TLG Beta Code Quick Reference Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Hebrew Alphabet
BBH2 Textbook Supplement Chapter 1 – The Hebrew Alphabet 1 The following comments explain, provide mnemonics for, answer questions that students have raised about, and otherwise supplement the second edition of Basics of Biblical Hebrew by Pratico and Van Pelt. Chapter 1 – The Hebrew Alphabet 1.1 The consonants For begadkephat letters (§1.5), the pronunciation in §1.1 is the pronunciation with the Dagesh Lene (§1.5), even though the Dagesh Lene is not shown in §1.1. .Kaf” has an “off” sound“ כ The name It looks like open mouth coughing or a cup of coffee on its side. .Qof” is pronounced with either an “oh” sound or an “oo” sound“ ק The name It has a circle (like the letter “o” inside it). Also, it is transliterated with the letter q, and it looks like a backwards q. here are different wa s of spellin the na es of letters. lef leph leˉ There are many different ways to write the consonants. See below (page 3) for a table of examples. See my chapter 1 overheads for suggested letter shapes, stroke order, and the keys to distinguishing similar-looking letters. ”.having its dot on the left: “Sin is never ri ht ׂש Mnemonic for Sin ׁש and Shin ׂש Order of Sin ׁש before Shin ׂש Our textbook and Biblical Hebrew lexicons put Sin Some alphabet songs on YouTube reverse the order of Sin and Shin. Modern Hebrew dictionaries, the acrostic poems in the Bible, and ancient abecedaries (inscriptions in which someone wrote the alphabet) all treat Sin and Shin as the same letter. -

End-Of-Line Hyphenation of Chemical Names (IUPAC Provisional
Pure Appl. Chem. 2020; aop IUPAC Recommendations Albert J. Dijkstra*, Karl-Heinz Hellwich, Richard M. Hartshorn, Jan Reedijk and Erik Szabó End-of-line hyphenation of chemical names (IUPAC Provisional Recommendations) https://doi.org/10.1515/pac-2019-1005 Received October 16, 2019; accepted January 21, 2020 Abstract: Chemical names and in particular systematic chemical names can be so long that, when a manu- script is printed, they have to be hyphenated/divided at the end of a line. Many systematic names already contain hyphens, but sometimes not in a suitable division position. In some cases, using these hyphens as end-of-line divisions can lead to illogical divisions in print, as can also happen when hyphens are added arbi- trarily without considering the ‘chemical’ context. The present document provides recommendations and guidelines for authors of chemical manuscripts, their publishers and editors, on where to divide chemical names at the end of a line and instructions on how to avoid these names being divided at illogical places as often suggested by desk dictionaries. Instead, readability and chemical sense should prevail when authors insert optional hyphens. Accordingly, the software used to convert electronic manuscripts to print can now be programmed to avoid illogical end-of-line hyphenation and thereby save the author much time and annoy- ance when proofreading. The recommendations also allow readers of the printed article to determine which end-of-line hyphens are an integral part of the name and should not be deleted when ‘undividing’ the name. These recommendations may also prove useful in languages other than English. -

Nl 6 1999-2000
& ST. SHENOUDA COPTIC NEWSLETTER SUBSCRIBER'S EDITION Quarterly Newsletter Published by the St. Shenouda Center for Coptic Studies 1494 S. Robertson Blvd., Ste. 204, LA, CA 90035 Tel: (310) 271-8329 Fax: (310) 558-1863 Mailing Address: 1701 So. Wooster St. Los Angeles, CA 90035, U.S.A. October, 1999 Volume 6(N.S. 3), No. 1 In This Issue: The Second St. Shenouda Conference of Coptic Studies (4) by Hany N. Takla ............1 Conference Abstracts (2) by Hany N. Takla ...................................................................7 The 7th International Congress of Coptic Studies by Dr. J. van der Vliet......................10 A Tribute to Professor Paul van Moorsel by Dr. Mat Immerzeel ...................................12 News by Hany N. Takla ..................................................................................................14 The Second St. Shenouda Conference of Coptic StudiesNewsletter (August 13 - 14, 1999 - Los Angeles, California) (4) (by Hany N. Takla) Introduction: For a second time in as many years, scholar, Bishop Samuel of Shibin al-Qanatar, the Society held its annual Conference of Coptic Egypt. Notably present was Prof. James Robinson, Studies. This time it was held at, its probable the retired director of the Claremont Institute for permanent future site, the Campus of the CopticChristianity and Antiquity (ICA). University of California, Los Angeles (UCLA). Several of the presenters came from different parts As planned, this gathering brought together several of the United States: Prof. Boulos Ayad Ayad, segments of the population that had the common Boulder Co; Dr. Bastiaan Van Elderen, Grand interest of Coptic Studies. This mixture of the Haven MI; Dr. Fawzy Estafanous, Cleveland OH; young and old, the amateurs and professionals, and Mr. -

On the Use of Coptic Numerals in Egypt in the 16 Th Century
ON THE USE OF COPTIC NUMERALS IN EGYPT IN THE 16 TH CENTURY Mutsuo KAWATOKO* I. Introduction According to the researches, it is assumed that the culture of the early Islamic period in Egypt was very similar to the contemporary Coptic (Qibti)/ Byzantine (Rumi) culture. This is most evident in their language, especially in writing. It was mainly Greek and Coptic which adopted the letters deriving from Greek and Demotic. Thus, it was normal in those days for the official documents to be written in Greek, and, the others written in Coptic.(1) Gold, silver and copper coins were also minted imitating Byzantine Solidus (gold coin) and Follis (copper coin) and Sassanian Drahm (silver coin), and they were sometimes decorated with the representation of the religious legends, such as "Allahu", engraved in a blank space. In spite of such situation, around A. H. 79 (698), Caliph 'Abd al-Malik b. Marwan implemented the coinage reformation to promote Arabisation of coins, and in A. H. 87 (706), 'Abd Allahi b. 'Abd al-Malik, the governor- general of Egypt, pursued Arabisation of official documentation under a decree by Caliph Walid b. 'Abd al-Malik.(2) As a result, the Arabic letters came into the immediate use for the coin inscriptions and gradually for the official documents. However, when the figures were involved, the Greek or the Coptic numerals were used together with the Arabic letters.(3) The Abjad Arabic numerals were also created by assigning the numerical values to the Arabic alphabetic (abjad) letters just like the Greek numerals, but they did not spread very much.(4) It was in the latter half of the 8th century that the Indian numerals, generally regarded as the forerunners of the Arabic numerals, were introduced to the Islamic world. -

PARK JIN HYOK, Also Known As ("Aka") "Jin Hyok Park," Aka "Pak Jin Hek," Case Fl·J 18 - 1 4 79
AO 91 (Rev. 11/11) Criminal Complaint UNITED STATES DISTRICT COURT for the RLED Central District of California CLERK U.S. DIS RICT United States ofAmerica JUN - 8 ?018 [ --- .. ~- ·~".... ~-~,..,. v. CENT\:y'\ l i\:,: ffl1G1 OF__ CAUFORN! BY .·-. ....-~- - ____D=E--..... PARK JIN HYOK, also known as ("aka") "Jin Hyok Park," aka "Pak Jin Hek," Case fl·J 18 - 1 4 79 Defendant. CRIMINAL COMPLAINT I, the complainant in this case, state that the following is true to the best ofmy knowledge and belief. Beginning no later than September 2, 2014 and continuing through at least August 3, 2017, in the county ofLos Angeles in the Central District of California, the defendant violated: Code Section Offense Description 18 U.S.C. § 371 Conspiracy 18 u.s.c. § 1349 Conspiracy to Commit Wire Fraud This criminal complaint is based on these facts: Please see attached affidavit. IBJ Continued on the attached sheet. Isl Complainant's signature Nathan P. Shields, Special Agent, FBI Printed name and title Sworn to before ~e and signed in my presence. Date: ROZELLA A OLIVER Judge's signature City and state: Los Angeles, California Hon. Rozella A. Oliver, U.S. Magistrate Judge Printed name and title -:"'~~ ,4G'L--- A-SA AUSAs: Stephanie S. Christensen, x3756; Anthony J. Lewis, x1786; & Anil J. Antony, x6579 REC: Detention Contents I. INTRODUCTION .....................................................................................1 II. PURPOSE OF AFFIDAVIT ......................................................................1 III. SUMMARY................................................................................................3 -

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

Transcription of Historical Ciphers and Keys: Guidelines
cl.lingfil.uu.se/decode Beáta Megyesi [email protected] February 10, 2020 Transcription of Historical Ciphers and Keys: Guidelines Content 1 Introduction 3 2 Transcription of Ciphertext 3 2.1 Metadata 3 2.2 Content 4 2.2.1 Line breaks, spaces, punctuation and diacritical marks 4 2.2.2 Catchwords 7 2.2.3 Notes in margins 8 2.3 Transcription of ciphertext, cleartext and plaintext 10 2.4 Upload of transcriptions into the DECODE database 12 3 Transcription of Keys 12 3.1 Original keys 14 3.1.1 Metadata 14 3.1.2 Transcription of codes 14 3.1.3 Upload of transcribed original keys into the DECODE database 17 3.2 Reconstructed keys 17 3.2.1 Metadata 17 3.2.2 Transcription of codes 18 3.2.3 Upload of transcribed recovered keys into the DECODE database 18 4 Transcription of Cleartexts 18 4.1 Metadata 18 4.2 Transcription of cleartext 19 4.3 Upload of cleartext transcriptions into the DECODE database 19 5. Summary 20 Acknowledgements 20 References 20 Appendix: Transcription of Special Symbols 21 Greek letters 21 Roman numerals 22 Zodiac signs 23 Alchemical signs 24 Other signs 25 2 1 Introduction The document describes guidelines for the transcription of encrypted sources and related documents, being it ciphertext, original or recovered keys, and cleartext. Usually, the first step in attacking a cipher is the conversion of the image into a machine- readable format, represented as text. There are many different ways of transcribing a manuscript. Therefore, we developed guidelines so that the transcriptions available in the DECODE database1 (Megyesi et al., 2019) have a common format. -
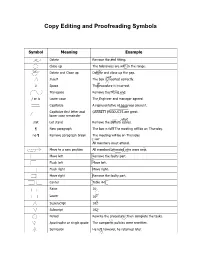
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Russia Imperial Russia & Soviet Union May 26, 2014
© 2014, David Feldman S.A. All rights reserved All content of this catalogue, such as text, images and their arrangement, is the property of David Feldman S.A., and is protected by international copyright laws. The objects displayed in this catalogue are shown with the expressed permission of their owners. Produced through The Bookmaker Printed in China by CTPS Russia Imperial Russia & Soviet Union May 26, 2014 Genève - Feldman Galleries Imperial Russia 10000-10454 Soviet Union 10455-10584 Contact Us Geneva 175, Route de Chancy, P.O. Box 81, CH-1213 Onex, Geneva, Switzerland Tel. +41 (0)22 727 07 77 – Fax +41 (0)22 727 07 78 – [email protected] www.davidfeldman.com Russia Imperial Russia & Soviet Union May 26, 2014 You are invited to participate VIEWING / VisiTE des LOTS / ANZeige Geneva / Genève / Genf Before May 23 Feldman Galleries 175 route de Chancy, 1213 Onex, Geneva, Switzerland By appointment: contact Tel.: +41 (0)22 727 07 77 (Viewing of lots on weekends or evenings can be arranged) From May 26 General viewing from 09:00 to 19:00 daily AUCTION / VENTE / AUKTION May 26 at 15:00 Lots 10000-10584 Phone line during the auction / Ligne téléphonique pendant la vente / Telefonleitung während der Auktion Tel. +41 22 727 07 77 British Guiana The John E. Du Pont Grand Prix Collection Geneva, June 27, 2014 One of the most important collections ever formed of the famous primitive issues Tasmania The Koichi Sato Grand Prix d’Honneur Collection Geneva, June 27, 2014 A wonderful collection of this rarely offered Australian State Geneva Hong Kong New York 175, Route de Chancy, P.O. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS