Introduction to Social Network Methods 1. Social Network Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Creating & Connecting: Research and Guidelines on Online Social
CREATING & CONNECTING//Research and Guidelines on Online Social — and Educational — Networking NATIONAL SCHOOL BOARDS ASSOCIATION CONTENTS Creating & Connecting//The Positives . Page 1 Online social networking Creating & Connecting//The Gaps . Page 4 is now so deeply embedded in the lifestyles of tweens and teens that Creating & Connecting//Expectations it rivals television for their atten- and Interests . Page 7 tion, according to a new study Striking a Balance//Guidance and Recommendations from Grunwald Associates LLC for School Board Members . Page 8 conducted in cooperation with the National School Boards Association. Nine- to 17-year-olds report spending almost as much time About the Study using social networking services This study was made possible with generous support and Web sites as they spend from Microsoft, News Corporation and Verizon. watching television. Among teens, The study was comprised of three surveys: an that amounts to about 9 hours a online survey of 1,277 nine- to 17-year-old students, an online survey of 1,039 parents and telephone inter- week on social networking activi- views with 250 school district leaders who make deci- ties, compared to about 10 hours sions on Internet policy. Grunwald Associates LLC, an a week watching TV. independent research and consulting firm that has conducted highly respected surveys on educator and Students are hardly passive family technology use since 1995, formulated and couch potatoes online. Beyond directed the study. Hypothesis Group managed the basic communications, many stu- field research. Tom de Boor and Li Kramer Halpern of dents engage in highly creative Grunwald Associates LLC provided guidance through- out the study and led the analysis. -

Judging You by the Company You Keep: Dating on Social Networking
Judging You by the Company You Keep: Dating on Social Networking Sites Adeline Lee, Amy Bruckman College of Computing/GVU Center Georgia Institute of Technology 85 5th Street, Atlanta, GA 30332 [email protected]; [email protected] ABSTRACT functionality, and concepts that may explain SNS dating behavior This study examines dating strategies in Social Networking Sites such as identity, self-representation and social capital. While there (SNS) and the features that help participants achieve their dating are many SNS today, the study data come from two well- goals. Qualitative data suggests the SNS feature, the friends list, established sites with critical mass and widespread popularity: plays a prominent role in finding potential dates, verifying Friendster and MySpace. credibility, and validating ongoing relationship commitment levels. Observations of how study participants use the friends list 1.1 Friends List: My Friends are Top Friends may provide design implications for social networking sites The friends list is the public display of one’s entire social network interested in facilitating romantic connection among their users. in which the connections are reciprocated. A friends list can be More broadly, this research shows how subtle user-interface comprised of hundreds of friends, but only a subset of these design choices in social computing software can have a profound friends appear on the front page of a member’s profile. This effect on non-trivial activities like finding a life partner. selective display of friends is called “My Friends” in Friendster (Figure 1) and “Top Friends” in MySpace (Figure 2). For Categories and Subject Descriptors simplicity, we refer to the selective display as Top Friends for H.5 [Information Interfaces and Presentation]: Group and either site. -

A Philosophical and Historical Analysis of Cosmology from Copernicus to Newton
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2017 Scientific transformations: a philosophical and historical analysis of cosmology from Copernicus to Newton Manuel-Albert Castillo University of Central Florida Part of the History of Science, Technology, and Medicine Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Masters Thesis (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Castillo, Manuel-Albert, "Scientific transformations: a philosophical and historical analysis of cosmology from Copernicus to Newton" (2017). Electronic Theses and Dissertations, 2004-2019. 5694. https://stars.library.ucf.edu/etd/5694 SCIENTIFIC TRANSFORMATIONS: A PHILOSOPHICAL AND HISTORICAL ANALYSIS OF COSMOLOGY FROM COPERNICUS TO NEWTON by MANUEL-ALBERT F. CASTILLO A.A., Valencia College, 2013 B.A., University of Central Florida, 2015 A thesis submitted in partial fulfillment of the requirements for the degree of Master of Arts in the department of Interdisciplinary Studies in the College of Graduate Studies at the University of Central Florida Orlando, Florida Fall Term 2017 Major Professor: Donald E. Jones ©2017 Manuel-Albert F. Castillo ii ABSTRACT The purpose of this thesis is to show a transformation around the scientific revolution from the sixteenth to seventeenth centuries against a Whig approach in which it still lingers in the history of science. I find the transformations of modern science through the cosmological models of Nicholas Copernicus, Johannes Kepler, Galileo Galilei and Isaac Newton. -

Levels of Assessment: from the Student to the Institution, by Ross Miller and Andrea Leskes (2005)
LEVELS of assessment From the Student to the Institution students»course»programBy Ross Miller and Andrea Leskes »institutions A Greater Expectations Publication LEVELS of assessment From the Student to the Institution By Ross Miller and Andrea Leskes Publications in AAC&U’s Greater Expectations Series Greater Expectations: A New Vision for Learning as Nation Goes to College (2002) Taking Responsibility for the Quality of the Baccalaureate Degree (2004) The Art and Science of Assessing General Education Outcomes, by Andrea Leskes and Barbara D. Wright (2005) General Education: A Self-Study Guide for Review and Assessment, by Andrea Leskes and Ross Miller (2005) General Education and Student Transfer: Fostering Intentionality and Coherence in State Systems, edited by Robert Shoenberg (2005) Levels of Assessment: From the Student to the Institution, by Ross Miller and Andrea Leskes (2005) Other Recent AAC&U Publications on General Education and Assessment Creating Shared Responsibility for General Education and Assessment, special issue of Peer Review, edited by David Tritelli (Fall 2004) General Education and the Assessment Reform Agenda, by Peter Ewell (2004) Our Students’ Best Work: A Framework for Accountability Worthy of Our Mission (2004) Advancing Liberal Education: Assessment Practices on Campus, by Michael Ferguson (2005) 1818 R Street, NW, Washington, DC 20009-1604 Copyright © 2005 by the Association of American Colleges and Universities. All rights reserved. ISBN 0-9763576-6-6 To order additional copies of this publication or to find out about other AAC&U publications, visit www.aacu.org, e-mail [email protected], or call 202.387.3760. This publication was made possible by a grant from Carnegie Corporation of New York. -

Examination of the Use of Online and Offline Networks by Housing Social Movement Organizations
University of Kentucky UKnowledge Theses and Dissertations--Sociology Sociology 2013 Examination of the Use of Online and Offline Networksy b Housing Social Movement Organizations Jessica N. Kropczynski University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Kropczynski, Jessica N., "Examination of the Use of Online and Offline Networksy b Housing Social Movement Organizations" (2013). Theses and Dissertations--Sociology. 11. https://uknowledge.uky.edu/sociology_etds/11 This Doctoral Dissertation is brought to you for free and open access by the Sociology at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Sociology by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained and attached hereto needed written permission statements(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine). I hereby grant to The University of Kentucky and its agents the non-exclusive license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. I agree that the document mentioned above may be made available immediately for worldwide access unless a preapproved embargo applies. -
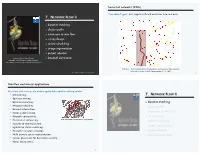
7. NETWORK FLOW II ‣ Bipartite Matching ‣ Disjoint Paths
Soviet rail network (1950s) "Free world" goal. Cut supplies (if cold war turns into real war). 7. NETWORK FLOW II ‣ bipartite matching ‣ disjoint paths ‣ extensions to max flow ‣ survey design ‣ airline scheduling ‣ image segmentation ‣ project selection Lecture slides by Kevin Wayne ‣ baseball elimination Copyright © 2005 Pearson-Addison Wesley http://www.cs.princeton.edu/~wayne/kleinberg-tardos Reference: On the history of the transportation and maximum flow problems. Alexander Schrijver in Math Programming, 91: 3, 2002. Last updated on Mar 31, 2013 3:25 PM Figure 2 2 From Harris and Ross [1955]: Schematic diagram of the railway network of the Western So- viet Union and Eastern European countries, with a maximum flow of value 163,000 tons from Russia to Eastern Europe, and a cut of capacity 163,000 tons indicated as ‘The bottleneck’. Max-flow and min-cut applications Max-flow and min-cut are widely applicable problem-solving model. ・Data mining. 7. NETWORK FLOW II ・Open-pit mining. ・Bipartite matching. ‣ bipartite matching ・Network reliability. ‣ disjoint paths ・Baseball elimination. ‣ extensions to max flow ・Image segmentation. ・Network connectivity. ‣ survey design liver and hepatic vascularization segmentation ・Distributed computing. ‣ airline scheduling ・Security of statistical data. ‣ image segmentation ・Egalitarian stable matching. ・Network intrusion detection. ‣ project selection ・Multi-camera scene reconstruction. ‣ baseball elimination ・Sensor placement for homeland security. ・Many, many, more. 3 Matching Bipartite matching Def. Given an undirected graph G = (V, E) a subset of edges M ⊆ E is Def. A graph G is bipartite if the nodes can be partitioned into two subsets a matching if each node appears in at most one edge in M. -

Models for Networks with Consumable Resources: Applications to Smart Cities Hayato Montezuma Ushijima-Mwesigwa Clemson University, [email protected]
Clemson University TigerPrints All Dissertations Dissertations 12-2018 Models for Networks with Consumable Resources: Applications to Smart Cities Hayato Montezuma Ushijima-Mwesigwa Clemson University, [email protected] Follow this and additional works at: https://tigerprints.clemson.edu/all_dissertations Recommended Citation Ushijima-Mwesigwa, Hayato Montezuma, "Models for Networks with Consumable Resources: Applications to Smart Cities" (2018). All Dissertations. 2284. https://tigerprints.clemson.edu/all_dissertations/2284 This Dissertation is brought to you for free and open access by the Dissertations at TigerPrints. It has been accepted for inclusion in All Dissertations by an authorized administrator of TigerPrints. For more information, please contact [email protected]. Models for Networks with Consumable Resources: Applications to Smart Cities A Dissertation Presented to the Graduate School of Clemson University In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy Computer Science by Hayato Ushijima-Mwesigwa December 2018 Accepted by: Dr. Ilya Safro, Committee Chair Dr. Mashrur Chowdhury Dr. Brian Dean Dr. Feng Luo Abstract In this dissertation, we introduce different models for understanding and controlling the spreading dynamics of a network with a consumable resource. In particular, we consider a spreading process where a resource necessary for transit is partially consumed along the way while being refilled at special nodes on the network. Examples include fuel consumption of vehicles together with refueling stations, information loss during dissemination with error correcting nodes, consumption of ammunition of military troops while moving, and migration of wild animals in a network with a limited number of water-holes. We undertake this study from two different perspectives. First, we consider a network science perspective where we are interested in identifying the influential nodes, and estimating a nodes’ relative spreading influence in the network. -

Towards Trust and Friendliness Approaches in the Social Internet of Things
applied sciences Review Towards Trust and Friendliness Approaches in the Social Internet of Things Farhan Amin 1 , Awais Ahmad 2 and Gyu Sang Choi 1,* 1 Department of Information and Communication Engineering, Yeungnam University, Gyeongsan 280, Korea; [email protected] 2 Department of Computer Science, Bahria University, Islamabad 44000, Pakistan; [email protected] * Correspondence: [email protected] Received: 27 November 2018; Accepted: 21 December 2018; Published: 4 January 2019 Abstract: The Internet of Things (IoT) is an interconnected network of heterogeneous entities, such as sensors and embedded devices. During the current era, a new field of research has emerged, referred to as the social IoT, which mainly includes social networking features. The social IoT refers to devices that are capable of creating interactions with each other to independently achieve a common goal. Based on the structure, the support of numerous applications, and networking services, the social IoT is preferred over the traditional IoT. However, aspects like the roles of users and network navigability are major challenges that provoke users’ fears of data disclosure and privacy violations. Thus, it is important to provide reliable data analyses by using trust- and friendliness-based properties. This study was designed because of the limited availability of information in this area. It is a classified catalog of trust- and friendliness-based approaches in the social IoT with important highlights of important constraints, such as scalability, adaptability, and suitable network structures (for instance, human-to-human and human-to-object). In addition, typical concerns like communities of interest and social contacts are discussed in detail, with particular emphasis on friendliness- and trust-based properties, such as service composition, social similarity, and integrated cloud services. -

What Is Social Network Analysis?
Scott, John. "Key concepts and measures." What is Social Network Analysis?. London: Bloomsbury Academic, 2012. 31–56. The 'What is?' Research Methods Series. Bloomsbury Collections. Web. 4 Oct. 2021. <http://dx.doi.org/10.5040/9781849668187.ch-003>. Downloaded from Bloomsbury Collections, www.bloomsburycollections.com, 4 October 2021, 00:35 UTC. Copyright © John Scott 2012. You may share this work for non-commercial purposes only, provided you give attribution to the copyright holder and the publisher, and provide a link to the Creative Commons licence. 3 Key concepts and measures Chapter 2 traced the history of social network analysis through the three broad mathematical approaches that have domi- nated the field: graph theory, algebraic approaches and spatial approaches. In this chapter I will first consider the principal methods of data collection for social network analysis, and I will then outline and define, in sequence, the key concepts and measures associated with each mathematical approach consid- ered in Chapter 2. I will suggest that graph theory provides the formal framework common to all these approaches. I will not present highly technical definitions, as these are more appropri- ate to the various handbooks of social network analysis (Scott 2012; Degenne and Forsé 1994; Prell 2012). Having done this, I will set out some of the statistical procedures used in assessing the validity of network measures in actual situations. 31 32 What is social network analysis? Collecting network data Relational data for social network analysis can be collected through a variety of methods. These include asking questions about the choice of friends, observing patterns of interaction, and compiling information on organisational memberships from printed directories. -

Dynamic Social Network Analysis: Present Roots and Future Fruits
Dynamic Social Network Analysis: Present Roots and Future Fruits Ms. Nancy K Hayden Project Leader Defense Threat Reduction Agency Advanced Systems and Concepts Office Stephen P. Borgatti, Ronald L. Breiger, Peter Brooks, George B. Davis, David S. Dornisch, Jeffrey Johnson, Mark Mizruchi, Elizabeth Warner July 2009 DEFENSE THREAT REDUCTION AGENCY •ADVANCED SYSTEMS AND CONCEPTS OFFICE REPORT NUMBER ASCO 2009 009 The mission of the Defense Threat Reduction Agency (DTRA) is to safeguard America and its allies from weapons of mass destruction (chemical, biological, radiological, nuclear, and high explosives) by providing capabilities to reduce, eliminate, and counter the threat, and mitigate its effects. The Advanced Systems and Concepts Office (ASCO) supports this mission by providing long-term rolling horizon perspectives to help DTRA leadership identify, plan, and persuasively communicate what is needed in the near term to achieve the longer-term goals inherent in the agency’s mission. ASCO also emphasizes the identification, integration, and further development of leading strategic thinking and analysis on the most intractable problems related to combating weapons of mass destruction. For further information on this project, or on ASCO’s broader research program, please contact: Defense Threat Reduction Agency Advanced Systems and Concepts Office 8725 John J. Kingman Road Ft. Belvoir, VA 22060-6201 [email protected] Or, visit our website: http://www.dtra.mil/asco/ascoweb/index.htm Dynamic Social Network Analysis: Present Roots and Future Fruits Ms. Nancy K. Hayden Project Leader Defense Threat Reduction Agency Advanced Systems and Concepts Office and Stephen P. Borgatti, Ronald L. Breiger, Peter Brooks, George B. Davis, David S. -

Structural Graph Theory Meets Algorithms: Covering And
Structural Graph Theory Meets Algorithms: Covering and Connectivity Problems in Graphs Saeed Akhoondian Amiri Fakult¨atIV { Elektrotechnik und Informatik der Technischen Universit¨atBerlin zur Erlangung des akademischen Grades Doktor der Naturwissenschaften Dr. rer. nat. genehmigte Dissertation Promotionsausschuss: Vorsitzender: Prof. Dr. Rolf Niedermeier Gutachter: Prof. Dr. Stephan Kreutzer Gutachter: Prof. Dr. Marcin Pilipczuk Gutachter: Prof. Dr. Dimitrios Thilikos Tag der wissenschaftlichen Aussprache: 13. October 2017 Berlin 2017 2 This thesis is dedicated to my family, especially to my beautiful wife Atefe and my lovely son Shervin. 3 Contents Abstract iii Acknowledgementsv I. Introduction and Preliminaries1 1. Introduction2 1.0.1. General Techniques and Models......................3 1.1. Covering Problems.................................6 1.1.1. Covering Problems in Distributed Models: Case of Dominating Sets.6 1.1.2. Covering Problems in Directed Graphs: Finding Similar Patterns, the Case of Erd}os-P´osaproperty.......................9 1.2. Routing Problems in Directed Graphs...................... 11 1.2.1. Routing Problems............................. 11 1.2.2. Rerouting Problems............................ 12 1.3. Structure of the Thesis and Declaration of Authorship............. 14 2. Preliminaries and Notations 16 2.1. Basic Notations and Defnitions.......................... 16 2.1.1. Sets..................................... 16 2.1.2. Graphs................................... 16 2.2. Complexity Classes................................ -

Social-Property Relations, Class-Conflict and The
Historical Materialism 19.4 (2011) 129–168 brill.nl/hima Social-Property Relations, Class-Conflict and the Origins of the US Civil War: Towards a New Social Interpretation* Charles Post City University of New York [email protected] Abstract The origins of the US Civil War have long been a central topic of debate among historians, both Marxist and non-Marxist. John Ashworth’s Slavery, Capitalism, and Politics in the Antebellum Republic is a major Marxian contribution to a social interpretation of the US Civil War. However, Ashworth’s claim that the War was the result of sharpening political and ideological – but not social and economic – contradictions and conflicts between slavery and capitalism rests on problematic claims about the rôle of slave-resistance in the dynamics of plantation-slavery, the attitude of Northern manufacturers, artisans, professionals and farmers toward wage-labour, and economic restructuring in the 1840s and 1850s. An alternative social explanation of the US Civil War, rooted in an analysis of the specific path to capitalist social-property relations in the US, locates the War in the growing contradiction between the social requirements of the expanded reproduction of slavery and capitalism in the two decades before the War. Keywords origins of capitalism, US Civil War, bourgeois revolutions, plantation-slavery, agrarian petty- commodity production, independent-household production, merchant-capital, industrial capital The Civil War in the United States has been a major topic of historical debate for almost over 150 years. Three factors have fuelled scholarly fascination with the causes and consequences of the War. First, the Civil War ‘cuts a bloody gash across the whole record’ of ‘the American .