Building 360-Degree Information Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

University of Iowa Instruments in Space
University of Iowa Instruments in Space A-D13-089-5 Wind Van Allen Probes Cluster Mercury Earth Venus Mars Express HaloSat MMS Geotail Mars Voyager 2 Neptune Uranus Juno Pluto Jupiter Saturn Voyager 1 Spaceflight instruments designed and built at the University of Iowa in the Department of Physics & Astronomy (1958-2019) Explorer 1 1958 Feb. 1 OGO 4 1967 July 28 Juno * 2011 Aug. 5 Launch Date Launch Date Launch Date Spacecraft Spacecraft Spacecraft Explorer 3 (U1T9)58 Mar. 26 Injun 5 1(U9T68) Aug. 8 (UT) ExpEloxrpelro r1e r 4 1915985 8F eJbu.l y1 26 OEGxOpl o4rer 41 (IMP-5) 19697 Juunlye 2 281 Juno * 2011 Aug. 5 Explorer 2 (launch failure) 1958 Mar. 5 OGO 5 1968 Mar. 4 Van Allen Probe A * 2012 Aug. 30 ExpPloiorenre 3er 1 1915985 8M Oarc. t2. 611 InEjuxnp lo5rer 45 (SSS) 197618 NAouvg.. 186 Van Allen Probe B * 2012 Aug. 30 ExpPloiorenre 4er 2 1915985 8Ju Nlyo 2v.6 8 EUxpKlo 4r e(rA 4ri1el -(4IM) P-5) 197619 DJuenc.e 1 211 Magnetospheric Multiscale Mission / 1 * 2015 Mar. 12 ExpPloiorenre 5e r 3 (launch failure) 1915985 8A uDge.c 2. 46 EPxpiolonreeerr 4130 (IMP- 6) 19721 Maarr.. 313 HMEaRgCnIe CtousbpeShaetr i(cF oMxu-1ltDis scaatelell itMe)i ssion / 2 * 2021081 J5a nM. a1r2. 12 PionPeioenr e1er 4 1915985 9O cMt.a 1r.1 3 EExpxlpolorerer r4 457 ( S(IMSSP)-7) 19721 SNeopvt.. 1263 HMaalogSnaett oCsupbhee Sriact eMlluitlet i*scale Mission / 3 * 2021081 M5a My a2r1. 12 Pioneer 2 1958 Nov. 8 UK 4 (Ariel-4) 1971 Dec. 11 Magnetospheric Multiscale Mission / 4 * 2015 Mar. -

Fiscal Year 1973, and Are the EROS Program Also Supports the ERTS Data Proiected at Almost $1 Million for Fiscal Year 1974
Aeronautics and Space Report of the President r973 Activities NOTE TO READERS: ALL PRINTED PAGES ARE INCLUDED, UNNUMBERED BLANK PAGES DURING SCANNING AND QUALITY CONTROL CHECK HAVE BEEN DELETED Aeronautics and Space Report of the President 1973 A c tivities National Aeronautics and Space Administration Washington, D.C. 20546 President’s Message of Transmittal To the Congress of the United States: the European Space Conference has agreed to con- struct a space laboratory-Spacelab-for use with the I am pleased to transmit this report on our Nation’s Shuttle. progress in aeronautics and space activities during Notable progress has also been made with the Soviet 1973. Union in preparing the Apollo-Soyuz Test Project This year has been particularly significant in that scheduled for 1975. We are continuing to cooperate many past efforts to apply the benefits of space tech- with other nations in space activities and sharing of nology and information to the solution of problems on scientific information. These efforts contribute to global Earth are now coming to fruition. Experimental data peace and prosperity. from the manned Skylab station and the unmanned While we stress the use of current technology to solve Earth Resources Technology Satellite are already being current problems, we are employing unmanned space- used operationally for resource discovery and manage- craft to stimulate further advances in technology and ment, environmental information, land use planning, to obtain knowledge that can aid us in solving future and other applications. problems. Pioneer 10 gave us our first closeup glimpse Communications satellites have become one of the of Jupiter and transmitted data which will enhance principal methods of international communication our knowledge of Jupiter, the solar system, and ulti- and are an important factor in meeting national de- mately our own planet. -

Go Los Angeles Explorer Pass - Los Angeles, CA for Up-To-Date Information on Available Attractions, Please Check Out: Gocity.Com/Los-Angeles/En-Us/EXP-Guide
Leisure Pass Group - Go Los Angeles Explorer Pass - Los Angeles, CA For up-to-date information on available attractions, please check out: gocity.com/los-angeles/en-us/EXP-Guide Explore LA’s top attractions and get up to 60% off admission with the Go Los Angeles Explorer Pass. Choose 3, 4, 5 or 7 activities from a list of over 30 attractions and tours. Go behind the scenes at Warner Bros. Studios, hop on and off a Big Bus tour, take a selfie with your favorite celebrity at Madame Tussauds Hollywood, or ride thrilling roller coasters at Six Flags Magic Mountain. Browse the free guidebook to plan your itinerary as you go. Your pass is fully digital and valid for 30 days from first attraction visit. Free admission to ALL of these attractions! Big Bus LA 1-Day Classic Ticket Perry’s Beach Café and Rentals – Mountain Warner Bros. Studio Tour (R) Bike OR Roller Skates (All Day) Madame Tussauds Hollywood The Huntington Library, Art Collection & Aquarium of the Pacific* Botanical Gardens Night Star Tour K1 Speed Indoor Karting plus membership Hollywood Behind-the-Scenes Tour by Red Los Angeles Zoo Line Tours (R) California Science Center IMAX Movie Harbor Cruise in Long Beach iFly Hollywood (1 Flight Package) (R) TCL Chinese Theatre Tour or Movie and a Shanti Hot Yoga drink Big Bus Celebrity Lifestyle & Homes Tour The Hollywood Movie Experience by Red Line Bucca di Beppo – Farmer’s Market $15 dining Tours (R) credit Harbor Cruise in San Pedro Seaside – Santa Monica Pier $15 dining credit Hollywood Hills Hike by Bikes & Hikes LA Dave & Busters Play & Dine Package Natural History Museum of LA LA Galaxy Game Ticket La Brea Tar Pits and Museum Celebrity Bike Tour (Self-Guided) by Bikes & Whale Watch in Long Beach Hikes LA Whale Watch in San Pedro Food, Arts, Culture DTLA Walking Tour GRAMMY Museum (R) – Reservations required Battleship IOWA Museum – Express Entry *These attractions are AFCTP partners and may be a better value independent of the Smart Destination website. -

2011–2012 Catalog Ii Capitol College 2011-2012 Catalog
2011–2012 catalog ii Capitol College 2011-2012 Catalog General Information General Information . 1 Locations . 4 Mission and Philosophy . 4 History . 6 Centers of Excellence . 7 Affiliations, Memberships and Partnerships . 8 Online Learning . 10 Academic Policies Academic Policies and Procedures . 11 Scholastic Standing . 13 Academic Performance . 15 Matriculation . 16 Transfer Credits . 18 Tuition/Financial Aid Tuition and Fees . 21 Payment Options . 22 Financial Aid . 24 Undergraduate Studies Undergraduate Program Offerings . 30 Undergraduate Admissions . 30 Astronautical Engineering . 35 Business Administration . 36 Computer Engineering . 37 Computer Engineering Technology . 38 Computer Science . 40 Electrical Engineering . 41 Electronics Engineering Technology . 42 Information Assurance . 44 Management of Information Technology . 45 Software Engineering . 46 Software and Internet Applications . 47 Telecommunications Engineering Technology . 48 Certificates . 50 Graduate Studies Graduate Program Offerings . 53 Doctorate Admissions . 53 Master’s Admissions . 54 Information Assurance (DSc) . 56 Business Administration (MBA) . 57 2011-2012 Catalog iii Astronautical Engineering . 58 Computer Science . 59 Electrical Engineering . 60 Information Assurance (MS) . 61 Information and Telecommunications Systems Management . 62 Internet Engineering . 63 Post-baccalaureate Certificates . 64 Non Credit Course and Certificate Offerings . 66 Courses Course Descriptions . 67 Resources Board of Trustees . 100 Advisory Boards . 101 Administration . 103 Faculty . 106 Calendar . 110 Index . 122 Map and Directions . 124 iv Capitol College The following offices are open as General Information indicated (EST) . Directory Admissions M, F 9 a.m.- 5 p.m. Capitol College T-Th 9 a .m .- 7 p .m . 11301 Springfield Road Saturday appointments are available. Laurel, MD 20708-9758 Business Office Main Telephone Numbers M, F 9 a.m.- 5 p.m. Information General 301-369-2800 T-Th 9 a .m .- 7 p .m . -

2010–2011 Catalog
2010–2011 catalog 2010-2011 Catalog General Information General Information . 1 Locations . 4 Mission and Philosophy . 4 History . 6 Partnerships . 7 Online Learning . 10 Academic Policies Academic Policies and Procedures . 11 Scholastic Standing . 13 Academic Performance . 15 Matriculation . 16 Transfer Credits . 18 Tuition/Financial Aid Tuition and Fees . 21 Financial Aid . 24 Undergraduate Studies Undergraduate Program Offerings . 30 Undergraduate Admissions . 30 Astronautical Engineering . 35 Business Administration . 36 Computer Engineering . 37 Computer Engineering Technology . 38 Computer Science . 40 Electrical Engineering . 41 Electronics Engineering Technology . 42 Information Assurance . 44 Management of Information Technology . 45 Software Engineering . 46 Software and Internet Applications . 47 Telecommunications Engineering Technology . 48 Certificates . 50 Non-degree Certification Programs . 53 Graduate Studies Graduate Program Offerings . 54 Graduate Admissions . 54 Information Assurance (DSc) . 56 Business Administration . 57 Computer Science . 58 Electrical Engineering . 59 2010-2011 Catalog iii Information Assurance (MS) . 60 Information and Telecommunications Systems Management . 61 Internet Engineering . 62 Post-baccalaureate Certificates . 63 Courses Course Descriptions . 65 Resources Board of Trustees . 100 Advisory Boards . 101 Administration . 103 Faculty . 106 Calendar . 110 Index . 122 Map and Directions . 124 iv Capitol College The following offices are open as General Information indicated (EST) . Directory Admissions M, F 9 a .m .- 5 p .m . Capitol College T-Th 9 a .m .- 7 p .m . 11301 Springfield Road Saturday appointments are available . Laurel, MD 20708-9758 Business Office Main Telephone Numbers M, F 9 a .m .- 5 p .m . General Information 301-369-2800 T-Th 9 a .m .- 7 p .m . 888-522-7486 Financial Aid Admissions M, F 9 a .m .-5 p .m . -

254 — 13 February 2014 Editor: Bo Reipurth ([email protected]) List of Contents
THE STAR FORMATION NEWSLETTER An electronic publication dedicated to early stellar/planetary evolution and molecular clouds No. 254 — 13 February 2014 Editor: Bo Reipurth ([email protected]) List of Contents The Star Formation Newsletter Interview ...................................... 3 My Favorite Object ............................ 5 Editor: Bo Reipurth [email protected] Perspective ................................... 10 Technical Editor: Eli Bressert Abstracts of Newly Accepted Papers .......... 13 [email protected] Abstracts of Newly Accepted Major Reviews . 54 Technical Assistant: Hsi-Wei Yen Dissertation Abstracts ........................ 60 [email protected] New Jobs ..................................... 61 Editorial Board Meetings ..................................... 63 Summary of Upcoming Meetings ............. 66 Joao Alves Alan Boss Short Announcements ........................ 67 Jerome Bouvier New Books ................................... 68 Lee Hartmann Thomas Henning Paul Ho Jes Jorgensen Charles J. Lada Cover Picture Thijs Kouwenhoven Michael R. Meyer This image shows the blueshifted outflow cav- Ralph Pudritz ity from the embedded quadruple Class I source Luis Felipe Rodr´ıguez L1551 IRS5 based on Hα and [SII] images obtained Ewine van Dishoeck with the Subaru telescope images. Two short jets, Hans Zinnecker HH 154, are seen to emerge from the source region to the upper left. The outflow cavity has burst The Star Formation Newsletter is a vehicle for through the front of the cloud, exposing the rich fast distribution of information of interest for as- and complex Herbig-Haro shock structures within. tronomers working on star and planet formation A few faint knots from the HH 30 jet (outside the and molecular clouds. You can submit material field) are visible at the top of the image. The for the following sections: Abstracts of recently field is about 7×8 arcmin, corresponding to about accepted papers (only for papers sent to refereed 0.30×0.35 pc at the assumed distance of 150 pc. -
Arxiv:2003.09066V1 [Astro-Ph.HE] 20 Mar 2020
DRAFT VERSION MARCH 23, 2020 Typeset using LATEX twocolumn style in AASTeX62 Multiwavelength Study of an X-ray Tidal Disruption Event Candidate in NGC 5092 DONGYUE LI,1, 2 R.D. SAXTON,3 WEIMIN YUAN,1, 2 LUMING SUN,4, 5 HE-YANG LIU,1, 2 NING JIANG,6, 5 HUAQING CHENG,1, 2 HONGYAN ZHOU,7, 5, 6 S. KOMOSSA,8, 9 AND CHICHUAN JIN1, 2 1Key Laboratory of Space Astronomy and Technology, National Astronomical Observatories, Chinese Academy of Sciences, 20A Datun Road, Chaoyang District, Beijing, 100101, China 2School of Astronomy and Space Science, University of Chinese Academy of Sciences, 19A Yuquan Road, Beijing, 100049, China 3Telespazio-Vega UK for ESA, Euporean Space Astronomy Centre, Operations Department, E-28691 Villanueva de la Can~ada, Spain 4Key Laboratory for Research in Galaxies and Cosmology, Department of Astronomy, The University of Science and Technology of China, Hefei, Anhui, 230026, China 5School of Astronomy and Space Sciences, University of Science and Technology of China, Hefei, Anhui, 230026, China 6Key laboratory for Research in Galaxies and Cosmology, Department of Astronomy, The University of Science and Technology of China, Hefei, Anhui, 230026, China 7Antarctic Astronomy Research Division, Key Laboratory for Polar Science of the State Oceanic Administration, Polar Research Institute of China, 451 Jinqiao Road, Shanghai, 20136, China 8Max Planck Institut fur¨ Radioastronomie, Auf dem Hugel¨ 69, D-53121 Bonn, Germany 9Key Laboratory of Space Science Astronomy and Technology, National Astronomical Observatories, Chinese Academy of Sciences, 20A Datun Road, Chaoyang District, Beijing, 100101, China ABSTRACT We present multiwavelength studies of a transient X-ray source, XMMSL1 J131952.3+225958, associated with the galaxy NGC 5092 at z = 0:023 detected in the XMM-Newton SLew survey (XMMSL). -

PHC Online Services Browser Support
PHC Online Services Browser Support This document lists browsers that are compatible and fully supported for use with the Partnership HealthPlan Applications. This list applies to web browsers that are used on desktop versions. Please refer to the list below to determine which web browsers are compatible and not compatible with different Partnership HealthPlan Applications. Online Services Version Information List of browsers that support Online services are as follows: . Internet Explorer 5 . Internet Explorer 6 . Internet Explorer 7 . Internet Explorer 8 . Internet Explorer 9 . Google Chrome – Online services work in Google Chrome but are not fully supported. Microsoft Microsoft Microsoft Microsoft Microsoft Microsoft Google Mozilla Safari for Opera Internet Internet Internet Internet Internet Internet Chrome Firefox Macintos Explorer Explorer Explorer Explorer Explorer Explorer h 5 6 7 8 9 10 Yes Yes Yes Yes Yes No No No No No All content of Online Services MUST be readable and usable and all functionality MUST work on recommended browsers. PARx (Pharmacy Prior Authorization System) Version Information List of browsers that support PAR x (Pharmacy Prior Authorization System) are as follows: . Internet Explorer 5 . Internet Explorer 6 . Internet Explorer 7 . Internet Explorer 8 . Internet Explorer 9 . Internet Explorer 10 . Google Chrome Microsoft Microsoft Microsoft Microsoft Microsoft Microsoft Google Mozilla Safari for Opera Internet Internet Internet Internet Internet Internet Chrome Firefox Macintos Explorer Explorer Explorer Explorer Explorer Explorer h 5 6 7 8 9 10 Yes Yes Yes Yes Yes Yes Yes No No No All content of PARx (Pharmacy Prior Authorization System) MUST be readable and usable and all functionality MUST work on recommended browsers. -

Stromatolite Explorer Microbial Mat Marine Ecology: Microbial
MICROSCOPIC MONSTERS: Episode XIII, Stromatolite Explorer 1 Accompanies Episode 13 of the 13-part video series Stromatolite Explorer Written by Eric R Russell diatoms cyanobacteria oxygen-rich levels Marine Ecology: Microbial Mat thickness 5 millimeters The Log of Captain Alda Adler purple sulfur bacteria Microbial Mat cross-section Day 1: 09:00 hours... My first mission! My first log entry... Grandpa Jon would know exactly what to say. He would know the perfect words... something inspiring and coura- geous. But, my crew and I are diving into a microcosm that he didn’t even dream of exploring – the extreme environ- ment of a shallow salty sea. Our mission is to survey and discover the chemical condi- tions to a depth of 5 millimeters – of a living microbial mat. We want to learn as much as possible about this extreme oxygen-poor levels Earth micro habitat. Exobiologists believe that this is the kind of harsh environment where life on other planets might sulfate reducing bacteria sulfate reducing be found. What we find here is the kind of life that human explorers to other planets will most likely encounter. The mat’s spiky surface is caused by filaments ofoxygen- producing bacteria pushing upward from below, creating a mountainous landscape. Our vessel, Stromatolite Explorer, will enter a microbial mat through a fissure on the surface. We intend to follow gaps and pockets in the living mat until we reach our destination. MICROSCOPIC MONSTERS: Episode XIII, Stromatolite Explorer 2 Stromatolite Explorer Extreme Micro Enviro Reconnaisance Vehicle Dimensions LENGTH .1 mm Top view BEAM .08 mm Vehicle Mission electric propulsion Maximum speed 1.5 mm per minute Mission duration 2 days rudder assembly grabber claws The Stromatolite Explorer is a sub-microscopic exploration vehicle designed to withstand the extreme conditions of Earth’s harshest environ- cockpit ments. -
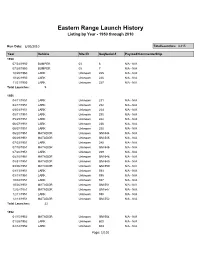
Eastern Range Launch History Listing by Year - 1950 Through 2010
Eastern Range Launch History Listing by Year - 1950 through 2010 Run Date: 6/30/2010 Total Launches: 3,415 Year Vehicle Site ID SeqSerial # Payload/Comments/Ship 1950 07/24/1950 BUMPER 03 8 N/A - N/A 07/29/1950 BUMPER 03 7 N/A - N/A 10/25/1950 LARK Unknown 225 N/A - N/A 10/26/1950 LARK Unknown 226 N/A - N/A 11/21/1950 LARK Unknown 227 N/A - N/A Total Launches: 5 1951 04/11/1951 LARK Unknown 231 N/A - N/A 04/17/1951 LARK Unknown 232 N/A - N/A 05/03/1951 LARK Unknown 234 N/A - N/A 05/11/1951 LARK Unknown 235 N/A - N/A 05/29/1951 LARK Unknown 242 N/A - N/A 06/07/1951 LARK Unknown 236 N/A - N/A 06/07/1951 LARK Unknown 238 N/A - N/A 06/20/1951 MATADOR Unknown GM-544 N/A - N/A 06/29/1951 MATADOR Unknown GM-545 N/A - N/A 07/03/1951 LARK Unknown 240 N/A - N/A 07/18/1951 MATADOR Unknown GM-546 N/A - N/A 07/20/1951 LARK Unknown 239 N/A - N/A 08/10/1951 MATADOR Unknown GM-548 N/A - N/A 08/31/1951 MATADOR Unknown GM-549 N/A - N/A 09/06/1951 MATADOR Unknown GM-550 N/A - N/A 09/13/1951 LARK Unknown 593 N/A - N/A 09/19/1951 LARK Unknown 595 N/A - N/A 10/04/1951 LARK Unknown 597 N/A - N/A 10/26/1951 MATADOR Unknown GM-551 N/A - N/A 12/07/1951 MATADOR Unknown GM-547 N/A - N/A 12/11/1951 LARK Unknown 598 N/A - N/A 12/13/1951 MATADOR Unknown GM-552 N/A - N/A Total Launches: 22 1952 01/15/1952 MATADOR Unknown GM-554 N/A - N/A 01/28/1952 LARK Unknown 600 N/A - N/A 02/12/1952 LARK Unknown 604 N/A - N/A Page: 1/101 Eastern Range Launch History Listing by Year - 1950 through 2010 Run Date: 6/30/2010 Total Launches: 3,415 Year Vehicle Site ID SeqSerial # Payload/Comments/Ship -

Final Design Report UV Imager Application for a Cube Satellite
Final Design Report UV Imager Application for a Cube Satellite Sponsor: UC Berkeley - Space Sciences Laboratory 2018 Senior Project Team: Jason Grillo - [email protected] Troy Hajjar - [email protected] Brady Hill - [email protected] Project Advisors: Eltahry Elghandour – Cal Poly Thomas Immel – UCBSSL Kodi Rider - UCBSSL Table of Contents Table of Contents ....................................................................................................................... 2 List of Figures ............................................................................................................................ 4 List of Tables.............................................................................................................................. 7 Abstract ...................................................................................................................................... 8 Chapter 1: Introduction .............................................................................................................. 9 Chapter 2: Background ............................................................................................................ 10 Chapter 3: Scope of the Senior Project .................................................................................... 16 3.1 Primary Focus ................................................................................................................ 16 3.2 Secondary Focus ........................................................................................................... -

NASA Pocket Statistics R~> —' 7~-* January 1983 Fttf (NASA-TM-105080) NASA POCKET STATISTICS N91-71755 (NASA) 67 P
https://ntrs.nasa.gov/search.jsp?R=19910074200 2020-03-17T14:52:35+00:00Z NASA Pocket Statistics r~> — ' 7~-* January 1983 fttf (NASA-TM-105080) NASA POCKET STATISTICS N91-71755 (NASA) 67 p U/iclas Z9/82 0033702 Distribution For NASA Reid Installations Following is a list of individuals who control the distribution of Pocket Statistics at their respective NASA Field Installations. All requests must be forwarded by memo through the controlling office as shown below. Ames Research Center Johnson Space Center Marshall Space Flight Center Mr. Paul Loschke, Staff Assistant Mr. N. S. Jakir Mr. R. G. Sheppard AS01 to the Assoc. Director Chief, Code JM-8 Management Operations Office Printing Management Branch Dryden Flight Research Center NASA/STDN Goldstone Station Magd^lina Ramirez' Kennedy Space Center & KSC/WIOD Mr. William E. Edeline Management Support Mr. M. Konjevich P.O. Box 789 Administrative Services Branch Barstow, CA 92311 Goddard Space Flight Center Ms. B. Sidwell tangley Research Center Wallops Flight Center Director of Administration, Ms. Agnes Lindler Mr. F. Moore and Management Mail Stop 115 Director of Administration Jet Propulsion Laboratory Lewis Research Center NSTL Mr. JohnW. Kemptpn. Mqr. Mr. James Burnett Mr. I. J. Hlass, Manager Documentation Section Director, Tech. Utilization & Public Affairs JPL Resident Office Mr. F. Bowen, Manager Pocket Statistics is published annually for the use of NASA managers and their immediate staffs. Included is a summary of the NASA Program goals and objectives, major mission performance, USSR spaceflights, summary comparisons of the USA and USSR space records, and selected technical, financial, and manpower data.