Memory Hierarchy and Caches
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Design of a Drum Memory System
Scholars' Mine Masters Theses Student Theses and Dissertations 1967 The design of a drum memory system Frederick W. Lynch Follow this and additional works at: https://scholarsmine.mst.edu/masters_theses Part of the Electrical and Computer Engineering Commons Department: Recommended Citation Lynch, Frederick W., "The design of a drum memory system" (1967). Masters Theses. 5163. https://scholarsmine.mst.edu/masters_theses/5163 This thesis is brought to you by Scholars' Mine, a service of the Missouri S&T Library and Learning Resources. This work is protected by U. S. Copyright Law. Unauthorized use including reproduction for redistribution requires the permission of the copyright holder. For more information, please contact [email protected]. THE DESIGN OF A DRUM MEMORY SYSTEM BY FREDERICK W. LYNCH A l'HESIS 129533 submitted to the faculty of the UNIVERSITY OF MISSOURI AT ROLLA in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE IN ELECTRICAL ENGINEERING Rolla, Missouri I"",,--;;'d I ~ 1967 rfJ·.dfl c, I ii ABSTRACT Three methods for obtaining an auxiliary memory for an SeC-6S0 (Scientific Control Corporation) digital computer are presented. A logic design is then developed on the basis of using the drum and write circuits from an available IBM-6S0 digital computer and con structing the remaining logic functions. The results of the logic design are the transfer equations necessary to implement the memory system. iii ACKNOWLEDGMENT The author wishes to express his sincere appreciation to his major professor, Dr. James Tracey, for guidance and support in the preparation of this thesis. iv TABLE OF CONTENTS Page ABSTRACT ii ACKNm>JLEDGlVIENT iii LIST OF FIGURES v LIST OF TABLES vi I. -

DRAM EMAIL GIM Teams!!!/Teaming Issues •Memories in Verilog •Memories on the FPGA
Memories & More •Overview of Memories •External Memories •SRAM (async, sync) •Flash •DRAM EMAIL GIM teams!!!/teaming Issues •Memories in Verilog •Memories on the FPGA 10/18/18 6.111 Fall 2018 1 Memories: a practical primer • The good news: huge selection of technologies • Small & faster vs. large & slower • Every year capacities go up and prices go down • Almost cost competitive with hard disks: high density, fast flash memories • Non-volatile, read/write, no moving parts! (robust, efficient) • The bad news: perennial system bottleneck • Latencies (access time) haven’t kept pace with cycle times • Separate technology from logic, so must communicate between silicon, so physical limitations (# of pins, R’s and C’s and L’s) limit bandwidths • New hopes: capacitive interconnect, 3D IC’s • Likely the limiting factor in cost & performance of many digital systems: designers spend a lot of time figuring out how to keep memories running at peak bandwidth • “It’s the memory - just add more faster memory” 10/18/18 6.111 Fall 2018 2 How do we Electrically Remember Things? • We can convey/transfer information with voltages that change over time • How can we store information in an electrically accessible manner? • Store in either: • Electric Field • Magnetic Field 10/18/18 6.111 Fall 2018 3 Mostly focus on rewritable • Punched Cards have existed as electromechanical program storage since ~1800s • We’re mostly concerned with rewritable storage mechanisms today (cards were true Computer program in punched card format ROMs) https://en.wiKipedia.org/wiKi/Computer_programming_in_the_ -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

Magnetic Storage- Magnetic-Core Memory, Magnetic Tape,RAM
Magnetic storage- From magnetic tape to HDD Juhász Levente 2016.02.24 Table of contents 1. Introduction 2. Magnetic tape 3. Magnetic-core memory 4. Bubble memory 5. Hard disk drive 6. Applications, future prospects 7. References 1. Magnetic storage - introduction Magnetic storage: Recording & storage of data on a magnetised medium A form of „non-volatile” memory Data accessed using read/write heads Widely used for computer data storage, audio and video applications, magnetic stripe cards etc. 1. Magnetic storage - introduction 2. Magnetic tape 1928 Germany: Magnetic tape for audio recording by Fritz Pfleumer • Fe2O3 coating on paper stripes, further developed by AEG & BASF 1951: UNIVAC- first use of magnetic tape for data storage • 12,7 mm Ni-plated brass-phosphorus alloy tape • 128 characters /inch data density • 7000 ch. /s writing speed 2. Magnetic tape 2. Magnetic tape 1950s: IBM : patented magnetic tape technology • 12,7 mm wide magnetic tape on a 26,7 cm reel • 370-730 m long tapes 1980: 1100 m PET –based tape • 18 cm reel for developers • 7, 9 stripe tapes (8 bit + parity) • Capacity up to 140 MB DEC –tapes for personal use 2. Magnetic tape 2014: Sony & IBM recorded 148 Gbit /squareinch tape capacity 185 TB! 2. Magnetic tape Remanent structural change in a magnetic medium Analog or digital recording (binary storage) Longitudinal or perpendicular recording Ni-Fe –alloy core in tape head 2. Magnetic tape Hysteresis in magnetic recording 40-150 kHz bias signal applied to the tape to remove its „magnetic history” and „stir” the magnetization Each recorded signal will encounter the same magnetic condition Current in tape head proportional to the signal to be recorded 2. -
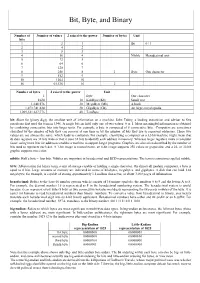
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

Influence of U.S. Cryptologic Organizations on the Digital Computer Industry
UNCLASSIFIED Influence of U.S. Cryptologic Organizations on the Digital Computer Industry SAMUELS. SNYDER This article was originally published in two parts in the Fall 1977 and Winter 1978 issues o{Cryptologic Spectrum (Vol. 7, No. 4 and Vol. 8, No. 2). INTRODUCTION An unfortunate aspect of historical accounts of computer lore in open sources is the omission - conspicuously to some of us - of mention of the U.S. cryptologic organizations, or of the contributions by these organizations which helped in laying the foundation of the computer industry. NSA, and other cryptologic organizations, have been required over the years to observe a policy of anonymity, and with good reason. But in the age of maturing appreciation of the role of computers in nearly all civilized endeavors, it is time to acknowledge, for the first time, their outstanding contributions to the computer industry. The reader will notice the absence of remarks concerning software efforts by cryptologic organizations. While this side of their operations received its proper share of support, space restrictions preclude its inclusion in this article. Also, the Army and Navy cryptologic services have frequently changed organizational titles throughout the years. Therefore, to avoid confusion in this article, they are, previous to 1945, referred to as "Army," "Navy," "service cryptologic organizations," and the like. Too, NSA's predecessor organization, AFSA, was established in 1949, and NSA in 1952. Consequently, references to "NSA" and "Agency" are, on occasion, used interchangeably, the particular agency referred to depending upon the time period being discussed. EARLY DEVELOPMENTS The development of the U.S. computer industry might have been delayed for years ifit had not been for the stimulus and financial support of the U.S. -

Computer Peripheral Memory System Forecast
OF NBS H^^LK,!,, STAND S. TECH PUBLICATIONS | COMPUTER SUici^CZ^i TECHNOLOGY: COMPUTER PERIPHERAL MEMORY SYSTEM FORECAST QC 100 U57 NBS Special Publication 500-45 #500-45 U.S. DEPARTMENT OF COMMERCE 1979 National Bureau of Standards NATIONAL BUREAU OF STANDARDS The National Bureau of Standards' was established by an act of Congress March 3, 1901 . The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to promote public safety. The Bureau's technical work is performed by the National Measurement Laboratory, the National Engineering Laboratory, and the Institute for Computer Sciences and Technology. THE NATIONAL MEASUREMENT LABORATORY provides the national system of physical and chemical and materials measurement; coordinates the system with measurement systems of other nations and furnishes essential services leading to accurate and uniform physical and chemical measurement throughout the Nation's scientific community, industry, and commerce; conducts materials research leading to improved methods of measurement, standards, and data on the properties of materials needed by industry, commerce, educational institutions, and Government; provides advisory and research services to other Government Agencies; develops, produces, and distributes Standard Reference Materials; and provides calibration services. The Laboratory consists of the following centers: Absolute Physical Quantities^ — Radiation Research — Thermodynamics and Molecular Science — Analytical Chemistry — Materials Science. -

1 Configuring SATA Controllers A
RAID Levels RAID 0 RAID 1 RAID 5 RAID 10 Minimum Number of Hard ≥2 2 ≥3 ≥4 Drives Array Capacity Number of hard Size of the smallest (Number of hard (Number of hard drives * Size of the drive drives -1) * Size of drives/2) * Size of the smallest drive the smallest drive smallest drive Fault Tolerance No Yes Yes Yes To create a RAID set, follow the steps below: A. Install SATA hard drive(s) in your computer. B. Configure SATA controller mode in BIOS Setup. C. Configure a RAID array in RAID BIOS. (Note 1) D. Install the SATA RAID/AHCI driver and operating system. Before you begin, please prepare the following items: • At least two SATA hard drives or M.2 SSDs (Note 2) (to ensure optimal performance, it is recommended that you use two hard drives with identical model and capacity). (Note 3) • A Windows setup disk. • Motherboard driver disk. • A USB thumb drive. 1 Configuring SATA Controllers A. Installing hard drives Connect the SATA signal cables to SATA hard drives and the Intel® Chipset controlled SATA ports (SATA3 0~5) on the motherboard. Then connect the power connectors from your power supply to the hard drives. Or install your M.2 SSD(s) in the M.2 connector(s) on the motherboard. (Note 1) Skip this step if you do not want to create RAID array on the SATA controller. (Note 2) An M.2 PCIe SSD cannot be used to set up a RAID set either with an M.2 SATA SSD or a SATA hard drive. -

Memory Krste Asanovic [email protected]
CS252 Graduate Computer Architecture Fall 2015 Lecture 11: Memory Krste Asanovic [email protected] http://inst.eecs.berkeley.edu/~cs252/fa15 CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 Last Time in Lecture 10 VLIW Machines § Compiler-controlled stac scheduling § Loop unrolling § SoEware pipelining § Trace scheduling § Rotang register file § Predicaon § Limits of stac scheduling CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 2 Early Read-Only Memory Technologies Punched cards, From early 1700s through Jaquard Loom, Punched paper tape, Babbage, and then IBM instrucCon stream in Harvard Mk 1 Diode Matrix, EDSAC-2 µcode store IBM Balanced Capacitor ROS IBM Card Capacitor ROS CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 3 Early Read/Write Main Memory Technologies Babbage, 1800s: Digits stored on mechanical wheels Williams Tube, Manchester Mark 1, 1947 Mercury Delay Line, Univac 1, 1951 Also, regenerave capacitor memory on Atanasoff-Berry computer, and rotang magneCc drum memory on IBM 650 CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 4 MIT Whirlwind Core Memory CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 5 Core Memory § Core memory was first large scale reliable main memory - invented by Forrester in late 40s/early 50s at MIT for Whirlwind project § Bits stored as magneCzaon polarity on small ferrite cores threaded onto two-dimensional grid of wires § Coincident current pulses on X and Y wires would write cell and also sense original state (destrucCve reads) § Robust, non-volale storage § Used on space shugle computers § Cores threaded onto wires by hand (25 billion a year at peak producCon) § Core access Cme ~ 1µs DEC PDP-8/E Board, 4K words x 12 bits, (1968) CS252, Fall 2015, Lecture 11 © Krste Asanovic, 2015 6 Semiconductor Memory § Semiconductor memory began to be compeCCve in early 1970s - Intel formed to exploit market for semiconductor memory - Early semiconductor memory was Stac RAM (SRAM). -

Lecture 8: Main Memory System
18-740/640 Computer Architecture Lecture 8: Main Memory System Prof. Onur Mutlu Carnegie Mellon University Fall 2015, 9/28/2015 Required Readings Required Reading Assignment: • Sec. 1 & 3 of B. Jacob, “The Memory System: You Can’t Avoid It, You Can’t Ignore It, You Can’t Fake It,” Synthesis Lectures on Computer Architecture, 2009. Recommended References: • O. Mutlu and L. Subramanian, “Research Problems and Opportunities in Memory Systems,” Supercomputing Frontiers and Innovations, 2015. • Lee et al., “Phase Change Technology and the Future of Main Memory,” IEEE Micro, Jan/Feb 2010. • Y. Kim, W. Yang, O. Mutlu, “Ramulator: A Fast and Extensible DRAM Simulator,” IEEE Computer Architecture Letters, May 2015. 2 State-of-the-art in Main Memory… Onur Mutlu and Lavanya Subramanian, "Research Problems and Opportunities in Memory Systems" Invited Article in Supercomputing Frontiers and Innovations (SUPERFRI), 2015. 3 Recommended Readings on DRAM DRAM Organization and Operation Basics Sections 1 and 2 of: Lee et al., “Tiered-Latency DRAM: A Low Latency and Low Cost DRAM Architecture,” HPCA 2013. http://users.ece.cmu.edu/~omutlu/pub/tldram_hpca13.pdf Sections 1 and 2 of Kim et al., “A Case for Subarray-Level Parallelism (SALP) in DRAM,” ISCA 2012. http://users.ece.cmu.edu/~omutlu/pub/salp-dram_isca12.pdf DRAM Refresh Basics Sections 1 and 2 of Liu et al., “RAIDR: Retention-Aware Intelligent DRAM Refresh,” ISCA 2012. http://users.ece.cmu.edu/~omutlu/pub/raidr-dram- refresh_isca12.pdf 4 Simulating Main Memory How to evaluate future main memory systems? An open-source simulator and its brief description Yoongu Kim, Weikun Yang, and Onur Mutlu, "Ramulator: A Fast and Extensible DRAM Simulator" IEEE Computer Architecture Letters (CAL), March 2015. -

Random Access Memory (Ram)
www.studymafia.org A Seminar report On RANDOM ACCESS MEMORY (RAM) Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: SUBMITTED BY: www.studymafia.org www.studymafia.org www.studymafia.org Acknowledgement I would like to thank respected Mr…….. and Mr. ……..for giving me such a wonderful opportunity to expand my knowledge for my own branch and giving me guidelines to present a seminar report. It helped me a lot to realize of what we study for. Secondly, I would like to thank my parents who patiently helped me as i went through my work and helped to modify and eliminate some of the irrelevant or un-necessary stuffs. Thirdly, I would like to thank my friends who helped me to make my work more organized and well-stacked till the end. Next, I would thank Microsoft for developing such a wonderful tool like MS Word. It helped my work a lot to remain error-free. Last but clearly not the least, I would thank The Almighty for giving me strength to complete my report on time. www.studymafia.org Preface I have made this report file on the topic RANDOM ACCESS MEMORY (RAM); I have tried my best to elucidate all the relevant detail to the topic to be included in the report. While in the beginning I have tried to give a general view about this topic. My efforts and wholehearted co-corporation of each and everyone has ended on a successful note. I express my sincere gratitude to …………..who assisting me throughout the preparation of this topic. -

History Timeline by Jeff Drobman (C) 2015 === 1889 - Punch Cards - Herman Hollerith (Of IBM Forerunner) Invented "IBM" Punch Cards to Be Used for the 1890 Census
Computer Memory History Timeline by Jeff Drobman (C) 2015 === 1889 - Punch cards - Herman Hollerith (of IBM forerunner) invented "IBM" punch cards to be used for the 1890 census. 1932 - Drum memory 1947 - Delay line memory 1949 - Magnetic CORE memory 1950 - Magnetic TAPE memory 1955 - Magnetic DISK memory - IBM RAMAC was first one 1957 - Plated wire memory 1962 - Thin film memory 1968 (ca) - Paper tape - Had beginnings dating back to 1846, but became widely used with teletype machines such as the Teletype Model 33 ASR, which were adopted early on by minicomputers as a primitive terminal. 1970 - Bubble memory 1970 - DRAM - Invented by Intel, first device was the 1101, organized as 256x1, followed by the 4x larger (1024x1) 1103(A) -- regarded as the world's first commercial DRAM (intro in October 1970). 1971 - Bipolar SRAM - Fairchild 256x1 (note IBM made a 16-bit SRAM in late 1960s. AMD made a second source of a 64x1 SRAM by Fairchild in 1971.) 1971 - EPROM - Invented by Dov Frohman of Intel as the i1702, a 2K-bit (256x8) EPROM. 1971 - "Floppy" disks -- First were 8-inch, hence very flexible ("floppy"). The 8" became commercially available in 1971. 1973 (ca) - Magnetic TAPE CASSETTE memory 1976 - Shugart Associates introduced the first 5¼-inch floppy (flexible) disk drive 1977 - EEPROM - invented by Eli Harari at Hughes - a BYTE erasable device 1979 - CMOS SRAM (static RAM, 4T/6T cell, implemented as a latch) - first introduced by HP then its spinoff as Integrated Device Technology. I believe first devices were 1K (1024x1), and later organized as x4 then x8.