE-Gx8036 and Intel Xeon Phi 5110P Evaluate many-core app performance and scalability with SHMEM and OpenMP on these many-core processors 2 Overview Devices Tilera TILE-Gx Intel Xeon Phi Benchmarking Parallel Applications SHMEM and OpenMP applications SHMEM-only applications Conclusions 3 Tilera TILE-Gx8036 Architecture 64-bit VLIW processors 32k L1i cache, 32k L1d cache 256k L2 cache per tile Up to 750 billion operations per second Up to 60 Tbps of on-chip mesh interconnect Over 500 Gbps memory bandwidth 1 to 1.5 GHz operating frequency Power consumption: 10 to 55W; 22W for typical applications 2-4 DDR3 memory controllers mPIPE delivers wire-speed