Iso/Iec Jtc1/Sc2/Wg2 N3286r L2/07-207R
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Ancient Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

The University of Chicago Oriental Institute Seminars Number 2
oi.uchicago.edu i THE UNIVERSITY OF CHICAGO ORIENTAL INSTITUTE SEMINARS NUMBER 2 Series Editors Leslie Schramer and Thomas G. Urban oi.uchicago.edu ii oi.uchicago.edu iii MARGINS OF WRITING, ORIGINS OF CULTURES edited by SETH L. SANDERS with contributions by Seth L. Sanders, John Kelly, Gonzalo Rubio, Jacco Dieleman, Jerrold Cooper, Christopher Woods, Annick Payne, William Schniedewind, Michael Silverstein, Piotr Michalowski, Paul-Alain Beaulieu, Theo van den Hout, Paul Zimansky, Sheldon Pollock, and Peter Machinist THE ORIENTAL INSTITUTE OF THE UNIVERSITY OF CHICAGO ORIENTAL INSTITUTE SEMINARS • NUMBER 2 CHICAGO • ILLINOIS oi.uchicago.edu iv Library of Congress Control Number: 2005938897 ISBN: 1-885923-39-2 ©2006 by The University of Chicago. All rights reserved. Published 2006. Printed in the United States of America. The Oriental Institute, Chicago Co-managing Editors Thomas A. Holland and Thomas G. Urban Series Editors’ Acknowledgments The assistance of Katie L. Johnson is acknowledged in the production of this volume. Front Cover Illustration A teacher holding class in a village on the Island of Argo, Sudan. January 1907. Photograph by James Henry Breasted. Oriental Institute photograph P B924 Printed by McNaughton & Gunn, Saline, Michigan The paper used in this publication meets the minimum requirements of American National Standard for Infor- mation Services — Permanence of Paper for Printed Library Materials, ANSI Z39.48-1984. oi.uchicago.edu v TABLE OF CONTENTS ACKNOWLEDGMENTS ................................................................................................................. -

Amendment No. 2 to Registry Agreement
Amendment No. 2 to Registry Agreement The Internet Corporation for Assigned Names and Numbers and Infibeam Incorporation Limited agree, effective as of _______________________________ (“Amendment No. 2 Effective Date”), that the modification set forth in this amendment No. 2 (the “Amendment”) is made to the 09 January 2014 .OOO Registry Agreement between the parties, as amended (the “Agreement”). The parties hereby agree to amend Exhibit A of the Agreement by deleting section 5.3 in its entirety: [OLD TEXT] “5.3 Registry Operator may offer registration of IDNs in the following languages/scripts (IDN Tables and IDN Registration Rules will be published by the Registry Operator as specified in the ICANN IDN Implementation Guidelines): 5.3.1. Arabic script 5.3.2. Armenian script 5.3.3. Avestan script 5.3.4. Azerbaijani language 5.3.5. Balinese script 5.3.6. Bamum script 5.3.7. Batak script 5.3.8. Belarusian language 5.3.9. Bengali script 5.3.10. Bopomofo script 5.3.11. Brahmi script 5.3.12. Buginese script 5.3.13. Buhid script 5.3.14. Bulgarian language 5.3.15. Canadian Aboriginal script 5.3.16. Carian script 5.3.17. Cham script 5.3.18. Cherokee script 5.3.19. Chinese language 5.3.20. Coptic script 5.3.21. Croatian language 5.3.22. Cuneiform script 5.3.23. Cyrillic script 5.3.24. Devanagari script 5.3.25. Egyptian Hieroglyphs script 5.3.26. Ethiopic script 5.3.27. French language 5.3.28. Georgian script 5.3.29. Glagolitic script 5.3.30. -

Preliminary Proposal to Encode the Book Pahlavi Script in the Unicode Standard
UTC Document Register L2/13-141R Preliminary proposal to encode the Book Pahlavi script in the Unicode Standard Roozbeh Pournader, Google Inc. July 24, 2013 1. Background This is a proposal to encode the Book Pahlavi script in the Unicode Standard. Book Pahlavi was last proposed in the “Preliminary proposal to encode the Book Pahlavi script in the BMP of the UCS” (L2/07-234 = JTC1/SC2/WG2 N3294). Here is a short summary of the major differences in the character repertoire between that document and this proposal: • Characters only proposed here: an alternate form of d and a second alternate form of l (see section 7), one atomic symbol and two atomic ligatures (section 8), combining dot below (sections 3 and 6); • Characters proposed in L2/07-234 but not proposed here: ABBREVIATION TAA (representable as a character sequence, section 9), three archigraphemes (ambiguity, implementability, and multiple representation concerns, section 5), combining three dots below (no evidence of usage found), KASHIDA (unified with TATWEEL, sections 9 and 10), numbers (more information needed, section 10). 2. Introduction Book Pahlavi was the most important script used in writing the Middle Persian language.1 It probably started to be commonly used near the end of the Sassanian era (sixth century CE), evolving from the non-cursive Inscriptional Pahlavi. While the term “Book Pahlavi” refers to the script mostly surviving in books, Book Pahlavi has also been used in inscriptions, coins, pottery, and seals. Together with the alphabetic and phonetic Avestan script, the Book Pahlavi abjad is of religious importance to the Zoroastrian community, as most of their surviving religious texts have been written in one or both of the scripts. -

Book Pahlavi
ISO/IEC JTC1/SC2/WG2 N3294 L2/07-234 2007-07-30 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Preliminary proposal to encode the Book Pahlavi script in the BMP of the UCS Source: Michael Everson, Roozbeh Pournader, and Desmond Durkin-Meisterernst Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N2556 Date: 2007-07-30 1. Introduction. “Pahlavi” is a term used in two senses. As a term for language, it means Zoroastrian or Sasanian Middle Persian. As a term for writing systems. the word is used to describe the scripts used to write religious and secular Sasanian Middle Persian and closely similar material, such as epigraphic Parthian and Middle Persian. Three “Pahlavi” scripts are distinguished: Inscriptional Pahlavi, Psalter Pahlavi, and Book Pahlavi. All of these derive from Imperial Aramic. Book Pahlavi is an alphabetic script with an incomplete representation of vowels. The original Imperial Aramaic script’s development is marked by a progressive loss of differentiation of many letters. Thus the Imperial Aramaic letters Ö WAW, ç NUN, è AYIN, and ì RESH coalesced into one simple vertical stroke, in Book Pahlavi written Ñ. (In Inscriptional Pahlavi only Ö WAW, ç NUN, and ì RESH coalesce into •.) The Imperial Aramaic letters Ä ALEPH and á HET coalesced into Book Pahlavi Ä; the Imperial Aramaic letters Ç GIMEL, É DALETH, and â YODH coalesced into Book Pahlavi Ç; and (less importantly) the Imperial Aramaic letters å MEM and í QOPH coalesced into Book Pahlavi ä. -

Chapter 6, Writing Systems and Punctuation
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Overview and Rationale
Integration Panel: Maximal Starting Repertoire — MSR-4 Overview and Rationale REVISION – November 09, 2018 Table of Contents 1 Overview 3 2 Maximal Starting Repertoire (MSR-4) 3 2.1 Files 3 2.1.1 Overview 3 2.1.2 Normative Definition 3 2.1.3 Code Charts 4 2.2 Determining the Contents of the MSR 5 2.3 Process of Deciding the MSR 6 3 Scripts 7 3.1 Comprehensiveness and Staging 7 3.2 What Defines a Related Script? 8 3.3 Separable Scripts 8 3.4 Deferred Scripts 9 3.5 Historical and Obsolete Scripts 9 3.6 Selecting Scripts and Code Points for the MSR 9 3.7 Scripts Appropriate for Use in Identifiers 9 3.8 Modern Use Scripts 10 3.8.1 Common and Inherited 11 3.8.2 Scripts included in MSR-1 11 3.8.3 Scripts added in MSR-2 11 3.8.4 Scripts added in MSR-3 or MSR-4 12 3.8.5 Modern Scripts Ineligible for the Root Zone 12 3.9 Scripts for Possible Future MSRs 12 3.10 Scripts Identified in UAX#31 as Not Suitable for identifiers 13 4 Exclusions of Individual Code Points or Ranges 14 4.1 Historic and Phonetic Extensions to Modern Scripts 14 4.2 Code Points That Pose Special Risks 15 4.3 Code Points with Strong Justification to Exclude 15 4.4 Code Points That May or May Not be Excludable from the Root Zone LGR 15 4.5 Non-spacing Combining Marks 16 5 Discussion of Particular Code Points 18 Integration Panel: Maximal Starting Repertoire — MSR-3 Overview and Rationale 5.1 Digits and Hyphen 19 5.2 CONTEXT O Code Points 19 5.3 CONTEXT J Code Points 19 5.4 Code Points Restricted for Identifiers 19 5.5 Compatibility with IDNA2003 20 5.6 Code Points for Which the -

Middle West Iranian
DEMO : Purchase from www.A-PDF.com to remove the watermark CHAPTER FOUR MIDDLE WEST IRANIAN Prods Oklor Skjarv@ 1 INTRODUCTION 1.1 Overview Middle Persian (MPers.) and Parthian (Parth.) constitute the western branch of the known Middle Iranian languages.* The term 'Pahlavi' (pahl.) refers to the Middle Persian of the Zoroastrian texts, but is also sometimes used fo r Middle Persian in general . The indigenous words fo r the languages may have been Parsig and Pahlawanag 'Parthian' (found in a Manichean text). This usage was sometimes adopted by Western scholars, as well (Herzfeld, Nyberg: Parsik, Pahlavik). Still earlier, Pahlavi and Chaldeo-Pahlavi were used. The two languages are closely similar in structure, though Parthian shares some features with its eastern neighbors, notably with Bactrian, rather than with Middle Persian (see Sims-Williams 2007). The fact that Manichean Middle Persian and Parthian were two separate languages with different linguistic affinities was firstshown by Tedesco (1921 ). Parthian was spoken in Parthia, east of the Caspian Sea, and became an official language under the Parthian (Arsacid) rulers of Iran (ca. 247 BCE-224 CE). It is known mainly from a large corpus of short, fo rmulaic, Parthian inscriptions mostly on potsherds from the Parthian capital of Nisa dating from the first century BCE (see Skj::erv0 1995a, 1999); a few royal Parthian inscriptions from the last couple of centuries of Parthian rule; Parthian versions of the inscriptions of the third-century Sasanian kings Ardashir I, Shapur 1, and Narseh; and from the Manichean (Man.) texts fo und at Turfan in north-eastern Chinese Turkestan (Xinjiang) in the early nineteenth century. -

Overview and Rationale
Integration Panel: Maximal Starting Repertoire — MSR-5 Overview and Rationale REVISION – APRIL 06, 2021 – PUBLIC COMMENT Table of Contents 1 Overview 3 2 Maximal Starting Repertoire (MSR-5) 3 2.1 Files 3 2.1.1 Overview 3 2.1.2 Normative Definition 4 2.1.3 HTML Presentation 4 2.1.4 Code Charts 4 2.2 Determining the Contents of the MSR 5 2.3 Process of Deciding the MSR 6 3 Scripts 8 3.1 Comprehensiveness and Staging 8 3.2 What Defines a Related Script? 9 3.3 Separable Scripts 9 3.4 Deferred Scripts 9 3.5 Historical and Obsolete Scripts 9 3.6 Selecting Scripts and Code Points for the MSR 10 3.7 Scripts Appropriate for Use in Identifiers 10 3.8 Modern Use Scripts 11 3.8.1 Common and Inherited 12 3.8.2 Scripts included in MSR-1 12 3.8.3 Scripts added in MSR-2 12 3.8.4 Scripts added in MSR-3 through MSR-5 13 3.8.5 Modern Scripts Ineligible for the Root Zone 13 3.9 Scripts for Possible Future MSRs 13 3.10 Scripts Identified in UAX#31 as Not Suitable for identifiers 14 4 Exclusions of Individual Code Points or Ranges 16 4.1 Historic and Phonetic Extensions to Modern Scripts 16 4.2 Code Points That Pose Special Risks 17 4.3 Code Points with Strong Justification to Exclude 17 4.4 Code Points That May or May Not be Excludable from the Root Zone LGR 17 4.5 Non-spacing Combining Marks 18 Integration Panel: Maximal Starting Repertoire — MSR-3 Overview and Rationale 5 Discussion of Particular Code Points 20 5.1 Digits and Hyphen 20 5.2 CONTEXT O Code Points 21 5.3 CONTEXT J Code Points 21 5.4 Code Points Restricted for Identifiers 21 5.5 Compatibility -

ALPHABETUM Unicode Font for Ancient Scripts
(VERSION 14.00, March 2020) A UNICODE FONT FOR LINGUISTICS AND ANCIENT LANGUAGES: OLD ITALIC (Etruscan, Oscan, Umbrian, Picene, Messapic), OLD TURKIC, CLASSICAL & MEDIEVAL LATIN, ANCIENT GREEK, COPTIC, GOTHIC, LINEAR B, PHOENICIAN, ARAMAIC, HEBREW, SANSKRIT, RUNIC, OGHAM, MEROITIC, ANATOLIAN SCRIPTS (Lydian, Lycian, Carian, Phrygian and Sidetic), IBERIC, CELTIBERIC, OLD & MIDDLE ENGLISH, CYPRIOT, PHAISTOS DISC, ELYMAIC, CUNEIFORM SCRIPTS (Ugaritic and Old Persian), AVESTAN, PAHLAVI, PARTIAN, BRAHMI, KHAROSTHI, GLAGOLITIC, OLD CHURCH SLAVONIC, OLD PERMIC (ANBUR), HUNGARIAN RUNES and MEDIEVAL NORDIC (Old Norse and Old Icelandic). (It also includes characters for LATIN-based European languages, CYRILLIC-based languages, DEVANAGARI, BENGALI, HIRAGANA, KATAKANA, BOPOMOFO and I.P.A.) USER'S MANUAL ALPHABETUM homepage: http://guindo.pntic.mec.es/jmag0042/alphabet.html Juan-José Marcos Professor of Classics. Plasencia. Spain [email protected] 1 March 2020 TABLE OF CONTENTS Chapter Page 1. Intr oduc tion 3 2. Font installati on 3 3. Encod ing syst em 4 4. So ft ware req uiremen ts 5 5. Unicode co verage in ALP HAB ETUM 5 6. Prec ompo sed cha racters and co mbining diacriticals 6 7. Pri vate Use Ar ea 7 8. Classical Latin 8 9. Anc ient (po lytonic) Greek 12 10. Old & Midd le En glis h 16 11. I.P.A. Internati onal Phon etic Alph abet 17 12. Pub lishing cha racters 17 13. Mi sce llaneous ch aracters 17 14. Espe ran to 18 15. La tin-ba sed Eu ropean lan gua ges 19 16. Cyril lic-ba sed lan gua ges 21 17. Heb rew 22 18. -
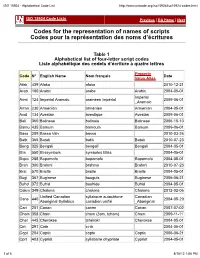
ISO 15924 - Alphabetical Code List
ISO 15924 - Alphabetical Code List http://www.unicode.org/iso15924/iso15924-codes.html ISO 15924 Code Lists Previous | RA Home | Next Codes for the representation of names of scripts Codes pour la représentation des noms d’écritures Table 1 Alphabetical list of four-letter script codes Liste alphabétique des codets d’écriture à quatre lettres Property Code N° English Name Nom français Date Value Alias Afak 439 Afaka afaka 2010-12-21 Arab 160 Arabic arabe Arabic 2004-05-01 Imperial Armi 124 Imperial Aramaic araméen impérial 2009-06-01 _Aramaic Armn 230 Armenian arménien Armenian 2004-05-01 Avst 134 Avestan avestique Avestan 2009-06-01 Bali 360 Balinese balinais Balinese 2006-10-10 Bamu 435 Bamum bamoum Bamum 2009-06-01 Bass 259 Bassa Vah bassa 2010-03-26 Batk 365 Batak batik Batak 2010-07-23 Beng 325 Bengali bengalî Bengali 2004-05-01 Blis 550 Blissymbols symboles Bliss 2004-05-01 Bopo 285 Bopomofo bopomofo Bopomofo 2004-05-01 Brah 300 Brahmi brahma Brahmi 2010-07-23 Brai 570 Braille braille Braille 2004-05-01 Bugi 367 Buginese bouguis Buginese 2006-06-21 Buhd 372 Buhid bouhide Buhid 2004-05-01 Cakm 349 Chakma chakma Chakma 2012-02-06 Unified Canadian syllabaire autochtone Canadian Cans 440 2004-05-29 Aboriginal Syllabics canadien unifié _Aboriginal Cari 201 Carian carien Carian 2007-07-02 Cham 358 Cham cham (čam, tcham) Cham 2009-11-11 Cher 445 Cherokee tchérokî Cherokee 2004-05-01 Cirt 291 Cirth cirth 2004-05-01 Copt 204 Coptic copte Coptic 2006-06-21 Cprt 403 Cypriot syllabaire chypriote Cypriot 2004-05-01 1 of 6 8/16/12 1:56 PM ISO