High Speed Deep Networks Based on Discrete Cosine Transformation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How I Came up with the Discrete Cosine Transform Nasir Ahmed Electrical and Computer Engineering Department, University of New Mexico, Albuquerque, New Mexico 87131
mxT*L. BImL4L. PRocEsSlNG 1,4-5 (1991) How I Came Up with the Discrete Cosine Transform Nasir Ahmed Electrical and Computer Engineering Department, University of New Mexico, Albuquerque, New Mexico 87131 During the late sixties and early seventies, there to study a “cosine transform” using Chebyshev poly- was a great deal of research activity related to digital nomials of the form orthogonal transforms and their use for image data compression. As such, there were a large number of T,(m) = (l/N)‘/“, m = 1, 2, . , N transforms being introduced with claims of better per- formance relative to others transforms. Such compari- em- lh) h = 1 2 N T,(m) = (2/N)‘%os 2N t ,...) . sons were typically made on a qualitative basis, by viewing a set of “standard” images that had been sub- jected to data compression using transform coding The motivation for looking into such “cosine func- techniques. At the same time, a number of researchers tions” was that they closely resembled KLT basis were doing some excellent work on making compari- functions for a range of values of the correlation coef- sons on a quantitative basis. In particular, researchers ficient p (in the covariance matrix). Further, this at the University of Southern California’s Image Pro- range of values for p was relevant to image data per- cessing Institute (Bill Pratt, Harry Andrews, Ali Ha- taining to a variety of applications. bibi, and others) and the University of California at Much to my disappointment, NSF did not fund the Los Angeles (Judea Pearl) played a key role. -

Digital Video in Multimedia Pdf
Digital video in multimedia pdf Continue Digital Electronic Representation of Moving Visual Images This article is about the digital methods applied to video. The standard digital video storage format can be viewed on DV. For other purposes, see Digital Video (disambiguation). Digital video is an electronic representation of moving visual images (video) in the form of coded digital data. This contrasts with analog video, which is a moving visual image with analog signals. Digital video includes a series of digital images displayed in quick succession. Digital video was first commercially introduced in 1986 in Sony D1 format, which recorded a non-repressive standard digital video definition component. In addition to uncompressed formats, today's popular compressed digital video formats include H.264 and MPEG-4. Modern interconnect standards for digital video include HDMI, DisplayPort, Digital Visual Interface (DVI) and Serial Digital Interface (SDI). Digital video can be copied without compromising quality. In contrast, when analog sources are copied, they experience loss of generation. Digital video can be stored in digital media, such as Blu-ray Disc, in computer data storage, or transmitted over the Internet to end users who watch content on a desktop or digital smart TV screen. In everyday practice, digital video content, such as TV shows and movies, also includes a digital audio soundtrack. History Digital Video Cameras Additional Information: Digital Cinematography, Image Sensor, and Video Camera Base for Digital Video Cameras are metallic oxide-semiconductor (MOS) image sensors. The first practical semiconductor image sensor was a charging device (CCD) invented in 1969 using MOS capacitor technology. -

Watermarked Image Compression and Transmission Through Digital Communication System
International Journal of Electronics, Communication & Instrumentation Engineering Research and Development (IJECIERD) ISSN 2249-684X Vol. 3, Issue 1, Mar 2013, 97-104 © TJPRC Pvt. Ltd. WATERMARKED IMAGE COMPRESSION AND TRANSMISSION THROUGH DIGITAL COMMUNICATION SYSTEM M. VENU GOPALA RAO 1, N. NAGA SWETHA 2, B. KARTHIK 3, D. JAGADEESH PRASAD 4 & K. ABHILASH 5 1Professor, Department of ECE, K L University, Vaddeswaram, Andhra Pradesh, India 2,3,4,5 Student, Department of ECE, K L University, Vaddeswaram, Andhra Pradesh, India ABSTRACT This paper presents a process able to mark digital images with an invisible and undetectable secrete information, called the watermark, followed by compression of the watermarked image and transmitting through a digital communication system. This process can be the basis of a complete copyright protection system. Digital water marking is a feasible method for the protection of ownership rights of digital media such as audio, image, video and other data types. The application includes digital signatures, fingerprinting, broadcast and publication monitoring, copy control, authentication, and secret communication. For the efficient transmission of an image across a channel, source coding in the form of image compression at the transmitter side & the image recovery at the receiver side are the integral process involved in any digital communication system. Other processes like channel encoding, signal modulation at the transmitter side & their corresponding inverse processes at the receiver side along with the channel equalization help greatly in minimizing the bit error rate due to the effect of noise & bandwidth limitations (or the channel capacity) of the channel. The results shows that the effectiveness of the proposed system for retrieving the secret data without any distortion. -

INTERIM Bual Repo#R
.* L, '. .. .. ." r . INTERIM BuAL REpo#r I B.W. J319Es (NASA-CE- 166225) S'IOCY OF CCCL~Jb?CBIICNS N83- !777!, 1AI.P CCHFRFSSICI EE11C3S Interin Einal ReFCrt (COY-COCE, Ioc,, EIountain View, Calif.) 267 p HC A I;/!IF AOI CSCL I7E !llnclas i G3/32 32908 Prepared for MAAMfE RESEARCH CEIWEIi MOF'FETT FEU), CALIFOFNU, 94035 NASA TECHNICAL MONITOR Larry B. Hofman COM-CODE, INC. 305 EASY ST. NO.9 IQN. VlEW I CALIFORNIA 94043 - .. , .. SECTION A SUMMARY REPQRT SECTION B VIDEO CCMPFESSION SECTION C LANDSAT IMAGE PRCCESSING SECTION D SATELLITE CaMEINNICATIONS f L SEXTION A SUMMARY REPORT This section provides a brief suaunary report of the work accolnplished under the "Study of Communications .Data Compression Methods", under NASA contract NAS 2-9703. The results are fully explained in subsequent sections on video canpression, Landsat image processipa, and satellite commnications . The first task of contract NAS 2-9703 was to extend a simple monochrome conditional replenishment system to higher compression and to higher motion levels, by incorporating spatially adaptive quantizers and field repeating. Conditional replenishment combines intraframe and interframe compression, and bath areas were to be investigated. The gain of conditional replenishment depends on the fraction of the image changing, since only changed parts of the image need to be transmitted. If the transmission rate is set so that only one-fourth of the image can be transmitted in each field, greater change fractions will overload the system. To accomplish task I, a computer simulation was prepared which incorporated 1) field repeat of changes, 2) a variable change threshold, 3) frame repeat for high change, and 4) two mcde, variable rate Hadamard intraframe quantizers. -

Analytical Links in the Tasks of Digital Content Compression
Analytical Links in the Tasks of Digital Content Compression Olena Kolganova 1[0000-0002-1301-9611], Viktoriia Kravchenko 1[0000-0003-0399-7013], Lidiia Tereshchenko 1[0000-0001-8183-9016], Volodymyr Shutko 1[0000-0002-9761-5583] and Mykola Shutko 1[0000-0002-3531-7724], Yevhen Vasiliu 2[0000-0002-8582-285X] 1 National Aviation University, Kyiv, Ukraine 2 O.S.Popov Odessa National Academy of Telecommunication, Odessa, Ukraine [email protected], [email protected] Abstract. The article is devoted to the development of a digital image compres- sion algorithm. Image compression is a type of data compression applied to dig- ital images, to reduce their cost for storage or transmission. Algorithms may take advantage of visual perception and the statistical properties of image data. We will consider a lossy compression algorithm. The new algorithm is based on multiscale decomposition with a spline as a basis function. In the process of multiscale analysis, when constructing a spline, we should take into account analytical links. The application of this approach give an increase in the com- pression ratio with the same quality of compressed images. Keywords: Digital Image Compression, Analytical Links, Hermitian Spline, Multiscale Analysis. 1 Introduction Multimedia standards for video compression for personalized television, high defini- tion digital television (HDTV), and image / video database maintenance use close motion and encoding methods. Three basic standards - MPEG-1, MPEG-2 and MPEG-4 were developed by the Moving Picture Experts Group (MPEG), under the auspices of the ISO and the International Telegraph and Telephone Consultative Committee (was renamed the International Telegraph Union (ITU). -
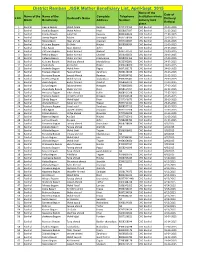
District Ramban JSSK Mother Beneficiary List, April-Sept. 2015 Name of the Date of Name of the Name of the Complete Telephone Institution Where S NO
District Ramban_JSSK Mother Beneficiary List, April-Sept. 2015 Name of the Date of Name of the Name of the Complete Telephone Institution where S NO. Husband's Name Delivery/ Block Beneficiary Address Number delivery took Refferal place. 1 Banihal Heena Begum Mohd Aslam Ramban 9797444452 CHC Banihal 20-03-2015 2 Banihal shahida Begum Mohd Ashraf Khari 9858667697 CHC Banihal 21-03-2015 3 Banihal Fatima Begum Jamal Din Kawana 9086360643 CHC Banihal 22-03-2015 4 Banihal Soniya Begum Babloo chinargali 9697168596 CHC Banihal 22-03-2015 5 Banihal Nizara Bgum Nisar ahmed chapnari 9697102667 CHC Banihal 22-03-2015 6 Banihal Kulsuma Begum Gh.Nabi Hinjhal 9858936084 CHC Banihal 22-03-2015 7 Banihal Ulfat Bgum Nazir Ahmed Asher NA CHC Banihal 23-03-2015 8 Banihal Zaitoona Begum Bashir Ahmed Amkoot 9697141572 CHC Banihal 23-03-2015 9 Banihal Rehana Begum Bashir Ahmed Chachal 9596931659 CHC Banihal 24-03-2015 10 Banihal Hafeeza Begum Shabir ahmed chacknarwa 9858003465 CHC Banihal 24-03-2015 11 Banihal Kulsuma Begum Mushtaq ahmed Mandakbass 9622392891 CHC Banihal 24-03-2015 12 Banihal shamshada Ab.Rashid Hingni 9906478060 CHC Banihal 24-03-2015 13 Banihal shakeela Begum Mohd Amin Fagoo 9697289173 CHC Banihal 24-03-2015 14 Banihal Maneera Begum Fayaz ahmed Zanchous 9858138106 CHC Banihal 25-03-2015 15 Banihal Parveena Begum Javeed Ahmed Ramban 9596834792 CHC Banihal 25-03-2015 16 Banihal Bareena Begum Mohd Farooq shabanbass 9906207401 CHC Banihal 25-03-2015 17 Banihal Zeena begum Bashir Ahmed chachal 9858589273 CHC Banihal 27-03-2015 18 Banihal Suriya -

(12) United States Patent (10) Patent N0.: US 8,942,977 B2 Chen (45) Date of Patent: Jan
US008942977B2 (12) United States Patent (10) Patent N0.: US 8,942,977 B2 Chen (45) Date of Patent: Jan. 27, 2015 (54) SYSTEM AND METHOD FOR SPEECH (56) References Cited RECOGNITION USING U.S. PATENT DOCUMENTS PITCH-SYNCHRONOUS SPECTRAL PARAMETERS 5,917,738 A * 6/1999 Pan ............................. .. 708/403 6,311,158 B1* 10/2001 Laroche .. 704/269 (71) Applicant: Chengiun Julian Chen, White Plains, 6,470,311 B1* 10/2002 Moncur .... .. 704/208 NY (U S) H2172 H * 9/2006 Staelin et a1. ............... .. 704/207 OTHER PUBLICATIONS Inventor: Chengiun Julian Chen, White Plains, (72) Hess, Wolfgang. “A pitch-synchronous digital feature extraction sys NY (U S) tem for phonemic recognition of speech.” Acoustics, Speech and Notice: Subject to any disclaimer, the term of this Signal Processing, IEEE Transactions on 24.1 (1976): 14-25.* (*) Mandyam, Giridhar, Nasir Ahmed, and Neeraj Magotra. “Applica patent is extended or adjusted under 35 tion of the discrete Laguerre transform to speech coding.” Asilomar U.S.C. 154(b) by 0 days. Conference on Signals, Systems and Computers. IEEE Computer Society, 1995* (21) Appl. No.: 14/216,684 Legat, Milan, J. Matousek, and Daniel Tihelka. “On the detection of pitch marks using a robust multi-phase algorithm.” Speech Commu (22) Filed: Mar. 17, 2014 nication 53.4 (2011): 552-566.* Wikipedia entry for tonal languages (Dec. 15, 2011).* (65) Prior Publication Data * cited by examiner US 2014/0200889 A1 Jul. 17,2014 Primary Examiner * Vincent P Harper (57) ABSTRACT Related US. Application Data The present invention de?nes a pitch- synchronous parametri Continuation-in-part of application No. -

Copy Mode for Static Screen Content Coding with Hevc
COPY MODE FOR STATIC SCREEN CONTENT CODING WITH HEVC Thorsten Laude and Jorn¨ Ostermann Institut fur¨ Informationsverarbeitung (TNT), Leibniz Universitat¨ Hannover, Germany ABSTRACT ing the last decades and are well known to provide the desired compatibility. In January 2013, the Joint Collaborative Team Screen content largely consists of static parts, e.g. static on Video Coding (JCT-VC) of ITU-T VCEG and ISO/IEC background. However, none of the available screen content MPEG has finished the technical work for the latest video coding tools fully employs this characteristic. In this paper coding standard, High Efficiency Video Coding (HEVC) [3]. we present the copy mode, a new coding mode specifically It achieves the same visual quality with half the bit rate com- aiming at increased coding efficiency for static screen con- pared to the predecessor standard AVC [4]. tent. The basic principle of the copy mode is the direct copy Even though this state-of-the-art video coding standard of the collocated block from the reference frame. Mean provides superior coding efficiency for camera captured weighted BD-Rate gains of 2.4% are achieved for JCT-VC videos, it is not the optimal coding method for screen con- test sequences compared to SCM-2.0. For sequences contain- tent (SC). The reason therefor is that HEVC (as well as the ing lots of static background, coding gains as high as 7.6% predecessor standards) has not been developed with careful are observed. The new coding mode is further enhanced consideration of screen content signals. Thus, after finalizing by several encoder optimizations, among them an early skip HEVC, the JCT-VC started the development of a screen con- mechanism. -

Extensions of Remarks E1823 EXTENSIONS of REMARKS
October 19, 2000 CONGRESSIONAL RECORD Ð Extensions of Remarks E1823 EXTENSIONS OF REMARKS TRIBUTE TO BO SHAFER with as many people as possible, and he will and he excelled at football, earning all-state be afforded a global opportunity to expand honors and a scholarship to the University of upon a lifelong devotion to community serv- Tennessee (UT) in Knoxville. HON. JOHN J. DUNCAN, JR. ice as Kiwanis' 2000±01 International Presi- Notably, he was a charter member of the OF TENNESSEE dentÐwhile spreading his homespun West High School Key Club, and then he be- IN THE HOUSE OF REPRESENTATIVES ``Boverbs'': came a charter member of the UT Circle K club. Years later when Bo was the Circle K ``JOY COMES FROM GIVING; PLEASURE COMES Wednesday, October 18, 2000 club's Kiwanis sponsor, he helped it form a FROM TAKING'' Mr. DUNCAN. Mr. Speaker, today I want to Big Brothers chapter. ``I don't think people are born with a serv- In college, footballÐwhich is taken very recognize Mr. Bo Shafer, who recently be- ant heart; I think we're born selfish,'' Bo seriously at UTÐoccupied much of his time. came the International President of the theorizes. ``And if you don't have spiritual A six-foot-two-inch, 220-pound ``average'' Kiwanis Club. help, you really don't have the right heart to tackle who played iron-man football (offense He is one of the finest men I know. do things for other people and expect noth- and defense) for the Volunteers, he saw a lot All who know Bo Shafer agree that he is a ing in return. -

BJMC-05-BLOCK-02.Pdf
Bachelor of Arts (Honors) in Journalism& Mass Communication (BJMC) BJMC-5 INTRODUCTION TO BROADCAST MEDIA Block - 2 BASICS OF VISUALS UNIT-1 TYPES OF IMAGES: STILL IMAGES, ELECTRONIC IMAGES, DIGITAL IMAGES UNIT-2 CHARACTERISTICS OF TELEVISION AS A VISUAL MEDIUM UNIT-3 IMAGE EDITING: POLITICS OF AN IMAGE UNIT-4 VISUAL CULTURE: CHANGING ECOLOGY OF IMAGES The Course follows the UGC prescribed syllabus for BA(Honors) Journalism under Choice Based Credit System (CBCS). Course Writer Course Editor Mr. Rakesh Kumar Dash Mr Sudarsan Sahoo Academic Consultant IIS Odisha State Open University News Editor, Doordarshan Sambalpur Bhubaneswar Material Production Dr. Manas Ranjan Pujari Registrar Odisha State Open University, Sambalpur (CC) OSOU, MAY 2020. BASICS OF VISUALS is made available under a Creative Commons Attribution-ShareAlike 4.0 http://creativecommons.org/licences/by-sa/4.0 Printed by: UNIT 1: TYPES OF IMAGES: STILL IMAGES, ELECTRONIC IMAGES, DIGITAL IMAGES Unit Structure 1.1 Learning Objectives 1.2 Introduction 1.3 Types of Images 1.4 Still Images 1.5 Electronic Images 1.6 Digital Images 1.7 Let‘s Sum- up 1.8 Check Your Progress 1.1 LEARNING OBJECTIVES After completion of this unit, learners should be able to understand: Different types of images and image formats Use of still and electronic images Digital images and its various applications 1.2 INTRODUCTION An image is a binary representation of visual information, such as drawings, pictures, graphs, logos or individual video frames. In a more complex language and in context of image signal processing, an image is the distributed amplitude of colors. -

BIOGRAPHY Behnaam Aazhang Office
BIOGRAPHY Behnaam Aazhang September 2015 Office: Home: Department of Electrical and Computer Engineering Rice University 3812 Marlowe Houston, TX 77251-1892 Houston, TX 77005 Tel: (713)-348-4749, FAX: (713)-348-6196 Tel: (713)-669-1922 E-mail: [email protected] http://www.ece.rice.edu/~aaz Research Interests: Communication theory, information theory, and their applications to wireless communication with a focus on the interplay of communication systems and networks; including network coding, user cooperation, spectrum sharing, opportunistic access, and scheduling with different delay constraints as well as millimeter wave communications. Signal processing, information processing, and their applications to neuro-engineering with foci on (i) modeling neuronal circuits connectivity and the impact of learning on connectivity (ii) real-time closed-loop stabilization of neuronal systems to mitigate disorders such as epilepsy, Parkinson, depression, and obesity, (iii) develop an understanding of cortical representation and fine-grained connectivity in the human language system. Build microelectronics with large data analysis techniques to develop a fine-grained recording and modulation system to remediate language disorders. Education: 1986 Ph.D. Electrical and Computer Engineering, University of Illinois, Urbana 1983 M.S. Electrical and Computer Engineering, University of Illinois, Urbana 1981 B.S. Electrical and Computer Engineering, University of Illinois, Urbana Positions: 2014-present Director of Center for Neuro-Engineering (CNE), a multi-university -
Various Countries' Examples of and Countermeasures to Fake News
14(Mon.) - 16(Wed.) September 2020 Conference Book Ⅰ Various Countries’ Examples of and Countermeasures to Fake News and The Future of the Journalism Fake News에 대한 각국 사례와 대응방안 그리고 언론의 미래 Contents Overview 005 Conference Ⅰ 015 Participants List 197 Overview Title World Journalists Conference 2020 Date 14(Mon.) - 16(Wed.) September 2020 Venue International Convention Hall [20F], Korea Press Center Hosted by Supported by Theme · Conference Ⅰ Various Countries’ Examples of and Countermeasures to Fake News and The Future of the Journalism · Conference Ⅱ Global Responses to COVID-19 and Disease Control Methods · Conference Ⅲ The 70th anniversary of the Korean War and Peace Policy in the Korean Peninsula · Discuss the development of journalism along with changes in the media Objectives environment - Share national journalism situations and discuss the future of journalism to cope with rapidly-changing media environment around the world - Seek countermeasures to the global issue of Fake News - Make efforts to restore media trust and develop business model sharing · Discuss status-quo and role of journalism in each country amid the spread of COVID-19 - Share the COVID-19 situation in each country and the quarantine system - Protect the public’s right to know and address human rights issues related to the infectious disease - Introduce Korea’s reporting guidelines for infectious diseases · The 70th Anniversary of the Korean War and Peace Strategy on the Korean Peninsula - form a consensus on the importance of peace on the Korean Peninsula and the world commemorating in 2020 the 70th anniversary of the outbreak of the Korean War - Let the world know the willingness of Koreans toward World Peace and gain supports - Discuss each country’s views on the situation on the Korean Peninsula and the role of ※ World Journalists Conference is funded by the Journalism Promotion Fund journalists to improve inter-Korean and North Korea-US relations raised by government advertising fees.