Strategies for the Intelligent Selection of Components
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Africa Centre of Excellence on Technology Enhanced Learning (ACETEL)
CIT 215: INTRODUCTION TO PROGRAMMING LANGUAGE Africa Centre of Excellence on Technology Enhanced Learning (ACETEL) Course Guide 1 NATIONAL OPEN UNIVERSITY OF NIGERIA FACULTY OF SCIENCE COURSE CODE: CIT 215 COURSE TITLE: INTRODUCTION TO PROGRAMMING LANGUAGE 2 Introduction CIT 215 Introduction to Programming Languages is a three [3] credit unit course of twenty units. It deals with Introduction to Programming languages. Programming languages are not very different from spoken languages. Learning any language requires an understanding of the building blocks and the grammar that govern the construction of statements in that language. This book will serve as an introduction to programming languages, taking you through the history of programming languages. We will also learn about the various universal properties of all programming languages and identify distinct design features of each programming language. By the end of this book, you will have a deeper understanding of what a programming language is and the ability to recognize the properties of programming languages. You will also take overview of some programming languages such as to Basic, Fortran, Pascal, C++ , HTML and Visual Basic. Module 1 provides a foundation for the course. In this module we introduce the art of computer programming; explained computer programming languages, and introductory theory of algorithms. Also covered in the module are Flowcharting Techniques and structured programming Module 2: In this module, we provide introductions to the rudiments of BASIC and FORTRAN programming language. In this module we introduce BASIC Programming; explained more programming statements in BASIC, and introduce you to FORTRAN Language. Also covered in the module are FORTRAN Keywords and Library Functions. -

BASIC Programming with Unix Introduction
LinuxFocus article number 277 http://linuxfocus.org BASIC programming with Unix by John Perr <johnperr(at)Linuxfocus.org> Abstract: About the author: Developing with Linux or another Unix system in BASIC ? Why not ? Linux user since 1994, he is Various free solutions allows us to use the BASIC language to develop one of the French editors of interpreted or compiled applications. LinuxFocus. _________________ _________________ _________________ Translated to English by: Georges Tarbouriech <gt(at)Linuxfocus.org> Introduction Even if it appeared later than other languages on the computing scene, BASIC quickly became widespread on many non Unix systems as a replacement for the scripting languages natively found on Unix. This is probably the main reason why this language is rarely used by Unix people. Unix had a more powerful scripting language from the first day on. Like other scripting languages, BASIC is mostly an interpreted one and uses a rather simple syntax, without data types, apart from a distinction between strings and numbers. Historically, the name of the language comes from its simplicity and from the fact it allows to easily teach programming to students. Unfortunately, the lack of standardization lead to many different versions mostly incompatible with each other. We can even say there are as many versions as interpreters what makes BASIC hardly portable. Despite these drawbacks and many others that the "true programmers" will remind us, BASIC stays an option to be taken into account to quickly develop small programs. This has been especially true for many years because of the Integrated Development Environment found in Windows versions allowing graphical interface design in a few mouse clicks. -
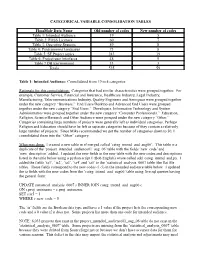
Categorical Variable Consolidation Tables
CATEGORICAL VARIABLE CONSOLIDATION TABLES FlossMole Data Name Old number of codes New number of codes Table 1: Intended Audience 19 5 Table 2: FOSS Licenses 60 7 Table 3: Operating Systems 59 8 Table 4: Programming languages 73 8 Table 5: SF Project topics 243 19 Table 6: Project user interfaces 48 9 Table 7 DB Environment 33 3 Totals 535 59 Table 1: Intended Audience: Consolidated from 19 to 4 categories Rationale for this consolidation: Categories that had similar characteristics were grouped together. For example, Customer Service, Financial and Insurance, Healthcare Industry, Legal Industry, Manufacturing, Telecommunications Industry, Quality Engineers and Aerospace were grouped together under the new category “Business.” End Users/Desktop and Advanced End Users were grouped together under the new category “End Users.” Developers, Information Technology and System Administrators were grouped together under the new category “Computer Professionals.” Education, Religion, Science/Research and Other Audience were grouped under the new category “Other.” Categories containing large numbers of projects were generally left as individual categories. Perhaps Religion and Education should have be left as separate categories because of they contain a relatively large number of projects. Since Mike recommended we get the number of categories down to 50, I consolidated them into the “Other” category. What was done: I created a new table in sf merged called ‘categ_intend_aud_aug06’. This table is a duplicate of the ‘project_intended_audience01_aug_06’ table with the fields ‘new_code’ and ‘new_description’ added. I updated the new fields in the new table with the new codes and descriptions listed in the table below using a python script I (Bob English) wrote called add_categ_intend_aud.py. -

DEALING with DATA EDITOR’S NOTE Does Your Program Smell Passive Authentication for ASP.NET with WIF Like Bacon? Michele Leroux Bustamante
THE MICROSOFT JOURNAL FOR DEVELOPERS AUGUST 2010 VOL 25 NO 8 COLUMNS DEALING WITH DATA EDITOR’S NOTE Does Your Program Smell Passive Authentication for ASP.NET with WIF Like Bacon? Michele Leroux Bustamante . 20 Keith Ward page 4 CUTTING EDGE Tips for Migrating Your Applications to the Cloud Don’t Worry, Be Lazy George Huey and Wade Wegner . 36 Dino Esposito page 6 Creating Synchronization Providers DATA POINTS Deny Table Access to the with the Sync Framework Entity Framework Without Joydip Kanjilal . 46 Causing a Mutiny Julie Lerman page 14 Building an AtomPub Server Using WCF Data Services TEST RUN Chris Sells . 54 Fault Injection Testing with TestApi James McCaffrey page 84 Tuning Your Database Calls THE WORKING PROGRAMMER with Tier Interaction Profi ling Inside SQLite Mark Friedman . 62 Ted Neward page 88 UI FRONTIERS Building Distributed Apps with NHibernate Multi-Touch Manipulation Events in WPF and Rhino Service Bus, Part 2 Charles Petzold page 92 Oren Eini . 72 DON’T GET ME STARTED Windows Phone and the Cloud: an Introduction Mars and Venus David Platt page 96 Ramon Arjona . 78 Untitled-5 2 3/5/10 10:16 AM Sure, Visual Studio 2010 has a lot of great functionality— we’re excited that it’s only making our User Interface components even better! We’re here to help you go beyond what Visual Studio 2010 gives you so you can create Killer Apps quickly, easily and without breaking a sweat! Go to infragistics.com/beyondthebox today to expand your toolbox with the fastest, best-performing and most powerful UI controls available. -

Deep Scrutiny of Compilers in Industry with Estimating on Conglomerate Factors
JOURNAL OF CRITICAL REVIEWS ISSN- 2394-5125 VOL 7, ISSUE 11, 2020 Deep scrutiny of compilers in industry with estimating on conglomerate factors Dr Sandeep Kulkarni 1, Prof(Dr) K P Yadav 2 1,2Sangum University, Bilwara, Rajasthan [email protected], [email protected] Received: 05 May 2020 Revised: and Accepted: 15 July 2020 ABSTRACT: As to understand the basic knowledge of compilers , various types of compilers in the programming world ,we will study in detail the compilers available in various languages. As we are going to study their compilers working usage for which they have used in various companies in software industries. M- DOS with Microsoft windows uses Borland C++ compilers with the help of any C and C++Integrated development environment tool. As it is advance version when compared to Turbo C++ it known for good performance in debugging purpose so for this Turbo debugger and this software is written mode of DOS which is protected.There are set of library which is helpful for building graphical windows projects known as Object windows library . With the C++ program DOS applications is created. Applications such as pop up boxes, application top menus, dialog boxes for this turbo vision is used. Applications presenting in 2 dimensional drawing. Borland graphics libraries CGA and VGA , it also supports third party supporting classes and also video libraries. Industries supporting or developing these kind of applications are GSN Consulting, Einfochips Limited. So will have detailed study on programming language used in industry on compiler based performances. KEYWORDS: Deep scrutiny of compilers in industry with estimating on conglomerate factors I. -

Intellitrace Debugging in a Nutshell
VisualStudioMagazine.com Program in Parallel Use PLINQ and the Task Parallel Library to take full advantage of multi-core systems. PLUS Ask Kathleen: Visual Studio 2010 Tips and Shortcuts How to Debug Applications with IntelliTrace Reviewed: Developer Express CodeRush and JetBrains ReSharper August 2010 August Volume 20, No. 8 Volume Untitled-5 2 3/5/10 10:19 AM Sure, Visual Studio 2010 has a lot of great functionality— we’re excited that it’s only making our User Interface components even better! We’re here to help you go beyond what Visual Studio 2010 gives you so you can create Killer Apps quickly, easily and without breaking a sweat! Go to infragistics.com/beyondthebox today to expand your toolbox with the fastest, best-performing and most powerful UI controls available. You’ll be surprised by your own strength! Infragistics Sales 800 231 8588 Infragistics Europe Sales +44 (0) 800 298 9055 Infragistics India +91-80-6785-1111 twitter.com/infragistics Copyright 1996-2010 Infragistics, Inc. All rights reserved. Infragistics and the Infragistics logo and NetAdvantage are registered trademarks of Infragistics, Inc. Untitled-5 3 3/5/10 10:19 AM Your best source for software development tools! ® X VMware vSphere LEADTOOLS Recognition SDK Multi-Edit NEW by LEAD Technologies by Multi Edit Software RELEASE! Put time back into your day. Develop desktop and server document imaging Multi-EditX is “The Solution” Your business depends on how you spend and ECM applications that require high-speed your time. You need to manage IT costs for your editing needs with without losing time or performance. -

2 the Direct Stiffness Method I
1 Overview 1–1 Chapter 1: OVERVIEW 1–2 TABLE OF CONTENTS Page §1.1. Where this Material Fits 1–3 §1.1.1. Computational Mechanics ............. 1–3 §1.1.2. Statics vs. Dynamics .............. 1–4 §1.1.3. Linear vs. Nonlinear ............... 1–4 §1.1.4. Discretization methods .............. 1–4 §1.1.5.FEMVariants................. 1–5 §1.2. What Does a Finite Element Look Like? 1–5 §1.3. The FEM Analysis Process 1–7 §1.3.1.ThePhysicalFEM............... 1–7 §1.3.2. The Mathematical FEM .............. 1–8 §1.3.3. Synergy of Physical and Mathematical FEM ...... 1–9 §1.4. Interpretations of the Finite Element Method 1–10 §1.4.1.PhysicalInterpretation.............. 1–11 §1.4.2. Mathematical Interpretation ............ 1–11 §1.5. Keeping the Course 1–12 §1.6. *What is Not Covered 1–12 §1.7. *Historical Sketch and Bibliography 1–13 §1.7.1. Who Invented Finite Elements? ........... 1–13 §1.7.2. G1: The Pioneers ............... 1–13 §1.7.3.G2:TheGoldenAge............... 1–14 §1.7.4. G3: Consolidation ............... 1–14 §1.7.5. G4: Back to Basics ............... 1–14 §1.7.6. Recommended Books for Linear FEM ........ 1–15 §1.7.7. Hasta la Vista, Fortran .............. 1–15 §1. References...................... 1–16 §1. Exercises ...................... 1–17 1–2 1–3 §1.1 WHERE THIS MATERIAL FITS This book is an introduction to the analysis of linear elastic structures by the Finite Element Method (FEM). This Chapter presents an overview of where the book fits, and what finite elements are. §1.1. Where this Material Fits The field of Mechanics can be subdivided into three major areas: Theoretical Mechanics Applied (1.1) Computational Theoretical mechanics deals with fundamental laws and principles of mechanics studied for their intrinsic scientific value. -

X11 Basic Manual
X11-BASIC VERSION 1.26 User Manual (C) 1997-2018 by Markus Hoffmann ([email protected]) (see http://x11-basic.sourceforge.net/) Latest revision: June 24, 2018 X11-Basic is a dialect of the BASIC programming language with graphics capa- bility that integrates features like shell scripting, cgi-programming and full graphical visualization into the easy to learn BASIC language on modern computers. The syntax is most similar to the old GFA-Basic on ATARI-ST implementation. Old GFA- programs should run with only few changes. About this document This document describes the features of X11-Basic. You will find information about the X11-Basic interpreter (the program xbasic under Unix or xbasic.exe under Windows) and the compiler (the program xbc under UNIX or xbc.exe under Win- dows) as well as the language itself. For a more compact description you may want to read the x11basic(1) man-page or the man-page of the X11-Basic compiler xbc(1). The latest information and updates and new versions of X11-Basic can be found at http://x11-basic.sourceforge.net/. 2 X11-Basic CONTENTS 1 About X11-Basic 1 2 Usage 5 2.1 InstallingX11-Basic . 5 2.2 Using the X11-Basic Interpreter . 10 2.2.1 Using the X11-Basic Interpreter under UNIX, Linux . 10 2.2.2 Using the WINDOWS Version of X11-Basic . 11 2.2.3 The Android Version of X11-Basic . 13 2.2.4 Command line parameters . 18 2.3 Editing X11-Basic programs . 19 2.4 The Bytecode Compiler and the Virtual Machine . -
Appendix a CP/M Software
Appendix A CP/M Software A major feature of the PCW8256/8512 is that it uses the CP/M operating system which means you can use a wide range of standard software products. Note that some of this software requires a second disk drive. Because new software is continually being made available for these machines it is impossible to produce a complete list. However, it is hoped that this list (compiled in Summer 1986) will demonstrate that the PCW is more than just a Word Processor! TITLE FROJ[ TYPE ABC Suite Quest Sales Invoicing Sales Ledger Stock Control Purchase Ledger Nominal Ledger A.B.C.S. Amsoft Sales/Debtors Ledger Sales Invoicing System Stock Control System Purchase/Creditors Ledger Nominal/General Ledger Amstrad Paymaster Amsoft Payroll system Analyser Quest Report generator (see Cash Trader) Assembler Plus MicroSoft Programming tool Aztec C II Manx Programming tool Back-up Xitan Copy utility BASIC Nevada Programming language BASIC Compiler MicroSoft Programming language Brainstorm Caxton Ideas processor 3-D scratchpad CBASIC Compiler Digital Research Programming language compiler 153 154 Word Processing with Amstrad C BDS Programming language compiler C HiSoft Programming language compiler CalcStar MicroPro Spreadsheet Camsoft Business Camsoft Database Software Nominal Ledger Payroll Purchase Ledger Sales Invoicing Sales Ledger Stock Control Cardbox Caxton Database Cardbox Plus Cash Trader Quest Accounting package (see Analyser) Catalog HiSoft Disk organiser Chit-Chat SageSoft Communications CIS-COBOL MicroFocus Programming language Classic Adventure Abersoft Text adventure game COBOL Microsoft Programming language Compact Accounts Compact Software Accounting packages Compact Daybook DataGem Gemini Database DataStar MicroPro Database dBaseII Ashton-Tate Database Del ta 1. -

Xbasic Guide
ALPHA SOFTWARE CORPORATION Xbasic Guide An introduction to Xbasic Examples used in this book are fictitious. Names, places, and incidents either are the products of the author’s imagination or are used fictitiously. Any resemblance to actual persons, living or dead, events, or locales is entirely coincidental. Copyright © 2020 by Sarah Mitchell and Alpha Software Corporation All rights reserved. First Published: January 13, 2020 Revised Edition: January 27, 2020 Published by Alpha Software Corporation www.alphasoftware.com Table of Contents 1 Welcome to Xbasic in Alpha Anywhere ................................................................................................ 4 1.1 Setting Up Your Workspace .......................................................................................................... 4 1.1.1 Create the Workspace........................................................................................................... 4 1.1.2 Create the Northwind Demo Connection String ................................................................... 4 1.2 The Interactive Window ................................................................................................................ 4 1.2.1 Interactive Window Commands ........................................................................................... 8 2 The Xbasic Programming Language .................................................................................................... 10 2.1 Variables & Data Types .............................................................................................................. -
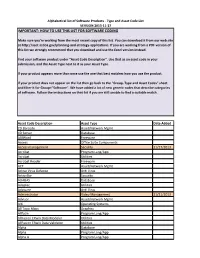
Important: How to Use This List for Software Coding
Alphabetical list of Software Products - Type and Asset Code List VERSION 2013-11-27 IMPORTANT: HOW TO USE THIS LIST FOR SOFTWARE CODING Make sure you're working from the most recent copy of this list. You can download it from our web site at http://aset.azdoa.gov/planning-and-strategy-applications. If you are working from a PDF version of this list we strongly recommend that you download and use the Excel version instead. Find your software product under "Asset Code Description". Use that as an asset code in your submission, and the Asset Type next to it as your Asset Type. If your product appears more than once use the one that best matches how you use the product. If your product does not appear on the list then go back to the "Group, Type and Asset Codes" sheet and filter it for Group="Software". We have added a lot of new generic codes that describe categories of software. Follow the instructions on that list if you are still unable to find a suitable match. Asset Code Description Asset Type Date Added 2D Barcode Asset/Network Mgmt 4D Server Database ABIWord Freeware Access Office Suite Components Access management Security 11/27/2013 Acrobat Program Lang/App Acrobat Utilities Acrobat Reader Freeware ACT Asset/Network Mgmt Active Virus Defense Anti Virus ActiveBar Security ADABAS Database Adaptec Utilities Adaware Anti Virus Administrator Video Management 11/21/2013 Advisor Asset/Network Mgmt AIX Operating Systems All Topo Maps Graphics Allfusin Program Lang/App AllFusion ERwin Data Modeler Utilities AllFusion ERwin Data Validator -

Formatting Syntax Formatting Syntax
26/09/2021 20:06 1/15 Formatting Syntax Formatting Syntax DokuWiki supports some simple markup language, which tries to make the datafiles to be as readable as possible. This page contains all possible syntax you may use when editing the pages. Simply have a look at the source of this page by pressing "Edit this page". If you want to try something, just use the playground page. The simpler markup is easily accessible via quickbuttons, too. Basic Text Formatting DokuWiki supports bold, italic, underlined and monospaced texts. Of course you can combine all these. DokuWiki supports **bold**, //italic//, __underlined__ and ''monospaced'' texts. Of course you can **__//''combine''//__** all these. superscript You can use subscript and , too. You can use <sub>subscript</sub> and <sup>superscript</sup>, too. You can mark something as deleted as well. You can mark something as <del>deleted</del> as well. Paragraphs are created from blank lines. If you want to force a newline without a paragraph, you can use two backslashes followed by a whitespace or the end of line. This is some text with some linebreaks Note that the two backslashes are only recognized at the end of a line or followed by a whitespace \\this happens without it. This is some text with some linebreaks\\ Note that the two backslashes are only recognized at the end of a line\\ or followed by\\ a whitespace \\this happens without it. You should use forced newlines only if really needed. Links DokuWiki supports multiple ways of creating links. JCL - https://web.fe.up.pt/~jlopes/ Last update: 29/07/2020 10:35 wiki:syntax https://web.fe.up.pt/~jlopes/doku.php/wiki/syntax External External links are recognized automagically: http://www.google.com or simply www.google.com - You can set the link text as well: This Link points to google.